JAVA面试八股文整理
目录
- Java基础
-
- JAVA基础八股文
-
- Switch能支持哪些类型?
- 内部类有哪几种?有什么优点?
- 为什么匿名内部类不能访问外部类未加final的变量
- String,StringBuffer,StringBuilder
- Java中的异常处理简介
- JAVA反射获取类的三种方式
- JAVA的四种标准元注解
- collection和map的关系
- collection里面的子类
- java 容器的快速失败(fast-fail)机制
- ArrayList扩容机制
- Vector和ArrayList
- HashSet判断元素相等性的方法
- 什么时候需要复写hashcode()和compartTo方法
- TreeSet是什么
- TreeMap
- HashMap的实现
- ConcurrentHashMap
- HashTable
- 各种集合实现的扩容倍数
- 哪些Map支持key为null
- select和epoll的区别
- wait和sleep的共同点和区别
- threadLocal简介
- synchronized和volatile区别
- java8的新特性
- java9的新特性
- compareTo接口规范
- 为什么要用元空间来代替永久代
- Java I/O
-
- JAVA NIO
- Java AIO(NIO.2)
- Zero copy
- Java多线程
-
- Java线程池
-
- 为什么要用线程池
- 线程池的创建方式
- Callable、Runable、Future、FutureTash
- 线程池工作流程
- 线程的生命周期
-
- 线程的五个生命周期
- 僵死进程
- JAVA多线程并发
-
- JAVA的锁
- SynchronousQueue原理
- JVM
-
- JVM相关知识
- JVM内存模型
- JVM线程模型
- 垃圾回收
-
- GC Roots
- 四种引用类型
- 常见垃圾回收算法
- 常见的垃圾回收器
-
- 垃圾回收器的选择
- 类加载机制
-
- 加载
- 验证
- 准备
- 解析
- 初始化
- 类加载器和双亲委派模型
- java对象内存相关
-
- 内存分配机制
- 访问内存中的对象
- JVM调优
-
- GC调优
Java基础
JAVA基础八股文
Switch能支持哪些类型?
jdk5之前,switch能够作用在byte,short,char,int(实际上都是提升为int)等四个基本类型,jdk5引入了enum(也是int),jdk7引入了字符串(实际上是调用了string的hashcode,因此本质上还是int),但是不能使用long,因为switch 对应的 JVM 字节码 lookupswitch、tableswitch 指令只支持 int 类型,而long没法转换为int。
内部类有哪几种?有什么优点?
成员内部类,局部内部类,匿名内部类和静态内部类。
- 静态内部类
类内部的静态类,可以访问外部类的所有静态变量,可以通过new 外部类.静态内部类()来创建。 - 成员内部类
类内部的,成员位置上的非静态类。可以访问外部类所有变量和方法。创建方式为外部类实例.new 内部类()。 - 局部内部类。
定义在方法内的内部类,就是局部内部类。定义在实例方法中的局部类可以访问外部类所有的变量和方法,定义在静态方法中的局部类只能访问外部类的静态变量和方法。在对应方法中new 内部类()来创建。 - 匿名内部类
没有名字的内部类。其必须继承一个抽象类或者实现一个接口;不能定义任何静态成员和静态方法;匿名内部类不能访问外部类未加final修饰的变量(注意:JDK1.8即使没有用final修饰也可以访问);匿名内部类不能是抽象的。
内部类的优点:
- 内部类可以访问外部类的内容(即使是private)。
- 内部类可以模拟出一种“多重继承”。
- 匿名内部类可以方便的定义回调。
为什么匿名内部类不能访问外部类未加final的变量
匿名内部类在生成字节码阶段,会把涉及的变量作为构造函数的参数,这样使得在匿名内部类中修改的数据无法传递到外部,因此不能是final。
参考资料 https://cuipengfei.me/blog/2013/06/22/why-does-it-have-to-be-final/
String,StringBuffer,StringBuilder
- String底层是final char value[]。因此其不可变。
- StringBuffer和StringBuilder都是继承自AbstractStringBuilder,其底层使用的是char value[](无final),所以可变。StringBuffer是线程安全的(使用synchronized保证),StringBuilder不是。
- 每次对String类型进行改变时,会生成一个新的String对象,然后把指针指向新的String,但是其他两个都是操作自身。
Java中的异常处理简介

所有的异常类都有个共同祖先 Throwable。
Error一般是指程序无法处理的错误或者不应该处理的错误。
Exception是程序可以处理的异常。
Exception分为runtime exception和非运行时异常;或者分为受检异常和非受检异常。受检异常是指编译器必须处理的异常
JAVA反射获取类的三种方式
- 调用对象的.getClass()方法
- 调用某个类的.class属性
- 使用Class.forName+类的全路径
JAVA的四种标准元注解
- @Target 修饰对象范围,例如types, packages
- @Retention 定义保留的时间长短,例如SOURCE,RUNTIME
- @Document描述javadoc
- @Inherited阐述某个被标注的类型是被继承的。作用:如果一个类用上了@Inherited修饰的注解,那么其子类也会继承这个注解。但是如果接口用上个@Inherited修饰的注解,其实现类不会继承这个注解;或者父类的方法用了@Inherited修饰的注解,子类也不会继承这个注解。这样操作后,子类可以获取父类的注解,字段等信息。
该部分参考资料:https://blog.csdn.net/qq_43390895/article/details/100175330
collection和map的关系
Java容器分为collection和map两大类。
collection里面的子类
主要包括list*包括ArrayList,LinkedList,Vector)和set(主要有HashSet,LinkedSet和TreeSet)
java 容器的快速失败(fast-fail)机制
这是通过modCount实现的。遍历器在遍历访问集合中的内容时,会维护modCount和expectedModCount。当modCount不等于expoectedModCount时,就会抛出异常。迭代器在调用next()、remove()方法时都是调用checkForComodification()方法来进行检测modCount是否等于expectedModCount。具体来说:在创建迭代器的时候会把对象的modCount的值传递给迭代器的expectedModCount,如果创建多个迭代器对一个集合对象进行修改的话,那么就会有一个modCount和多个expectedModCount,且modCount的值之间也会不一样,这就导致了moCount和expectedModCount的值不一致,从而产生异常。
那么为什么在下列代码中即使单线程,也会出现快速失败呢:
for( Integer i:list){
list.remove(i);
}
因为当使用for each时,会生成一个iterator来来遍历该list,同时这个list正在被iterator.remove修改。
解决办法:
- 在遍历过程中,所有改变modCount值的地方都加上synchronized。
- 使用CopyOnWriteArrayList来替换ArrayList。CopyOnWriteArrayList是在有写操作的时候会copy一份数据,然后写完再设置成新的数据。
该部分参考资料:https://blog.csdn.net/weixin_44170221/article/details/105028266
