燃!阿里AI技术取得重大突破:连破中、英语言处理两项世界纪录
日前,阿里巴巴披露了自然语言处理技术取得的两项新成绩:在全球顶级的知识库构建测评KBP2017中,斩获英文实体发现测评全球冠军;在中文语法错误自动诊断大赛(Chinese Grammatical Error Diagnosis,以下简称 CGED)三个level中全面夺得冠军,核心指标比其他参赛机构高出一倍。

iDST自然语言处理首席科学家司罗
司罗是全球权威机器智能学者,曾担任美国普渡大学计算机系终身教授,先后获得美国国家科学基金会成就奖、雅虎、谷歌研究奖等。在阿里巴巴,司罗领导了iDST自然语言处理团队,他们的使命是支持阿里大生态(新零售、金融、物流、娱乐、旅行等)的自然语言处理需求;通过阿里云技术输出,赋能广大全网合作者,创造更多商业机会;沉淀技术,和学界、工业界合作者一起创新自然语言技术。
比赛中使用的分词、词性标注和句法分析等基础NLP工具都是由该团队自主研发的AliNLP 平台。该平台支持阿里大生态(新零售、金融、物流、娱乐、旅行等)的每天多达600亿次的自然语言处理需求。团队横跨中国(杭州,北京)和美国(硅谷,西雅图),普遍拥有10年以上自然语言处理研发经验,30%以上有博士学历(如CMU,伯克利,普林斯顿,清华,北大等)。 团队多次在国际自然语言技术竞赛中取得冠军成绩。
本次KBP比赛团队主力 Zhang Qiong, Zhao HuaSha, Yang Yi等;2017 CGED比赛团队主力李林琳,谢朋峻,杨毅等。
阿里巴巴夺实体发现测评全球第一

两场比赛中,KBP是由NIST(National Institute of Standards and Technology,美国国家标准与技术研究院)指导、美国国防部协办的赛事,主要任务为从自然书写的非结构化文本中抽取实体,以及实体之间的关系。这次测评吸引了全球20多支顶尖团队参与,包括IBM Research, BBN, Stanford Univ, CMU Univ, UIUC Univ, Columbia Univ, 腾讯等。
这项测评要求AI算法在“读完”一篇英文文章后,构建一个物理世界的命名实体和实体之间关系的知识库,如“克林顿和希拉里之间是夫妻关系”、“克林顿毕业于耶鲁法学院”这样一个个实体的关系。
司罗介绍,阿里的算法可以做到对文章上下文的理解。比如,文章出现了Apple,再出现Jobs,就可以辨别出这个Jobs指的是乔布斯,而不是工作。再比如,文章出现了Microsoft,那么Apple就更有可能是苹果公司,而不是一种水果。
“另外,我们构建了一个算法去学习不同领域之间共同的部分,通过迁移学习提升我们学习的准确度。对于不同领域数据,我们取其精华,去其糟粕,进行智能学习”,司罗说。
在这次测评中,iDST团队采用经过改良的深度神经网络架构对文本进行理解。改良的架构有三个主要特点:首先该模型可以自动阅读海量文章(如维基百科)并从中汲取经验;其次,该架构可以智能选择训练数据集以保证训练数据的准确性;最后,采用post regularization的办法保证模型结果的一致性。
对于KBP2017的成绩,司罗表示:“很荣幸能够同全球的同行分享阿里巴巴的研究成果,人工智能在机器阅读理解和知识库构建上还处在起步阶段,我们正在积极和同行业顶尖机构学习交流,推动行业发展。比如我们内部建设的信息抽取平台AliIE项目就在同斯坦福大学展开积极合作”。
阿里巴巴正在将这样的信息抽取技术广泛的应用到实际业务当中,并致力于让更多的中小开发者从中收益。他们搭建的信息抽取平台AliIE拥有最顶尖的AI技术,并从一开始的架构设计就考虑到平台的开放性和可扩展性,可以让更多的开发者、研究员共同开发,并将成果回馈给这个社区。
阿里巴巴夺中文语法大赛 CGED全球冠军

另一场比赛,中文语法错误自动诊断大赛(Chinese Grammatical Error Diagnosis,以下简称 CGED)由IJCNLP联办,今年已是第四届。比赛的背景是:学习中文的外国人数不断增加,由于中文的博大精深,外国友人在中文写作中会出现语法错误。主办方挑选了一些外国友人写的中文作文片段,希望参赛者用人工智能算法自动识别里面的语法语义错误。
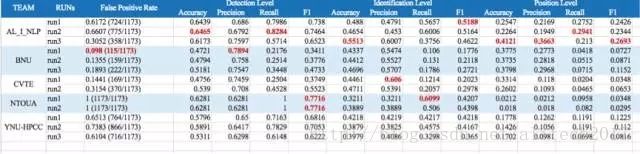
参赛机构比赛成绩公布
根据组委会公开的结果,司罗团队在所有的3个level的正确率都以较大优势位居第一,获取2017 CGED比赛的冠军。主力成员李林琳,谢朋峻,杨毅等通过在深度学习中引入无监督的语法知识,同时结合了集成学习等方法取得了好成绩。
司罗介绍,中文语法诊断的挑战性在于,中文语言知识丰富、语法多样;人在判断一句话是否有错误的时候,会用到长期积累的知识体系(比如一句话是否通顺、两个词是否可以搭配、语义上是否成立等)。相比之下,比赛提供的训练数据非常有限,仅通过训练数据来识别错误是很困难的。
赛题中包含的错误分为四种类型:多词(Redundant)、缺词(Missing)、错词(Selection)和词序错误(Word Order)。系统性能的评估也由易到难分为3个level:detection level(识别句子有没有错误)、identification level(识别错误句子的具体错误类型)和position level(识别错误的位置和对应类型)

比赛要求诊断的四种错误类型
比如,“我要送給你一个庆祝礼物。要是两、三天晚了,请别生气”这句话,在第3个Level,AI需要明确指出“两、三天晚了”存在错误才能得分(正确用法应该是“晚了两、三天”)。
根据组委会公开的结果,司罗团队在所有的3个level的正确率都以较大优势位居第一,获取2017 CGED比赛的冠军。他们通过在深度学习中引入无监督的语法知识,同时结合了集成学习等方法。
技术细节上,IDST团队在bilstm-crf模型的基础上,结合了分词、词性、依存句法等特征,同时将language model等无监督的知识embedding到神经网络。依靠RNN结构以及词性、依存等特征,不光能识别短程的语法错误,比如“一头牛”好于“一只牛”;也能识别比较长程的语法错误,比如“虽然父母很辛苦,而且对孩子照顾得很好”中“虽然”和“而且“不搭配。此外,他们针对比赛的3个不同level,设计了不同的基于神经网络的snapshot emsembles方法。
司罗表示:“很荣幸能够同全球的同行分享阿里巴巴的研究成果,人工智能在对于自然语言的理解还处在起步阶段,要实现真正的语义理解还需要 5-10 年的跨越。我们正在积极和同行业顶尖机构学习交流,推动行业发展”。
司罗认为,自然语言处理是实现强人工智能的非常重要的一环,而且重要性会越来越显现。感知层面的事情越来越成熟了,认知层面也得跟上了。虽然有很大的鸿沟摆在面前,但这是必须要跨越的。“因为 NLP 技术是达到强人工智能的路上必须攻克的关键节点”。