论文浅尝 | 知识图谱的神经符号推理(上)
笔记整理 | 叶橄强,浙江大学在读硕士,研究方向为知识图谱的表示学习和预训练。

知识图谱推理是支撑信息提取、信息检索和推荐等机器学习任务的基础组成部分,并且由于知识图可以看作知识的离散符号表示,自然可以利用符号技术做知识图谱推理任务。但是符号推理对模糊和噪声数据容忍度很低,在真正的应用中受到很多限制。而近年来,深度学习的繁荣促进了知识图谱神经推理的快速发展,它能很好地克服模糊和噪声数据带来的干扰因此具有较强的鲁棒性,但与符号推理相比缺乏解释能力。正因为两种方法各有优缺点,最近不少研究者将这两种推理方法结合起来进行了努力。该论文对符号推理、神经推理和混合推理在知识图上的发展进行了深入的研究,而本文的分享主要聚焦于神经符号混合推理的相关方法。
一、推理方法分类
推理通常有三种主要的组合方法。
(1)神经推理,又称知识图谱嵌入,其目的是学习知识图谱中实体和关系的分布嵌入向量,在给定头实体和关系的情况下,根据嵌入向量推断出答案实体。一般来说,现有的神经推理方法可分为基于翻译的模型、乘法模型和深度学习模型。
(2)符号推理,其目的是从知识图谱中推导出一般的逻辑规则,从给定的头实体派生的实体和遵循逻辑规则的查询关系作为答案返回。现有的符号推理方法主要是基于搜索的归纳逻辑程序设计(Inductive Logic Programming,ILP)方法,通常是对规则进行搜索和剪枝。
(3)神经符号推理,融合了神经推理和符号推理的优点的一种推理方法,在下文中详细阐述。
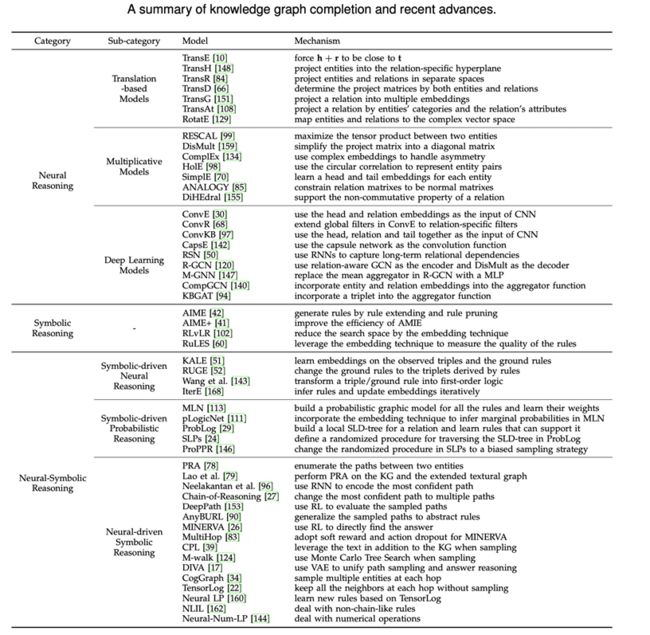
三种推理方法具体可以参考表1,其中囊括了这三种方法下的主要代表模型
表1 推理方法和知识图谱补全方法汇总
二、神经符号推理
本文的分享主要介绍神经符号推理部分。
神经推理和符号推理有各自的特征并有着显著不同的优缺点:符号推理擅长逻辑推理,具有很强的可解释性,但它很难处理实体和关系的不确定性以及自然语言的模糊性,即对数据噪声的抵抗能力较差;相反,神经网络具有很强的容错行,能够利用嵌入向量学习抽象语义,并通过符号表示来进一步比较和运算这些嵌入向量,而不只是实体和关系之间的字面意义。推理方向的最新进展结合了这两种推理方法,可以将这些研究成果归纳汇总为三种类别。
第一种是以神经推理为目标,利用逻辑规则改进神经推理的嵌入,称为符号驱动神经推理。
第二种是用概率框架代替神经推理,即建立一个概率模型来推断答案,其中逻辑规则被设计为概率模型中的特征,称为符号驱动概率推理。
第三种是通过符号推理来推理规则,但结合了神经网络来处理数据的不确定性和模糊性。这种方法减少了符号推理的搜索空间,称为神经驱动符号推理。
1.符号驱动神经推理
符号驱动神经推理的基本思想是不仅学习知识图谱中原始观察到的三元组上的实体和关系嵌入,而且学习根据一些预定义规则推断出的三元组或基本规则。
(1)KALE模型
KALE模型处理两种类型的规则:
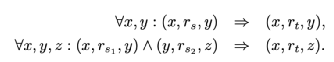
KALE模型找到上述两类规则的所有基本规则,为每个基本规则分配一个分数,表示满足基本规则的可能性,最后学习原始三元组和基本规则的训练集上的实体和关系嵌入。他们采用t-范数模糊逻辑,将规则的真值定义为通过特定的基于t-范数的逻辑连接词将其组成部分的真值组成,以计算基本规则f1的分数⇒ f2组件:
![]()
其中f表示一个原子即三元组,或由逻辑运算关联的多个原子组成的公式{∧, ∨, ¬}。如果上述公式中的f是一个三元组,则其得分由TransE方法计算;如果f是一个公式,则其分数被定义为其组成部分分数的组成:
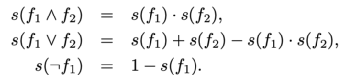
(2)RUGE模型
在KALE模型的基础上,研究人员进一步提出RUGE模型并将一轮规则注入变为迭代方式。RUGE没有直接将基本规则作为KALE的正实例,而是将一些规则派生的三元组作为未标记的三元组注入,以更新实体或者关系嵌入。由于未标记的三元组不一定是真的,研究人员根据当前的嵌入情况预测了每个未标记三元组的概率,然后根据标记的和未标记的三元组更新嵌入。初始规则由AMIE方法获得,这样就可以迭代地计算未标记的三元组评分过程和嵌入更新过程。
(3)Wang等人提出的模型
KALE模型和RUGE模型将规则或公式的分数计算为其组成部分的分数组成,这可能导致规则或公式的高分,即使其中的三元组完全不相关,因为三元组的分数是分开估计的。为了解决这个问题,Wang等人提出将一个三元组或一个基本规则转化为一阶逻辑,然后根据一阶逻辑中包含的实体和关系的嵌入,通过执行一些向量或者矩阵运算对一阶逻辑进行评分。

