深度学习-数据加载
深度学习中第一步就是加载数据
目录
数字数据加载
1.原始方法
numpy.loadtxt
panda的pd.read_csv
2.使用DataLoader和Dataset加载数据
Dataset
DataLoader
图片数据加载
1.直接从文件中加载图片
2.从字节流中加载图片
数字数据加载
1.原始方法
numpy.loadtxt
xy = np.loadtxt('diabetes.csv.gz',delimiter=',',dtype=np.float32)
x_data = torch.from_numpy(xy[:,:-1])#所有行,除最后一列外,其他列都要
y_data = torch.from_numpy(xy[:,[-1]])#所有行的最后一列,加【】是因为要的是一个向量,不加【】就是一列数使用原始方法获取数据,训练时直接使用即可
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
print("epoch:",epoch," loss:",loss.item())
optimizer.zero_grad()#梯度归零,
loss.backward()
optimizer.step()#权值更新panda的pd.read_csv
xy = np.loadtxt(filepath,delimiter=',',dtype=np.float32)两者的区别在于
- loadtxt以array的形式读取数据,而read_csv以dataframe(matrix)的形式读取数据;
- dataframe的优势是可以对数据进行很多操作,例如缺失值处理、合并或截取数据等;不需要考虑每一列的数据的类型是什么。
- ndarry的优势在于支持并行化运算,但使用前要对数据的类型进行处理
2.使用DataLoader和Dataset加载数据
Dataset
抽象类,用户继承该类自定义数据类
以获取糖尿病数据为例
糖尿病数据是8个特征位,1个结果
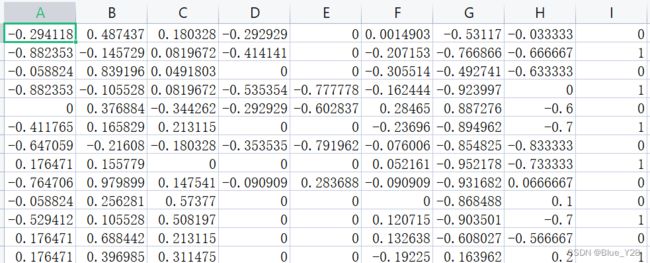
class DiabetesDataset(Dataset):
def __init__(self,filepath):
xy = np.loadtxt(filepath,delimiter=',',dtype=np.float32)
self.len = xy.shape[0]#xy是一个n行m列的矩阵,shape方法会拿到(n,m),则shape【0】表示取出n的值
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:,[-1]])
def __getitem__(self, item):
return self.x_data[item],self.y_data[item]
def __len__(self):
return self.len类方法说明:
- getitem():当用户使用索引时,就会调用这个方法
- len():当用户想要获取长度时,就会调用这个方法
构造数据集时一般有两种方法
- 在init函数中将所有的数据都加载进来,读到内存,使用索引来获取数据,适合本身数据集容量不大
- 定义一个列表,列表的每一项是文件名,真实的数据存放在文件中,适用于如图像文件等数据很大的问题,使用时根据索引读出想要的文件中的数据,可以保证内存的高效使用
DataLoader
pytorch提供的数据加载器,直接实例化使用即可

- dataset:数据集名称,
- batch-size:一个小批量的大小,
- shuffle:是否打乱
- sampler:从数据集中加载的数据所采用的策略,如果指定,shuffle需为false
- batch_sampler:表示一次返回一个batch的index
- num_workers:读取数据时是否是多线程并行。=0表示使用主线程加载数据;当>0时表示采取指定数量的线程来加载进程,此时主进程不参与加载数据
- collate_fn:表示合并样品列表以形成小批量的Tensor对象
- pin_memory:表示将load进来的数据是否要拷贝到pin_memory区中,默认为False
- drop_last:当整个数据长度不能整除batch_size,选择是否要丢弃最后一个不完整的batch,默认为False
#使用时传入数据集的文件路径
dateset = DiabetesDataset('diabetes.csv.gz')
#实例化加载器
train_loader = DataLoader(dataset=dateset, batch_size=32, shuffle=True, num_workers=0)每次需要先自定义数据集dataset,然后通过数据加载器dataloader规定是如何加载的,是否要打乱,每个batch的大小等参数
通过这种方式加载数据是如何训练
for epoch in range(100):
for i,data in enumerate(train_loader,0):#每次都会读出一个batch的数据,返回(x,y)元组
inputs,lables = data
y_pred = model(inputs)
loss = criterion(y_pred,lables)
print(epoch,i,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()由于作者对enumerate不熟,所以想看看每次遍历返回的是啥
for epoch in range(100):
for i,data in enumerate(train_loader,0)
print("i=",i," data=",data)结果部分截图
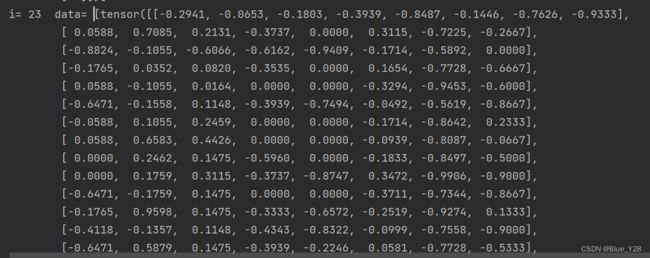
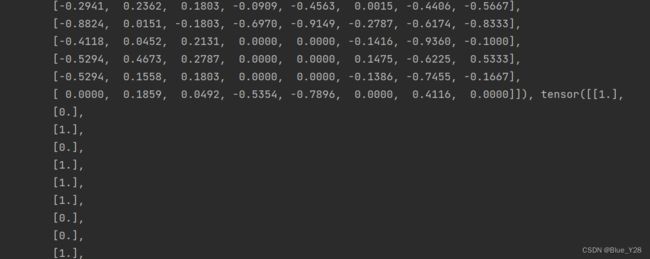 这里返回的每个data是两个向量,一个32*8的向量(x),一个32*1的向量(y)
这里返回的每个data是两个向量,一个32*8的向量(x),一个32*1的向量(y)
由此得出结论i表示下标,data表示loader中可遍历的数据对象,在这里每个data就是(x,y)这样一个元组,x和y都是一个向量,向量的维度是在加载器实例化的时候规定的
图片数据加载
1.直接从文件中加载图片
import cv2
import numpy as np
img = cv2.imread('picture.jpg',cv2.IMREAD_GRAYSCALE)
cv2.imshow('image',img)#展示图片
cv2.waitKey(0)
#图片尺寸大小
(h, w, d) = image.shape
print("width={}, height={}, depth={}".format(w, h, d))
该方法的缺点是图片的路径不能包含中文
如果图片路径包含中文采用以下方式
import cv2
import numpy as np
img = cv2.imdecode(np.fromfile(img_path,dtype=np.uint8),-1)
cv2.imshow('image',img)
cv2.waitKey(0)2.从字节流中加载图片
import cv2
import numpy as np
np_arr = np.fromstring(bytes, np.uint8)
# 加载彩色图片
img = cv2.imdecode(np_arr, cv2.IMREAD_COLOR)
cv2.imshow('image',img)
cv2.waitKey(0)