【论文简述】Dense Hybrid Recurrent Multi-view Stereo Netwith Dynamic Consistency Checking(ECCV 2020)
一、论文简述
1. 第一作者:Jianfeng Yan、Zizhuang Wei、Hongwei Yi
2. 发表年份:2020
3. 发表期刊:ECCV
4. 关键词:MVS,深度学习,稠密混合循环MVSNet,动态一致性检查
5. 探索动机:分辨率、内存、深度图融合效率
- those deep learning based MVS methods still have the following problems. First, due to the memory limitation, some methods like MVSNet cannot deal with images with large resolutions. Then, RMVSNet are proposed to solve this problem, while the completeness and accuracy of reconstruction are compromised. Second, heavy backbones with downsampling module have to be used to extract features,which rely on large memory and lose information in the downsampling process. At last, those deep learning based MVS methods have to fuse the depth maps obtained by different images.The fusion criteria are set in a heuristic pre-defined manner for all data-sets, which lead to low complete results。
- All of the above methods have to fuse the depth maps from different reference images to obtain the final reconstructed dense point clouds by following the postprocessing in the non learning based MVS method COLMAP. In the postprocessing, consistency is checked in a pre-defined manner, which is not robust for different scenes and may miss some good points viewed by few images.
6. 工作目标:提高高分辨率MVS的计算速度并减少内存消耗,同时保证较高的重建质量。
7. 核心思想:提出了一种具有动态一致性检查的高效、有效的密集混合循环多视点立体网络D2HC-RMVSNet,在后处理中融合深度图,重建精确的稠密点云。
- 提出了一种新的轻量级DRENet来提取稠密特征图,用于稠密点云重建;
- 设计了一种混合结构DHU-LSTM,它吸收了LSTM和U-Net的优点,将3D匹配体正则化为包含不同层级信息的预测深度图,并输入LSTM,在保持重建精度的同时降低了内存开销;
- 设计了一种很有意义的动态一致性检查算法进行过滤,以保持更可靠和准确的深度值,并获得更完整的稠密点云。
8. 实验结果:该方法在复杂的室外Tanks and Temples基准测试中排名第一。在室内DTU数据集上的大量实验表明,与最先进的方法相比该方法表现出具有竞争力的性能,同时显着降低了内存消耗,其成本仅为R-MVSNet内存消耗的19:4%。
9. 论文&代码下载:
https://arxiv.org/pdf/2007.10872.pdf
http:// https://github.com/yhw-yhw/D2HC-RMVSNet
二、实现过程
1.DH-RMVSNet概述
DRENet从多视图图像中提取2D特征图,经过可微单应性形变和均方方差,生成3D代价体。HU-LSTM按照深度方向顺序处理3D代价体,用于进一步的训练或深度预测。

2. 图像特征提取器
通过连接来自不同扩展卷积层的特征图,设计了一个稠密感受扩张子网络,以在不损失分辨率的情况下聚合多尺度上下文信息。
给定N视图图像,令Ii=0, Ii=1···N−1分别表示参考图像和相邻源图像。首先使用两个正常卷积层来局部像素信息,然后使用三个具有不同膨胀的卷积层率2,3,4在不影响分辨率的情况下提取多尺度上下文信息。连接后DRENet可以高效地提取密集特征图Fi ∈C×H×W,其中C表示特征通道。

Conv和Deconv分别表示二维卷积和二维反卷积,GR是群归一化和ReLU的缩写。
3. 代价体
使用和MVSNet一样的方式构建代价体C。
4. 混合循环正则化
现有两种正则化的方式:There exists two different ways to regularize the cost volume C into one probability map P. One is to utilize the 3DCNN U-Net in MVSNet [33] which can well leverage local wise information and multi-scale context information, but it can not directly be used to regress the original dense depth map estimation due to limited GPU memory especially for large resolution images. The other is to use stacked convolutional GRU in R-MVSNet [34] which is quiet efficient by sequentially processing the 3D volume through the depth direction but loss the aggregation of multi-scale context information.
吸收了两种方法的优点,提出了具有比GRU更强大的循环卷积单元的混合循环正则化网络LSTMConvCell,并构建了一种混合U-LSTM,是一种新颖的2D U-net结构,每一层都是LSTMConvCell,可以按顺序处理。称这个模块为HU-LSTM。该算法可以很好地聚合多尺度的上下文信息,同时可以高效地处理稠密的原始大小的代价体。如下:

代价体C可视为D个2D代价图C(i)在深度假设方向上的连接。因此可以按顺序处理,第i步正则化后的输出为CH(i)。因此,CH(i)既依赖于当前输入代价图C(i),也依赖于之前所有状态CH (0,···,i−1)。在此使用循环单元 ConvLSTMCell,该单元具有三个门控来控制信息流,能够很好地聚合不同尺度的上下文信息。
HU-LSTM通过聚合不同尺度的上下文信息来提高深度估计的鲁棒性和准确性,采用3个LSTMConvCell来传播具有下采样比例0:5为的不同尺度的输入特征图,采用2个LSTMConvCell来聚合多尺度的上下文信息。具体来说,我们将32通道输入代价图Ci输入到第一个LSTMConvCell,每个LSTMConvCell的输出将被输入下一个LSTMConvCell。然后将正则化的代价匹配体CH(i) 经过softmax层,生成相应的概率体P,用于进一步计算训练损失。
5. 损失函数
多分类损失,在概率体P和真实深度图G之间使用相同的交叉熵损失函数L:
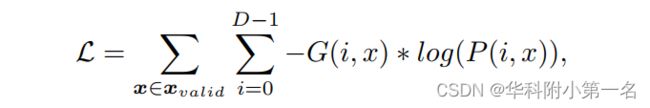
其中xvalid是有效像素的集合,G(i,x)表示像素x的真实的深度值G生成的one-hot向量,P(i,x)为相应的深度估计概率。在测试阶段,我们不需要保存整个概率图。为了进一步提高效率,对深度图进行了顺序处理,采用winner-take-all的方法,从正则化的代价体中生成估计后的深度图。
6. 动态一致性检查
得到深度图后要进行过滤再进行点云融合。先前的方法都使用预先定义参数的几何一致性,但是有缺点。
缺点:These parameters are defined intuitively and not robust for different scenes, though they have large influence on the quality of reconstruct point cloud. For example, those depth values with much high reliable consistency in two views are filtered and a fixed number valid views also lose information in the views with slightly worse errors. Beside, using the fixed τ1 and τ2 may not filter enough mismatched pixels in different scenes.
一般来说,当深度估计值在少数视图中重投影误差很小,或在大多数视图中误差较小时,深度估计值是准确可靠的。因此,提出了一种新的动态一致性检查算法来选择有效的深度值,这与重投影误差和视图数有关。通过将动态几何匹配代价考虑为所有邻居视图之间的一致性,可以得到更鲁棒、更完整的三维密集点云。表示参考图像Ii上像素p的估计深度值Di(p)。摄像机参数Pi = [Mi | ti]表示。首先,将像素p反投影到3D空间中以生成相应的3D点X通过:
![]()
然后将3D点X投影到相邻视图Ij上,生成投影像素q: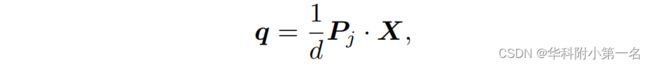
其中Pj为相邻视图Ij的相机参数,d为投影的深度。反过来,我们将邻居视图上的投影像素q用估计的深度Dj(q)反投影到3D空间中,并重新投影回参考图像p':
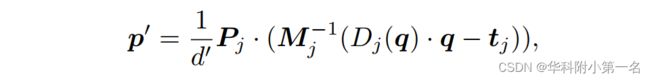
其中d'是参考图像上重投影的像素p’的深度值。基于上述运算,重投影误差计算为:
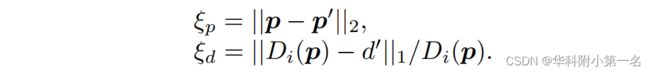
为了量化两个不同视图之间的深度匹配一致性,我们考虑了所有视图之间的动态匹配一致性,提出了动态匹配一致性。不同视图下的动态匹配一致性定义为:
![]()
其中λ用于平衡两个不同指标的重投影误差。通过聚合所有相邻视图的匹配一致性,得到全局动态多视图几何一致性Cgeo(p)为:

计算每个像素的动态几何一致性,并过滤掉Cgeo(p) < τ的离群值。得益于动态一致性检查算法,与之前的直觉固定阈值方法相比,过滤后的深度图能够存储更准确和完整的深度值。提高了三维重建点云的鲁棒性、完整性和准确性。
7. 实验
6.1. 数据集
DTU Dataset、Tanks and Temples Dataset
6.2. 实现
训练:PyTorch实现,使用DTU数据集训练。输入视图数N=3,深度值的样本总数设置为D = 128。使用Adam训练,学习率为0.001。批大小设置为6,并在2 NVIDIA TITAN RTX 上训练模型。
评估:对于DTU,设置输入图像数量N为7,深度值的样本总数设置为D = 256,使用逆深度。评估Tanks & Temples数据集,输入图像大小为1920 × 1056,相机位置、稀疏点云和深度范围由开源SfM软件OpenMVG得到。使用768 × 576分辨率的原始图像测试BlendedMVS数据集。
滤波与融合:首先,概率小于φ = 0:4的深度将被丢弃。然后,使用动态全局几何一致性检查算法进一步对多视图深度图滤波,λ = 200和τ = 1.8。
6.3. 结果
DTU数据集基准比较:SOTA
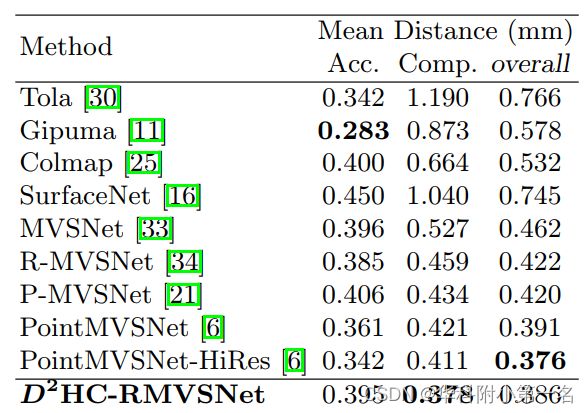

该方法生成的点云比其他方法更完整、更准确,证明了动态一致性检查算法的有效性。
Tanks & Temples泛化性:SOTA ,

BlendedMVS。BlendedMVS是一种基于Altizure的3D重建模型合成的大规模MVS数据集。数据集包含超过113个不同的场景,各种不同的相机轨迹。每个场景由20到1000个输入图像组成,包括建筑、雕塑和小物体。重建结果比R-MVSNet好。