R语言机器学习mlr3:嵌套重抽样
获取更多R语言和生信知识,请关注公众号:医学和生信笔记。
公众号后台回复R语言,即可获得海量学习资料!
目录
-
- 嵌套重抽样
-
- 进行嵌套重抽样
- 评价模型
- 把超参数应用于模型
嵌套重抽样
既有外部重抽样,也有内部重抽样,彼此嵌套,可以很好的解决过拟合问题,得到更加稳定的模型。
对于概念不清楚的可以自行百度学习,就不在这里赘述了。
可使用下图帮助理解: 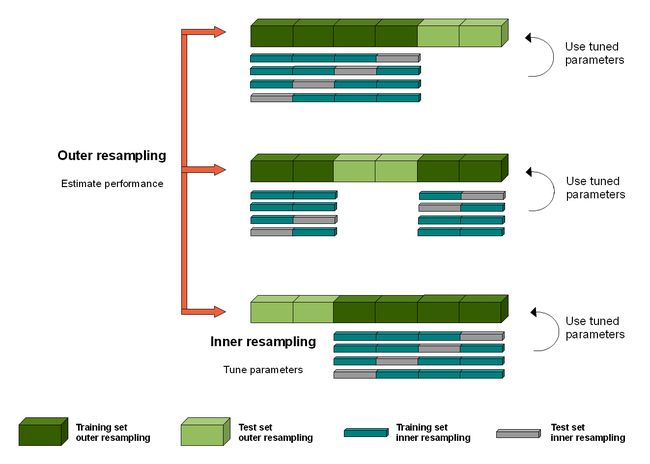
进行嵌套重抽样
内部使用4折交叉验证:
rm(list = ls())
library(mlr3verse)
library(mlr3tuning)
learner <- lrn("classif.rpart")
resampling <- rsmp("cv", folds = 4)
measure <- msr("classif.ce")
search_space <- ps(cp = p_dbl(lower = 0.001, upper = 0.1))
terminator <- trm("evals", n_evals = 5)
tuner <- tnr("grid_search", resolution = 10)
at <- AutoTuner$new(learner, resampling, measure, terminator, tuner,search_space)
外部使用3折交叉验证:
task <- tsk("pima")
outer_resampling <- rsmp("cv", folds = 3)
rr <- resample(task, at, outer_resampling, store_models = T)
## INFO [20:51:33.072] [mlr3] Applying learner 'classif.rpart.tuned' on task 'pima' (iter 3/3)
## INFO [20:51:34.416] [bbotk] 0.023 0.2382812
这里演示的数据集比较小,大数据可以使用并行化技术,将在后面介绍。
评价模型
提取内部抽样的模型表现:
extract_inner_tuning_results(rr)
## iteration cp classif.ce learner_param_vals x_domain task_id
## 1: 1 0.078 0.2812500 pima
## 2: 2 0.023 0.2382812 pima
## 3: 3 0.023 0.2480469 pima
## learner_id resampling_id
## 1: classif.rpart.tuned cv
## 2: classif.rpart.tuned cv
## 3: classif.rpart.tuned cv
提取内部抽样的存档:
extract_inner_tuning_archives(rr)
## iteration cp classif.ce x_domain_cp runtime_learners timestamp
## 1: 1 0.078 0.2812500 0.078 0.03 2022-02-27 20:51:33
## 2: 1 0.067 0.2871094 0.067 0.03 2022-02-27 20:51:33
## 3: 1 0.100 0.2812500 0.100 0.02 2022-02-27 20:51:33
## 4: 1 0.089 0.2812500 0.089 0.03 2022-02-27 20:51:33
## 5: 1 0.023 0.2949219 0.023 0.04 2022-02-27 20:51:33
## 6: 2 0.023 0.2382812 0.023 0.02 2022-02-27 20:51:34
## 7: 2 0.089 0.2617188 0.089 0.02 2022-02-27 20:51:34
## 8: 2 0.078 0.2617188 0.078 0.03 2022-02-27 20:51:34
## 9: 2 0.034 0.2421875 0.034 0.01 2022-02-27 20:51:34
## 10: 2 0.012 0.2382812 0.012 0.02 2022-02-27 20:51:34
## 11: 3 0.012 0.2519531 0.012 0.04 2022-02-27 20:51:33
## 12: 3 0.089 0.2636719 0.089 0.03 2022-02-27 20:51:33
## 13: 3 0.067 0.2519531 0.067 0.02 2022-02-27 20:51:33
## 14: 3 0.023 0.2480469 0.023 0.04 2022-02-27 20:51:33
## 15: 3 0.078 0.2636719 0.078 0.04 2022-02-27 20:51:33
## batch_nr warnings errors resample_result task_id learner_id
## 1: 1 0 0 pima classif.rpart.tuned
## 2: 2 0 0 pima classif.rpart.tuned
## 3: 3 0 0 pima classif.rpart.tuned
## 4: 4 0 0 pima classif.rpart.tuned
## 5: 5 0 0 pima classif.rpart.tuned
## 6: 1 0 0 pima classif.rpart.tuned
## 7: 2 0 0 pima classif.rpart.tuned
## 8: 3 0 0 pima classif.rpart.tuned
## 9: 4 0 0 pima classif.rpart.tuned
## 10: 5 0 0 pima classif.rpart.tuned
## 11: 1 0 0 pima classif.rpart.tuned
## 12: 2 0 0 pima classif.rpart.tuned
## 13: 3 0 0 pima classif.rpart.tuned
## 14: 4 0 0 pima classif.rpart.tuned
## 15: 5 0 0 pima classif.rpart.tuned
## resampling_id
## 1: cv
## 2: cv
## 3: cv
## 4: cv
## 5: cv
## 6: cv
## 7: cv
## 8: cv
## 9: cv
## 10: cv
## 11: cv
## 12: cv
## 13: cv
## 14: cv
## 15: cv
可以看到和上面的结果是不一样的哦,每一折都有5次迭代,这就和我们设置的参数有关系了。
