【DeepMind】新算法MuZero在Atari基准上取得了新SOTA效果,成果问鼎Nature
深度强化学习实验室
来源:AI科技评论
作者: 陈彩娴、青暮
编辑:DeepRL

近日,DeepMind一篇关于MuZero的论文“Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model”在Nature发表。与AlphaZero相比,MuZero多了玩Atari的功能,这一突破进展引起科研人员的广泛关注。

MuZero通过DQN算法,仅使用像素和游戏分数作为输入就可以在Atari视频游戏中达到人类的水平。相对于围棋、国际象棋、日本将棋,Atari游戏的规则与动态变化未知且复杂。
AlphaGo在2016年的围棋比赛中以4-1击败了围棋世界冠军李世石;AlphaGo Zero,可以从零通过自我对弈训练,仅在知道基本游戏规则的情况下,第二年在性能上超过了AlphaGo;AlphaZero于2017年通过对AlphaGo Zero进行一般化,可以将其应用于其他游戏,包括国际象棋和日本将棋。
而据Nature报道,尽管每步进行的树搜索计算量较少,但MuZero在玩围棋方面被证明比AlphaZero稍好。
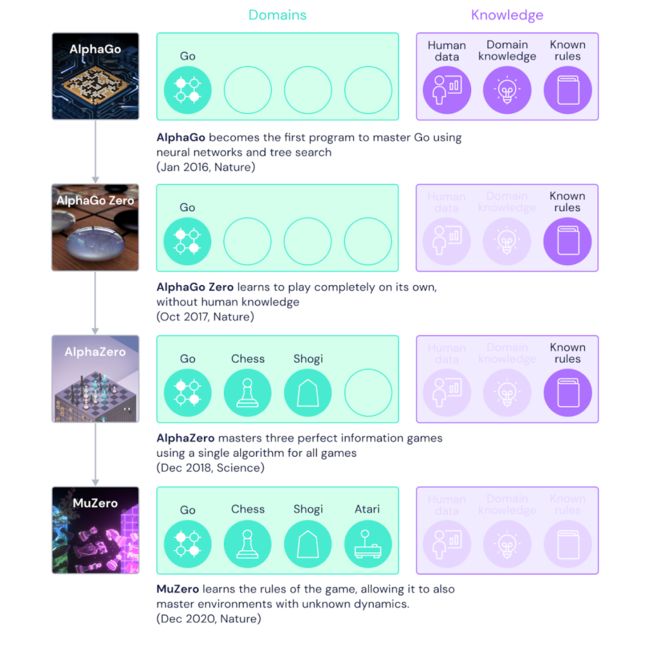 图注:DeepMind游戏AI的进化。
图注:DeepMind游戏AI的进化。
以研究AI打扑克出名的FAIR研究科学家Noam Brown对MuZero评价道:
当前人们对游戏AI的主要批评是:模型不能对现实世界中相互作用进行准确建模。MuZero优雅而令人信服地克服了这个问题(适用于完美信息游戏)。我认为,这是可以与AlphaGo和AlphaZero相提并论的重大突破!