https://www.cnblogs.com/zhangcaiwang/p/7131035.html
ArrayList扩容机制
简单来说就是当前容量*1.5+1,具体可以参考https://blog.csdn.net/qq_26542493/article/details/88873168
Vector和ArrayList
Vector与ArrayList一样,也是通过数组实现的,不同的是它支持线程的同步,即某一时刻只有一个线程能够写Vector,避免多线程同时写而引起的不一致性,但实现同步需要很高的花费,因此,访问它比访问ArrayList慢。
###LinkedList
LinkedList是用双向链表结构存储数据的,并且通过first和last引用分别指向链表的第一个和最后一个元素,很适合数据的动态插入和删除,随机访问和遍历速度比较慢。另外,他还提供了List接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。
HashSet判断元素相等性的方法
HashSet首先判断两个元素的哈希值,如果哈希值一样,接着会比较equals方法 如果 equls结果为true ,HashSet就视为同一个元素。如果equals 为false就不是同一个元素。
什么时候需要复写hashcode()和compartTo方法
HashMap中实现了一个Entry[]数组,数组的每个item是一个单项链表的结构,当我们put(key, value)的时候,HashMap首先会newItem.key.hashCode()作为该newItem在Entry[]中存储的下标,要是对应的下标的位置上没有任何item,则直接存储上去,要是已经有oldItem存储在了上面,那就会判断oldItem.key.equals(newItem.key),那么要是我们把上面的Person作为key进行存储的时候,重写了equals()方法,但没重写hashCode()方法,当我们去put()的时候,首先会通过hashCode() 计算下标,由于没有重写hashCode(),那么实质是完整的Object的hashCode(),会受到Object多个属性的影响,本来equals的两个Person对象,反而得到了两个不同的下标。
同样的,HashMap在get(key)的过程中,也是首先调用hashCode()计算item的下标,然后在对应下标的地方找,要是为null,就返回null,要是 != null,会去调用equals()方法,比较key是否一致,只有当key一致的时候,才会返回value,要是我们没有重写hashCode()方法,本来有的item,反而会找不到,返回null结果。
所以,要是你重写了equals()方法,而你的对象可能会放入到散列(HashMap,HashTable或HashSet等)中,那么还必须重写hashCode(), 如果你的对象有可能放到有序队列(实现了Comparable)中,那么还需要重写compareTo()的方法。
TreeSet是什么
- TreeSet()是使用二叉树的原理对新add()的对象按照指定的顺序排序(升序、降序),每增加一个对象都会进行排序,将对象插入的二叉树指定的位置。
- Integer和String对象都可以进行默认的TreeSet排序,而自定义类的对象是不可以的,自己定义的类必须实现Comparable接口,并且覆写相应的compareTo()函数,才可以正常使用。
- 在覆写compare()函数时,要返回相应的值才能使TreeSet按照一定的规则来排序。比较此对象与指定对象的顺序。如果该对象小于、等于或大于指定对象,则分别返回负整数、零或正整数。
TreeMap
与HashSet和HashMap关系类似,TreeSet是基于TreeMap实现的。他采用红黑树来保存map的每一个Entry。
HashMap的实现
HashMap根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。 HashMap最多只允许一条记录的键为null,允许多条记录的值为null。HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap。我们用下面这张图来介绍 HashMap 的结构。
JDK7:
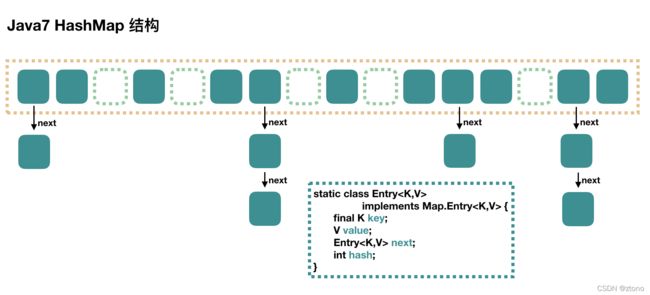
大方向上,HashMap 里面是一个数组,然后数组中每个元素是一个单向链表。上图中,每个绿色的实体是嵌套类 Entry 的实例,Entry 包含四个属性:key, value, hash 值和用于单向链表的 next。
1. capacity:当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。
2. loadFactor:负载因子,默认为 0.75(负载因子设置为0.75是为了在大量空间浪费和大量hash冲突之间取得一个平衡)。计算HashMap的实时装载因子的方法为:size/capacity
3. threshold:扩容的阈值,等于 capacity * loadFactor
4. size:size表示HashMap中存放KV的数量(为链表和树中的KV的总和)
JDK8:
Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由 数组+链表+红黑树 组成。 根据 Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为 O(n)。为了降低这部分的开销,在 Java8 中,当链表中的元素超过了 8 个以后,会将链表转换为红黑树 (将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。

HashMap是线程不安全的,其主要体现:
1.在jdk1.7中,在多线程环境下,扩容时会造成环形链或数据覆盖。
参考资料:https://blog.csdn.net/qq_21993785/article/details/80384250
2.在jdk1.8中,在多线程环境下,会发生数据覆盖的情况。
参考资料:https://blog.csdn.net/javageektech/article/details/116101276
HashMap扩容的时候为什么是2的n次幂?
数组下标的计算方法是(n - 1) & hash,取余(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是2的 n 次方;)。” 并且 采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是2的幂次方。
HashMap的put方法:
1.根据key通过哈希算法与与运算得出数组下标
2.如果数组下标元素为空,则将key和value封装为Entry对象(JDK1.7是Entry对象,JDK1.8是Node对象)并放入该位置。
3.如果数组下标位置元素不为空,则要分情况
(i)如果是在JDK1.7,则首先会判断是否需要扩容,如果要扩容就进行扩容,如果不需要扩容就生成Entry对象,并使用头插法添加到当前链表中。
(ii)如果是在JDK1.8中,则会先判断当前位置上的TreeNode类型,看是红黑树还是链表Node
(a)如果是红黑树TreeNode,则将key和value封装为一个红黑树节点并添加到红黑树中去,在这个过程中会判断红黑树中是否存在当前key,如果存在则更新value。
(b)如果此位置上的Node对象是链表节点,则将key和value封装为一个Node并通过尾插法插入到链表的最后位置去,因为是尾插法,所以需要遍历链表,在遍历过程中会判断是否存在当前key,如果存在则更新其value,当遍历完链表后,将新的Node插入到链表中,插入到链表后,会看当前链表的节点个数,如果大于8,则会将链表转为红黑树
(c)将key和value封装为Node插入到链表或红黑树后,在判断是否需要扩容,如果需要扩容,就结束put方法。
HashMap源码中在计算hash值的时候为什么要右移16位?