查看外部重抽样的模型表现:
rr$score()[,9]
## classif.ce
## 1: 0.2460938
## 2: 0.2656250
## 3: 0.2890625
查看平均表现:
rr$aggregate()
## classif.ce
## 0.2669271
把超参数应用于模型
at$train(task)
## INFO [20:51:34.578] [bbotk] Starting to optimize 1 parameter(s) with '' and ' [n_evals=5, k=0]'
## INFO [20:51:34.580] [bbotk] Evaluating 1 configuration(s)
## INFO [20:51:34.994] [bbotk] 0.012 0.2434896
现在模型就可以应用于新的数据集了。
以上过程也是有简便写法的,但是需要注意,这里的mlr3tuning需要用github版的,cran版的还有bug,不知道修复了没:
rr1 <- tune_nested(
method = "grid_search",
resolution = 10,
task = task,
learner = learner,
inner_resampling = resampling,
outer_resampling = outer_resampling,
measure = measure,
term_evals = 20,
search_space = search_space
)
## INFO [20:51:35.045] [mlr3] Applying learner 'classif.rpart.tuned' on task 'pima' (iter 1/3)
## INFO [20:51:37.689] [bbotk] 0.089 0.2441406
这个rr1本质上和rr是一样的,
print(rr1)
## of 3 iterations
## * Task: pima
## * Learner: classif.rpart.tuned
## * Warnings: 0 in 0 iterations
## * Errors: 0 in 0 iterations
print(rr)
## of 3 iterations
## * Task: pima
## * Learner: classif.rpart.tuned
## * Warnings: 0 in 0 iterations
## * Errors: 0 in 0 iterations
查看内部抽样表现:
extract_inner_tuning_results(rr1)
## iteration cp classif.ce learner_param_vals x_domain task_id
## 1: 1 0.100 0.2578125 pima
## 2: 2 0.012 0.2500000 pima
## 3: 3 0.089 0.2441406 pima
## learner_id resampling_id
## 1: classif.rpart.tuned cv
## 2: classif.rpart.tuned cv
## 3: classif.rpart.tuned cv
提取归档资料:
extract_inner_tuning_archives(rr1)
## iteration cp classif.ce x_domain_cp runtime_learners timestamp
## 1: 1 0.100 0.2578125 0.100 0.01 2022-02-27 20:51:35
## 2: 1 0.034 0.2578125 0.034 0.03 2022-02-27 20:51:35
## 3: 1 0.001 0.2832031 0.001 0.04 2022-02-27 20:51:35
## 4: 1 0.023 0.2734375 0.023 0.05 2022-02-27 20:51:35
## 5: 1 0.078 0.2578125 0.078 0.03 2022-02-27 20:51:35
## 6: 1 0.067 0.2578125 0.067 0.04 2022-02-27 20:51:35
## 7: 1 0.012 0.2910156 0.012 0.01 2022-02-27 20:51:35
## 8: 1 0.089 0.2578125 0.089 0.01 2022-02-27 20:51:35
## 9: 1 0.056 0.2578125 0.056 0.03 2022-02-27 20:51:35
## 10: 1 0.045 0.2578125 0.045 0.04 2022-02-27 20:51:35
## 11: 2 0.089 0.2597656 0.089 0.02 2022-02-27 20:51:36
## 12: 2 0.056 0.2597656 0.056 0.03 2022-02-27 20:51:36
## 13: 2 0.100 0.2636719 0.100 0.04 2022-02-27 20:51:36
## 14: 2 0.067 0.2519531 0.067 0.02 2022-02-27 20:51:36
## 15: 2 0.045 0.2558594 0.045 0.02 2022-02-27 20:51:36
## 16: 2 0.001 0.2675781 0.001 0.05 2022-02-27 20:51:36
## 17: 2 0.078 0.2597656 0.078 0.01 2022-02-27 20:51:36
## 18: 2 0.034 0.2558594 0.034 0.04 2022-02-27 20:51:36
## 19: 2 0.012 0.2500000 0.012 