初入爬虫学习之糗事百科爬虫
查看向百度网址发送请求对应的请求头
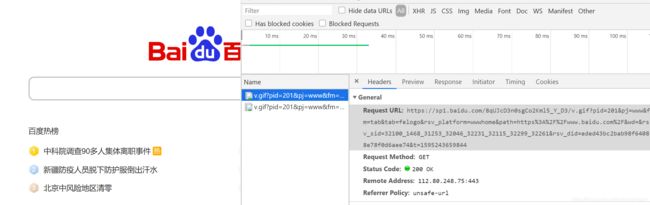 其中Remote Address记录远程百度服务器的主机地址
其中Remote Address记录远程百度服务器的主机地址
返回的数据为response,在浏览器中的Response中可以查看到相应的内容(返回的内容为html+css+javascript)
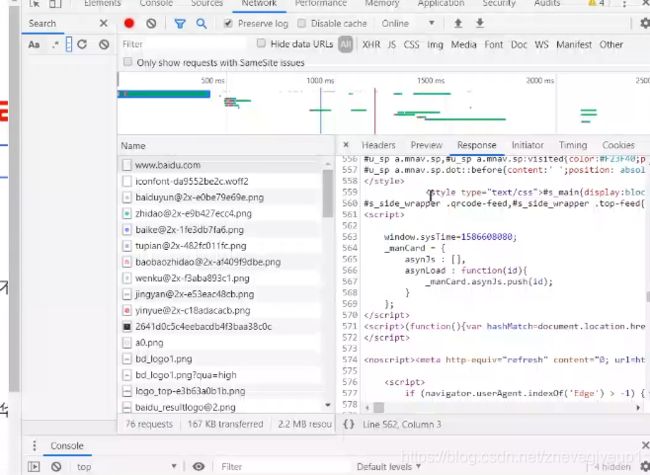
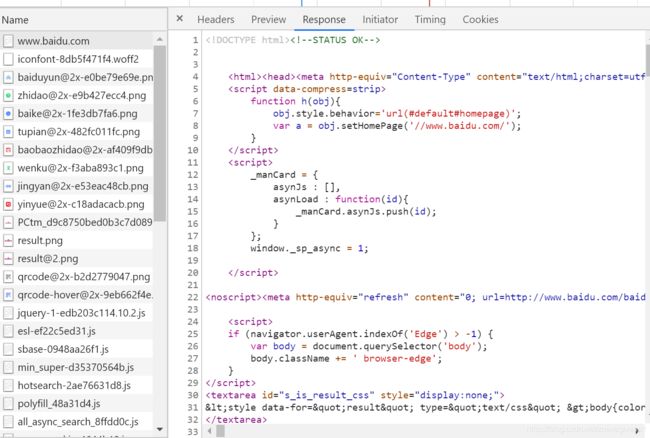
浏览器的作用:发送请求,接受相应结果并返回页面,get没有请求体,post才有请求体。
爬虫使用python语言编写一个应用程序:“替代浏览器发请求,接受响应”
关注重要的内容user-agent
 (1)发送请求:
(1)发送请求:
url = 'https://www.baidu.com/'#请求的方式为get,所以对应选择request的get方法
resp = requests.get(url)#resp就是响应结果
print(resp)
#返回的码为200,说明响应结果正常,200表示成功,418表示遇到反爬
print(resp.request.headers)
#返回的头部为一个python-requests表示返回的为一个爬虫
![]() 将headers改为具体的User-Agent,从浏览器中查看具体的User-Agent
将headers改为具体的User-Agent,从浏览器中查看具体的User-Agent

import requests
url = 'https://www.baidu.com/'#请求的方式为get,所以对应选择request的get方法
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'}
#为什么要写headers?因为是反爬的一种手段,伪装成浏览器
resp = requests.get(url,headers = headers)#resp就是响应结果
print(resp)
#返回的码为200,说明响应结果正常,200表示成功,418表示遇到反爬
print(resp.request.headers)
#返回的头部为一个python-requests表示返回的为一个爬虫
print(resp.text)
#返回服务器给你响应回来的数据
![]() 此时如果遇到简单的反爬就爬不到你,它认为你写得程序就是一个正常的人为的访问服务器的工作。
此时如果遇到简单的反爬就爬不到你,它认为你写得程序就是一个正常的人为的访问服务器的工作。
打开糗事百科中的video(视频内容)进行查看


import re为导入一个需要正则的模块
import requests
import re
url = 'https://www.qiushibaike.com/video/'#请求的方式为get,所以对应选择request的get方法
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'}
#为什么要写headers?因为是反爬的一种手段,伪装成浏览器
resp = requests.get(url,headers = headers)#resp就是响应结果
#第一个参数为匹配的规则,第二个参数为
info = re.findall(r'' ,resp.text)
#.为任意字符,*为任意个,小括号的意思是只要小括号里面的内容
#此时没有拿到任意东西
print(info)
修改代码之后再次进行爬虫
import requests
import re
url = 'https://www.qiushibaike.com/video/'#请求的方式为get,所以对应选择request的get方法
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'}
#为什么要写headers?因为是反爬的一种手段,伪装成浏览器
resp = requests.get(url,headers = headers)#resp就是响应结果
#第一个参数为匹配的规则,第二个参数为
#info = re.findall(r'',resp.text)
#.为任意字符,*为任意个,小括号的意思是只要小括号里面的内容
#此时没有拿到任意东西
info = re.findall(r' 爬取出来的数据不能直接进行使用,因为前面少了一个https,每次爬取之后前面加上https之后运行程序
爬取出来的数据不能直接进行使用,因为前面少了一个https,每次爬取之后前面加上https之后运行程序
在当前文件夹下建立video文件,然后打开对视频进行下载
import requests
import re
url = 'https://www.qiushibaike.com/video/'#请求的方式为get,所以对应选择request的get方法
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'}
#为什么要写headers?因为是反爬的一种手段,伪装成浏览器
resp = requests.get(url,headers = headers)#resp就是响应结果
info = re.findall(r'运行完之后,视频就可以下载成功了
如果是对于糗事百科文本的提取,首先需要分析糗事百科上面笑话文本的标签结构
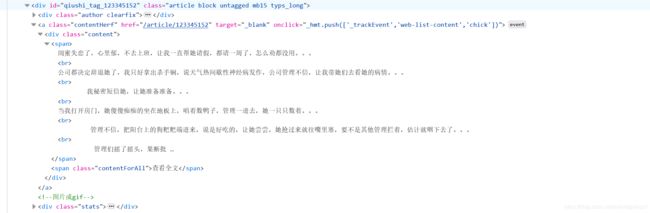 可以看出首先进入一个
可以看出首先进入一个
<div id="qiushi_tag_123345152" class="article block untagged mb15 typs_long">
的标签之中,然后到了
<div class="content">
的内容之后显示笑话中的具体内容,深入观察之后发现后面的class里面的内容还有可能为
“article block untagged mb15 typs_hot”
所以我们需要将这两个class标签中的内容都包含进去。
import requests
from bs4 import BeautifulSoup
r = requests.get('https://www.qiushibaike.com/text/')
content = r.text
soup = BeautifulSoup(r.text, 'lxml')
divs = soup.find_all(class_ = 'article block untagged mb15 typs_long')+soup.find_all(class_ = 'article block untagged mb15 typs_hot')
#共通点是class里面包含两个部分,所以将两个部分都放置进去
for div in divs:
#if div.find_all(class_ = 'thumb'):
# continue
joke = div.span.get_text()
#将divs中的每个div都取出来,把其中的span标签的文字放进joke中并打印出来
print(joke)
print('------')