零基础使用飞桨VisualDL轻松实现可视化调参
零基础使用飞桨VisualDL轻松实现可视化调参目录
- 零基础使用飞桨VisualDL轻松实现可视化调参
-
- 1 背景介绍
- 2 启动本地训练
-
- 2.1 准备工作
- 2.2 启动训练
- 2.3 调参并完成训练
- 3 使用VisualDL的Scalar功能对比分析本地训练日志
-
- 3.1 一行命令启动VDL本地训练日志可视化
- 3.2 分析经过VDL可视化处理后的训练日志
-
- 3.2.1 对比调节Batchsize对模型训练的影响
- 3.2.2 对比调节max_iters对模型训练的影响
- 4 使用VisualDL的VDL.service功能快速分享训练日志
-
- 4.1 一行命令调用VDL.service
- 5 结语
零基础使用飞桨VisualDL轻松实现可视化调参
VisualDL 是一个面向深度学习任务设计的可视化工具。VisualDL 利用了丰富的图表来展示数据,用户可以更直观、清晰地查看数据的特征与变化趋势,有助于分析数据、及时发现错误,进而改进神经网络模型的设计。
此篇分享将通过PaddleDetection完成一个简单的PCB电路版瑕疵目标检测的模型训练,并在此过程中跟大家分享如何在训练中使用VisualDL的Scalar和VDL.service功能来轻松实现可视化调参。
如有小伙伴对本地开发环境配置并不擅长,想尝试在线版项目,可前往我在AI Studio公开的一个项目,fork下来就能直接运行啦~
项目地址:https://aistudio.baidu.com/aistudio/projectdetail/1195160
1 背景介绍
-
通过使用VisualDL的Scalar功能,我们可以简单轻松地实现训练日志的可视化。
-
通过使用VisualDL的VDL.service功能,我们可以便捷高效地分享可视化后的训练结果。
-
此篇分享所使用的数据集是印刷电路板(PCB)瑕疵数据集,这是一个由北京大学发布的公共合成PCB数据集,其中包含1386张图像以及6种缺陷(缺失孔,鼠标咬伤,开路,短路,杂散,伪铜),用于检测,分类和配准任务。我们选取了其中适用与检测任务的693张图像,随机选择593张图像作为训练集,100张图像作为验证集。
-
此篇分享还使用到了PaddleDetection端到端目标检测开发套件,PaddleDetection旨在帮助开发者更快更好地完成检测模型的组建、训练、优化及部署等全开发流程。PaddleDetection模块化地实现了多种主流目标检测算法,提供了丰富的数据增强策略、网络模块组件(如骨干网络)、损失函数等,并集成了模型压缩和跨平台高性能部署能力。对此不太了解的小伙伴可以前往其官方仓库(https://github.com/PaddlePaddle/PaddleDetection)先做一个简单的了解。如过你是初次接触PaddleDetection,对安装配置这些并不了解,可以参考我之前在B站上发的一个安装教程(https://www.bilibili.com/video/BV1Lk4y1171x/)。