0.03 2022-02-27 20:51:36
## 20: 2 0.023 0.2597656 0.023 0.02 2022-02-27 20:51:36
## 21: 3 0.089 0.2441406 0.089 0.02 2022-02-27 20:51:36
## 22: 3 0.034 0.2500000 0.034 0.03 2022-02-27 20:51:37
## 23: 3 0.100 0.2441406 0.100 0.00 2022-02-27 20:51:37
## 24: 3 0.023 0.2617188 0.023 0.04 2022-02-27 20:51:37
## 25: 3 0.067 0.2441406 0.067 0.03 2022-02-27 20:51:37
## 26: 3 0.045 0.2441406 0.045 0.03 2022-02-27 20:51:37
## 27: 3 0.001 0.2832031 0.001 0.03 2022-02-27 20:51:37
## 28: 3 0.078 0.2441406 0.078 0.04 2022-02-27 20:51:37
## 29: 3 0.012 0.2675781 0.012 0.04 2022-02-27 20:51:37
## 30: 3 0.056 0.2441406 0.056 0.02 2022-02-27 20:51:37
## iteration cp classif.ce x_domain_cp runtime_learners timestamp
## batch_nr warnings errors resample_result task_id learner_id
## 1: 1 0 0 pima classif.rpart.tuned
## 2: 2 0 0 pima classif.rpart.tuned
## 3: 3 0 0 pima classif.rpart.tuned
## 4: 4 0 0 pima classif.rpart.tuned
## 5: 5 0 0 pima classif.rpart.tuned
## 6: 6 0 0 pima classif.rpart.tuned
## 7: 7 0 0 pima classif.rpart.tuned
## 8: 8 0 0 pima classif.rpart.tuned
## 9: 9 0 0 pima classif.rpart.tuned
## 10: 10 0 0 pima classif.rpart.tuned
## 11: 1 0 0 pima classif.rpart.tuned
## 12: 2 0 0 pima classif.rpart.tuned
## 13: 3 0 0 pima classif.rpart.tuned
## 14: 4 0 0 pima classif.rpart.tuned
## 15: 5 0 0 pima classif.rpart.tuned
## 16: 6 0 0 pima classif.rpart.tuned
## 17: 7 0 0 pima classif.rpart.tuned
## 18: 8 0 0 pima classif.rpart.tuned
## 19: 9 0 0 pima classif.rpart.tuned
## 20: 10 0 0 pima classif.rpart.tuned
## 21: 1 0 0 pima classif.rpart.tuned
## 22: 2 0 0 pima classif.rpart.tuned
## 23: 3 0 0 pima classif.rpart.tuned
## 24: 4 0 0 pima classif.rpart.tuned
## 25: 5 0 0 pima classif.rpart.tuned
## 26: 6 0 0 pima classif.rpart.tuned
## 27: 7 0 0 pima classif.rpart.tuned
## 28: 8 0 0 pima classif.rpart.tuned
## 29: 9 0 0 pima classif.rpart.tuned
## 30: 10 0 0 pima classif.rpart.tuned
## batch_nr warnings errors resample_result task_id learner_id
## resampling_id
## 1: cv
## 2: cv
## 3: cv
## 4: cv
## 5: cv
## 6: cv
## 7: cv
## 8: cv
## 9: cv
## 10: cv
## 11: cv
## 12: cv
## 13: cv
## 14: cv
## 15: cv
## 16: cv
## 17: cv
## 18: cv
## 19: cv
## 20: cv
## 21: cv
## 22: cv
## 23: cv
## 24: cv
## 25: cv
## 26: cv
## 27: cv
## 28: cv
## 29: cv
## 30: cv
## resampling_id
查看模型表现:
rr1$aggregate()
## classif.ce
## 0.2682292
rr1$score()
## task task_id learner learner_id
## 1: pima classif.rpart.tuned
## 2: pima classif.rpart.tuned
## 3: pima classif.rpart.tuned
## resampling resampling_id iteration prediction
## 1: cv 1
## 2: cv 2
## 3: cv 3
## classif.ce
## 1: 0.2539062
## 2: 0.2578125
## 3: 0.2929688
注意,使用
tune_nested()之后,并没有提供方法应用于新的数据集,在咨询开发者之后,得到的说法是:tune_nested()是一种评估算法在整个数据集中的表现的方法,不是用于挑选合适的超参数的方法。重抽样过程会产生很多超参数组合,不应该用于模型中。
获取更多R语言和生信知识,请关注公众号:医学和生信笔记。
公众号后台回复R语言,即可获得海量学习资料!