第4章 数据可视化答案
目录
P70思考与练习1
【老书第一版此题】
P84思考与练习2
方法一:使用Basemap绘制地图
方法二:使用Pyecharts绘制地图
P86综合练习题
本书中所有的数据文件保存在data文件夹中,链接如下:
https://pan.baidu.com/s/1Tu__B-YfXDz_yXzbzNKB4A?pwd=sfw2
提取码:sfw2
P70思考与练习1
1.叙述Pandas和Matplotlib绘图工具之间的关系。如何在绘图中综合使用两种工具的绘图函数,达到既快速绘图又可精细化设置图元的目标。
1.pandas封装了Matplotlib的主要绘图功能。pandas基于Series与DataFrame绘图,使用Series与DataFrame封装数据,调Series.plot()或DataFrame.plot()完成绘图。pandas绘图简单直接,若要更细致地控制图标样式,如添加标注、在一幅图中包含多副子图,必须使用Matplotlib提供的基础函数。Matplotlib中使用pyplot的图元设置函数来实现图形的精细化设置,能够对pandas绘出的图形进行精细化设置。
我们可以先将数据封装成Series或DataFrame,通过Pandas快速绘图,最后再通过Matplotlib中的pyplot图元设置函数对图形进一步精细化设置,达到精细化绘图的目的。
2. 2012~2020年我国人均可支配收入为[1.47, 1.62, 1.78, 1.94, 2.38, 2.60,2.82,3.07,3.21](单位:万元)。按照要求绘制以下图形。
1)模仿例4-1和4-3,绘制人均可支配收入折线图。用小矩形标记数据点,黑色虚线,用注解标注最高点,图例标题“Income ”,设置坐标轴标题,最后将图形保存为jpg文件。
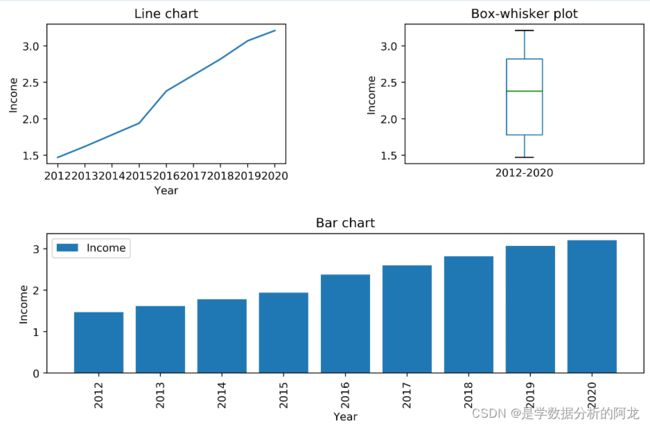
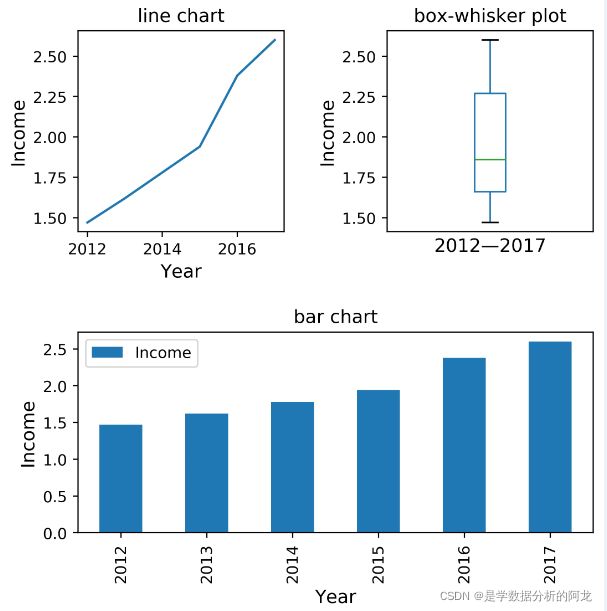
2)模仿例4-2,使用多个子图分别绘制人均可支配收入的折线图、箱形图以及柱状图(效果如下图所示)。
【提示】:
(1)本实验准备数据时可使用Series对象或DataFrame对象。
(2)创建3个子图分别使用(2,2,1)、(2,2,2)和(2,1,2)作为参数。
(3)使用plt.subplots_adjust()函数调整子图间距离,以便添加图标题。
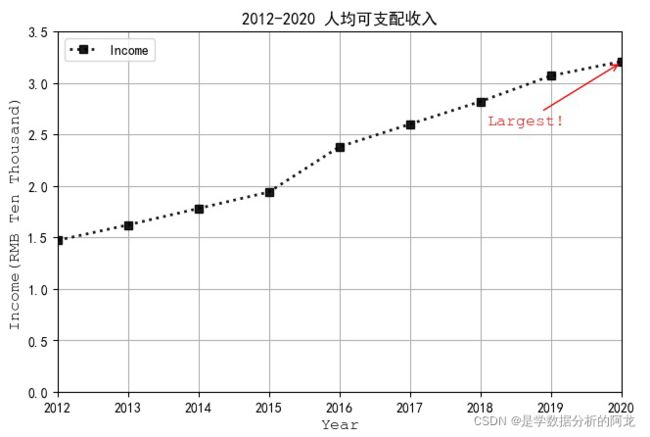

新书第二版要求的画图效果
第(1)题:
共列举以下三种方法
【方法一】:使用Series.plot画图,数据为Series形式
【方法二】:使用DataFrame.plot画图,数据为DataFrame形式
【方法三】:使用plt.plot函数画图(默认kind='line‘,画折线图),数据为列表形式
#方法一:Series.plot
import matplotlib.pyplot as plt
from pandas import Series
Income_data = Series([1.47, 1.62, 1.78, 1.94, 2.38, 2.60,2.82,3.07,3.21],index = ['2012','2013','2014','2015','2016','2017','2018','2019','2020'])
Income_data.plot(title = '2012-2020 年人均可支配收入',marker = 's',linestyle = 'dotted',grid = True,label = 'Income',
yticks = [0.0,0.5,1.0,1.5,2.0,2.5,3.0,3.5],c = 'black') #label代表图例,c代表线、点的颜色
plt.xlabel('Year') #添加x轴标题
plt.ylabel('Income(RMB Ten Thousand)') #添加y轴标题
plt.legend() #显示图例,若无则不显示
plt.annotate('Largest!',xy = (8,3.21),xytext = (6.1,2.6),arrowprops = dict(arrowstyle = '->',color = 'r'),color = 'r') #xy为箭头位置坐标,xytext为文字起点位置
plt.show()
#方法二:DataFrame.plot
import matplotlib.pyplot as plt
from pandas import DataFrame
#DataFrame1中columns即为图例,index即为横坐标值
Income_data = DataFrame([1.47, 1.62, 1.78, 1.94, 2.38, 2.60,2.82,3.07,3.21],index = ['2012','2013','2014','2015','2016','2017','2018','2019','2020'],columns = ['Income'])
Income_data.plot(title = '2012-2020 年人均可支配收入',marker = 's',linestyle = 'dotted',grid = True,
yticks = [0.0,0.5,1.0,1.5,2.0,2.5,3.0,3.5],c = 'black')
plt.xlabel('Year')
plt.ylabel('Income(RMB Ten Thousand)')
plt.annotate('Largest!',xy = (8,3.21),xytext = (6.1,2.6),arrowprops = dict(arrowstyle = '->',color = 'r'),color = 'r')
plt.show()
#方法三:plt.plot
import matplotlib.pyplot as plt
Income_data = [1.47, 1.62, 1.78, 1.94, 2.38, 2.60,2.82,3.07,3.21]
plt.plot(['2012','2013','2014','2015','2016','2017','2018','2019','2020'],[1.47, 1.62, 1.78, 1.94, 2.38, 2.60,2.82,3.07,3.21],marker = 's',
linestyle = 'dotted',c = 'black',label = 'Income')
plt.title('2012-2020 年人均可支配收入')
plt.yticks([0.0,0.5,1.0,1.5,2.0,2.5,3.0,3.5])
plt.xlim(0,8) #设置x轴刻度范围
plt.xlabel('Year')
plt.ylabel('Income(RMB Ten Thousand)')
plt.annotate('Largest!',xy = (8,3.21),xytext = (6.1,2.6),arrowprops = dict(arrowstyle = '->',color = 'r'),color = 'r')
plt.legend()
plt.grid() #显示网格线结果如下:
第(2)题:
共列举以下6种方法
可采用figure.add_subplot()函数或plt.subplot()两种函数创建子图。而数据形式分别为Series、DataFrame与列表三种形式。由此列举6种方法求解。
前三种方法采用figure.add_subplot()函数
【方法一】:采用figure.add_subplot()函数创建子图。使用Series.plot画图,数据为Series形式。
【方法二】:采用figure.add_subplot()函数创建子图。使用DataFrame.plot画图,数据为DataFrame形式。
【方法三】:采用figure.add_subplot()函数创建子图。使用各类画图函数画图(plt.plot()画折线图,plt.boxplot()画箱形图,plt.bar()画柱状图),数据为列表形式。
后三种方法采用plt.subplot()函数
【方法四】:采用plt.subplot()函数创建子图。使用Series.plot绘图,数据为Series形式。
【方法五】:采用plt.subplot()函数创建子图。使用DataFrame.plot画图,数据为DataFrame形式。
【方法六】:采用plt.subplot()函数创建子图。使用各类画图函数画图(plt.plot()画折线图,plt.boxplot()画箱形图,plt.bar()画柱状图),数据为列表形式。
前三种方法(采用figure.add_subplot()函数):
先定义画布:fig = plt.figure(figsize = ())
再创建子图:fig.add_subplot()或者ax1... = fig.add_subplot()
对于Series与列表类型的数据:可不返回ax=ax1,ax=ax2,ax=ax3....。(也可返回)
对于DataFrame类型的数据:写为ax1(ax2、ax3...) = fig.add_subplot(),每次画图在画图函数里都要返回ax=ax1,ax=ax2,ax=ax3....。例如DataFrame.plot(...,ax = ax1)等,否则画图出错。
#方法一:采用figure.add_subplot()函数创建子图。使用Series.plot画图,数据为Series形式
import matplotlib.pyplot as plt
from pandas import Series
Income_data =Series([1.47, 1.62, 1.78, 1.94, 2.38, 2.60,2.82,3.07,3.21],index = ['2012','2013','2014','2015','2016','2017','2018','2019','2020'])
fig = plt.figure(figsize = (10,6)) #figure创建绘图对象,figsize设置画布尺寸
#将绘图区域分为2行2列4份,在第1份上作图
ax1 = fig.add_subplot(2,2,1)
#绘制折线图
ax1.plot(Income_data) #采用AxesSubplot绘制折线图
plt.title('Line chart')
plt.xlabel('Year')
plt.ylabel('Incone')
'''
还可采用Series.plot()函数绘制折线图:
Income_data.plot(title = 'Line chart') #采用Series.plot画折线图
plt.xticks(range(0,9),['2012','2013','2014','2015','2016','2017','2018','2019','2020']) #让x轴刻度显示全
plt.xlim(-0.5,8.5) #增大x轴刻度范围
plt.xlabel('Year')
plt.ylabel('Income')
'''
#将绘图区域分为2行2列4份,在第2份上作图
ax2 = fig.add_subplot(2,2,2) #也可去掉"ax2="写为fig.add_subplot(2,2,2)
#绘制箱形图
Income_data.plot(kind = 'box',title = 'Box-whisker plot')
plt.xlabel('2012-2020')
plt.ylabel('Income')
plt.xticks([])
#将绘图区域分为2行1列2份,在第2份作图
ax3 = fig.add_subplot(2,1,2) #也可去掉"ax3="写为fig.add_subplot(2,1,2)
#绘制柱状图
Income_data.plot(kind = 'bar',label = 'Income')
plt.title('Bar chart')
plt.xlabel('Year')
plt.ylabel('Income')
plt.legend() #显示图例
#调整子图间距离
plt.subplots_adjust(wspace = 0.5,hspace = 0.5)
#方法二:采用figure.add_subplot()函数创建子图。使用DataFrame.plot画图,数据为DataFrame形式,需返回ax=ax1,ax=ax2,ax=ax3
import matplotlib.pyplot as plt
from pandas import DataFrame
Income_data =DataFrame([1.47, 1.62, 1.78, 1.94, 2.38, 2.60,2.82,3.07,3.21],index = ['2012','2013','2014','2015','2016','2017','2018','2019','2020'],
columns = ['Income'])
fig = plt.figure(figsize = (10,6))
#画折线图
ax1 = fig.add_subplot(221) #(2,2,1)可连写(221)
Income_data.plot(title = 'Line chart',legend = False,ax = ax1) #返回ax1 #legend = False去掉图例
plt.xticks(range(0,9),['2012','2013','2014','2015','2016','2017','2018','2019','2020']) #让x轴刻度显示全
plt.xlim(-0.5,8.5) #增大x轴刻度范围
plt.xlabel('Year')
plt.ylabel('Income')
#画箱形图
ax2 = fig.add_subplot(222)
Income_data.plot(kind = 'box',title = 'Box-whisker plot',xticks = [],ax = ax2) #返回ax2
plt.xlabel('2012-2020')
plt.ylabel('Income')
#画柱状图
ax3 = fig.add_subplot(212)
Income_data.plot(kind = 'bar',title = 'Bar chart',ax = ax3) #返回ax3
plt.xlabel('Year')
plt.ylabel('Income')
#调间距
plt.subplots_adjust(wspace = 0.5,hspace = 0.5)
plt.savefig('Income222.jpg',dpi = 400,bbox_inches = 'tight') #保存导出图像
plt.show()
#方法三:采用figure.add_subplot()函数创建子图。使用各类画图函数画图,数据为列表形式
import matplotlib.pyplot as plt
Income_data = [1.47, 1.62, 1.78, 1.94, 2.38, 2.60,2.82,3.07,3.21]
fig = plt.figure(figsize = (10,6))
#画折线图
fig.add_subplot(221)
plt.plot(['2012','2013','2014','2015','2016','2017','2018','2019','2020'],Income_data) #折线图函数:plt.plot()
plt.title('Line chart')
plt.xlabel('Year')
plt.ylabel('Incone')
#画箱形图
fig.add_subplot(222)
plt.boxplot(Income_data,boxprops = {'color':'#1F77B4'},medianprops = {'color':'green'},whiskerprops={'color':'#1F77B4'})
#箱形图函数:plt.boxplot()。boxprops设置箱体的属性,whiskerprops设置须的属性,medianprops设置中位数的属性
plt.title('Box-whisker plot')
plt.xlabel('2012-2020')
plt.xticks([]) #不显示坐标轴刻度
plt.ylabel('Income')
#画柱状图
fig.add_subplot(212)
plt.bar(['2012','2013','2014','2015','2016','2017','2018','2019','2020'],Income_data,label = 'Income') #柱状图函数:plt.bar(x,height)
plt.title('Bar chart')
plt.legend()
plt.xlabel('Year')
plt.xticks(rotation = 90) #rotation设置刻度旋转角度值
plt.ylabel('Income')
#调间距
plt.subplots_adjust(wspace = 0.5,hspace = 0.5)
plt.savefig('Income2.jpg',dpi = 400,bbox_inches = 'tight')
plt.show()
后三种方法(采用plt.subplot()函数):
思路同上三种方法。
先定义画布:plt.figure(figsize = ())
再创建子图:plt.subplot()
对于Series与列表类型的数据:可不返回ax=ax1,ax=ax2,ax=ax3....。(也可返回)
对于DataFrame类型的数据:写为ax1(ax2、ax3...) = plt.subplot(),每次画图在画图函数里都要返回ax=ax1,ax=ax2,ax=ax3....。否则画图出错。如下:
#方法四:采用plt.subplot()函数创建子图。使用Series.plot绘图,数据为Series形式
import matplotlib.pyplot as plt
from pandas import Series
Income_data = Series([1.47, 1.62, 1.78, 1.94, 2.38, 2.60,2.82,3.07,3.21],index = ['2012','2013','2014','2015','2016','2017','2018','2019','2020'])
plt.figure(figsize = (10,6))
#画折线图
plt.subplot(221)
Income_data.plot(title = 'Line chart') #用Series.plot画折线图
plt.xticks(range(0,9),['2012','2013','2014','2015','2016','2017','2018','2019','2020']) #让x轴刻度显示全
plt.xlim(-0.5,8.5) #增大x轴刻度范围
plt.xlabel('Year')
plt.ylabel('Income')
#画箱形图
plt.subplot(222)
Income_data.plot(kind = 'box',title = 'Box-whisker plot')
plt.xlabel('2012-2020')
plt.ylabel('Income')
plt.xticks([])
#画柱状图
plt.subplot(212)
Income_data.plot(kind = 'bar',label = 'Income')
plt.title('Bar chart')
plt.xlabel('Year')
plt.ylabel('Income')
plt.legend()
#调整子图间距离
plt.subplots_adjust(wspace = 0.5,hspace = 0.5)
#方法五:采用plt.subplot()函数创建子图。使用DataFrame.plot画图,数据为DataFrame形式,需返回ax=ax1,ax=ax2,ax=ax3
import matplotlib.pyplot as plt
from pandas import DataFrame
Income_data =DataFrame([1.47, 1.62, 1.78, 1.94, 2.38, 2.60,2.82,3.07,3.21],index = ['2012','2013','2014','2015','2016','2017','2018','2019','2020'],
columns = ['Income'])
plt.figure(figsize = (8,6))
#画折线图
ax1 = plt.subplot(221)
Income_data.plot(title = 'Line chart',legend = False,ax = ax1) #legend = False去掉图例
plt.xticks(range(0,9),['2012','2013','2014','2015','2016','2017','2018','2019','2020']) #让x轴刻度显示全
