【ACL2021】Target-Oriented Fine-tuning for Zero-Resource Named Entity Recognition
【ACL2021】Target-Oriented Fine-tuning for Zero-Resource Named Entity Recognition
- 论文地址:https://arxiv.org/abs/2107.10523
- 代码地址:https://github.com/Yarkona/TOF
Abstrat
Zero-source的命名实体识别(NER)受特定领域(domain)和特定语言(language)的数据稀缺的困扰。因此许多任务通过在不同的相关任务上进行微调实现基于知识迁移的Zero-source的命名实体识别。
本文在domain、language和task进行知识迁移解决上述问题,并强调他们之间的联系。本文提出四个有效的guidelines来引导知识迁移和任务微调。基于这些guidelines,本文设计了一个目标导向的微调框架( target-oriented fine-tuning (TOF) framework)从以上三方面获取各种数据。
本文方法在六种基准模型,实验表明,我们的方法比起cross-domain和cross-lingual场景中,都有不错的效果。
Introduction
-
zero-resource的命名实体识别的任务定义:在一个特定领域或者语言,使用没有标注的训练数据进行NER。
-
zero-resource的命名实体识别的问题:数据缺失
如下理想的训练数据被看作是Targets,这些数据满足以下两个条件:
- 在目标领域或者目标语言当中
- 有标注
因此这些数据可以被用于从task、laguage和domain三方面来增强数据或者迁移知识。因此domain和language可以被分为source和target两个集合。主流的 zero-resource NER 就是从source domain/language迁移到target。如,从新闻到推特1、从英语到西班牙语2,其中前者是cross-domain,后者是cross-lingual。
最近的主流方法是微调模型,然后指出目前的cross-domain和cross-lingual的NER任务的两个问题:
- 只考虑target语料集的无标注数据和source语料集的标注数据,进行知识迁移
- 在各种辅助任务上进行微调,并且这个过程只进行一次,作者认为只进行一次不足以很好地捕捉知识,另外还缺乏有效地策略逼近Targets。
因此本文提出的四条指引(Guideline):
- 强调task、language和domain方面知识迁移的必要性;
- domain/language方面,关注源语料和目标语料之间的差异;
- task方面,关注非NER任务和NER任务的差距;
- 强调目标领域/语言和NER任务之间的知识迁移
然后得出了一个用于zero-resource NER任务的目标导向的微调架构(TOF)。该架构应用了三种任务(MLM、MRC、NER)来捕捉三个方面的知识。
Background
任务定义:zero-source NER就是从标注的源预料中学习到的知识,迁移到无标注的目标领域数据中。
因此,以下三种语料可被用于训练:
- NER任务的源标注语料;
- 无标注的目标语料
- 非NER任务的目标标注语料(MRC
本文方法的大概框架启发来自3,以下是大概的步骤:
1.领域微调
通过训练一个MLM来对上下文词嵌入进行微调,使之包含目标领域的数据。
2.任务微调
微调上下文词嵌入并学习序列标注任务的预测模型。
Our Approach
首先解释Domain、Language和Task三个方面,结合图1:

Domain
比如:Twitter,在图1中,“@”只存在于推特文本中,而“#”用来强调某物
Language
英语:As the tennis player is popularly known in Brazil
西班牙语:Como se conoce popularmente en Brasil al tenista
Task
表示对于不同任务的手工标注。如图一中,NER任务中的LOC、ORG等标签;MRC任务中,“W NJ"被作为问题的回答!
四个使用的指引
Background部分有提到,这些复制一下原文:
- Guideline-I: It is necessary to exploit available knowledge from domain, language, and task.
- Guideline-II: Bridge the gap between source domains/languages and target domains/languages.
- Guideline-III: Bridge the gap between annotations for non-NER tasks and NER task.
- Guideline-IV: Fuse the knowledge of both the target domain/language and NER task.