-
此篇分享提供配套的视频教程,地址是:https://www.bilibili.com/video/BV1WK4y1j7Db/,如有帮助,还请点个赞哦~
VisualDL开源的功能不只此篇分享里提到的Scalar和VDL.service,还有许多实用的功能,感兴趣的小伙伴欢迎前往VisualDL的官方GIthub查看更多细节,如觉得有所帮助,可以给VisualDL的仓库点个Star来支持官方把这个实用便捷的开源工具越做越好~
VisualDL的Github地址:https://github.com/PaddlePaddle/VisualDL
VIsualDL的Gitee地址:https://gitee.com/PaddlePaddle/VisualDL
2 启动本地训练
2.1 准备工作
-
需要在本地安装配置好CUDA且能正常调用padddlepaddle-gpu,视频教程可参考https://www.bilibili.com/video/BV1sV411y7uj/
-
在本地安装配置好PaddleDetection,视频教程可参考https://www.bilibili.com/video/BV1Lk4y1171x/
-
检查配置文件&文件路径设置是否正确,如,参数设置是否过高(batchsize过高,本地训练显存不足的情况下很容易出现显存溢出的问题),yml配置文件里的数据集地址是否正确(配置文件的数据集地址指向本地的如果是绝对路径形式的,那么就需要提前修改好,否则训练时很容易出现找不到数据集重新下载数据集的情况)
Tip:
- 如果本地的GPU不支持CUDA,或者算力太低、跑不动模型(跑起来太慢了),又或者是初次接触VisualDL,想体验一下VisualDL可视化模型训练的效果,但又不想做以上相对复杂的本地环境配置,可以使用AI Studio做为学习时模型训练的工具,可参考我之前分享的一个项目,零基础用VDL实现Anchor-Free系列模型训练日志可视化(https://aistudio.baidu.com/aistudio/projectdetail/1195160)。
- 训练需要的yml配置文件,我放在此项目打开后的
work路径下,PCB数据集也可以在打开项目后的data/data52914路径里找到,需要的小伙伴打开项目直接下载即可。
2.2 启动训练
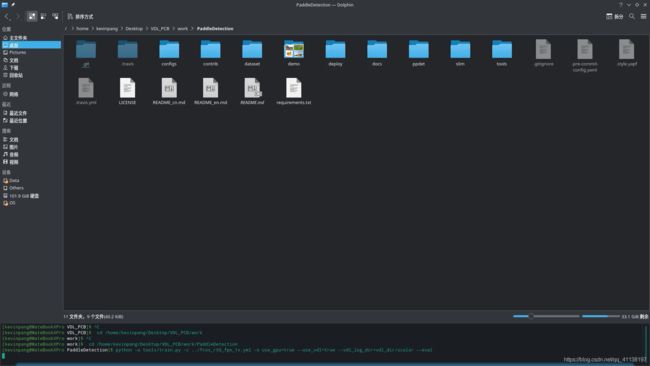
- 一行代码直接启动训练