plt.xlim(-0.5,8.5) #增大x轴刻度范围
plt.xlabel('Year')
plt.ylabel('Income')
#画箱形图
ax2 = plt.subplot(222)
Income_data.plot(kind = 'box',title = 'Box-whisker plot',xticks = [],ax = ax2)
plt.xlabel('2012-2020')
plt.ylabel('Income')
#画柱状图
ax3 = plt.subplot(212)
Income_data.plot(kind = 'bar',title = 'Bar chart',ax = ax3)
plt.xlabel('Year')
plt.ylabel('Income')
#调间距
plt.subplots_adjust(wspace = 0.5,hspace = 0.5)
#方法六:采用plt.subplot()函数创建子图。使用各类画图函数画图,数据为列表形式
import matplotlib.pyplot as plt
Income_data = [1.47, 1.62, 1.78, 1.94, 2.38, 2.60,2.82,3.07,3.21]
plt.figure(figsize = (10,6))
#画折线图
plt.subplot(221)
plt.plot(['2012','2013','2014','2015','2016','2017','2018','2019','2020'],Income_data) #折线图函数:plt.plot()
plt.title('Line chart')
plt.xlabel('Year')
plt.ylabel('Incone')
#画箱形图
plt.subplot(222)
plt.boxplot(Income_data,boxprops = {'color':'#1F77B4'},medianprops = {'color':'green'},whiskerprops={'color':'#1F77B4'}) #箱形图函数:plt.boxplot()
plt.title('Box-whisker plot')
plt.xlabel('2012-2020')
plt.xticks([]) #不显示坐标轴刻度,也可写为plt.xticks(())
plt.ylabel('Income')
#画柱状图
plt.subplot(212)
plt.bar(['2012','2013','2014','2015','2016','2017','2018','2019','2020'],Income_data,label = 'Income') #柱状图函数:plt.bar(x,height)
plt.title('Bar chart')
plt.legend()
plt.xlabel('Year')
plt.xticks(rotation = 90) #rotation设置刻度旋转角度值
plt.ylabel('Income')
#调间距
plt.subplots_adjust(wspace = 0.5,hspace = 0.5)六种方法运行结果皆如下:
【老书第一版此题】
宋晖《数据科学技术与应用》第一版老书中,该题目为:
2012~2017年我国人均可支配收入为[1.47, 1.62, 1.78, 1.94, 2.38, 2.60](单位:万元)。
题目要求图形如下:

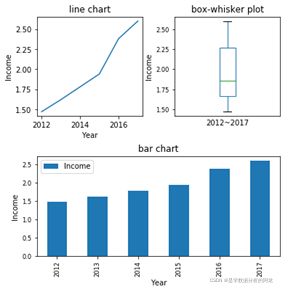
老书第一版要求的画图效果
第(1)题:
同样有类似的三种方法:
#方法一:采用Series.plot绘图。
import matplotlib.pyplot as plt
from pandas import Series
plt.figure()
Income_data = Series([1.47,1.62,1.78,1.94,2.38,2.60],index = ['2012','2013','2014','2015','2016','2017'])
Income_data.plot(title = 'Income chart',marker = 's',color = 'black',linestyle = 'dashed',grid = True,
yticks = [0.0,0.5,1.0,1.5,2.0,2.5,3.0],use_index = True) #若不加use_index = True,则x轴刻度范围会多一些
plt.xlabel('Year',fontsize = 12)
plt.ylabel('Income(RMB Ten Thousand)',fontsize = 12)
plt.legend(('Income',)) #添加逗号让图例文本显示全
plt.annotate('Largest!',color = 'red',xy = (5,2.60),xytext = (3,2.55),arrowprops = dict(arrowstyle = '->',color = 'red'))
plt.savefig('Income chart.jpg',dpi = 400,bbox_inches = 'tight') #保存为jpg图片
plt.show()
#方法二:采用DataFrame.plot绘图,用columns做标签,无需设label。同时x,y轴刻度采用函数取得
import matplotlib.pyplot as plt
import numpy as np
from pandas import DataFrame
%matplotlib inline
Income = [1.47,1.62,1.78,1.94,2.38,2.60]
data = DataFrame({'Income':Income},index = np.arange(2012,2018))#此处需要注意index中数的坐标,(标注释时xy中坐标改变)
data.plot(title = 'Income chart',linestyle = 'dashed',marker = 's',color = 'k',grid = True,yticks = np.arange(0.0,3.5,0.5)) #此处可以显示或者不显示图例,加legend = True/False
#精细设置图元
plt.xlabel('Year',fontsize = 12)
plt.ylabel('Income(RMB Ten Thousand)',fontsize = 12)
plt.annotate('Largest!',color = 'r',xy = (2017,2.60),xytext = (2015,2.55),arrowprops = dict(arrowstyle = '->',color = 'r'))
plt.savefig('Income chart.jpg',dpi = 400,bbox_inches = 'tight')
plt.show()
#方法三:采用plt.plot画图,设置坐标轴与标题的字体
import matplotlib.pyplot as plt
import numpy as np
Income = [1.47,1.62,1.78,1.94,2.38,2.60]
plt.plot(Income,linestyle = 'dashed',color = 'k',marker = 's',label = 'Income') #注:里面无grid,需要直接设置
plt.xticks(range(0,6),['2012','2013','2014','2015','2016','2017']) #将x轴刻度映射为字符串
plt.yticks(np.arange(0,3.5,0.5))
plt.title('Income chart',fontdict = {'family':'Times New Roman','size':12})
plt.xlabel('Year',fontdict = {'family':'Times New Roman','size':12})
plt.ylabel('Income(RMB Ten Thousand)',fontdict = {'family':'Times New Roman','size':12})
plt.xlim(0,5)
plt.legend(loc = 1) #loc = 1表示图例位于第一象限。#此处亦可写plt.legend(('Income',),loc = 'upper right'),不用label #亦可写plt.legend()
plt.grid()
plt.annotate('Largest!',xy = (5,2.60),xytext = (3,2.55),arrowprops = dict(arrowstyle = '->',color = 'r'),color = 'red')
plt.savefig('Income chart.jpg',dpi = 400,bbox_inches = 'tight')
plt.show()
结果如下:
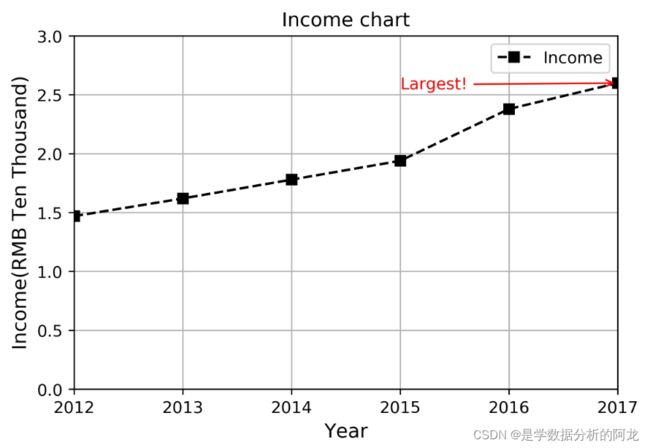
第(2)题:
同样列举以下6种方法:
【方法一】:fig.add_subplot绘图,Series.plot()绘图,数据为series形式
【方法二】:fig.add_subplot绘图,DataFrame.plot()绘图,数据为DataFrame形式
【方法三】:fig.add_subplot()函数,运用各类画图函数画图,数据为列表形式
【方法四】:采用subplot()函数绘图。Series.plot()函数,数据为Series形式
【方法五】:采用subplot()函数绘图。DataFrame.plot()函数,数据为DataFrame形式
【方法六】:采用subplot()函数,运用各类画图函数画图,数据为列表形式
六种方法如下:
#方法一:fig.add_subplot绘图,Series.plot()绘图,数据为series形式
import matplotlib.pyplot as plt
from pandas import Series
data = Series([1.47,1.62,1.78,1.94,2.38,2.60],index = ['2012','2013','2014','2015','2016','2017'])
#定义图形大小
fig = plt.figure(figsize = (6,6))
