cs231n_2020 作业knn笔记
Nearest Neighbor分类器
L1距离计算:
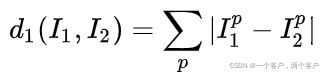
 与
与  分别代表训练与测试图像,对两图像逐个像素做差,所得结果即为L1值(如下图所示)
分别代表训练与测试图像,对两图像逐个像素做差,所得结果即为L1值(如下图所示)
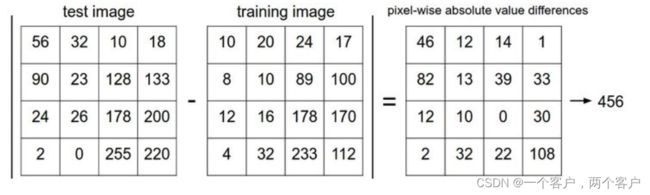
L1插值越大,代表test图片与train图片差异越大。
L2距离公式:
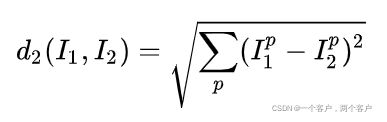
代码笔记:
1.notbook 导入包设置plt
# 此处为notebook部分代码
import random
import numpy as np
from cs231n.data_utils import load_CIFAR10
import matplotlib.pyplot as plt
# matplotlib 是款画图使用的插件
%matplotlib inline #使用%matplotlib命令可以将matplotlib的图表直接嵌入到Notebook之中
plt.rcParams['figure.figsize'] = (10.0, 8.0) # 设置图像尺寸
plt.rcParams['image.interpolation'] = 'nearest' # 最近邻差值: 像素为正方形
plt.rcParams['image.cmap'] = 'gray' # 输出为灰色
# Some more magic so that the notebook will reload external python modules;
# see http://stackoverflow.com/questions/1907993/autoreload-of-modules-in-ipython
%load_ext autoreload
%autoreload 2matplotlib更多设置可见此处: http://t.csdn.cn/TPgOh
2.加载数据集
#notebook部分第二块代码
# Load the raw CIFAR-10 data.
cifar10_dir = 'cs231n/datasets/cifar-10-batches-py' #此处为cifar数据集存放地址,可以
# 手动下载放置其中,cs231n在assignment1目录之下
# Cleaning up variables to prevent loading data multiple times (which may
# cause memory issue)
try:
del X_train, y_train #del函数可以清除后续变量中的内容,在存储上是解绑变量与内存
del X_test, y_test
print('Clear previously loaded data.')
except:
pass
X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir) #载入数据集,在
# data_utils中可以找到
# As a sanity check, we print out the size of the training and test data.
print('Training data shape: ', X_train.shape)
print('Training labels shape: ', y_train.shape)
print('Test data shape: ', X_test.shape)
print('Test labels shape: ', y_test.shape)
#输出结果为下
#Training data shape: (50000, 32, 32, 3)
#Training labels shape: (50000,)
#Test data shape: (10000, 32, 32, 3)
#Test labels shape: (10000,)3.展示部分数据集
flatnonzero(),与random.choice()函数详细解析http://t.csdn.cn/abuYJ
#notebook部分第三块代码
# Visualize some examples from the dataset.
# We show a few examples of training images from each class.
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship',
'truck']
#classes是分类的标签
num_classes = len(classes) #记录标签数
samples_per_class = 7 #展示图片数设定
for y, cls in enumerate(classes): # 遍历y为标签位置,cls为标签值如 y=1,cls=plane
idxs = np.flatnonzero(y_train == y) # 筛选出y_train中值为y的数据地址
idxs = np.random.choice(idxs, samples_per_class, replace=False)
# 从idxs中抽取samples_per_class张图片组成新数组
for i, idx in enumerate(idxs):
plt_idx = i * num_classes + y + 1 #计算索引位置,i为行位置,y为列位置(可见显示矩阵)
plt.subplot(samples_per_class, num_classes, plt_idx)
plt.imshow(X_train[idx].astype('uint8'))
plt.axis('off')
if i == 0:
plt.title(cls)
plt.show()图片显示如下:
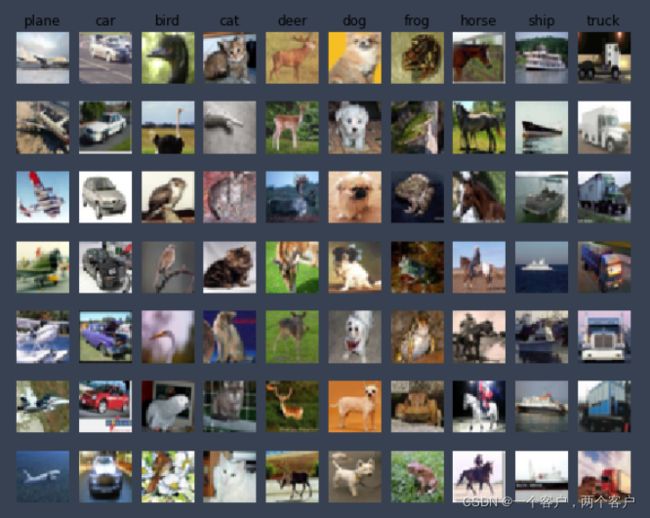
4.二次采样
#notebook部分第四块代码
# Subsample the data for more efficient code execution in this exercise
# 使用mask数组划分训练集,测试集
num_training = 5000
mask = list(range(num_training))
X_train = X_train[mask]
y_train = y_train[mask]
num_test = 500
mask = list(range(num_test))
X_test = X_test[mask]
y_test = y_test[mask]
# Reshape the image data into rows
# 将图片数据转化为行
X_train = np.reshape(X_train, (X_train.shape[0], -1)) # 转化为行数为X_train.shape[0]的形状
X_test = np.reshape(X_test, (X_test.shape[0], -1))
print(X_train.shape, X_test.shape)