python -u tools/train.py -c ../fcos_r50_fpn_1x.yml -o use_gpu=true --use_vdl=true --vdl_log_dir=vdl_dir/scalar --eval
2.训练中用到的参数说明:
“-c …/fcos_r50_fpn_1x.yml”:指定配置文件
“-o use_gpu=true”:设置配置文件里的参数内容,此处是设置使用GPU,使用-o配置相较于-c选择的配置文件具有更高的优先级
“–use_vdl=true”:使用VisualDL记录数据,进而在VisualDL面板中显示
“–vdl_log_dir=vdl_dir/scalar”:指定 VisualDL 记录数据的存储路径
“–eval”:开启边训练边测试
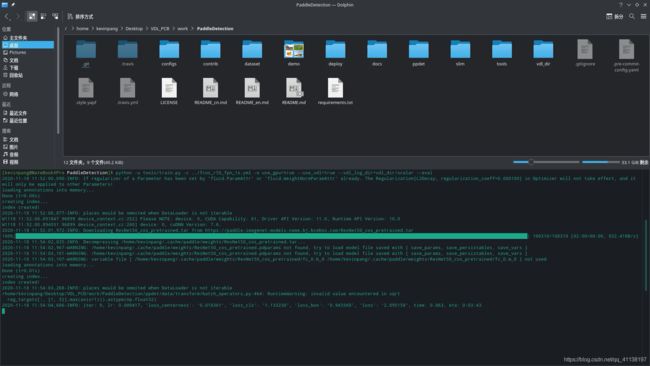
2.3 调参并完成训练
这里为了简单对比调参的效果,这里我用最简单的控制变量法来做个小的对比实验,来确定接下来的参数调整方向。
- 配置文件在默认参数下,训练完成后得到的训练日志(max_iters: 3558)
- 只将配置文件的batchsize增大一倍后,max_iters保持不变,训练得到的训练日志

- 只将配置文件的max_iters增大一倍,其余参数保持不变,训练得到的训练日志
3 使用VisualDL的Scalar功能对比分析本地训练日志
3.1 一行命令启动VDL本地训练日志可视化
本地调用VisualDL的Scalar功能来可视化训练日志的方法十分简单,一行命令即可~
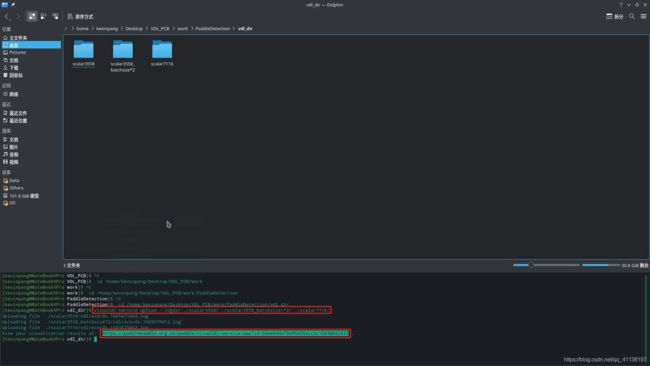
visualdl service upload --logdir ./scalar3558 ./scalar3558_batchsize\*2/ ./scalar7116/
使用说明:visualdl service upload --logdir [训练日志目录所在的路径地址]
3.2 分析经过VDL可视化处理后的训练日志
在浏览器直接打开命令之后返回的本地地址(此过程不需要联网),即可直接查看可视化的训练日志,以做进一步对比分析
3.2.1 对比调节Batchsize对模型训练的影响
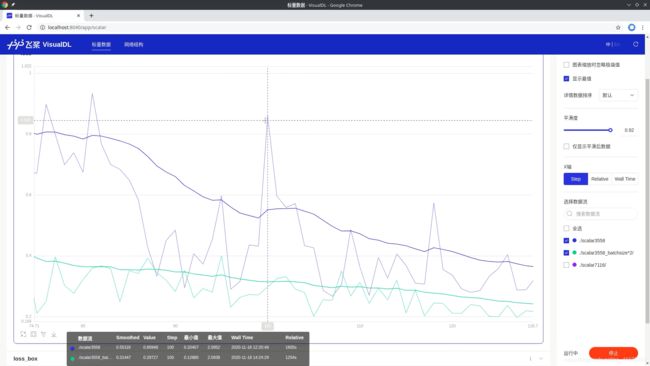
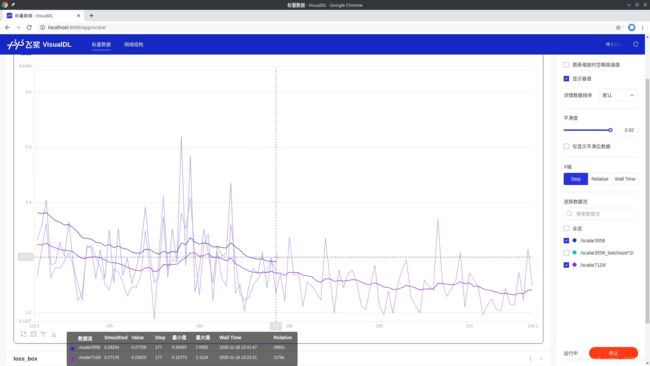
下图中,蓝色的是默认配置文件跑出的结果,绿色的是增大一倍batchsize之后跑出的结果,通过对比生成的两条折现可以发现,适当增大batchsize能有效降低losss值。

放大后,可以直观的看到增大batchsize所跑出的loss值折线的波动情况对比默认值得到了有效的改善。
3.2.2 对比调节max_iters对模型训练的影响
