干货 | 人工智能在视频领域的应用初探

近些年人工智能的热度很高,人工智能在视频领域的应用已经逐渐走入人们的生活,人脸识别,行为分析,车牌识别等等。
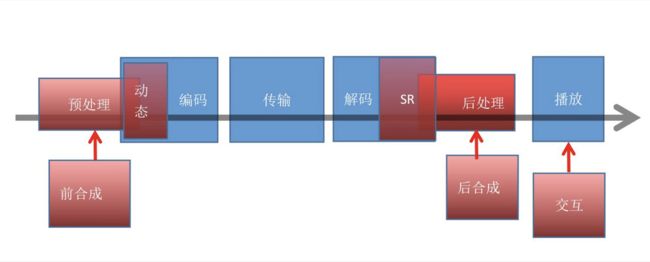
传统视频应用的流程:

一、人工智能对视频应用的渗透
目前的人工智能还处于工具阶段,能够渗透包括预处理和后处理,超分辨率,机器视觉等等,人们在这些过程中使用人工智能工具来提升开发效率或者处理效果。

在移动直播的环境下,在编码前,不影响画质的前提下,自动检测是否为弱网环境从而判断是否选择性丢帧,以降低编码环节的功耗开销。另一方面在弱网环境下带宽可能出现瓶颈,通过测速可进行动态码率切换,以保障网络推流流畅。
在播放前对视频中的人或物进行检测并处理,集成自动美颜、渲染等,以达到更好的观看效果。
近年来网络直播应用的兴起,出现了跟以往广播电视编解码不太一样的需求。那就是:
-
编码端,保证编码实时性和码率的要求的同时,保证尽量高的图像质量;
-
发送,传输,缓冲,延时尽量小;
-
解码器尽量能输出最好的质量,最好能超分辨率。
业内一直在努力把人工智能技术跟编解码做更深的融合,用来解决传统方法一直很难解决的这几个问题。
二、人工智能增强的编码器
当前编码器遇到的问题:硬件编码器性能好,但是图像质量差,码率高。软件编码器效率较低,遇到复杂视频,比如物体繁多,较大运动,闪光,旋转,既不能满足实时编码的需求,同时输出码率也出现较大抖动。对于网络应用来说是很大的障碍。
1、动态编码器
不同场景下编码保持恒定质量的码率:

编码时间和码率是正相关的,在码率暴涨的同时,编码时间也剧烈延长。对于低延时需求强烈的直播应用,会造成严重的卡顿。
一般就只好使用绝对不变码率ABR. 不同场景下ABR的图像质量:
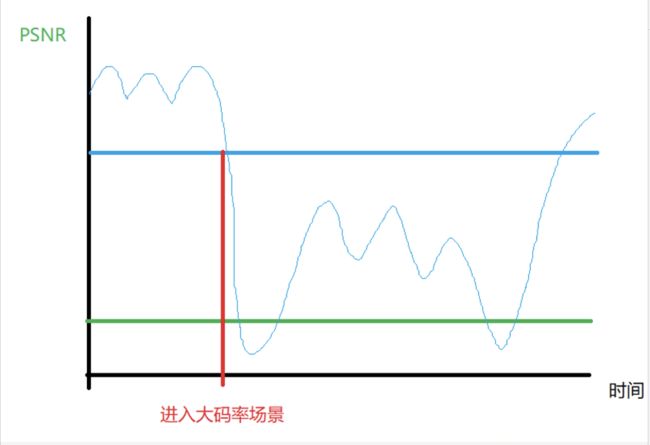
这样带来的结果就是图像质量不稳定。
我们希望是下图这样的曲线:
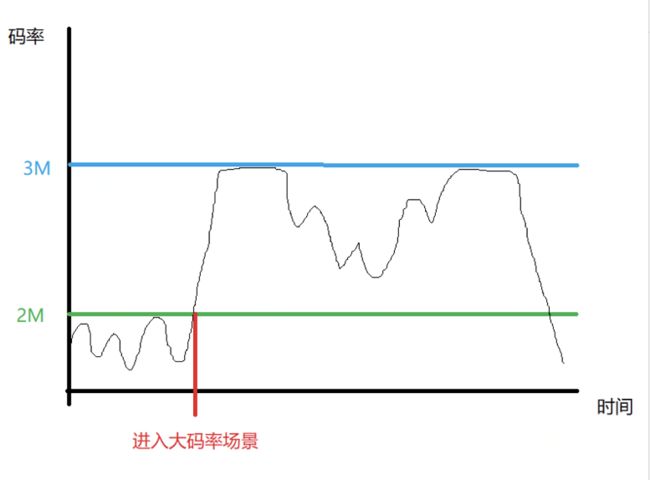
这就需要编码器能够提前判定大码率场景出现的可能性。需要判定的几种情况:
-
物体繁多且有摄像机运动;
-
背景不动但是有大量物体的大范围运动,包括快速运动,旋转,仿射,蠕变等;
-
出现闪光,风沙,粒子系统。
这就需要开发一种适用于高清晰度直播应用的面向场景的智能编码技术。该技术通过监督学习将常见视频编码卡顿场景分类并快速识别,提前预判视频场景的编码复杂度和码率抖动,使用动态参数配置来编码,保证编码的实时性和限定码率下最好的图像质量。
京东云基于业界领先的AI技术,提供对单人及多人的姿态预估技术,准确地判断出图片或视频中的人体14个主要关键点并给出相应的置信度,可应用于各个领域中的人体动作姿态分析、预估及检测。算法性能LIP Dataset(单人)mAP 90%;COCO val 2017(多人)mAP 80%,处于业内领先水平。