#输出结果
#(5000, 3072) (500, 3072)5.导入 k_nearest_neighbor
#notebook部分第五块代码
from cs231n.classifiers import KNearestNeighbor
# 导入k_nearest_neighbor.py程序中的KNearestNeighbor类
# Create a kNN classifier instance.
# Remember that training a kNN classifier is a noop:
# the Classifier simply remembers the data and does no further processing
classifier = KNearestNeighbor()
classifier.train(X_train, y_train)k_nearest_neighbor.py模块代码如下:
from builtins import range
from builtins import object
import numpy as np
from past.builtins import xrange
class KNearestNeighbor(object):
""" a kNN classifier with L2 distance """
def __init__(self):
pass
def train(self, X, y):
"""
Train the classifier. For k-nearest neighbors this is just
memorizing the training data.
Inputs:
- X: A numpy array of shape (num_train, D) containing the training data
consisting of num_train samples each of dimension D.
- y: A numpy array of shape (N,) containing the training labels, where
y[i] is the label for X[i].
"""
self.X_train = X
self.y_train = y
def predict(self, X, k=1, num_loops=0):
"""
Predict labels for test data using this classifier.
Inputs:
- X: A numpy array of shape (num_test, D) containing test data consisting
of num_test samples each of dimension D.
- k: The number of nearest neighbors that vote for the predicted labels.
- num_loops: Determines which implementation to use to compute distances
between training points and testing points.
Returns:
- y: A numpy array of shape (num_test,) containing predicted labels for the
test data, where y[i] is the predicted label for the test point X[i].
"""
if num_loops == 0:
dists = self.compute_distances_no_loops(X)
elif num_loops == 1:
dists = self.compute_distances_one_loop(X)
elif num_loops == 2:
dists = self.compute_distances_two_loops(X)
else:
raise ValueError('Invalid value %d for num_loops' % num_loops)
return self.predict_labels(dists, k=k)L2(self, X)距离函数代码如下,公式为:
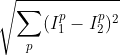
此为2层循环代码
def compute_distances_two_loops(self, X):
"""
Compute the distance between each test point in X and each training point
in self.X_train using a nested loop over both the training data and the
test data.
Inputs:
- X: A numpy array of shape (num_test, D) containing test data.
Returns:
- dists: A numpy array of shape (num_test, num_train) where dists[i, j]
is the Euclidean distance between the ith test point and the jth training
point.
"""
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in range(num_test):
for j in range(num_train):
#####################################################################
# TODO: #
# Compute the l2 distance between the ith test point and the jth #
# training point, and store the result in dists[i, j]. You should #
# not use a loop over dimension, nor use np.linalg.norm(). #
#####################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
dists[i][j] = np.sqrt(np.sum((X[i]-self.X_train[j]) ** 2))
# dists[i][j] = np.linalg.norm(X[i]-self.X_train[j])
pass
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return dists使用单次循环,代码如下
def compute_distances_one_loop(self, X):
"""
Compute the distance between each test point in X and each training point
in self.X_train using a single loop over the test data.
Input / Output: Same as compute_distances_two_loops
"""
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in range(num_test):
#######################################################################
# TODO: #
# Compute the l2 distance between the ith test point and all training #
# points, and store the result in dists[i, :]. #
# Do not use np.linalg.norm(). #
#######################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
#dists[i, :] = np.sqrt(np.sum((self.X_train-X[i])**2, axis=1))
dists[i, :] = np.sqrt(np.sum(np.square((self.X_train-X[i])), axis=1))
pass
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return dists无循环代码推导公式,详情http://t.csdn.cn/upPdB
代码如下:
def compute_distances_no_loops(self, X):
"""
Compute the distance between each test point in X and each training point
in self.X_train using no explicit loops.