当数组的长度很短时,只有低位数的hashcode值能参与运算。而让高16位参与运算可以更好的均匀散列,减少碰撞,进一步降低hash冲突的几率。并且使得高16位和低16位的信息都被保留了。
而在这里采用异或运算而不采用& ,| 运算的原因是 异或运算能更好的保留各部分的特征,如果采用&运算计算出来的值的二进制会向1靠拢,采用|运算计算出来的值的二进制会向0靠拢。
计算方式:hash实际上是object.hashCode() ^ object.hashCode() >> 16。数组下标index = (table.length-1)&hash。table.length-1的目的是把结果限制在0-table.length-1里面,因为这个值通常不大,所以会丢失高位信息(因为是&操作)。
参考资料:https://www.cnblogs.com/skyvalley/p/14227702.html
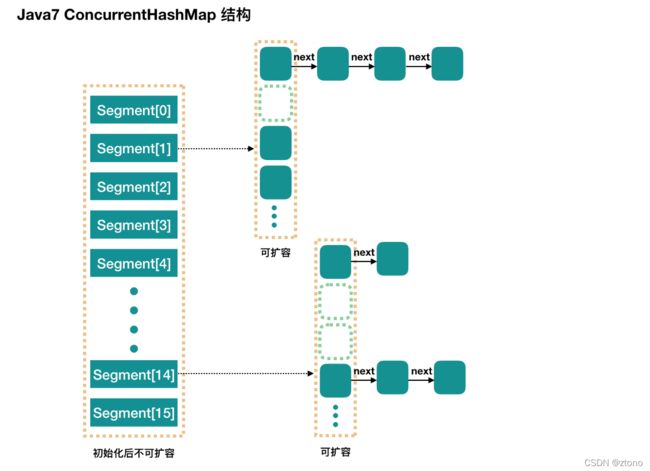
ConcurrentHashMap
Segment段:
ConcurrentHashMap 和 HashMap 思路是差不多的,但是因为它支持并发操作,所以要复杂一些。整个 ConcurrentHashMap 由一个个 Segment 组成,Segment 代表”部分“或”一段“的意思,所以很多地方都会将其描述为分段锁。注意,行文中,我很多地方用了“槽”来代表一个 segment。
线程安全(Segment 继承 ReentrantLock 加锁)
简单理解就是,ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
concurrencyLevel: 并行级别、并发数、Segment 数。默认是 16,也就是说 ConcurrentHashMap 有 16 个 Segments,所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。再具体到每个 Segment 内部,其实每个 Segment 很像之前介绍的 HashMap,不过它要保证线程安全,所以处理起来要麻烦些。
和HashMap一样,ConcurrentHashMap的JDK7和JDK8实现也有区别。如下图所示:
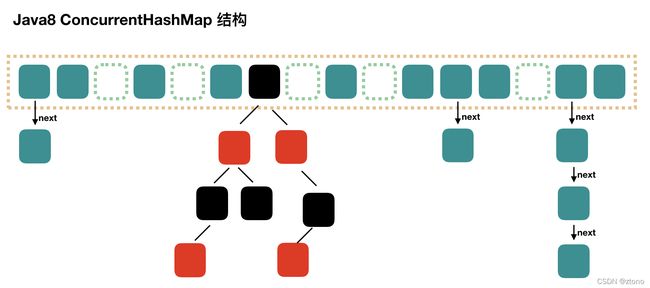
可以看到Java8中的ConcurrentHashMap和Java8的HashMap很像,那么他是怎么保证线程安全的呢。java8实现了粒度更细的加锁,去掉了segment数组,直接使用synchronized锁住hash后得到的数组下标位置中的第一个元素 ,如下图,这样加锁比segment加锁能支持更高的并发量。
HashTable
Hashtable是遗留类,很多映射的常用功能与HashMap类似,不同的是它承自Dictionary类,并且是线程安全的,任一时间只有一个线程能写Hashtable,并发性不如ConcurrentHashMap,因为ConcurrentHashMap引入了分段锁。Hashtable不建议在新代码中使用,不需要线程安全的场合可以用HashMap替换,需要线程安全的场合可以用ConcurrentHashMap替换。
各种集合实现的扩容倍数
| 名称 | 倍数 | 备注 |
|---|---|---|
| HashMap | 2倍 | jdk1.7中,扩容后重新计算hash,1.8中,根据,是否仍然在同一个桶中判断,即e.hash()& oldCap,oldCap为旧容量,当你给定了初始容量值时,会将其扩充到2的幂,参考资料https://blog.csdn.net/lkforce/article/details/89521318 |
| HashTable | 2倍+1 | 无 |
哪些Map支持key为null
HashMap 、LinkedHashMap 的 key 和 value 都允许为 null。
而ConcurrentHashMap、ConcurrentSkipListMap、Hashtable、TreeMap 的 key 不允许为 null。
参考资料:https://blog.csdn.net/vsmybits/article/details/120496341
select和epoll的区别
当需要读两个以上的I/O的时候,如果使用阻塞式的I/O,那么可能长时间的阻塞在一个描述符上面,另
外的描述符虽然有数据但是不能读出来,这样实时性不能满足要求,大概的解决方案有以下几种:
- 使用多进程或者多线程,但是这种方法会造成程序的复杂,而且对与进程与线程的创建维护也需要
很多的开销(Apache服务器是用的子进程的方式,优点可以隔离用户); - 用一个进程,但是使用非阻塞的I/O读取数据,当一个I/O不可读的时候立刻返回,检查下一个是否
可读,这种形式的循环为轮询(polling),这种方法比较浪费CPU时间,因为大多数时间是不可
读,但是仍花费时间不断反复执行read系统调用; - 异步I/O,当一个描述符准备好的时候用一个信号告诉进程,但是由于信号个数有限,多个描述符
时不适用; - 一种较好的方式为I/O多路复用,先构造一张有关描述符的列表(epoll中为队列),然后调用一个
函数,直到这些描述符中的一个准备好时才返回,返回时告诉进程哪些I/O就绪。select和epoll这
两个机制都是多路I/O机制的解决方案,select为POSIX标准中的,而epoll为Linux所特有的。
它们的区别主要有三点:
- select的句柄数目受限,在linux/posix_types.h头文件有这样的声明: #define __FD_SETSIZE
1024 表示select最多同时监听1024个fd。而epoll没有,它的限制是最大的打开文件句柄数目; - epoll的最大好处是不会随着FD的数目增长而降低效率,在selec中采用轮询处理,其中的数据结构
类似一个数组的数据结构,而epoll是维护一个队列,直接看队列是不是空就可以了。epoll只会对”
活跃”的socket进行操作—这是因为在内核实现中epoll是根据每个fd上面的callback函数实现的。那
么,只有”活跃”的socket才会主动的去调用 callback函数(把这个句柄加入队列),其他idle状态
句柄则不会,在这点上,epoll实现了一个”伪”AIO。但是如果绝大部分的I/O都是“活跃的”,每个I/O
端口使用率很高的话,epoll效率不一定比select高(可能是要维护队列复杂); - 使用mmap加速内核与用户空间的消息传递。无论是select,poll还是epoll都需要内核把FD消息通知
给用户空间,如何避免不必要的内存拷贝就很重要,在这点上,epoll是通过内核于用户空间
mmap同一块内存实现的。
wait和sleep的共同点和区别
共同点 :
- 他们都是在多线程的环境下,都可以在程序的调用处阻塞指定的毫秒数,并返回。
- wait()和sleep()都可以通过interrupt()方法 打断线程的暂停状态 ,从而使线程立刻抛出InterruptedException。
如果线程A希望立即结束线程B,则可以对线程B对应的Thread实例调用interrupt方法。如果此刻线程B正在wait/sleep/join,则线程B会立刻抛出InterruptedException,在catch() {} 中直接return即可安全地结束线程。
需要注意的是,InterruptedException是线程自己从内部抛出的,并不是interrupt()方法抛出的。对某一线程调用 interrupt()时,如果该线程正在执行普通的代码,那么该线程根本就不会抛出InterruptedException。但是,一旦该线程进入到 wait()/sleep()/join()后,就会立刻抛出InterruptedException 。
不同点 :
1.每个对象都有一个锁来控制同步访问。Synchronized关键字可以和对象的锁交互,来实现线程的同步。
sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法。
2.wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用
3.sleep必须捕获异常,而wait,notify和notifyAll不需要捕获异常
4.sleep是线程类(Thread)的方法,导致此线程暂停执行指定时间,给执行机会给其他线程,但是监控状态依然保持,到时后会自动恢复。调用sleep不会释放对象锁。
5.wait是Object类的方法,对此对象调用wait方法导致本线程放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象发出notify方法(或notifyAll)后本线程才进入对象锁定池准备获得对象锁进入就绪状态。
threadLocal简介
ThreadLocal为变量在每个线程都创建了一个副本。每个线程可以访问自己内部的副本变量。首先,在每个线程Thread内部有一个ThreadLocal.ThreadLocalMap类型的成员变量threadLocals,这个threadLocals就是用来存储实际的变量副本的,键值为当前ThreadLocal变量,value为变量副本(即T类型的变量)。
初始时,在Thread里面,threadLocals为空,当通过ThreadLocal变量调用get()方法或者set()方法,就会对Thread类中的threadLocals进行初始化,并且以当前ThreadLocal变量为键值,以ThreadLocal要保存的副本变量为value,存到threadLocals。
然后在当前线程里面,如果要使用副本变量,就可以通过get方法在threadLocals里面查找。
threadLocaMap为什么是弱引用呢?
