RocketMQ-零拷贝
零拷贝
PageCache
由内存中的物理page组成,其内容对应磁盘上的block。
page cache的大小是动态变化的。
backing store: cache缓存的存储设备
一个page通常包含多个block, 而block不一定是连续的
读Cache
当内核发起一个读请求时, 先会检查请求的数据是否缓存到了page cache中。
如果有,那么直接从内存中读取,不需要访问磁盘, 此即 cache hit(缓存命中)
如果没有, 就必须从磁盘中读取数据, 然后内核将读取的数据再缓存到cache中, 如此后续的读请求就可以命中缓存了。
page可以只缓存一个文件的部分内容, 而不需要把整个文件都缓存进来
写Cache
当内核发起一个写请求时, 也是直接往cache中写入, 后备存储中的内容不会直接更新。
内核会将被写入的page标记为dirty, 并将其加入到dirty list中。
内核会周期性地将dirty list中的page写回到磁盘上, 从而使磁盘上的数据和内存中缓存的数据一致
cache回收
Page cache的另一个重要工作是释放page, 从而释放内存空间。
cache回收的任务是选择合适的page释放
如果page是dirty的, 需要将page写回到磁盘中再释放
cache和buffer的区别
-
Cache:缓存区,是高速缓存,是位于CPU和主内存之间的容量较小但速度很快的存储器,因为CPU的速度远远高于主内存的速度,CPU从内存中读取数据需等待很长的时间,而 Cache保存着CPU刚用过的数据或循环使用的部分数据,这时从Cache中读取数据会更快,减少了CPU等待的时间,提高了系统的性能。
Cache并不是缓存文件的,而是缓存块的(块是I/O读写最小的单元);Cache一般会用在I/O请求上,如果多个进程要访问某个文件,可以把此文件读入Cache中,这样下一个进程获取CPU控制权并访问此文件直接从Cache读取,提高系统性能。 -
Buffer:缓冲区,用于存储速度不同步的设备或优先级不同的设备之间传输数据;通过buffer可以减少进程间通信需要等待的时间,当存储速度快的设备与存储速度慢的设备进行通信时,存储慢的数据先把数据存放到buffer,达到一定程度存储快的设备再读取buffer的数据,在此期间存储快的设备CPU可以干其他的事情。
Buffer:一般是用在写入磁盘的,例如:某个进程要求多个字段被读入,当所有要求的字段被读入之前已经读入的字段会先放到buffer中。
HeapByteBuffer和DirectByteBuffer
HeapByteBuffer,是在jvm堆上面一个buffer,底层的本质是一个数组,用类封装维护了很多的索引(limit/position/capacity等)。
DirectByteBuffer,底层的数据是维护在操作系统的内存中,而不是jvm里,DirectByteBuffer里维护了一个引用address指向数据,进而操作数据。
HeapByteBuffer优点:内容维护在jvm里,把内容写进buffer里速度快;更容易回收
DirectByteBuffer优点:跟外设(IO设备)打交道时会快很多,因为外设读取jvm堆里的数据时,不是直接读取的,而是把jvm里的数据读到一个内存块里,再在这个块里读取的,如果使用DirectByteBuffer,则可以省去这一步,实现zero copy(零拷贝)
外设之所以要把jvm堆里的数据copy出来再操作,不是因为操作系统不能直接操作jvm内存,而是因为jvm在进行gc(垃圾回收)时,会对数据进行移动,一旦出现这种问题,外设就会出现数据错乱的情况
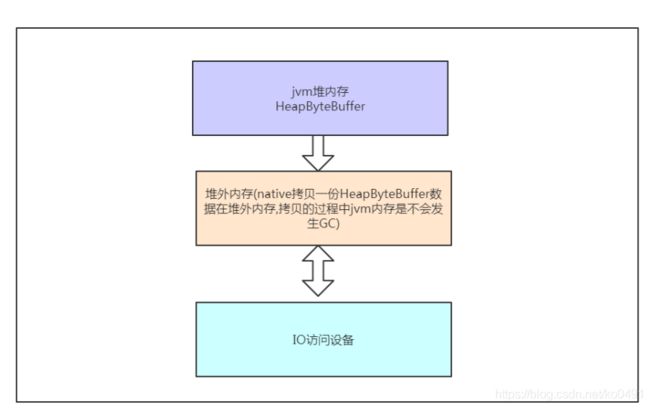
所有的通过allocate方法创建的buffer都是HeapByteBuffer.