Input / Output: Same as compute_distances_two_loops
"""
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
#########################################################################
# TODO: #
# Compute the l2 distance between all test points and all training #
# points without using any explicit loops, and store the result in #
# dists. #
# #
# You should implement this function using only basic array operations; #
# in particular you should not use functions from scipy, #
# nor use np.linalg.norm(). #
# #
# HINT: Try to formulate the l2 distance using matrix multiplication #
# and two broadcast sums. #
#########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# hmmm... reference: https://mlxai.github.io/2017/01/03/finding-distances-between-data-points-with-numpy.html
dists = X.dot(self.X_train.T)
X_square = np.sum(np.square(X), axis=1)
X_train_square = np.square(self.X_train).sum(axis=1)
dists = np.sqrt(X_square[:, np.newaxis] + X_train_square - 2*dists)#np.newaxis用于扩展维度
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return dists预测标签函数代码如下,其中argsort详情参考http://t.csdn.cn/UZ9oe:
def predict_labels(self, dists, k=1):
"""
Given a matrix of distances between test points and training points,
predict a label for each test point.
Inputs:
- dists: A numpy array of shape (num_test, num_train) where dists[i, j]
gives the distance betwen the ith test point and the jth training point.
Returns:
- y: A numpy array of shape (num_test,) containing predicted labels for the
test data, where y[i] is the predicted label for the test point X[i].
"""
num_test = dists.shape[0]
y_pred = np.zeros(num_test)
for i in range(num_test):
# A list of length k storing the labels of the k nearest neighbors to
# the ith test point.
closest_y = []
#########################################################################
# TODO: #
# Use the distance matrix to find the k nearest neighbors of the ith #
# testing point, and use self.y_train to find the labels of these #
# neighbors. Store these labels in closest_y. #
# Hint: Look up the function numpy.argsort. #
#########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
closest_y = self.y_train[np.argsort(dists[i])][0:k]
#argsort将图像从小到大排序,并输出前k个的类型
pass
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
#########################################################################
# TODO: #
# Now that you have found the labels of the k nearest neighbors, you #
# need to find the most common label in the list closest_y of labels. #
# Store this label in y_pred[i]. Break ties by choosing the smaller #
# label. #
#########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
y_pred[i] = max(closest_y, key=list(closest_y).count)
#对得到的k个数进行投票,选取出现次数最多的类别作为最后的预测类别
pass
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return y_pred6.交叉验证部分
交叉验证思维导图如下
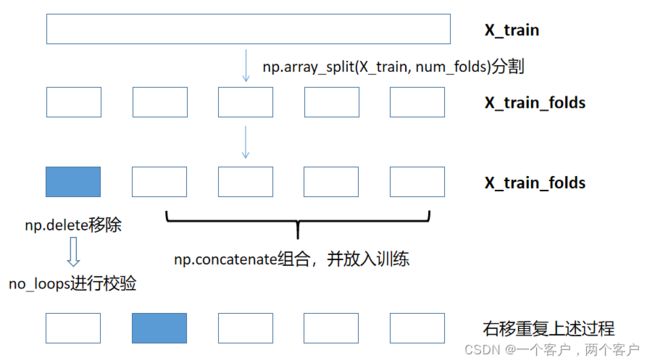
num_folds = 5
k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100]
X_train_folds = []
y_train_folds = []
################################################################################
# TODO: #
# Split up the training data into folds. After splitting, X_train_folds and #
# y_train_folds should each be lists of length num_folds, where #
# y_train_folds[i] is the label vector for the points in X_train_folds[i]. #
# Hint: Look up the numpy array_split function. #
################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
y_train=y_train.reshape(-1,1)
X_train_folds = np.array_split(X_train, num_folds)
y_train_folds = np.array_split(y_train, num_folds)
# 将X_train,y_train分割成五个数组
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# A dictionary holding the accuracies for different values of k that we find
# when running cross-validation. After running cross-validation,
# k_to_accuracies[k] should be a list of length num_folds giving the different
# accuracy values that we found when using that value of k.
k_to_accuracies = {}
################################################################################
# TODO: #
# Perform k-fold cross validation to find the best value of k. For each #
# possible value of k, run the k-nearest-neighbor algorithm num_folds times, #
# where in each case you use all but one of the folds as training data and the #
# last fold as a validation set. Store the accuracies for all fold and all #
# values of k in the k_to_accuracies dictionary. #
################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
num_fold_test = y_train_folds[0].shape[0]
for k in k_choices:
classifier = KNearestNeighbor()
k_to_accuracies[k] = []
for test_idx in range(num_folds):
# print(np.concatenate(np.delete(X_train_folds, k, 0), axis=0).shape)
classifier.train(np.concatenate(np.delete(X_train_folds, test_idx, 0)),
np.concatenate(np.delete(y_train_folds, test_idx, 0)))
#np.concatenate的作用是将np.delete处理后的数组拼接成一个数组
#np.delete是对X_train_folds矩阵的test_idx索引按行删除
dists = classifier.compute_distances_no_loops(X_train_folds[test_idx])
k_to_accuracies[k].append(np.sum(classifier.predict_labels(dists, k) == y_train_folds[test_idx]) / num_fold_test*1.0)
#计算交叉验证准确率
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# Print out the computed accuracies
for k in sorted(k_to_accuracies):
for accuracy in k_to_accuracies[k]:
print('k = %d, accuracy = %f' % (k, accuracy))