每个Thread内部都维护一个ThreadLocalMap字典数据结构,字典的Key值是ThreadLocal,那么当某个ThreadLocal对象不再使用(没有其它地方再引用)时,每个已经关联了此ThreadLocal的线程怎么在其内部的ThreadLocalMap里做清除此资源呢?JDK中的ThreadLocalMap又做了一次精彩的表演,它没有继承java.util.Map类,而是自己实现了一套专门用来定时清理无效资源的字典结构。其内部存储实体结构Entry
ThreadLocal是如何做到为每一个线程维护变量的副本的呢?
其实实现的思路很简单:在ThreadLocal类中有一个static声明的Map,用于存储每一个线程的变量副本,Map中元素的键为线程对象,而值对应线程的变量副本。
synchronized和volatile区别
- volatile主要应用在多个线程对实例变量更改的场合,刷新主内存共享变量的值从而使得各个线程可以获得最新的值,线程读取变量的值需要从主存中读取;synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。另外,synchronized还会创建一个内存屏障,内存屏障指令保证了所有CPU操作结果都会直接刷到主存中(即释放锁前),从而保证了操作的内存可见性,同时也使得先获得这个锁的线程的所有操作
- volatile仅能使用在变量级别;synchronized则可以使用在变量、方法、和类级别的。 volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞,比如多个线程争抢 synchronized锁对象时,会出现阻塞。
- volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量的修改可见性和原子性,因为线程获得锁才能进入临界区,从而保证临界区中的所有语句全部得到 执行。
- volatile标记的变量不会被编译器优化,可以禁止进行指令重排;synchronized标记的变量可以被编译器优化。
java8的新特性
- 接口的默认实现
- lambda表达式
注意lambda表达式不能访问接口的默认方法。 - 函数式接口
常见的函数式接口有Predicate,Function,Optional,Stream,Filter,Sort,Map,Match,Count,Reduce等 - 方法与构造函数引用
- Date的API
- annotation
java9的新特性
- 模块系统
- java.net.http,提供了良好的http1和http2的支持
- jshell
- 不可变集合工厂方法
- 私有接口方法
- I/O流新特性(增加了新的方法来读取和复制InputStream的内容)
- 多版本兼容jar
- 统一JVM日志
- 默认垃圾处理器从Parallel GC切换到了G1
compareTo接口规范
小于返回<0,等于返回0,大于返回大于0
为什么要用元空间来代替永久代
1、字符串存在永久代中,容易出现性能问题和内存溢出。
2、类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出。
3、永久代会为 GC 带来不必要的复杂度,并且回收效率偏低。
Java I/O
- 堵塞IO模型。
最传统的一种 IO 模型,即在读写数据过程中会发生阻塞现象。当用户线程发出 IO 请求之后,内核会去查看数据是否就绪,如果没有就绪就会等待数据就绪,而用户线程就会处于阻塞状态,用户线程交出 CPU。当数据就绪之后,内核会将数据拷贝到用户线程,并返回结果给用户线程,用户线程才解除block 状态。典型的阻塞 IO 模型的例子为:data = socket.read();如果数据没有就绪,就会一直阻塞在 read 方法。 - 非堵塞IO模型。
当用户线程发起一个 read 操作后,并不需要等待,而是马上就得到了一个结果。如果结果是一个error 时,它就知道数据还没有准备好,于是它可以再次发送 read 操作。一旦内核中的数据准备好了,并且又再次收到了用户线程的请求,那么它马上就将数据拷贝到了用户线程,然后返回。所以事实上,在非阻塞 IO 模型中,用户线程需要不断地询问内核数据是否就绪,也就说非阻塞 IO不会交出 CPU,而会一直占用 CPU。但是对于非阻塞 IO 就有一个非常严重的问题,在 while 循环中需要不断地去询问内核数据是否就绪,这样会导致 CPU 占用率非常高,因此一般情况下很少使用 while 循环这种方式来读取数据。 - 多路复用 IO 模型
多路复用 IO 模型是目前使用得比较多的模型。Java NIO 实际上就是多路复用 IO。在多路复用 IO模型中,会有一个线程不断去轮询多个 socket 的状态,只有当 socket 真正有读写事件时,才真正调用实际的 IO 读写操作。因为在多路复用 IO 模型中,只需要使用一个线程就可以管理多个socket,系统不需要建立新的进程或者线程,也不必维护这些线程和进程,并且只有在真正有socket 读写事件进行时,才会使用 IO 资源,所以它大大减少了资源占用。在 Java NIO 中,是通过 selector.select()去查询每个通道是否有到达事件,如果没有事件,则一直阻塞在那里,因此这种方式会导致用户线程的阻塞。多路复用 IO 模式,通过一个线程就可以管理多个 socket,只有当socket 真正有读写事件发生才会占用资源来进行实际的读写操作。因此,多路复用 IO 比较适合连接数比较多的情况。
另外多路复用 IO 为何比非阻塞 IO 模型的效率高?因为在非阻塞 IO 中,不断地询问 socket 状态
时通过用户线程去进行的,而在多路复用 IO 中,轮询每个 socket 状态是内核在进行的,这个效
率要比用户线程要高的多。
不过要注意的是,多路复用 IO 模型是通过轮询的方式来检测是否有事件到达,并且对到达的事件
逐一进行响应。因此对于多路复用 IO 模型来说,一旦事件响应体很大,那么就会导致后续的事件
迟迟得不到处理,并且会影响新的事件轮询。
一般的,IO多路复用机制都依赖于一个事件多路分离器(Event Demultiplexer)。分离器对象可将来自事件源的IO事件分离出来,并分发到对应的read/write事件处理器。
Reactor模型和Proactor模型
Reactor模型和Proactor模型都是用来处理IO复用的模型。Reactor采用同步IO,Proactor采用异步IO。
在Reactor模式中,事件分离器负责风带文件描述符或者socket为读写操作准备就绪,并将就绪事件传递给对应的处理器,最后由处理器负责完成实际的读写工作。
在Proactor模式中,处理器或者兼任处理器的事件分离器,只负责发起异步读写操作。IO是由系统完成的。
以读操作为例,介绍两者差异:
在reactor中实现读:
step1: 注册读就绪事件和相应的事件处理器。
step2:事件分离器等待事件。
step3:事件到来,激活分离器,分离器调用时间对应的处理器。
step4:处理器完成读操作,注册新的事件,返还控制权。
在Proactor中实现读:
step1:处理器发出异步读请求,这时候处理器无视IO就绪事件,关注的是完成事件。