#绘制折线图
ax1 = fig.add_subplot(2,2,1)
ax1.plot(data)
plt.title('line chart')
plt.xticks(range(0,6,2),['2012','2014','2016'])
plt.xlabel('Year',fontsize = 12)
plt.ylabel('Income',fontsize = 12)
#绘制箱形图
ax2 = fig.add_subplot(2,2,2)
data.plot(kind = 'box',xticks = []) #xticks = []表示无刻度
plt.title('box-whisker plot')
plt.xlabel('2012—2017',fontsize = 12)
plt.ylabel('Income',fontsize = 12)
#绘制柱状图
ax3 = fig.add_subplot(2,1,2)
data.plot(kind = 'bar')
plt.legend(('Income',))
plt.title('bar chart')
plt.xlabel('Year',fontsize = 12)
plt.ylabel('Income',fontsize = 12)
#调整子图间距离
plt.subplots_adjust(wspace = 0.5,hspace = 0.5) #wspace、hspace分别表示子图之间左右、上下的间距
plt.savefig('Image2.jpg',dpi = 400,bbox_inches = 'tight')
plt.show()
#方法二:fig.add_subplot绘图,DataFrame.plot()绘图,数据为DataFrame形式
import matplotlib.pyplot as plt
from pandas import DataFrame
data1 = [1.47,1.62,1.78,1.94,2.38,2.60]
Incomedata = DataFrame({'Income':data1},index = ['2012','2013','2014','2015','2016','2017'])
fig = plt.figure(figsize = (6,6))
#绘制折线图
ax1 = fig.add_subplot(2,2,1)
Incomedata.plot(title = 'line chart',legend = False,ax = ax1) #legend = False去掉标注 。
#另外重要发现:不加ax=ax1画图出错。而Series.plot未发现出错
plt.xticks(range(0,6,2),['2012','2014','2016'])
plt.xlabel('Year',fontsize = 12)
plt.xlim(-0.5,5.5) #扩大x刻度范围
plt.ylabel('Income',fontsize = 12)
#绘制箱线图
ax2 = fig.add_subplot(2,2,2)
Incomedata.plot(kind = 'box',title = 'box-whisker plot',ax = ax2)
plt.xticks(())
plt.xlabel('2012—2017',fontsize = 12)
plt.ylabel('Income',fontsize = 12)
#绘制柱状图
ax3 = fig.add_subplot(2,1,2)
Incomedata.plot(kind = 'bar',title = 'bar chart',ax = ax3)
plt.xlabel('Year',fontsize = 12)
plt.ylabel('Income',fontsize = 12)
#调整子图间间距
plt.subplots_adjust(wspace = 0.5,hspace = 0.5)
plt.show()
#方法三:运用各类画图函数画图:采用fig.add_subplot()函数,数据为列表形式
import matplotlib.pyplot as plt
data = [1.47,1.62,1.78,1.94,2.38,2.60]
fig = plt.figure(figsize = (6,6))
#折线图
ax1 = fig.add_subplot(2,2,1)
plt.plot(data)
plt.title('line chart')
plt.xticks(range(0,6,2),['2012','2014','2016'])
plt.xlabel('Year',fontsize = 12)
plt.ylabel('Income',fontsize = 12)
#箱型图
ax2 = fig.add_subplot(2,2,2)
plt.boxplot(data,boxprops = {'color':'#1F77B4'},medianprops = {'color':'green'},whiskerprops={'color':'#1F77B4'})
#boxprops设置箱体的属性,whiskerprops设置须的属性,medianprops设置中位数的属性
plt.xticks(()) #双括号不显示坐标轴刻度
plt.title('box-whisker plot')
plt.xlabel('2012—2017',fontsize = 12)
plt.ylabel('Income',fontsize = 12)
#柱形图
ax3 = fig.add_subplot(2,1,2)
plt.bar(['2012','2013','2014','2015','2016','2017'],[1.47,1.62,1.78,1.94,2.38,2.60]) #bar(x,height)
plt.legend(('Income',))
plt.xticks(rotation = 90) #x刻度倾斜90度
plt.title('bar chart')
plt.xlabel('Year',fontsize = 12)
plt.ylabel('Income',fontsize = 12)
#调整子图间距离
plt.subplots_adjust(wspace = 0.5,hspace = 0.5)
#方法四:采用subplot()函数绘图。Series.plot()函数,数据为Series形式
import matplotlib.pyplot as plt
from pandas import Series
plt.figure(figsize = (6,6))
#绘制折线图
plt.subplot(2,2,1)
data = Series([1.47,1.62,1.78,1.94,2.38,2.60],index = ['2012','2013','2014','2015','2016','2017'])
plt.plot(data)
plt.title('line chart')
plt.xticks(range(0,6,2),['2012','2014','2016'])
plt.xlabel('Year',fontsize = 12)
plt.ylabel('Income',fontsize = 12)
#绘制箱型图
plt.subplot(2,2,2)
data.plot(title = 'box-whisker plot',kind = 'box',xticks = [])
plt.xlabel('2012—2017',fontsize = 12)
plt.ylabel('Income',fontsize = 12)
#绘制柱形图
plt.subplot(2,1,2)
data.plot(kind = 'bar')
plt.legend(('Income',))
plt.title('bar chart')
plt.xlabel('Year',fontsize = 12)
plt.ylabel('Income',fontsize = 12)
#调整子图间距离
plt.subplots_adjust(wspace = 0.5,hspace = 0.5)
plt.show()
#方法五:采用subplot()函数绘图。DataFrame.plot()函数,数据为DataFrame形式
import matplotlib.pyplot as plt
from pandas import DataFrame
data1 = [1.47,1.62,1.78,1.94,2.38,2.60]
Incomedata = DataFrame({'Income':data1},index = ['2012','2013','2014','2015','2016','2017'])
plt.figure(figsize = (6,6))
#折线图
ax1 = plt.subplot(221) #将第一个画板划分为2行1列组成的区块,并获取到第一块区域
Incomedata.plot(title = 'line chart',legend = False,ax = ax1) #若无ax = ax1,则画不出图
plt.xticks(range(0,6,2),['2012','2014','2016'])
plt.xlabel('Year',fontsize = 12)
plt.xlim(-0.5,5.5) #扩大x刻度范围
plt.ylabel('Income',fontsize = 12)
#绘制箱线图
ax2 = plt.subplot(222)
Incomedata.plot(kind = 'box',title = 'box-whisker plot',ax = ax2)
plt.xticks(())
plt.xlabel('2012—2017',fontsize = 12)
plt.ylabel('Income',fontsize = 12)
#绘制柱状图
ax3 = plt.subplot(212)
Incomedata.plot(kind = 'bar',title = 'bar chart',ax = ax3)
plt.xlabel('Year',fontsize = 12)
plt.ylabel('Income',fontsize = 12)
#调整子图间间距
plt.subplots_adjust(wspace = 0.5,hspace = 0.5)
#方法六:运用各类画图函数画图:采用subplot()函数,数据为列表形式
import matplotlib.pyplot as plt