下图中,蓝色的是默认配置文件跑出的结果,紫色的是增大一倍max_iters之后跑出的结果,通过对比生成的两条折现可以发现,增大max_iters能有效降低loss值(但必然需要更多的时间,一般是在其他参数都调优完毕后才去调整这个值)。
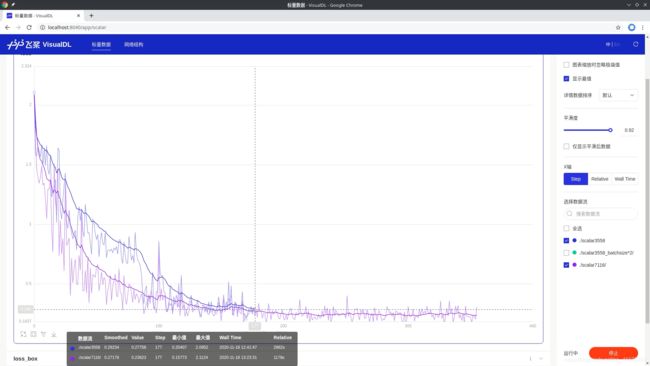
放大后,可以看到,只调整max_iters并不能使loss值折线的波动情况得到有效改善。
4 使用VisualDL的VDL.service功能快速分享训练日志
4.1 一行命令调用VDL.service
VDL.service能以链接形式将我们的可视化结果保存下来,此链接可在其他设备打开,便于我们分享展示训练结果,但是也有限制,为了保证服务器的安全和响应速度,目前VDL.service每两次请求之间需要间隔5min,上传的模型大小目前也被限制在100M以内(是的,目前还支持模型结构的展示,基础功能使用没问题之,感兴趣的小伙伴可以自行前往VisualDL的Github仓库查看相关文档~)
在调参遇到问题需要请教他人时,可以试试此方法,一条link胜过“千言万语”,此功能也是一行命令即可实现~(此功能需要联网)
visualdl service upload --logdir ./scalar3558 ./scalar3558_batchsize\*2/ ./scalar7116/
使用说明:visualdl service upload --logdir [训练日志目录所在的路径地址]
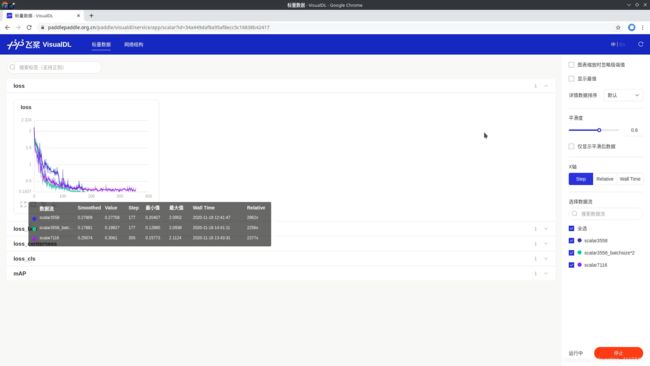
打开链接后,里面展示的内容和功能都跟本地的是一模一样的,感兴趣的小伙伴下次训练模型可以试试哦~
5 结语
在上面这个小案例中,通过使用VisualDL的Scalar功能可以直观清晰地对比可视化处理后的多组训练日志,进而发现通过适当增大batchsize和max_iters能有效改善模型训练结果(降低loss值),适当增大batchsize还能让模型训练过程更稳定。在此,我要说明一点,这里所展示的数据只是我这次训练所观察到的“现象”(这些数据每个我都跑过三次,由于篇幅原因,此案例分享就只展示其中随机选的一组结果,所以不是偶然出现的结果,可以用于指导我接下来的调参方向),这种训练时所得到的“现象”虽然不是结论,但能让我们接下来的调参更有方向,并不断积淀以形成我们的经验。如小伙伴对此感兴趣,可以找个自己感兴趣的模型先在AI Studio上训练训练。
因为VisualDL更多的还只是训练时辅助性的工具,所以,初次接触ViusalDL的小伙伴也不需要有太大压力,VisualDL仓库也有详细的使用说明,下面我贴上VisualDL仓库的地址:
VisualDL的Github地址:https://github.com/PaddlePaddle/VisualDL
VisualDL的Gitee地址:https://gitee.com/PaddlePaddle/VisualDL