表2 一阶逻辑的格式
表2展示了一阶逻辑的格式,表3展示了如何用数学表达式对一阶逻辑进行评分。这样,包含在同一规则中的不同组件(即三元组)直接在向量空间中交互,这保证了规则及其编码格式都具有一对一的映射转换。

表3 一阶逻辑的数学表达式
(4)IterE模型
上述三种方法在学习过程中只推理一次规则,然后保持规则不变。因此规则会影响嵌入向量学习,但嵌入向量不利于规则的引用,因此引出IterE模型。
虽然IterE模型也在每次迭代中基于更新的嵌入推断出新的规则,但它具体地推断出新的规则,并从基于实体和关系嵌入的规则中导出新的三元组,然后基于扩展的三元组集更新这些嵌入向量。这两个过程是迭代执行的,新的置信规则是根据它们的分数推断出来的,分数是通过对规则中包含的关系的矩阵执行一些矩阵运算计算出来的。为了获得初始规则池,IterE模型提出了一种剪枝策略,其思想与AMIE方法相似,但结合了遍历和随机选择操作,以平衡潜在规则的搜索过程和高度可能规则的收敛。
2.符号驱动概率推理
符号驱动概率推理将一阶逻辑与概率图形模型相结合,在概率框架下学习逻辑规则的权重,从而有效地处理不确定性。这种方法通常是先将规则接地,即用知识图谱中的任何实体迭代替换规则原子中的变量,直到不能推导出新的事实或者新的三元组,然后将概率附加到基本规则上,从而限定逻辑规则。在某种意义上,逻辑规则的置信度和质量可以定义为预先构建的概率基础图上的概率分布,如图1所示。