data = [1.47,1.62,1.78,1.94,2.38,2.60]
fig = plt.figure(figsize = (6,6))
#折线图
plt.subplot(2,2,1)
plt.plot(data)
plt.title('line chart')
plt.xticks(range(0,6,2),['2012','2014','2016'])
plt.xlabel('Year',fontsize = 12)
plt.ylabel('Income',fontsize = 12)
#箱型图
plt.subplot(2,2,2)
plt.boxplot(data,boxprops = {'color':'#1F77B4'},medianprops = {'color':'green'},whiskerprops={'color':'#1F77B4'})
#boxprops设置箱体的属性,whiskerprops设置须的属性,medianprops设置中位数的属性
plt.xticks(()) #双括号不显示坐标轴刻度
plt.title('box-whisker plot')
plt.xlabel('2012—2017',fontsize = 12)
plt.ylabel('Income',fontsize = 12)
#柱形图
plt.subplot(2,1,2)
plt.bar(['2012','2013','2014','2015','2016','2017'],[1.47,1.62,1.78,1.94,2.38,2.60]) #bar(x,height)
plt.legend(('Income',))
plt.xticks(rotation = 90) #x刻度倾斜90度
plt.title('bar chart')
plt.xlabel('Year',fontsize = 12)
plt.ylabel('Income',fontsize = 12)
#调整子图间距离
plt.subplots_adjust(wspace = 0.5,hspace = 0.5) 运行结果如下:
P84思考与练习2
1.叙述各类图形的特点、适合展示的数据特性,以及在数据探索阶段的用途。
- 函数绘图:可直观地观察两个变量之间的关系,可以为线性或逻辑回归等模型提供结果展示。x采样值越多,绘制曲线越精确。
- 散点图:它将两组数据分别作为点的横坐标与纵坐标。可分析两个数据序列之间是否具有相关关系。可辅助线性或逻辑回归算法建立合理的预测模型。
- 柱状图:用多个柱体描述单个总体处于不同状态的数量。易于展示数据的大小和比较数据之间的差别,还能用来表示均值和方差估计。
- 折线图:用线条描述事物的发展变化及趋势。
- 直方图:用于描述总体的频数分配情况。它将横坐标按区间个数等分,每个区间的高度表示区间样本的频数,面积表示数量。可观测数据的离散化情况。
- 密度图:采用平滑的峰值函数来拟合概率密度函数,对真实的概率分布曲线进行模拟。
- 饼图:描述总体的样本值构成比。饼图可清楚反映出部分与部分、部分与整体之间的数量关系。
- 箱形图:适于表达数据的分位数分布帮助找到异常值。可以快速确定一个样本是否有利于进行分组判别。
2.数据文件high-speed rail.csv存放着世界各国高速铁路的情况。数据格式如下表所示。请对世界各国高铁的数据进行绘图分析。
| Country |
Operation |
Under-construction |
Planning |
| 国家 |
运营里程(公里) |
在建里程(公里) |
计划里程(公里) |
1)各国运营里程对比柱状图, 标注China为“Longest”,如下图:

列举以下三种方法:
【方法一】:读取文件未设置index_col = 0,则行索引为0~5的数字,而Series.plot画垂直柱状图(kind = 'bar')以行索引作为x刻度,需要重新设置x刻度值。
【方法二】:读取文件设置了index_col = 0,即选中"Country"列作为了行索引,Series.plot画垂直柱状图以行索引作为x刻度,不需要重新设置x刻度值。
【方法三】:采用垂直柱状图函数plt.bar(x,y,width)画图 。
#方法一:未设置index_col = 0
import matplotlib.pyplot as plt
import pandas as pd
plt.figure()
data = pd.read_csv('data\High-speed rail.csv')
#1)柱状图
data['Operation'].plot(kind = 'bar',title = 'Operation Mileage',rot = 45) #rot旋转x轴刻度 #亦可单独加一行plt.xticks(rotation = 45)
plt.xticks(range(0,6),data['Country'])
plt.annotate('Longest!',xy = (0,20000),xytext = (1,20000),color = 'red',arrowprops = dict(arrowstyle = '->',color = 'red')) #此处标注位置直接用数字,
plt.xlabel('Country')
plt.ylabel('Mileage(km)')
plt.show()
#方法二,设置了index_col = 0
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
data = pd.read_csv('data\High-speed rail.csv',index_col = 0)
#1)柱状图
data['Operation'].plot(kind = 'bar',title = 'Operation Mileage',rot = 45)
plt.annotate('Longest!',xy = (0,20000),xytext = (1,20000),color = 'red',arrowprops = dict(arrowstyle = '->',color = 'red'))
plt.xlabel('Country')
plt.ylabel('Mileage(km)')
plt.show()
#方法三:采用bar函数绘图。plt.bar(x,y,width)
import matplotlib.pyplot as plt
import pandas as pd
data1 = pd.read_csv('data\High-speed rail.csv')
#1)柱状图
plt.bar(data1['Country'],data1['Operation'],width = 0.5) #此处进行柱状图宽度设置width,默认值0.8,稍宽。
plt.xticks(rotation = 45)
plt.annotate('Longest!',xy = (0,20000),xytext = (1,20000),color ='red',arrowprops = (dict(arrowstyle = '->',color = 'red')))
plt.title('Operation Mileage')
plt.xlabel('Country')
plt.ylabel('Mileage(km)')
plt.show()2)各国运营里程现状和发展堆叠柱状图,如下图:
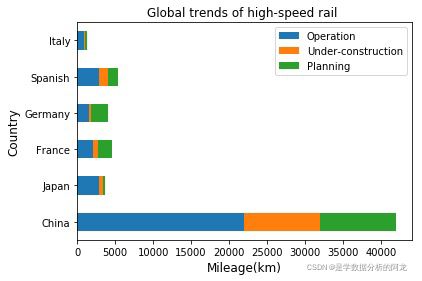
列举以下三种方法:
【方法一】:读取文件未设置index_col = 0,则行索引为0~5的数字,而Series.plot画水平柱状图(kind = 'barh')以行索引作为y刻度,需要重新设置y刻度值。
【方法二】:读取文件设置了index_col = 0,即选中"Country"列作为了行索引,Series.plot画水平柱状图以行索引作为y刻度,不需要重新设置y刻度值。
【方法三】:采用水平柱状图函数plt.barh(y,x,height,label)画图 。
#方法一:不加index_col = 0
import matplotlib.pyplot as plt
import pandas as pd
data = pd.read_csv('data\High-speed rail.csv')
data[['Operation','Under-construction','Planning']].plot(kind = 'barh',stacked = True,title = 'Global trends of high-speed rail')
plt.yticks(range(0,6),data['Country']) #注:此处为yticks设置坐标值
plt.xlabel('Mileage(km)')
plt.ylabel('Country')
plt.show()
#方法二:加index_col = 0
import matplotlib.pyplot as plt
import pandas as pd
data = pd.read_csv('data\High-speed rail.csv',index_col = 0)
data[['Operation','Under-construction','Planning']].plot(kind = 'barh',stacked = True,title = 'Global trends of high-speed rail') #stacked为True表示堆叠
plt.xlabel('Mileage(km)')
plt.show()
#方法三:用barh函数画水平堆叠柱状图。plt.barh(y,x,height,label)
import matplotlib.pyplot as plt
import pandas as pd
data = pd.read_csv('data\High-speed rail.csv')
plt.barh(data['Country'],data['Operation'],height = 0.5,label = 'Operation') #柱宽度用height
plt.barh(data['Country'],data['Under-construction'],left = data['Operation'],height = 0.5,label = 'Under-construction') #此处用left