Target-Oriented Fine-tuning Framework
该框架包含了两个部分:
- 知识迁移:不仅是domain/language方面的迁移,还是任务知识方面的迁移;
- 微调
以上所有都遵循上面的四个指引,具体看图2:

Knowledge Transfer
以上包含了六种数据:
- 无标注NER数据集 D t , n o D_{t,no} Dt,no;
- 无标注NER数据集 D s , n o D_{s,no} Ds,no;
- 标注MRC数据集 D t , m D_{t,m} Dt,m;
- 标注MRC数据集 D s , m D_{s,m} Ds,m;
- 无标注NER数据集 D t , n o D_{t,no} Dt,no;
- 标注NER数据集 D s , n D_{s,n} Ds,n;
其中,1、3、5是目标领域;2、4、6是源领域。
对于指引一,就是如上分成的积累数据;对于指引二,要考虑source和target domain/language之间的差异,可以使用source和target的混合数据进行微调,另外还可以将源数据转化为目标数据的形式(如把源语言翻译成目标语言)。
Fine-tuning Process
基于AdaptaBERT,我们提出了一个在domain-tuning 和 task-tuning之间的微调任务,因此包含了三个微调任务。
- Masked Language Model (MLM)
我们模型使用 D t , n o D_{t,no} Dt,no和 D s , n o D_{s,no} Ds,no的混合数据集进行训练,使用3中的策略。
- Machine Reading Comprehension (MRC)
根据指引三,我们加入了一个span extraction的MRC任务。然后又以下几个好处:
- MRC能增强NER模型在span extraction方面的能力,更好地捕捉语义特征
- MRC框架被用于解决NER任务,并逐渐变成NER和其他任务的桥梁4;
- 最近的研究中,把许多其他任务看成MRC任务处理
- Named Entity Recognition (NER).
为了微调上下文的词嵌入和学习预测模型,将词向量输入线性分类层并使之每个token概率最大化。
Training

训练步骤要从可得到的数据和Target中知识的差距。所以包含了三个步骤:
- MRC Enhancing
通过连续的训练MLM f ( ⋅ , θ m l m ) f(·, θ_{mlm}) f(⋅,θmlm)、MRC g ( ⋅ , θ m r c ) g(·, θ_{mrc}) g(⋅,θmrc)和NER$h(·, θ_{ner}) $来微调上下文词向量。(Step-1∼3)
- Pseudo Data Enhancing
根据指引四,我们使用训练得到的NER模型(Step-3)来生成假的NER无标注数据 D ^ t , n \hat D_{t,n} D^t,n,然后通过假数据微调我们的NER模型$h(·, θ^{(0)}_{ner}) $。
- Continual Learning Enhancing
为了充分利用假数据和模仿我们的Targets,持续的微调MRC和NER模型使用我们的假数据(Step-6∼7),然后假的数据有以下三个特点:
- 假的标注NER数据可以通过在每一次迭代的微调NER模型后,进行优化;
- 假数据可以被转化为MRC的形式
- 假数据可以用于所有MRC和NER的训练
在Step8-9中,我们利用微调的NER模型来优化假数据,并且把它当作训练数据。
经过T轮迭代,我们NER模型 h ( ⋅ , θ ( T ) n e r ) h(·, θ(T)_{ner}) h(⋅,θ(T)ner)在无标注数据集上进行预测。
Experiments
- Cross-Lingual:CoNLL03 for German5、CoNLL02 for Dutch (nl) and Spanish6和三个作为target的MRC数据集(MLQA (es7)、XQuAD (de)8、 SQuAD (en)9)
- Cross-Domain:三个英文数据集(CBS SciTech News dataset10、Twitter NER11、WNUT1612),News(NewsQA13)、Twitter(TweetQA14)
本文方法实验结果:

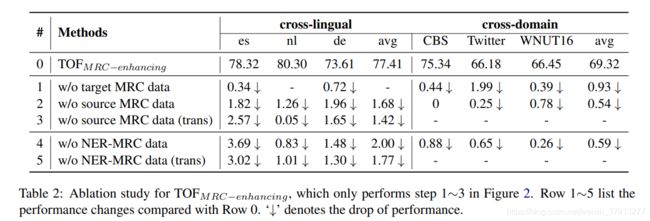
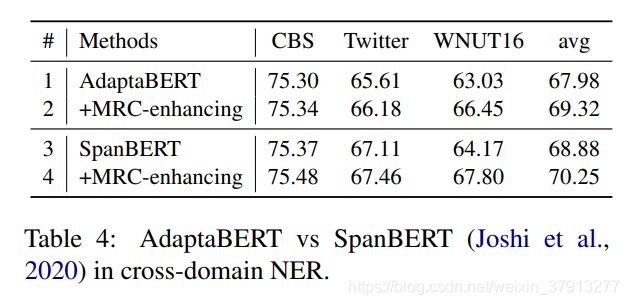
和SpanBERT对比效果:
思考
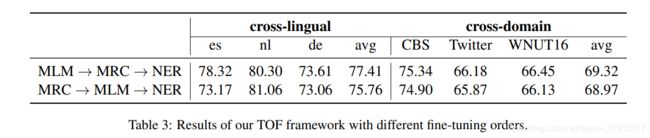
本文主要思路是通过Cross-Lingual和Cross-Domain的思想来解决NER任务中数据缺乏的问题。通过以上两个Cross任务,其中包含三个微调任务,然后这三个微调模型的的参数是逐层继承关系。再利用所得模型生成假数据,进行迭代地学习充分利用这些假数据,来获得一个NER模型。
Reference
Benjamin Strauss, Bethany Toma, Alan Ritter, MarieCatherine De Marneffe, and Wei Xu. 2016. Results of the wnut16 named entity recognition shared task. In Proceedings of the 2nd Workshop on Noisy Usergenerated Text (WNUT), pages 138–144. ↩︎