David Silver在接受BBC的采访中提到,MuZero已经投入实际使用,用于寻找一种新的视频编码方式,从而实现视频压缩。“互联网上的数据大部分是视频,那么如果可以更有效地压缩视频,则可以节省大量资金。”由于谷歌拥有世界上最大的视频共享平台YouTube,因此他们很可能将MuZero其应用到该平台上。
现实世界混乱而复杂,没有人给我们提供有关其运作方式的规则手册。但是人类有能力制定下一步的计划和策略。我们第一次真正拥有了这样的系统,能够建立自己对世界运作方式的理解,并利用这种理解来进行这种复杂的预见性规划,我们以前也在AlphaZero上实现过类似的能力。MuZero可以从零开始,仅通过反复试验就可以发现世界规则,并使用这些规则来实现超人的表现。

1
关于MuZero
一直以来,构建具有规划能力的智能体是人工智能领域的主要挑战之一。此前,基于树的规划方法在国际象棋与围棋等领域取得了巨大的成功。然而,在现实世界中,控制环境的动态变化(dynamics)通常是复杂且不可知的。
因此,DeepMind团队提出了MuZero算法,通过将基于树的搜索与经过学习的模型相结合,可以在一系列具有挑战性和视觉复杂的领域中,无需了解基本的动态变化即可实现超越人类的出色性能。
MuZero算法学习可迭代模型,该模型能够产生与规划相关的预测,包括动作选择策略、价值函数和奖励。在57种不同的Atari游戏上进行评估时,MuZero算法获得了最先进的性能。
Atari游戏是用于测试人工智能技术的规范视频游戏环境,其中,此前基于模型的规划方法均无效。而在围棋、国际象棋和日本将棋(用于评估高性能计划的典型环境)上进行评估时,MuZero算法在无需任何游戏动态的相关知识,就能与游戏规则完全匹配。
 论文地址:https://arxiv.org/pdf/1911.08265.pdf
论文地址:https://arxiv.org/pdf/1911.08265.pdf
在正式推出MuZero之前,DeepMind已在探索智能算法上取得了多项显著成就:2016年,DeepMind推出了第一个能在围棋游戏中击败人类的AI程序——AlphaGo。2018年,AlphaGo的继承者AlphaZero从零开始学习并掌握了围棋、国际象棋和日本将棋。而MuZero的推出,是DeepMind探索多功能算法的又一突破。
MuZero由DeepMind团队于2019年初步提出,能够在未知环境中规划获胜策略,因此,它也无需提前了解规则,即可掌握围棋、国际象棋、日本将棋与Atari的相关知识。
多年来,研究人员一直在寻找既可以学习能够解释环境的模型,又可以使用该模型来规划最佳行动方案的方法。然而,到目前为止,大多数方法都难以在Atari等规则与动态变化均未知且复杂的领域进行有效规划。
与其他方法不同的是,MuZero通过学习仅关注规划环境中最关键因素的模型来解决该问题。
通过将模型与AlphaZero的树搜索功能相结合,MuZero在Atari基准上取得了最新的技术优势,同时在围棋、国际象棋和日本将棋的经典规划挑战中与AlphaZero的性能不相上下,展示了强化学习算法的快速飞跃。
先前,研究人员通过前向搜索与基于模型的规划等两种方法来提高AI的规划能力。
使用前向搜索的系统(例如AlphaZero)在跳棋、国际象棋和扑克等经典游戏中取得了显著成功,但这类系统之所以取胜,是因为有事先了解游戏环境的动态变化知识,比如游戏规则或配备了精确的模拟器。显然,这一类系统很难应用于解决混乱的现实问题,因为现实世界的问题通常很复杂,很难用简单的三两句规则去概括。
基于模型的系统则旨在通过学习环境动态的精确模型,然后使用模型进行规划。但是,对环境的各个方面进行建模非常复杂,导致算法无法在视觉丰富的领域(例如Atari)中竞争。截至目前为止,在Atari上取得最好结果的是无模型系统,例如DQN,R2D2和Agent57。无模型算法不使用经过学习的模型,而是通过预测来采取最佳的下一步措施。