plt.barh(data['Country'],data['Planning'],left = data['Operation']+data['Under-construction'],height = 0.5,label = 'Planning') #此处left为之前堆叠数据的和
plt.legend() #显示图标
plt.title('Global trends of high-speed rail')
plt.xlabel('Mileage(km)')
plt.ylabel('Country')
plt.show()3)各国运营里程占比饼图,China扇形离开中心点,如下图:

列举以下三种方法:
【方法一】:读取文件未设置index_col = 0,则行索引为0~5的数字,而Series.plot画扇形图(kind = 'pie')以行索引作为扇形块的标签(labels),需要重新设置扇形块的标签。
【方法二】:读取文件设置了index_col = 0,即选中"Country"列作为了行索引,Series.plot画扇形图以行索引扇形块标签,不需要重新设置扇形块的标签(labels)。
【方法三】:采用扇形图函数plt.pie(x,labels,startangle,autopct,shadow,explode)画图 。
#方法一:不加index_col = 0,需要自己设置labels
import matplotlib.pyplot as plt
import pandas as pd
data = pd.read_csv('data\High-speed rail.csv')
data['Operation'].plot(kind = 'pie',labels = data['Country'],startangle = 60,autopct = '%1.1f%%',shadow = True,explode = [0.1,0,0,0,0,0],title = 'Opeartion Mileage')
plt.ylabel('') #删除饼图中调用Series中的值的名称“Operation”
plt.show()
#方法一:加index_col = 0
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
data = pd.read_csv('data\High-speed rail.csv',index_col = 0)
data['Operation'].plot(kind = 'pie',startangle = 60,autopct = '%1.1f%%',shadow = True,explode = [0.1,0,0,0,0,0],title = 'Opeartion Mileage')
plt.ylabel('') #删除饼图中调用Series中的值的名称“Operation”
plt.show()
#方法三:用pie()函数
import matplotlib.pyplot as plt
import pandas as pd
data = pd.read_csv('data\High-speed rail.csv')
plt.pie(data['Operation'],labels = data['Country'],startangle = 60,autopct = '%1.1f%%',shadow = True,explode = [0.1,0,0,0,0,0])
plt.title('Opeartion Mileage')
plt.show()4)绘制现有里程的地图,用不同颜色表示数量由大到小。
提示】:
(1)从文件中读取数据时,使用第一列数据作为index:
data = pd.read_csv(‘High-speed rail.csv’, index_col =‘Country’) ,获取中国对应的数据行,使用data ['China’]。
本题思路有二:
【思路一】:使用Basemap函数绘制散点图,用不同颜色散点的大小表示里程。
【思路二】:使用Pyecharts绘制交互式地图,用不同形状、颜色的点来表示里程。
方法一:使用Basemap绘制地图
前言:
安装教程:
Basemap安装使用简介 开源地理空间基金会中文分会 开放地理空间实验室
https://www.osgeo.cn/post/17d83
使用教程:
工作台 - Heywhale.com
一些说明:
在地图中,“东西经,南北纬”。“上北下南,左西右东”。记住这两句话,画图会轻松不少。
Basemap()内部参数中:
projection:代表投影方式。不设置一般默认为'cyl',为经纬度投影。
lon_0:表示地图中心点的经度值。lat_0则表示地图中心点的纬度值。
lon_0范围为[0,360]分别对应[0°E,180°E,180°W,0°W](便大家理解,故这样写),其中纬度lat_0与经度设置类似。设置lon_0 = 160和lon_0 = 240。
我们看看效果图:
再根据一个小例子了解一下Basemap绘图的基本操作:
import numpy as np
from mpl_toolkits.basemap import Basemap #导入Basemap函数
import matplotlib.pyplot as plt
plt.figure(figsize = (16,8))
m = Basemap() #实例化一个map,Basemap()默认lon_0=0,lat_0=0,projection = 'cyl'(经纬度投影)。
#Basemap里面无参数,画出为全球地图
m.drawcoastlines(linewidth = 1,color = 'red') #绘制海岸线,设置线宽、颜色
m.drawstates() #绘制州界(主要北美洲、南美洲与澳大利亚)
m.drawcountries() #绘制国界
m.drawmapboundary(fill_color='white') #背景图颜色
m.fillcontinents(color='yellow',lake_color='purple') # 画大洲,颜色填充为黄色,内陆湖为紫色
m.drawmapboundary(fill_color='aqua') #对海洋进行颜色填充,aqua为湖绿色
m.drawparallels(np.arange(-90., 91.,10.),labels=[1,1,1,1], fontsize=10,color='green') #在图中横线是绿色
#南北纬标签设置,labels中0可用False代替,1可用True代替,labels中前两个数决定标注的左右位置
m.drawmeridians(np.arange(-180., 181.,20.),labels=[1,1,0,1], fontsize=10,color = 'blue') #在图中竖线是蓝色
#东西经标签设置,labels中后两个数决定标注的上下位置
plt.savefig('name1.jpg',dpi = 400,bbox_inches = 'tight') #将地图保存为一个图像
plt.show()运行结果:
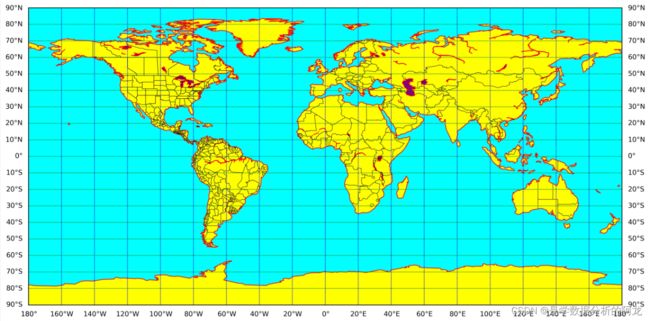
下面开始做题:
import matplotlib.pyplot as plt
from mpl_toolkits.basemap import Basemap
import pandas as pd
from pandas import DataFrame
import numpy as np
data = pd.read_csv('data\High-speed rail.csv',index_col = 0)
print(data['Operation'])
plt.figure(figsize = (16,8))
m = Basemap(llcrnrlon = -10,urcrnrlon = 150,llcrnrlat = 0, urcrnrlat = 80)
#局部绘图参数。llcrnrlon与urcrnrlon分别为地图的经度范围最小值与最大值。
#llcrnrlat与urcrnrlat分别为地图纬度范围的最小值与最大值。
m.drawcountries(linewidth = 1) #国界
m.drawstates() #州界
m.drawcoastlines(linewidth = 1) #海岸线
lat = np.array(data['Latitude']) #获取各区纬度值
lon = np.array(data['Longitude']) #获取各区经度值
Ope = np.array(data["Operation"]) #获取运营里程值
size=(Ope/np.max(Ope))*1000 #绘制散点图时里程值对应点的大小
x,y = m(lon,lat) #确定各区经纬度坐标点
m.scatter(x,y,s=size,color =['#f6941d','#00FF00','#585eaa','#ea66a6','#54211d','#ffd400']) #在地图上绘制散点图
parallels = np.arange(-90.,91.,10.)
m.drawparallels(parallels,labels=[1,0,0,0],fontsize=10) #绘制纬线,设置标注字体大小
meridians = np.arange(-180.,181.,20)
m.drawmeridians(meridians,labels=[0,0,0,1],fontsize=10) #绘制经线
#m.etopo() #绘制地形图,浮雕样式
#m.shadedrelief() #绘制阴影地图浮雕
plt.savefig('name2.jpg',dpi = 400,bbox_inches = 'tight')
plt.show()运行结果如下:
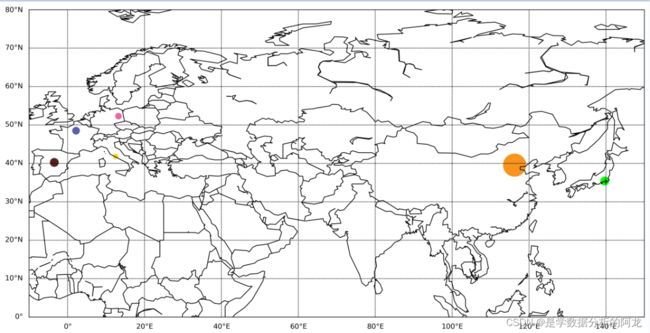 还可用shadedrelief() 绘制阴影浮雕地图:
还可用shadedrelief() 绘制阴影浮雕地图:
还可用etopo() 绘制地形图,浮雕样式:
方法二:使用Pyecharts绘制地图
前言:
pyecharts主要用Map,Geo,BMap函数绘制交互式地图。可视化效果较好,绘图结果保存为.html网页格式,支持在Jupyter Notebook等Web 框架中使用,一般的编译环境如Spyder,Sublime中无法显示结果。
知乎入门:
就是这么简单!Pyecharts绘制可视化地图大全 - 知乎
使用教程:
pyecharts - A Python Echarts Plotting Library built with love.