step2:事件分离器等待操作完成事件。
step3:在分离器等待过程中,操作系统完成读操作,并将结果存入用户自定义缓冲区,通知时间分离器读操作完成。
step4:事件分离器呼唤处理器。
step5:事件处理器处理用户自定义缓冲区中的数据,然后启动一个新的异步操作,并将控制权返回事件分类器。 - 信号驱动IO模型
在信号驱动 IO 模型中,当用户线程发起一个 IO 请求操作,会给对应的 socket 注册一个信号函数,然后用户线程会继续执行,当内核数据就绪时会发送一个信号给用户线程,用户线程接收到信号之后,便在信号函数中调用 IO 读写操作来进行实际的 IO 请求操作。 - 异步 IO 模型
异步 IO 模型才是最理想的 IO 模型,在异步 IO 模型中,当用户线程发起 read 操作之后,立刻就可以开始去做其它的事。而另一方面,从内核的角度,当它受到一个 asynchronous read 之后,它会立刻返回,说明 read 请求已经成功发起了,因此不会对用户线程产生任何 block。然后,内核会等待数据准备完成,然后将数据拷贝到用户线程,当这一切都完成之后,内核会给用户线程发送一个信号,告诉它 read 操作完成了。也就说用户线程完全不需要实际的整个 IO 操作是如何进行的,只需要先发起一个请求,当接收内核返回的成功信号时表示 IO 操作已经完成,可以直接去使用数据了。
也就说在异步 IO 模型中,IO 操作的两个阶段都不会阻塞用户线程,这两个阶段都是由内核自动完成,然后发送一个信号告知用户线程操作已完成。用户线程中不需要再次调用 IO 函数进行具体的读写。这点是和信号驱动模型有所不同的,在信号驱动模型中,当用户线程接收到信号表示数据已经就绪,然后需要用户线程调用 IO 函数进行实际的读写操作;而在异步 IO 模型中,收到信号表示 IO 操作已经完成,不需要再在用户线程中调用 IO 函数进行实际的读写操作。
JAVA NIO
NIO基于Reactor。
NIO主要有三大核心部分:Channel(通道),Buffer(缓冲区), Selector。传统IO基于字节流和字符流进行操作,而NIO基于Channel和Buffer(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。Selector(选择区)用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个线程可以监听多个数据通道。如下图所示:
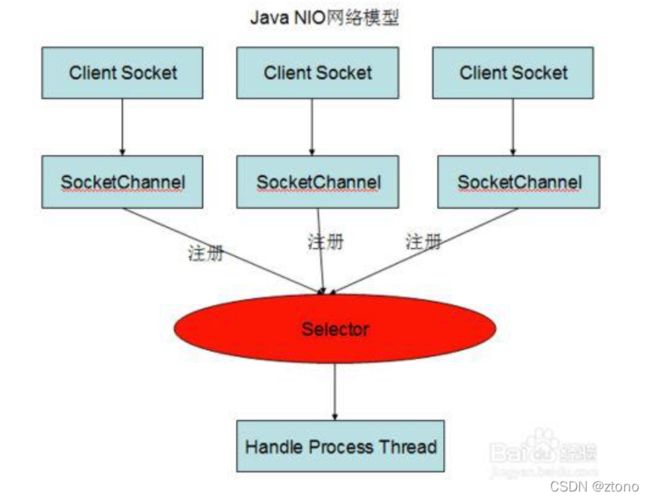
NIO和传统IO之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的。
Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。NIO的缓冲导向方法不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。 NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
下面说明下一些名词的含义:
- Channel。Channel和IO中的Stream(流)是差不多一个等级的。只不过Stream是单向的,譬如:InputStream, OutputStream,而Channel是双向的,既可以用来进行读操作,又可以用来进行写操作。
- Buffer,故名思意,缓冲区,实际上是一个容器,是一个连续数组。Channel提供从文件、网络读取数据的渠道,但是读取或写入的数据都必须经由Buffer。
客户端发送数据时,必须先将数据存入Buffer中,然后将Buffer中的内容写入通道。服务端这边接收数据必须通过Channel将数据读入到Buffer中,然后再从Buffer中取出数据来处理。
下图描述了一个从一个客户端向服务端发送数据,然后服务端接收数据的过程。

- Selector。Selector类是NIO的核心类,Selector能够检测多个注册的通道上是否有事件发生,如果有事件发生,便获取事件然后针对每个事件进行相应的响应处理。这样一来,只是用一个单线程就可以管理多个通道,也就是管理多个连接。这样使得只有在连接真正有读写事件发生时,才会调用函数来进行读写,就大大地减少了系统开销,并且不必为每个连接都创建一个线程,不用去维护多个线程,并且避免了多线程之间的上下文切换导致的开销。
Java AIO(NIO.2)
与NIO不同,当进行读写操作时,只需要调用API的Read和Write方法即可这两个都是异步的,完成后会调用回调函数。
主要在java.nio.channels包下增加了下面四个异步通道:
AsynchronousSocketChannel
AsynchronousServerSocketChannel
AsynchronousFileChannel
AsynchronousDatagramChannel
其中,对于AsynchronousSocketChannel而言,linux和windows实现方式并不一致,windows上通过IOCP实现,即WindowsAsynchronousSocketChannelImpl,实现接口为Iocp.OverlappedChannel;而在Linux上是UnixAsynchronousSocketChannelImpl,实现接口为Port.PollableChannel。
AIO不需要对selector进行轮询。
Zero copy
例如从文件中读取数据并将其通过网络传输给其他应用程序的的操作需要经历四次内核态和用户态的切换。
步骤如下:
- read()的调用引起了从用户态到内核态的切换(看图二),内部是通过sys_read()(或者类似的方
法)发起对文件数据的读取。数据的第一次复制是通过DMA(直接内存访问)将磁盘上的数据复制
到内核空间的缓冲区中; - 数据从内核空间的缓冲区复制到用户空间的缓冲区后,read()方法也就返回了。此时内核态又切换
回用户态,现在数据也已经复制到了用户地址空间的缓存中; - socket的send()方法的调用又会引起用户态到内核的切换,第三次数据复制又将数据从用户空间缓
冲区复制到了内核空间的缓冲区,这次数据被放在了不同于之前的内核缓冲区中,这个缓冲区与数
据将要被传输到的socket关联; - send()系统调用返回后,就产生了第四次用户态和内核态的切换。随着DMA单独异步的将数据从内
核态的缓冲区中传输到协议引擎发送到网络上,有了第四次数据复制。
Java中的java.nio.channels.FilleChannel中定义了两个方法:transferTo和transferFrom,该方法允许将一个通道交叉连接到另一个通道,而不需要通过一个中转缓冲区来传递数据。
使用transferTo()方式所经历的步骤: - transferTo调用会引起DMA将文件内容复制到读缓冲区(内核空间的缓冲区),然后数据从这个缓冲
区复制到另一个与socket输出相关的内核缓冲区中; - 第三次数据复制就是DMA把socket关联的缓冲区中的数据复制到协议引擎上发送到网络上。
这次改善,是通过将内核、用户态切换的次数从四次减少到两次,将数据的复制次数从四次减少到
三次(只有一次用到cpu资源)。但这并没有达到我们零复制的目标。如果底层网络适配器支持收集操作的