堆外内存实现零拷贝
-
前者分配在JVM堆上(ByteBuffer.allocate()),后者分配在操作系统物理内存上
(ByteBuffer.allocateDirect(),JVM使用C库中的malloc()方法分配堆外内存); -
DirectByteBuffer可以减少JVM GC压力,当然,堆中依然保存对象引用,fullgc发生时也会回收直接内存,也可以通过system.gc主动通知JVM回收,或者通过 cleaner.clean主动清理。Cleaner.create()方法需要传入一个DirectByteBuffer对象和一个Deallocator(一个堆外内存回收线程)。GC发生时发现堆中的DirectByteBuffer对象没有强引用了,则调用Deallocator的run()方法回收直接内存,并释放堆中DirectByteBuffer的对象引用;
-
底层I/O操作需要连续的内存(JVM堆内存容易发生GC和对象移动),所以在执行write操作时需要将HeapByteBuffer数据拷贝到一个临时的(操作系统用户态)内存空间中,会多一次额外拷贝。而DirectByteBuffer则可以省去这个拷贝动作,这是Java层面的 “零拷贝” 技术,在netty中广泛使用
-
MappedByteBuffer底层使用了操作系统的mmap机制,FileChannel#map()方法就会返回MappedByteBuffer。DirectByteBuffer虽然实现了MappedByteBuffer,不过DirectByteBuffer默认并没有直接使用mmap机制。
缓冲IO和直接IO
缓存IO
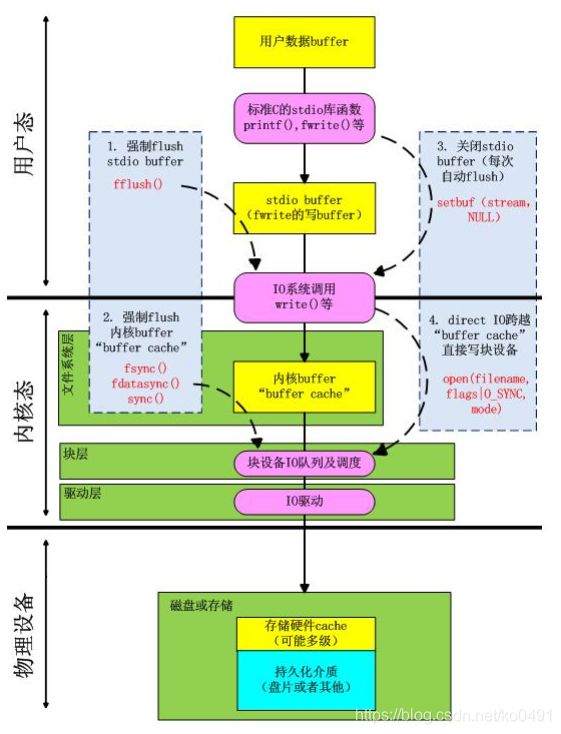
缓存I/O又被称作标准I/O,大多数文件系统的默认I/O操作都是缓存I/O。在Linux的缓存I/O机制中,数据先从磁盘复制到内核空间的缓冲区,然后从内核空间缓冲区复制到应用程序的地址空间。读操作:操作系统检查内核的缓冲区有没有需要的数据,如果已经缓存了,那么就直接从缓存中返回;否则从磁盘中读取,然后缓存在操作系统的缓存中。
写操作:将数据从用户空间复制到内核空间的缓存中。这时对用户程序来说写操作就已经完成,至于什么时候再写到磁盘中由操作系统决定,除非显示地调用了sync同步命令。
缓存I/O的优点:
- 在一定程度上分离了内核空间和用户空间,保护系统本身的运行安全;
- 可以减少读盘的次数,从而提高性能。
缓存I/O的缺点:
3. 在缓存 I/O 机制中,DMA 方式可以将数据直接从磁盘读到页缓存中,或者将数据从页缓存直
接写回到磁盘上,而不能直接在应用程序地址空间和磁盘之间进行数据传输。数据在传输过程
中就需要在应用程序地址空间(用户空间)和缓存(内核空间)之间进行多次数据拷贝操作,
这些数据拷贝操作所带来的CPU以及内存开销是非常大的
直接IO
直接IO就是应用程序直接访问磁盘数据,而不经过内核缓冲区,这样做的目的是减少一次从内核缓冲区到用户程序缓存的数据复制。比如说数据库管理系统这类应用,它们更倾向于选择它们自己的缓存机制,因为数据库管理系统往往比操作系统更了解数据库中存放的数据,数据库管理系统可以提供一种更加有效的缓存机制来提高数据库中数据的存取性能。
直接IO的缺点:如果访问的数据不在应用程序缓存中,那么每次数据都会直接从磁盘加载,这种直接加载会非常缓慢。通常直接IO与异步IO结合使用,会得到比较好的性能。
下图分析了写场景下的DirectIO和BufferIO
内存映射文件(Mmap)
在LINUX中我们可以使用mmap用来在进程虚拟内存地址空间中分配地址空间,创建和物理内存的映射关系。

- 映射关系可以分为两种
- 文件映射 磁盘文件映射进程的虚拟地址空间,使用文件内容初始化物理内存。
- 匿名映射 初始化全为0的内存空间
- 而对于映射关系是否共享又分为
- 私有映射(MAP_PRIVATE) 多进程间数据共享,修改不反应到磁盘实际文件,是一个copy-onwrite(写时复制)的映射方式。
- 共享映射(MAP_SHARED) 多进程间数据共享,修改反应到磁盘实际文件中
- 因此总结起来有4种组合
- 私有文件映射 多个进程使用同样的物理内存页进行初始化,但是各个进程对内存文件的修改不会共享,也不会反应到物理文件中
- 私有匿名映射 mmap会创建一个新的映射,各个进程不共享,这种使用主要用于分配内存(malloc分配大内存会调用mmap)。 例如开辟新进程时,会为每个进程分配虚拟的地址空间,这些虚拟地址映射的物理内存空间各个进程间读的时候共享,写的时候会copy-on-write。
- 共享文件映射 多个进程通过虚拟内存技术共享同样的物理内存空间,对内存文件 的修改会反应到实际物理文件中,他也是进程间通信(IPC)的一种机制。
- 共享匿名映射 这种机制在进行fork的时候不会采用写时复制,父子进程完全共享同样的物理内存页,这也就实现了父子进程通信(IPC).