鉴于其他方法的局限性,MuZero没有尝试对整个环境建模,而只是对智能体进行决策过程中至关重要的方面进行建模。毕竟,如果在下雨的环境,知道打伞避雨比对空气中的雨滴行为进行建模更有用。
具体来说,MuZero对三个环境要素进行建模(这三个要素对于规划非常重要):
价值:当前处境的好坏程度
策略:所能采取的最佳行动
奖励:最后一个动作的好坏程度
这三个要素都是使用深度神经网络来学习,也是MuZero在采取特定行动时考虑后果与做出相应规划所需要知道的全部内容。
 图注:如何使用Monte Carlo树搜索与Muzero神经网络进行规划。Muzero从游戏的当前位置开始(动画顶部的示意图),使用表示功能(H)将观察内容映射到神经网络使用的嵌入(S0)。此外,Muzero使用动态函数(G)和预测函数(F)来考虑下一步要采取的动作序列(A),并选择最佳动作。
图注:如何使用Monte Carlo树搜索与Muzero神经网络进行规划。Muzero从游戏的当前位置开始(动画顶部的示意图),使用表示功能(H)将观察内容映射到神经网络使用的嵌入(S0)。此外,Muzero使用动态函数(G)和预测函数(F)来考虑下一步要采取的动作序列(A),并选择最佳动作。
 图注:MuZero使用其在与环境互动时所收集的经验训练神经网络。这类经验包括对环境的观察和奖励,以及在决定最佳行动时进行的搜索结果。
图注:MuZero使用其在与环境互动时所收集的经验训练神经网络。这类经验包括对环境的观察和奖励,以及在决定最佳行动时进行的搜索结果。
 图注:在训练过程中,模型与所收集的经验一同被取消,在每个步骤中预测先前保存的信息:价值函数V预测所观察到的奖励之和(U),策略估计(P)预测之前所进行的搜索,奖励估计R则预测最后观察到的奖励(U)。
图注:在训练过程中,模型与所收集的经验一同被取消,在每个步骤中预测先前保存的信息:价值函数V预测所观察到的奖励之和(U),策略估计(P)预测之前所进行的搜索,奖励估计R则预测最后观察到的奖励(U)。
这个方法的另一个优点是:MuZero可以反复使用其学习的模型来改进自己的规划,而不是从环境中收集新数据。比方说,在Atari suite的测试中,被称为MuZero Reanalyze的变体在90%的时间里使用学习的模型来重新规划先前episode中应该做但没有做的事情。
2
Muzero的性能
研究者选择了四个不同的任务来测试MuZeros的能力,分别是围棋、国际象棋、日本将棋和Atari套件(Atari suite),其中前三者被用来评估MuZero在挑战性规划问题上的表现,Atari套件则作为视觉上更复杂问题的基准。
在所有任务中,MuZero以强化学习算法达到了新的SOTA,其性能优于Atari套件上的所有先前的算法,并且也达到了与AlphaZero相当的在围棋、国际象棋和日本将棋上的超人性能。
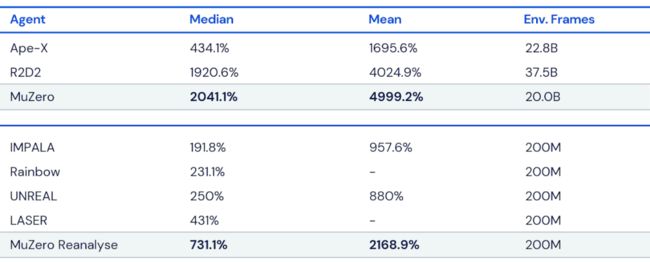 图注:在训练中分别使用2亿帧或200亿帧的MuZero在Atari套件上的性能。MuZero在两个方面都实现了新的SOTA。所有得分均根据人类测试的性能(100%)进行了归一化,每个实验设置的最佳结果以粗体显示。
图注:在训练中分别使用2亿帧或200亿帧的MuZero在Atari套件上的性能。MuZero在两个方面都实现了新的SOTA。所有得分均根据人类测试的性能(100%)进行了归一化,每个实验设置的最佳结果以粗体显示。
研究者还详细测试了MuZero利用其学习的模型进行规划的能力。他们从围棋中经典的精密规划挑战开始,在此挑战中,单步行动可能决定着获胜或失败。
为了验证更多的规划会带来更好的结果这一直觉,研究者对这个问题进行了测试:如果有更多的时间来规划每次行动,那么经过全面训练的MuZero是否可以变得更强大(如下左图所示)?