话,我们可以进一步减少内核对数据的复制次数。在内核为2.4或者以上版本的linux系统上,socket缓
冲区描述符将被用来满足这个需求。这个方式不仅减少了内核用户态间的切换,而且也省去了那次需要
cpu参与的复制过程。从用户角度来看依旧是调用transferTo()方法,但是其本质发生了变化: - 调用transferTo方法后数据被DMA从文件复制到了内核的一个缓冲区中;
- 数据不再被复制到socket关联的缓冲区中了,仅仅是将一个描述符(包含了数据的位置和长度等信
息)追加到socket关联的缓冲区中。DMA直接将内核中的缓冲区中的数据传输给协议引擎,消除了
仅剩的一次需要cpu周期的数据复制。
Java多线程
Java线程池
为什么要用线程池
- 降低资源消耗。通过重复利用已创建的线程降低线程创建、销毁线程造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配、调优和监控。
- 提供更多更强大的功能:线程池具备可拓展性,允许开发人员向其中增加更多的功能。比如延时定时线程池ScheduledThreadPoolExecutor,就允许任务延期执行或定期执行。
线程池的创建方式
线程池的创建方法总共有 7 种,但总体来说可分为 2 类:
一类是通过 ThreadPoolExecutor 创建的线程池;另一个类是通过 Executors 创建的线程池。
线程池的创建方式总共包含以下 7 种(其中 6 种是通过 Executors 创建的,1 种是通过ThreadPoolExecutor 创建的):
Executors.newFixedThreadPool:创建一个固定大小的线程池,可控制并发的线程数,超出的线程会在队列中等待;
Executors.newCachedThreadPool:创建一个可缓存的线程池,若线程数超过处理所需,缓存一段时间后会回收,若线程数不够,则新建线程;
Executors.newSingleThreadExecutor:创建单个线程数的线程池,它可以保证先进先出的执行顺序;
Executors.newScheduledThreadPool:创建一个可以执行延迟任务的线程池;
Executors.newSingleThreadScheduledExecutor:创建一个单线程的可以执行延迟任务的线程池;
Executors.newWorkStealingPool:创建一个抢占式执行的线程池(任务执行顺序不确定)【JDK 1.8 添加】。
ThreadPoolExecutor:最原始的创建线程池的方式,它包含了 7 个参数可供设置。
| 参数 | 说明 |
|---|---|
| corePoolSize | 核心线程数量,线程池维护线程的最少数量 |
| maximumPoolSize | 线程池维护线程的最大数量 |
| keepAliveTime | 线程池除核心线程外的其他线程的最长空闲时间,超过该时间的空闲线程会被销毁 |
| unit | keepAliveTime的单位,TimeUnit中的几个静态属性:NANOSECONDS(纳秒)、MICROSECONDS(微秒)、MILLISECONDS(毫秒)、SECONDS(秒)、MINUTES、HOURS、DAYS |
| workQueue | 线程池所使用的任务缓冲队列,有如下几种: 1. ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列。2.- LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列。3. SynchronousQueue:一个不存储元素的阻塞队列,即直接提交给线程不保持它们。 4. PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。5 . DelayQueue:一个使用优先级队列实现的无界阻塞队列,只有在延迟期满时才能从中提取元素。6. LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。与SynchronousQueue类似,还含有非阻塞方法。7. LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。 |
| threadFactory | 线程工厂,用于创建线程,一般用默认的即可 |
| handler | 线程池对拒绝任务的处理策略,包括如下几种:1. AbortPolicy:拒绝并抛出异常。2.CallerRunsPolicy:使用当前调用的线程来执行此任务。3. DiscardOldestPolicy:抛弃队列头部(最旧)的一个任务,并执行当前任务。4. DiscardPolicy:忽略并抛弃当前任务。 |
一般来说,推荐使用ThreadPoolExecutor创建线程池(因为Executor创建的很多线程池,Executors 返回的线程池对象的弊端如下:
1) FixedThreadPool 和 SingleThreadPool:允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。
2)CachedThreadPool:允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
Callable、Runable、Future、FutureTash
四者之间的关系:
Callable是Runnable封装的异步运算任务。
Future用来保存Callable异步运算的结果
FutureTask封装Future的实体类
- Callable与Runnbale的区别
a、Callable定义的方法是call,而Runnable定义的方法是run。
b、call方法有返回值,而run方法是没有返回值的。
c、call方法可以抛出异常,而run方法不能抛出异常。 - Future
Future表示异步计算的结果,主要是判断任务是否完成、中断任务、获取任务执行结果。 - FutureTask
可取消的异步计算,此类提供了对Future的基本实现,仅在计算完成时才能获取结果,如果计算尚未完
成,则阻塞get方法。
FutureTask不仅实现了Future接口,还实现了Runnable接口,所以不仅可以将FutureTask当成一个任务交给Executor来执行,还可以通过Thread来创建一个线程。
线程池工作流程
简单来说,提交一个任务到线程池中,线程池的处理流程如下:
1、判断线程池里的核心线程是否都在执行任务,如果不是(核心线程空闲或者还有核心线程没有被创建)则创建一个新的工作线程来执行任务。如果核心线程都在执行任务,则进入下个流程。
2、线程池判断工作队列是否已满,如果工作队列没有满,则将新提交的任务存储在这个工作队列里。如果工作队列满了,则进入下个流程。
3、判断线程池里的线程是否都处于工作状态,如果没有,则创建一个新的工作线程来执行任务。如果已经满了,则交给饱和策略来处理这个任务。
线程的生命周期
线程的五个生命周期
新建(New)、就绪(Runnable)、运行(Running)、阻塞(Blocked)和死亡(Dead)五种。