M Saiful Bari, Shafiq Joty, and Prathyusha Jwalapuram. 2020. Zero-resource cross-lingual named entity recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 7415–7423. ↩︎
Xiaochuang Han and Jacob Eisenstein. 2019. Unsupervised domain adaptation of contextualized embeddings for sequence labeling. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 4238–4248, Hong Kong, China. Association for Computational Linguistics. ↩︎ ↩︎
Xiaoya Li, Jingrong Feng, Yuxian Meng, Qinghong Han, Fei Wu, and Jiwei Li. 2020. A unified MRC framework for named entity recognition. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5849– 5859, Online. Association for Computational Linguistics. ↩︎
Erik F Tjong Kim Sang and Fien De Meulder. 2003. Introduction to the conll-2003 shared task: languageindependent named entity recognition. In Proceedings of the seventh conference on Natural language learning at HLT-NAACL 2003-Volume 4, pages 142– 147. ↩︎
Erik F. Tjong Kim Sang. 2002. Introduction to the CoNLL-2002 shared task: Language-independent named entity recognition. In COLING-02: The 6th Conference on Natural Language Learning 2002 (CoNLL-2002). ↩︎
Patrick S. H. Lewis, Barlas Oguz, Ruty Rinott, Sebastian Riedel, and Holger Schwenk. 2019. MLQA: evaluating cross-lingual extractive question answering. CoRR, abs/1910.07475. ↩︎
Mikel Artetxe, Sebastian Ruder, and Dani Yogatama. 2019. On the cross-lingual transferability of monolingual representations. CoRR, abs/1910.11856. ↩︎
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. Squad: 100, 000+ questions for machine comprehension of text. CoRR, abs/1606.05250. ↩︎
Chen Jia, Xiaobo Liang, and Yue Zhang. 2019. Crossdomain ner using cross-domain language modeling. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2464–2474. ↩︎
Qi Zhang, Jinlan Fu, Xiaoyu Liu, and Xuanjing Huang. 2018b. Adaptive co-attention network for named entity recognition in tweets. In AAAI, pages 5674– 5681 ↩︎
Benjamin Strauss, Bethany Toma, Alan Ritter, MarieCatherine De Marneffe, and Wei Xu. 2016. Results of the wnut16 named entity recognition shared task. In Proceedings of the 2nd Workshop on Noisy Usergenerated Text (WNUT), pages 138–144. ↩︎
Adam Trischler, Tong Wang, Xingdi Yuan, Justin Harris, Alessandro Sordoni, Philip Bachman, and Kaheer Suleman. 2016. Newsqa: A machine comprehension dataset. CoRR, abs/1611.09830. ↩︎
Wenhan Xiong, Jiawei Wu, Hong Wang, Vivek Kulkarni, Mo Yu, Shiyu Chang, Xiaoxiao Guo, and William Yang Wang. 2019. TWEETQA: A social media focused question answering dataset. CoRR, abs/1907.06292. ↩︎