mmap只是在虚拟内存分配了地址空间,只有在第一次访问虚拟内存的时候才分配物理内存。在mmap之后,并没有在将文件内容加载到物理页上,只上在虚拟内存中分配了地址空间。当进程在访问这段地址时,通过查找页表,发现虚拟内存对应的页没有在物理内存中缓存,则产生"缺页",由内核的缺页异常处理程序处理,将文件对应内容,以页为单位(4096)加载到物理内存,注意是只加载缺页,但也会受操作系统一些调度策略影响,加载的比所需的多
- 直接内存读取并发送文件的过程
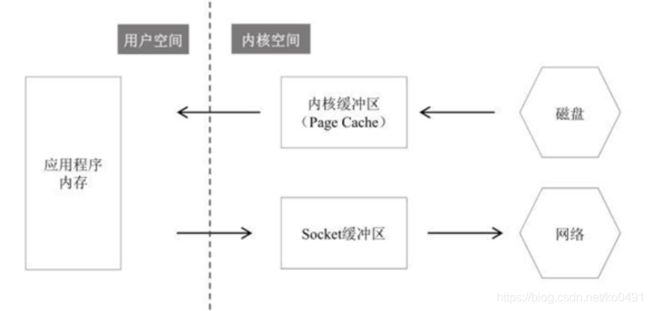
- Mmap读取并发送文件的过程
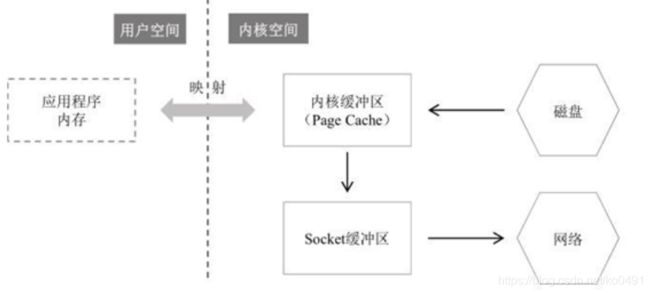
- Sendfile零拷贝读取并发送文件的过程
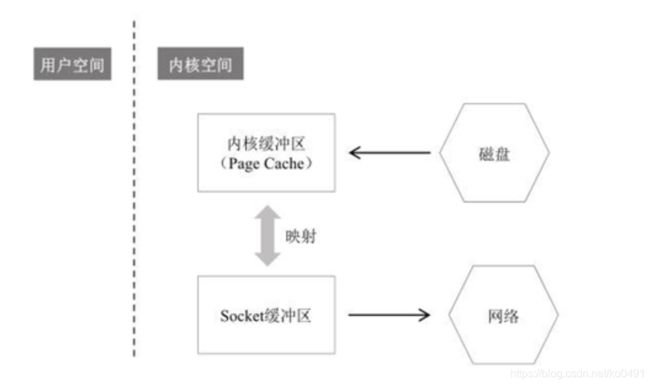
-
虽然叫零拷贝,实际上sendfile有2次数据拷贝的。第1次是从磁盘拷贝到内核缓冲区,第二次是从内核缓冲区拷贝到网卡(协议引擎)。如果网卡支持 SG-DMA(The Scatter-GatherDirect Memory Access)技术,就无需从PageCache拷贝至 Socket 缓冲区;
-
之所以叫零拷贝,是从内存角度来看的,数据在内存中没有发生过拷贝,只是在内存和I/O设备之间传输。很多时候我们认为sendfile才是零拷贝,mmap严格来说不算;
-
Linux中的API为sendfile、mmap,Java中的API为FileChanel.transferTo()、FileChannel.map()等;
-
Netty、Kafka(sendfile)、Rocketmq(mmap)、Nginx等高性能中间件中,都有大量利用操作系统零拷贝特性