① 使用Map函数绘制散点图,有连续色度条
#使用Map()函数绘图,连续色度条
import pandas as pd
from pyecharts.charts import Map
from pyecharts import options as opts
from pyecharts.globals import ThemeType
data = pd.read_csv('data/High-speed rail.csv',index_col = 0)
country = data.index.tolist()
Operation = data['Operation'].tolist()
c = ( #pyecharts中支持链式调用
Map(init_opts=opts.InitOpts(theme=ThemeType.WESTEROS)) #设置背景风格
.add("", [list(z) for z in zip(country,Operation)],"world")
.set_series_opts(label_opts=opts.LabelOpts(is_show=False)) #不显示地图标签(即国家名称)
.set_global_opts(
title_opts=opts.TitleOpts(title="世界各国高铁运营里程图",pos_left='center',
title_textstyle_opts=opts.TextStyleOpts(font_size=25)),
visualmap_opts=opts.VisualMapOpts(max_ = 22000,min_=900))
.render("Operation1.html")
)运行结果如下:

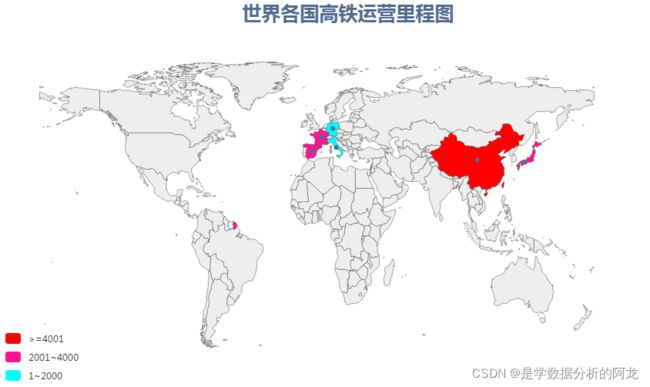
② 使用Map函数绘制散点图,色度分段
#使用Map()函数绘图,色度分阶
import pandas as pd
from pyecharts.charts import Map
from pyecharts import options as opts
from pyecharts.globals import ThemeType
data = pd.read_csv('data/High-speed rail.csv',index_col = 0)
country = data.index.tolist()
Operation = data['Operation'].tolist()
c = (
Map(init_opts=opts.InitOpts(theme=ThemeType.WESTEROS))
.add("", [list(z) for z in zip(country,Operation)],"world")
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title="世界各国高铁运营里程图",pos_left='center',
title_textstyle_opts=opts.TextStyleOpts(font_size=25)),
visualmap_opts=opts.VisualMapOpts(
is_piecewise=True,pieces =[
{"max": 2000, "min": 1, "label": "1~2000", "color": "#00FFFF"},
{"max": 4000, "min": 2001, "label": "2001~4000", "color": "#FF1493"},
{"max": 25000, "min": 4000, "label": ">=4001", "color": "#FF0000"}]))
.render("Operation2.html")
)运行结果如下:
③使用Geo函数绘制涟漪特效散点图,色度分段
#使用Geo()函数绘图 ,涟漪图
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Geo
from pyecharts.globals import ThemeType, CurrentConfig, GeoType
import json
data = pd.read_csv('data/High-speed rail.csv')
print(data)
#自定义坐标,写在json文件,以JOSN文件格式新增多个坐标点
data_json={}
for index,row in data.iterrows(): #iterrows() 是在数据框中的行进行迭代的一个生成器,它返回每行的索引及一个包含行本身的对象
data_json[row['Country']]=[float(row['Longitude']),float(row['Latitude'])]
with open("Ope_MAP.json","w") as f:
json.dump(data_json,f)
geo = ( Geo(init_opts=opts.InitOpts(width='800px',
height='600px',
theme=ThemeType.WESTEROS)) #维斯特洛大陆风格
.add_coordinate_json("Ope_MAP.json") #加载自定义坐标
.add_schema(maptype='world')
.add("",data_pair=[list(z) for z in zip(data['Country'].tolist(),data['Operation'].tolist())],
type_=GeoType.EFFECT_SCATTER,
symbol_size=10)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False)) # is_show=True/False 是否显示标签
.set_global_opts(
title_opts=opts.TitleOpts(title="世界各国高铁运营里程图",pos_left='center',
title_textstyle_opts=opts.TextStyleOpts(font_size=25)),
visualmap_opts=opts.VisualMapOpts(is_piecewise=True,pieces =[
{"max": 2000, "min": 1, "label": "1~2000", "color": "#00FFFF"},
{"max": 4000, "min": 2001, "label": "2001~4000", "color": "#FFD700"},
{"max": 25000, "min": 4001, "label": ">=4001", "color": "#FF0000"}]))
)
geo.render("Operation3.html")
运行结果如下: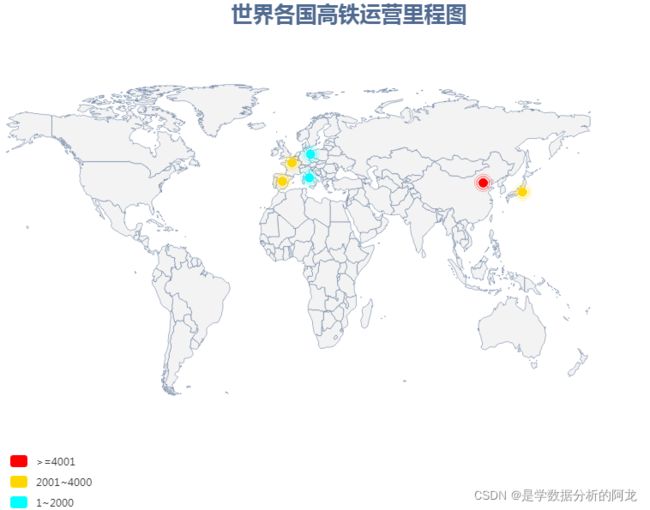
④使用Geo函数绘制涟漪效果散点图,修改点大小(也可用for循环)
#使用Geo()函数绘图 ,涟漪点,大小不同(按比例)
import pandas as pd
import numpy as np
from pyecharts import options as opts
from pyecharts.charts import Geo
from pyecharts.globals import ThemeType, ChartType, GeoType
data = pd.read_csv('data/High-speed rail.csv')
Ope = np.array(data["Operation"])
size = (Ope/np.max(Ope))*100
print(data)
geo = Geo(init_opts=opts.InitOpts(width='800px',height='600px',theme=ThemeType.ESSOS))
geo.add_schema(maptype='world',center = [70,40]) #定位的左上角以及右下角
geo.add_coordinate('China',116.24,39.55)
geo.add("",data_pair =[('Chian',22000)],symbol_size =100 ,type_=GeoType.EFFECT_SCATTER,symbol = "pin") #symbol = "pin"决定形状为水滴状
geo.add_coordinate('Japan',139.69,35.42)
geo.add("",data_pair =[('Japan',2900)],symbol_size =13.18 ,type_=GeoType.EFFECT_SCATTER,symbol = "pin")
geo.add_coordinate('France',2.21,48.51)
geo.add("",data_pair =[('France',2100)],symbol_size =9.55 ,type_=GeoType.EFFECT_SCATTER,symbol = "pin")
geo.add_coordinate('Germany',13.25,52.30)
geo.add("",data_pair =[('Germany',1500)],symbol_size =6.82 ,type_=GeoType.EFFECT_SCATTER,symbol = "pin")
geo.add_coordinate('Spain',-3.45,40.25)
geo.add("",data_pair =[('Spain',2900)],symbol_size =13.18 ,type_=GeoType.EFFECT_SCATTER,symbol = "pin")
geo.add_coordinate('Italy',12.50,41.80)
geo.add("",data_pair =[('Italy',900)],symbol_size =4.10 ,type_=GeoType.EFFECT_SCATTER,symbol = "pin")
geo.set_series_opts(label_opts=opts.LabelOpts(is_show=False),effect_opts=opts.EffectOpts(scale=5))
geo.set_global_opts(title_opts=opts.TitleOpts(
title="世界各国高铁运营里程图",pos_left='center',
title_textstyle_opts=opts.TextStyleOpts(font_size=25)),
visualmap_opts=opts.VisualMapOpts(is_piecewise=True,pieces =[
{"max": 2000, "min": 1, "label": "1~2000", "color": "#00FFFF"},
{"max": 4000, "min": 2001, "label": "2001~4000", "color": "#FFD700"},
{"max": 25000, "min": 4001, "label": ">=4001", "color": "#FF0000"}]))
geo.render("Operation4.html")
运行结果如下:

P86综合练习题
1.文件bankpep.csv存放着银行储户的基本信息,数据格式如下表所示:
| id |
age |
sex |