图1 两个规则示例和对应的马尔可夫逻辑网络(虚线是与规则R1相关联的组件,实线是与规则R2相关联的组件,灰色节点是要推断的未观察到的三元组)
符号驱动概率推理设计概率模型来度量规则的置信度,而不是利用嵌入技术来限定规则。在这一节中,我们介绍了两种典型的概率模型,马尔科夫逻辑网络(和ProbLog来解释这类方法的特点,然后简要介绍了几种类似的方法。
(1)马尔科夫逻辑网络
马尔可夫逻辑网络(Markov Logic Network,MLN)是基于预先定义的规则和以知识图谱为单位的事实建立一个概率图形模型,然后学习不同规则的权重。具体来说,给定一组规则{γi} ,每个γi可以被知识图谱的三元组接地。然后根据这些基本规则,可以建立如下马尔可夫逻辑网络:
① 为每个基本规则中的每个基本原子建立一个节点,如果以知识图谱为单位观察,则该节点的值设置为1,否则设置为0。
② 当且仅当对应的两个基态原子可同时用于实例化至少一个规则时,在两个节点之间建立边。
③ 基本规则中的所有节点即基本原子,形成一个不一定是最大的组件,它对应于一个特征,如果基本规则为真,则值为1,否则为0;权重wi与每个规则γi相关联。
利用所建立的马尔可夫逻辑网络,将网络中所有节点的值X的联合分布定义为:
![]()
其中ni(x)是规则的真实基础数γi,而wi是规则对应的权重γi。然后将MCMC算法应用于马尔可夫逻辑网络中的推理,并通过优化伪似然测度有效地学习权值。
(2)pLogicNet模型
由于三元组间复杂的图形结构,马尔可夫逻辑网络的推理过程困难且效率低下。此外,知识图谱中缺失的三元组也会影响规则推理的结果。
由于最近的嵌入技术可以有效地预测丢失的三元组,并且可以用随机梯度进行有效的训练,pLogicNet模型提出将马尔可夫逻辑网络和图嵌入技术结合起来来解决上述问题。其基本思想是用马尔可夫逻辑网络定义三元组或者事实的联合分布,并将每个逻辑规则与一个权重相关联,但通过变分EM算法有效地学习它们。在该算法中,E-step推断未观测三元组的合理性,其中变分分布由知识图谱嵌入模型参数化,如TransE模型等,而M-step则通过对观察到的三元组和知识图谱嵌入模型推断出的三元组的伪似然进行优化来更新逻辑规则的权重。
(3)ProbLog模型
ProbLog模型是Prolog编程模型的概率扩展。与Prolog模型相比,ProbLog模型为每个子句ci增加了一个概率,它表示一个规则或一个基本原子。用于派生查询的子句示例,即查找满足居住于(LeBron,S)的所有实体e,如下所示:

给定一个查询q,三元组成功概率P(q | T)定义为:
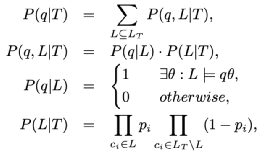
式中,T={p1:c1,…,pn:cn}表示原因L⊆ LT={c1,…cn}上的概率分布。第一个公式表示查询q的成功概率被分解为查询的所有联合概率和每个可能的原因集L的总和。第二个公式进一步将P(q,L | T)分解为P(q | L)和P(L | T)。P(q | L)表示给定原因集L的查询q的概率,如果至少有一个答案替换,则其值等于1。第四个公式解释了如何计算原因集L的概率。
为了计算成功概率P(q | L),一个简单的方法是枚举所有可能的逻辑规则L及其实例。显然,它在实际应用中效率很低。ProbLog模型根据Prolog的选择性线性定解(Selective Linear Definite,SLD)算法,为目标查询q构造了一个证明树,解决了这个问题。标准SLD解析以自顶向下的方式构造SLD树,如图2所示。它首先通过查询初始化根节点,然后通过应用每个子句及其实例化递归地创建子目标,当到达结束条件时迭代停止。例如子目标为空,这意味着找到了可能的答案路径或达到最大树深度。因此,每个可能的答案路径都与一组子句{p1:c1,…,pn:cn} ⊆ T关联。

图2 为查询构建的SLD树的示例
然后按照公式一到四,可以很容易地计算出单个答案路径的成功问题。进一步应用二元决策图(Binary Decision Diagram,BDD)计算多路径的成功概率。SLD树也是其他类似方法的基础,如随机逻辑程序模型(Stochastic Logic Programs, SLPs)和个性化PageRank编程模型(Programming with Personalized PageRank,ProPPR)。
(4)其他模型
马尔可夫逻辑网络和ProbLog模型都学习规则的概率,马尔可夫逻辑网络为所有规则建立全局概率图同时学习所有规则的概率,而ProbLog模型为每个查询构建了一个本地SLD树,并学习了支持目标查询的原因的问题能力。其他类似方法,例如概率数据日志(probabilistic Datalog),MarkoViews模型,随机逻辑程序模型(SLPs),也将概率附加到子句,但在更新这些概率时具有不同的优化框架。例如,随机逻辑程序模型定义了一个随机的遍历SLD树的过程,在这个过程中,通过向上加权所需的应答子句并向下加权其他子句来学习节点上定义的概率分布。使用个性化PageRank编程模型(ProPPR)是SLP模型的一个扩展,它将随机抽样更改为基于个性化PageRank模型(Personalized PageRank,PPR)的策略。他们使用PPR模型根据一些预先定义的特征计算每个子句的概率,而不是直接在公式四中设置概率。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。