- 线程的实现有两种方式,一是继承Thread类,二是实现Runnable接口,但无论如何,当我们new了这个对象后。线程就进入了初始状态;
- 当该对象调用了start()方法,就进入可执行状态;
- 进入可执行状态后,当该对象被操作系统选中。获得CPU时间片就会进入执行状态;
- 进入执行状态后情况就比較复杂了
4.1. run()方法或main()方法结束后,线程就进入终止状态;
4.2. 当线程调用了自身的sleep()方法或其它线程的join()方法,就会进入堵塞状态(该状态既停止当前线程,但并不释放所占有的资源)。当sleep()结束或join()结束后。该线程进入可执行状态,继续等待OS分配时间片;
4.3. 线程调用了yield()方法,意思是放弃当前获得的CPU时间片,回到可执行状态,这时与其它进程处于同等竞争状态,OS有可能会接着又让这个进程进入执行状态。
4.4. 当线程刚进入可执行状态(注意,还没执行),发现将要调用的资源被synchroniza(同步),获取不到锁标记。将会马上进入锁池状态,等待获取锁标记(这时的锁池里或许已经有了其它线程在等待获取锁标记,这时它们处于队列状态,既先到先得),一旦线程获得锁标记后,就转入可执行状态。等待OS分配CPU时间片。
4.5. 当线程调用wait()方法后会进入等待队列(进入这个状态会释放所占有的全部资源,与堵塞状态不同)。进入这个状态后。是不能自己主动唤醒的,必须依靠其它线程调用notify()或notifyAll()方法才干被唤醒(因为notify()仅仅是唤醒一个线程,但我们由不能确定详细唤醒的是哪一个线程。或许我们须要唤醒的线程不可以被唤醒,因此在实际使用时,一般都用notifyAll()方法,唤醒有所线程),线程被唤醒后会进入锁池。等待获取锁标记。
僵死进程
什么是僵死进程:
僵死进程就是指子进程退出时,父进程并未对其发出的SIGCHLD信号进行适当处理,导致子进程停留在僵死状态等待其父进程,这个状态下的子进程就是僵死进程。这个僵死进程不占有内存,也不会执行代码,更不能被调用,他只是在进程列表中占了个地位而已。
如何结束僵死进程:
- 他只需要父进程调用wait()函数来替他收尸然后就完整的结束这一生。否则会一直保存这个僵死的状态。
- 把他父进程给kill了,这样他就变成了一个孤儿进程,父亲没了没人替他收拾,这时候僵死进程就会被过继给一个名叫init()进程,这个进程会给他收尸。
JAVA多线程并发
JAVA的锁
- 互斥同步锁
1)Synchorized
2)ReentrantLock
互斥同步锁也叫做阻塞同步锁,特征是会对没有获取锁的线程进行阻塞。
要理解互斥同步锁,首选要明白什么是互斥什么是同步。简单的说互斥就是非你即我,同步就是顺序访问。互斥同步锁就是以互斥的手段达到顺序访问的目的。操作系统提供了很多互斥机制比如信号量,互斥量,临界区资源等来控制在某一个时刻只能有一个或者一组线程访问同一个资源。
Java里面的互斥同步锁就是Synchorized和ReentrantLock,前者是由语言级别实现的互斥同步锁,理解和写法简单但是机制笨拙,在JDK6之后性能优化大幅提升,即使在竞争激烈的情况下也能保持一个和ReentrantLock相差不多的性能,所以JDK6之后的程序选择不应该再因为性能问题而放弃synchorized。
ReentrantLock是API层面的互斥同步锁,需要程序自己打开并在finally中关闭锁,和synchorized相比更加的灵活,体现在三个方面:等待可中断,公平锁以及绑定多个条件。但是如果程序猿对
ReentrantLock理解不够深刻,或者忘记释放lock,那么不仅不会提升性能反而会带来额外的问题。另外synchorized是JVM实现的,可以通过监控工具来监控锁的状态,遇到异常JVM会自动释放掉锁。而ReentrantLock必须由程序主动的释放锁。
互斥同步锁都是可重入锁,好处是可以保证不会死锁。但是因为涉及到核心态和用户态的切换,因此比较消耗性能。JVM开发团队在JDK5-JDK6升级过程中采用了很多锁优化机制来优化同步无竞争情况下锁的性能。比如:自旋锁和适应性自旋锁,轻量级锁,偏向锁,锁粗化和锁消除。 - 非堵塞同步
- 原子类(CAS)
非阻塞同步锁也叫乐观锁,相比悲观锁来说,它会先进行资源在工作内存中的更新,然后根据与主存中旧值的对比来确定在此期间是否有其他线程对共享资源进行了更新,如果旧值与期望值相同,就认为没有更新,可以把新值写回内存,否则就一直重试直到成功。它的实现方式依赖于处理器的机器指令:
CAS(Compare And Swap)
JUC中提供了几个Automic类以及每个类上的原子操作就是乐观锁机制
不激烈情况下,性能比synchronized略逊,而激烈的时候,也能维持常态。激烈的时候,Atomic的性能会优于ReentrantLock一倍左右。但是其有一个缺点,就是只能同步一个值,一段代码中只能出现一个 Atomic的变量,多于一个同步无效。因为他不能在多个Atomic之间同步。
非阻塞锁是不可重入的,否则会造成死锁。
- 无同步方案
1)可重入代码
在执行的任何时刻都可以中断-重入执行而不会产生冲突。特点就是不会依赖堆上的共享资源
2)ThreadLocal/Volaitile
线程本地的变量,每个线程获取一份共享变量的拷贝,单独进行处理。
- 线程本地存储
如果一个共享资源一定要被多线程共享,可以尽量让一个线程完成所有的处理操作,比如生产者消费者模式中,一般会让一个消费者完成对队列上资源的消费。典型的应用是基于请求-应答模式的web服务器的设计
SynchronousQueue原理
SynchronousQueue 是一个队列,但它的特别之处在于它内部没有容器。其中的一个生产线程,当它生产产品(即put的时候),如果当前没有人想要消费产品(即当前没有线程执行take),此生产线程必须阻塞,等待一个消费线程调用take操作,take操作将会唤醒该生产线程,同时消费线程会获取生产线程的产品(即数据传递),这样的一个过程称为一次配对过程(当然也可以先take后put,原理是一样的)。SynchronousQueue的实现并不依赖AQS(AbstractQueuedSynchronizer)而是使用CAS。
SynchronousQueue的内部实现了两个类,一个是TransferStack类,使用LIFO顺序存储元素,这个类用于非公平模式;还有一个类是TransferQueue,使用FIFI顺序存储元素,这个类用于公平模式。这两个类继承自"Nonblocking Concurrent Objects with Condition Synchronization"算法,此算法是由W. N. Scherer III 和 M. L. Scott提出的,关于此算法的理论内容在这个网站中:http://www.cs.rochester.edu/u/scott/synchronization/pseudocode/duals.html。两个类的性能差不多,FIFO通常用于在竞争下支持更高的吞吐量,而LIFO在一般的应用中保证更高的线程局部性。
参考资料:
https://blog.csdn.net/yanyan19880509/article/details/52562039
https://www.jianshu.com/p/d5e2e3513ba3