2、内容自动植入
这里说的广告的自动植入问题。一种是在编码前合成到视频里面,这个过程跟编码关系不大。但是直接合成到视频之后,所有的观众看到的内容就都一样。
要做到个性化,精准的广告投放,就只有在播放端解码后合成。要做到这点,服务器不仅要发送原始视频流,还要发送后期合成物体的定位方法和图像数据,以便客户端按照需求进行动态合成。
首先,自动植入的广告跟前贴片比起来优势很明显,可以植入的广告数量非常巨大,效果也更自然,用户也不会产生明显的反感。
其次,个性化精准投放,又进一步扩大了广告投放的总容量和效率。
京东云视频直播平台拥有领先的合成技术,除了字幕、广告外,还可以提供水印、静态或动态logo等功能,以增强视频的宣传力度和版权保护。

3、交互式视频
目前基本做法是图像识别后,与搜索引擎连接,产生一个内容链接。

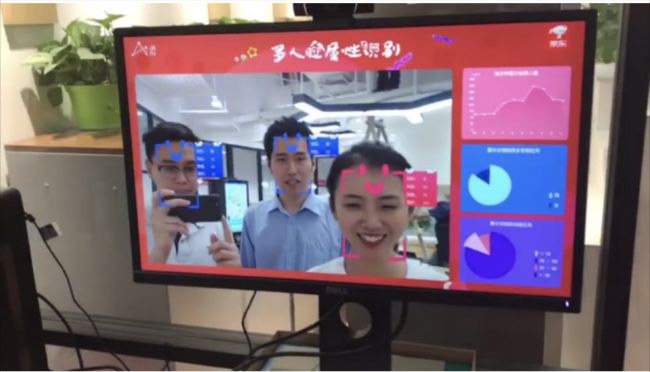
针对视频和图像中的人物,京东云提供的AI能力可对人脸进行搜索和比对实现企业、商业、住宅等多种场景的刷脸进门等功能,提升安全性、效率和用户体验用。
同时还可快速检测并定位人脸,返回高精度的人脸框坐标,五官与轮廓关键点和三维坐标,并且可识别多达9种人脸自然属性和5种情绪属性。
三、人工智能增强的解码器
当前解码器需要增强的点:大家都在构想能不能应用超分辨率技术,把较低分辨率的视频的播放质量提升一大块。目前有很多算法显示出巨大的潜力,比如谷歌的RAISR,处理图像时候效果很好。能不能实时用到视频上,或者硬件化,或者采用更快的能实时运行的算法。我们在后面会讨论一种折中方案,在牺牲一点质量的前提下,能够实时运行的超分辨率算法。
1、单个图像的超分辨率
自然图像基本上是平滑的纹理填充和较明显的边缘组合形成。
常规拉伸算法有双线性插值和双三次样条曲线差值。一般说来,三次曲线要比线性插值效果好。但实际简单的双线性插值的目视效果要好过三次曲线。
原因有以下几个:
1、低分辨率下线条会变得模糊。
2、低分辨率图像在拉伸到高分辨率时候会在线条上引入额外的模糊。
3、噪音的存在。
第1点不用过多解释,分辨率低了自然会模糊
第2点:比如B样条,三次样条曲线有一个应用条件,那就是样本数据本身应该是光滑的,至少是分段光滑。但是在图像里面,物体的边界和背景的结合处,就不满足这个条件了。普通的三次样条曲线插值并没有考虑图像内部各个物体的不同,简单的把整个图像作为一个整体来计算。这样必然就在边界处引入了严重的模糊。
因此超分辨率主要从以上几个方面进行处理。
那么如何降低线条的拉伸效应,也就是线条的锐度保持。
比如一个4x4的像素块,比较常见的是如下的形态:

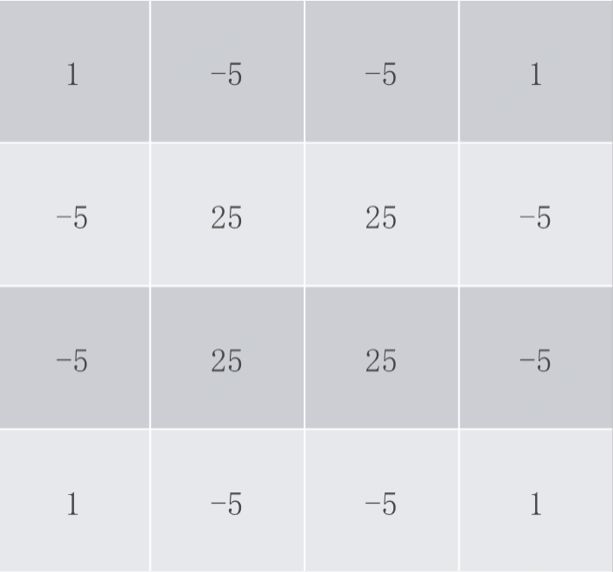
普通的三次b样条的滤波器参数矩阵为:
加入在4x4像素块中心插入一个点
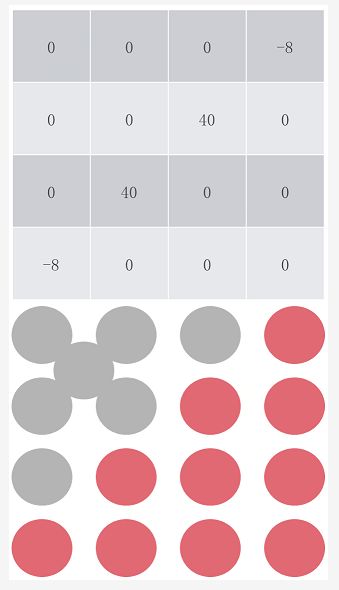
第一种情况,插入点在边界上:

使用标准滤波器:

使用改进滤波器:

第二种情况,插入点在边界内:

标准滤波:

第三种情况,插入点在边界外:

使用标准滤波器:

使用改进滤波器:
第三种情况与第一种一样。所以只需要考虑插入点在边界上的情况。
由于每个像素是8位的,所以一个4x4像素块可能的组合是大致128位整数。而现实中常出现的种类一般少于理论上限,因此需要考虑的组合往往不需要这么多。这种情况就需要使用统计方法,也就是通过机器学习来获得一个比较好的滤波器参数表。
机器学习过程通常是准备一些原始 HR 图象(2x2)和从采样生成的 LR(1x1)图象,作为配对数据。然后采用一些优化操作:
第一步,将复杂 4x4 梯度图象点阵处理成为简单的码本图象(HASH);
第二步,针对这个码本图象,使用考虑临近像素梯度权重的方法重构B样条滤波器参数,每次都和原始的 2x2 倍图象进行 SAD (COST函数)计算,寻找最接近的拟合曲线参数(下山法);
第三步,对上一步获得的大量参数计算概率分布,取最大概率的参数作为该码本的最优解;
第四步,对近似的码本进行合并处理,以减小码本的数量。
关于低分图像对边界造成的模糊,我们可以尝试使用一个梯度变换的方法:
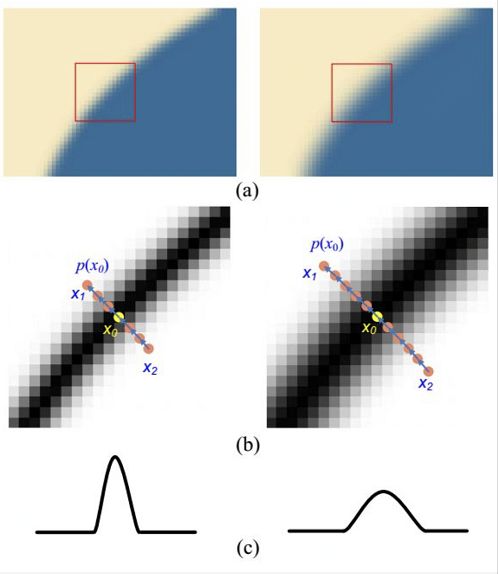
这种算法的思路就是计算出梯度的分布,然后适当把梯度收窄。不考虑实现速度的话,这个方法取得效果也是很惊人的。
但是这个算法的运算量非常庞大。因此需要把这个过程融合到寻找滤波器参数矩阵的过程中。
2、视频的超分辨率
上面是单个图像的超分辨率。视频的超分辨率和单个图像不同。单个图像的超分辨率算法可以融合到视频超分辨率里面来。
视频的超分辨率是从连续的视频序列中重新创建高分辨率的图像,涉及到图像配准和子像素提取。研究方法和评价方法也存在很大差异。有些人用图像的超分辨率方法来套用的话就会出现一些疑惑:
首先视频编码是一个有损压缩过程,不同分辨率的序列压缩退化过程是不同的,因此找不到合适的HR/LR配对。视频质量的评估也是远比图像质量评估要复杂。因此目视质量是一个比较简易的评估标准。当然寻找一个HR/LR配对来计算PSNR(峰值信噪比)也是可以的,但是说服力远不如图像配对的情况。
评估模型:
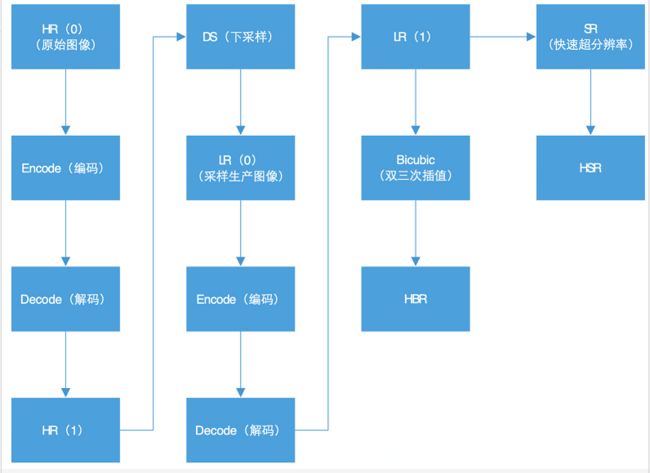
在这个过程中,因为原始视频(未经压缩)图像较大,所以HR(0)不适合用来做原始分辨率参照。我们可以选取HR(1)和HSR来比较获取一个PSNR(0), 然后选取HR(1)和普通拉伸获得的HBR来比较获取一个PSNR(1). 如果PSNR(0)比PSNR(1)要高的话,就说明超分辨取得了效果。
在视频直播和人工智能的结合方面,京东云一直在不断探索,我们希望可以基于京东云平台优质底层资源和领先的实施转码技术,为客户提供更加专业的一站式服务。
点击"京东云"了解更多详情
欢迎点击“京东云”了解更多精彩内容。