region |
income |
married |
children |
car |
save_act |
current_act |
mortgage |
pep |
| 编号 |
年龄 |
性别 |
区域 |
收入 |
婚否 |
孩子数 |
有车否 |
存款账户 |
现金账户 |
是否抵押 |
接受新业务 |
请通过绘图对这些客户数据进行探索性分析。
1)客户年龄分布的直方图和密度图,如下图:

import matplotlib.pyplot as plt
import pandas as pd
data = pd.read_csv('data/bankpep.csv')
#1)
data['age'].plot(kind = 'hist',bins = 10,normed = True,title = 'Customer Age')
data['age'].plot(kind = 'kde',style = 'k-')
plt.xlabel('Age')
plt.ylabel('Density')
plt.show()2)客户年龄和收入关系的散点图,如下图:
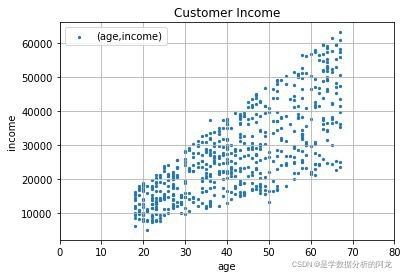
列举以下两种方法:
【方法一】:采用DataFrame.plot(kind = 'scatter',x,y,title,label,grid,xlim,marker,s)绘图。
【方法二】:采用散点图plt.scatter(x,y,marker,s)函数绘图
#2)
#方法一
data[['age','income']].plot(kind = 'Scatter',x = 'age',y = 'income',marker = 's',s = 8,title = 'Customer Income',label = '(age,income)',grid = True,
xlim = [0,80]) #s设置点大小
plt.xlabel('Age')
plt.ylabel('Income')
plt.show()
#方法二:采用scatter函数绘图
plt.figure(figsize = (10,6)) #更改图片大小与背景
plt.scatter(data['age'],data['income'],marker = 's',s = 10) #s设置点大小
plt.grid()
plt.title('Customer Income')
plt.xlabel('Age')
plt.ylabel('Income')
plt.xlim([0,80])
plt.legend(('(age,income)',)) #加“,”使图例显示完整
plt.show()3)绘制散点图观察账户(年龄,收入,孩子数)之间的关系,对角线显示直方图,如下图:

#3)
pd.plotting.scatter_matrix(data[['age','income','children']],c = 'm') #c用来设置颜色:m为红紫色
plt.show()4)按区域展示平均收入的柱状图,并显示标准差,如下图:
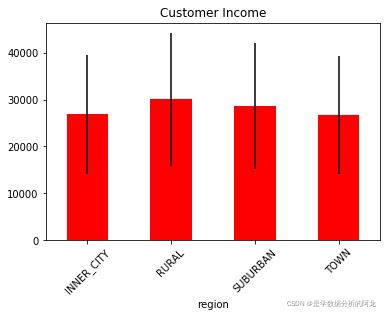
列举以下两种方法:
【方法一】:采用DataFrame.plot(kind = 'bar',yerr = std,rot,title,color)绘制垂直柱状图(yerr = std标y轴的轴向误差线)
【方法二】:采用柱状图plt.bar(x,height,width,yerr = std,color)函数绘图。注:bar函数中的x值、height值、yerr为Series或列表。
#4)
#方法一
import numpy as np
mean = data.groupby(['region']).agg({'income':np.mean})
std = data.groupby(['region']).agg({'income':np.std})
mean.plot(kind = 'bar',yerr = std ,rot = 45,title = 'Customer Income',legend = False,color = 'r')
plt.xlabel('Region')
plt.show()
#方法二:bar函数
import numpy as np
mean = data.groupby(['region']).agg({'income':np.mean})
std = data.groupby(['region']).agg({'income':np.std})
plt.bar(mean.index,mean.income,color = 'r',width = 0.5,yerr = std.income.tolist()) # bar函数中的x值、height值、yerr为Series或列表。
plt.xlabel('Region')
plt.xticks(rotation = 45)
plt.title('Customer Income')
plt.show()5)多子图绘制:账户中性别占比饼图,有车的性别占比饼图,按孩子数的账户占比饼图,如下图:
【方法一】:figure.add_subplot()函数,Series.plot函数绘图。Series类型的可不加ax=ax1,ax2,ax3
【方法二】:figure.add_subplot()函数,plt.pie(x,labels,startangle,autopct')函数绘图
【方法三】与【方法四】均采用plt.subplot()函数绘图。用法同figure.add_subplot()
#5)
#方法一:Series.plot绘图,fig.add_subplot()函数,Series类型的可不加ax=ax1,ax2,ax3
sex_data = data.groupby(['sex'])['sex'].count()
car_data = data[data['car'] =='YES'].groupby(['sex'])['sex'].count()
children_data = data.groupby(['children'])['children'].count()
fig = plt.figure(figsize = (7,6))
fig.add_subplot(2,2,1)
sex_data.plot(kind = 'pie',title ='Customer Sex',startangle = 60,autopct = '%1.1f%%')
fig.add_subplot(2,2,2)
car_data.plot(kind = 'pie',title = 'Customer Car Sex',startangle = 60,autopct = '%1.1f%%')
fig.add_subplot(2,2,3)
children_data.plot(kind = 'pie',title = 'Customer Children',startangle = 60,autopct = '%1.1f%%')
plt.savefig('饼图.jpg',dpi = 400,bbox_inches = 'tight')
plt.show()
#方法二:采用pie函数,fig.add_subplot()函数
sex_data = data.groupby(['sex'])['sex'].count()
car_data = data[data['car'] =='YES'].groupby(['sex'])['sex'].count()
children_data = data.groupby(['children'])['children'].count()
fig = plt.figure(figsize = (7,6))
fig.add_subplot(221) #221可加可不加逗号
plt.pie(x = sex_data,labels = sex_data.index,startangle = 60,autopct = '%1.1f%%')
plt.title('Customer Sex')
plt.ylabel('sex')
fig.add_subplot(222)
plt.pie(x = car_data,labels = sex_data.index,startangle = 60,autopct = '%1.1f%%')
plt.title('Customer Car Sex')
plt.ylabel('sex')
fig.add_subplot(223)
plt.pie(x = children_data,labels = children_data.index,startangle = 60,autopct = '%1.1f%%')
plt.title('Customer Children')
plt.ylabel('Children')
plt.show()6)按客户的性别、收入绘制的箱形图,如下图:
列举以下三种方法:
【方法一】:采用DataFrame.boxplot(by,figsize)画图。(by为用于分组的列名)
【方法二】:采用DataFrame.plot(kind = 'box',title,...)画图。
【方法三】:采用plt.box(x,labels,boxprops,medianprops,whiskerprops...)画图。
#6)
#方法一
data[['income','sex']].boxplot(by = 'sex',figsize = (6,6))
plt.show()
#方法二
import pandas as pd
MALE_data = data[data['sex']=='MALE']['income']
FEMALE_data = data[data['sex']=='FEMALE']['income']
sex_data1 = pd.concat([FEMALE_data,MALE_data],axis = 1) #使用pd.concat函数合并两个series组成DataFrame
sex_data1.plot(kind = 'box',title = 'Boxplot grouped by sex income',grid = True,figsize = (6,6)) #df.plot中可设置画布大小
plt.xticks(range(1,3),['FEMALE','MALE'])
plt.xlabel('[sex]')
plt.show()
#方法三
plt.figure(figsize = (6,6))
MALE_data = data[data['sex']=='MALE']['income']
FEMALE_data = data[data['sex']=='FEMALE']['income']
labels = 'FEMALE','MALE'
#括号可加可不加,或者在下面加plt.boxplot([FEMALE_data,MALE_data],labels =( 'FEMALE','MALE'))
#或者单独加plt.xticks(range(1,3),['FEMALE','MALE'])
plt.boxplot([FEMALE_data,MALE_data],labels = labels,boxprops = {'color':'#1F77B4'},medianprops = {'color':'green'},whiskerprops={'color':'#1F77B4'}) #画多个箱线图要加[]
plt.grid()
plt.title('Boxplot grouped by sex income')
plt.xlabel('[sex]')
plt.show()