结果表明,随着将每次行动的时间从十分之一秒增加到50秒,MuZero的能力会增加1000 Elo(衡量玩家的相对技能),这基本相当于熟练的业余玩家和最强的职业玩家之间的区别。
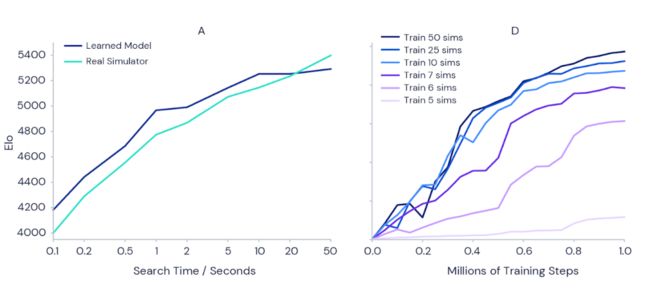 图注:(左)随着规划每次动作的时间的增加,MuZero的围棋能力显着增加。注意MuZero的缩放比例几乎完美地匹配了可以访问完美模拟器的AlphaZero。(右)在训练期间,Atari Games Pac-Man的得分也随着每次行动的规划量而增加。图中每条曲线都显示了一个不同设置的训练运行,MuZero允许考虑每次行动的规划数量不同。
图注:(左)随着规划每次动作的时间的增加,MuZero的围棋能力显着增加。注意MuZero的缩放比例几乎完美地匹配了可以访问完美模拟器的AlphaZero。(右)在训练期间,Atari Games Pac-Man的得分也随着每次行动的规划量而增加。图中每条曲线都显示了一个不同设置的训练运行,MuZero允许考虑每次行动的规划数量不同。
为了测试这种规划设置是否还会在整个训练过程中带来好处,研究者使用单独训练的MuZero实例在Atari游戏Ms Pac-Man上进行了一组实验(如上右图所示)。MuZero允许在每个动作中考虑不同数量的规划,范围从5到50。结果证实,增加每个动作的规划数量可使MuZero更快地学习并获得更好的最终性能。
有趣的是,当MuZero仅允许每步进行6或7次规划时(这个数字太小而无法覆盖Ms Pac-Man的所有可用动作),它仍然取得了良好的性能。这表明MuZero能够在行动和环境状态之间的匹配上进行泛化,而无需详尽搜索所有可能的状态以有效学习。
DeepMind表示,MuZero展示了学习环境模型并成功进行规划的能力,证明了强化学习的重大进步。MuZero的前身AlphaZero已被应用于化学、量子物理学等领域的一系列复杂问题。MuZero强大的学习和规划算法背后的思想可能为应对机器人、工业系统和其他复杂多样的“游戏规则”未知的现实世界中的新挑战铺平道路。
参考链接:
1、https://www.deepmind.com/blog/article/muzero-mastering-go-chess-shogi-and-atari-without-rules
2、https://www.nature.com/articles/s41586-020-03051-4
3、http://www.furidamu.org/blog/2020/12/22/muzero-intuition/
4、https://arxiv.org/abs/1911.08265
5、https://www.bbc.com/news/technology-55403473
6、MuZero的伪代码和解释:https://medium.com/applied-data-science/how-to-build-your-own-deepmind-muzero-in-python-part-3-3-ccea6b03538b
完
总结1:周志华 || AI领域如何做研究-写高水平论文
总结2:全网首发最全深度强化学习资料(永更)
总结3: 《强化学习导论》代码/习题答案大全
总结4:30+个必知的《人工智能》会议清单
总结5:2019年-57篇深度强化学习文章汇总
总结6: 万字总结 || 强化学习之路
总结7:万字总结 || 多智能体强化学习(MARL)大总结
总结8:深度强化学习理论、模型及编码调参技巧
完
第91篇:详解用TD3算法通关BipedalWalker环境
第90篇:Top-K Off-Policy RL论文复现
第89篇:腾讯开源分布式多智能TLeague框架
第88篇:分层强化学习(HRL)全面总结
第87篇:165篇CoRL2020 accept论文汇总
第86篇:287篇ICLR2021深度强化学习论文汇总
第85篇:279页总结"基于模型的强化学习方法"
第84篇:阿里强化学习领域研究助理/实习生招聘
第83篇:180篇NIPS2020顶会强化学习论文
第82篇:强化学习需要批归一化(Batch Norm)吗?
第81篇:《综述》多智能体强化学习算法理论研究
第80篇:强化学习《奖励函数设计》详细解读
第79篇: 诺亚方舟开源高性能强化学习库“刑天”
第78篇:强化学习如何tradeoff"探索"和"利用"?
第77篇:深度强化学习工程师/研究员面试指南
第76篇:DAI2020 自动驾驶挑战赛(强化学习)
第75篇:Distributional Soft Actor-Critic算法
第74篇:【中文公益公开课】RLChina2020
第73篇:Tensorflow2.0实现29种深度强化学习算法
第72篇:【万字长文】解决强化学习"稀疏奖励"
第71篇:【公开课】高级强化学习专题
第70篇:DeepMind发布"离线强化学习基准“
第69篇:深度强化学习【Seaborn】绘图方法
第68篇:【DeepMind】多智能体学习231页PPT
第67篇:126篇ICML2020会议"强化学习"论文汇总
第66篇:分布式强化学习框架Acme,并行性加强
第65篇:DQN系列(3): 优先级经验回放(PER)
第64篇:UC Berkeley开源RAD来改进强化学习算法
第63篇:华为诺亚方舟招聘 || 强化学习研究实习生
第62篇:ICLR2020- 106篇深度强化学习顶会论文
第61篇:David Sliver 亲自讲解AlphaGo、Zero
第60篇:滴滴主办强化学习挑战赛:KDD Cup-2020
第59篇:Agent57在所有经典Atari 游戏中吊打人类
第58篇:清华开源「天授」强化学习平台
第57篇:Google发布"强化学习"框架"SEED RL"
第56篇:RL教父Sutton实现强人工智能算法的难易
第55篇:内推 || 阿里2020年强化学习实习生招聘
第54篇:顶会 || 65篇"IJCAI"深度强化学习论文
第53篇:TRPO/PPO提出者John Schulman谈科研
第52篇:《强化学习》可复现性和稳健性,如何解决?
第51篇:强化学习和最优控制的《十个关键点》
第50篇:微软全球深度强化学习开源项目开放申请
第49篇:DeepMind发布强化学习库 RLax
第48篇:AlphaStar过程详解笔记
第47篇:Exploration-Exploitation难题解决方法
第46篇:DQN系列(2): Double DQN 算法
第45篇:DQN系列(1): Double Q-learning
第44篇:科研界最全工具汇总
第43篇:起死回生|| 如何rebuttal顶会学术论文?
第42篇:深度强化学习入门到精通资料综述
第41篇:顶会征稿 || ICAPS2020: DeepRL
第40篇:实习生招聘 || 华为诺亚方舟实验室
第39篇:滴滴实习生|| 深度强化学习方向
第38篇:AAAI-2020 || 52篇深度强化学习论文
第37篇:Call For Papers# IJCNN2020-DeepRL
第36篇:复现"深度强化学习"论文的经验之谈
第35篇:α-Rank算法之DeepMind及Huawei改进
第34篇:从Paper到Coding, DRL挑战34类游戏
第33篇:DeepMind-102页深度强化学习PPT
第32篇:腾讯AI Lab强化学习招聘(正式/实习)
第31篇:强化学习,路在何方?
第30篇:强化学习的三种范例
第29篇:框架ES-MAML:进化策略的元学习方法
第28篇:138页“策略优化”PPT--Pieter Abbeel
第27篇:迁移学习在强化学习中的应用及最新进展
第26篇:深入理解Hindsight Experience Replay
第25篇:10项【深度强化学习】赛事汇总
第24篇:DRL实验中到底需要多少个随机种子?
第23篇:142页"ICML会议"强化学习笔记
第22篇:通过深度强化学习实现通用量子控制
第21篇:《深度强化学习》面试题汇总
第20篇:《深度强化学习》招聘汇总(13家企业)
第19篇:解决反馈稀疏问题之HER原理与代码实现
第18篇:"DeepRacer" —顶级深度强化学习挑战赛
第17篇:AI Paper | 几个实用工具推荐
第16篇:AI领域:如何做优秀研究并写高水平论文?
第15篇:DeepMind开源三大新框架!
第14篇:61篇NIPS2019DeepRL论文及部分解读
第13篇:OpenSpiel(28种DRL环境+24种DRL算法)
第12篇:模块化和快速原型设计Huskarl DRL框架
第11篇:DRL在Unity自行车环境中配置与实践
第10篇:解读72篇DeepMind深度强化学习论文
第9篇:《AutoML》:一份自动化调参的指导
第8篇:ReinforceJS库(动态展示DP、TD、DQN)
第7篇:10年NIPS顶会DRL论文(100多篇)汇总
第6篇:ICML2019-深度强化学习文章汇总
第5篇:深度强化学习在阿里巴巴的技术演进
第4篇:深度强化学习十大原则
第3篇:“超参数”自动化设置方法---DeepHyper
第2篇:深度强化学习的加速方法
第1篇:深入浅出解读"多巴胺(Dopamine)论文"、环境配置和实例分析