https://www.jianshu.com/p/95cb570c8187
JVM
JVM相关知识

JVM内存模型
JVM包括五块数据区域:
| 参数 | 说明 |
|---|---|
| 方法区 | 方法区是各个线程共享的内存区域,用于存储被虚拟机加载的类型信息,常量,静态变量,即时编译器编译后的代码缓存等数据,其中包括运行时常量池(用于存放编译器生成的各种字面量和符号引用 ) |
| 虚拟机栈 | 线程私有,描述的是Java方法执行的线程内存模型,每个方法被执行的时候,Java虚拟机都会同步创建一个栈帧用于存储局部变量,操作数栈,动态连接,方法出口等信息。每一个方法被调用直到执行完毕的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程,其中含有局部变量表,存放Java基本数据类型,对象引用和returnAddress(指向了一条字节码指令的地址) |
| 本地方法栈 | 结构与虚拟机栈相似,但是是服务于本地方法的 |
| 程序计数器 | 线程私有,可以看成当前线程所执行的字节码的行号指示器。 |
| JAVA堆 | 线程共享,此内存区域用于存放对象实例 |
| 直接内存 | 直接内存并不是 JVM 运行时数据区的一部分, 但也会被频繁的使用: 在 JDK 1.4 引入的 NIO 提供了基于 Channel 与 Buffer 的 IO 方式, 它可以使用 Native 函数库直接分配堆外内存, 然后使用DirectByteBuffer 对象作为这块内存的引用进行操作(详见: Java I/O 扩展), 这样就避免了在 Java堆和 Native 堆中来回复制数据, 因此在一些场景中可以显著提高性能。 |
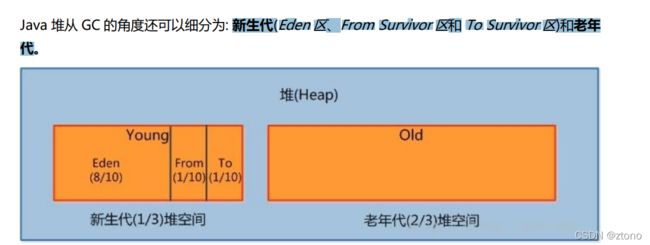
其中,JVM堆从GC角度看看能被分为新生代(Eden 区、From Survivor 区和 To Survivor 区)和老年代。如下图所示:
名词解释:
- 新生代。是用来存放新生的对象。一般占据堆的 1/3 空间。由于频繁创建对象,所以新生代会频繁触发MinorGC 进行垃圾回收。新生代又分为 Eden 区、ServivorFrom、ServivorTo 三个区。
- Eden区。Java 新对象的出生地(如果新创建的对象占用内存很大,则直接分配到老年代)。当 Eden 区内存不够的时候就会触发 MinorGC,对新生代区进行一次垃圾回收。
- ServivorFrom。 上一次 GC 的幸存者,作为这一次 GC 的被扫描者。
- ServivorTo。保留了一次 MinorGC 过程中的幸存者。
- 老年代。主要存放应用程序中生命周期长的内存对象。老年代的对象比较稳定,所以 MajorGC 不会频繁执行。在进行 MajorGC 前一般都先进行了一次 MinorGC,使得有新生代的对象晋身入老年代,导致空间不够用时才触发。当无法找到足够大的连续空间分配给新创建的较大对象时也会提前触发一次 MajorGC 进行垃圾回收腾出空间。 MajorGC 采用标记清除算法:首先扫描一次所有老年代,标记出存活的对象,然后回收没有标记的对象。MajorGC 的耗时比较长,因为要扫描再回收。MajorGC 会产生内存碎片,为了减少内存损耗,我们一般需要进行合并或者标记出来方便下次直接分配。当老年代也满了装不下的时候,就会抛出 OOM(Out of Memory)异常。
- 永久代。指内存的永久保存区域,主要存放 Class 和 Meta(元数据)的信息,Class 在被加载的时候被放入永久区域,它和存放实例的区域不同,GC 不会在主程序运行期对永久区域进行清理。所以这也导致了永久代的区域会随着加载的 Class 的增多而胀满,最终抛出 OOM 异常。在 Java8 中,永久代已经被移除,被一个称为“元数据区”(元空间)的区域所取代。元空间的本质和永久代类似,元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制。类的元数据放入 native memory, 字符串池和类的静态变量放入 java 堆中(从1.7开始),这样可以加载多少类的元数据就不再由MaxPermSize 控制, 而由系统的实际可用空间来控制。除了OOM的原因,元空间取代永久代的原因是为了合并Hotspot和JRockit的代码(http://openjdk.java.net/jeps/122Motivation)。
元数据的定义:
- It’s the model of the loaded class base that Java retains at runtime in order to dynamically load, link, JIT compile, and execute Java code.
- Different design choices you make when writing your code can significantly expand or contract the amount of metadata Java needs to retain.
- The JVM can give you a breakdown of metadata storage costs for individual structures that model each loaded class, allowing you to weigh and compare the costs of alternative designs.
这部分参考资料:https://developers.redhat.com/blog/2018/02/14/java-class-metadata
GC过程:
新生代GC采用复制算法。称为Minor GC。
- 首先,把 Eden 和 ServivorFrom 区域中存活的对象复制到 ServicorTo 区域(如果对象的年龄已经达到了老年的标准,则赋值到老年代区),同时把这些对象的年龄+1(如果 ServicorTo 不够位置了就放到老年区)。
- 清空 eden、servicorFrom,以及互换这两个区域名字。
JVM线程模型
一般来说,线程模型有三种,分别是:
- 内核线程模型。
完全由操作系统内核提供的内核线程(Kernel-Level Thread ,KLT)来实现多线程。在此模型下,线程的切换调度由系统内核完成,系统内核负责将多个线程执行的任务映射到各个CPU中去执行。操作系统内核提供的内核线程(Kernel-Level Thread ,KLT)来实现多线程。在此模型下,线程的切换调度由系统内核完成,系统内核负责将多个线程执行的任务映射到各个CPU中去执行。由于内核线程的支持,每个轻量级进程都成为一个独立的调度单元,即使有一个轻量级进程在系统调用中阻塞了,也不会影响整个进程继续工作,但是轻量级进程具有它的局限性:
首先,由于是基于内核线程实现的,所以各种线程操作,如创建、析构及同步,都需要进行系统调用。而系统调用的代价相对较高,需要在用户态(User Mode)和内核态(Kernel Mode)中来回切换。
其次,每个轻量级进程都需要有一个内核线程的支持,因此轻量级进程要消耗一定的内核资源(如内核线程的栈空间),因此一个系统支持轻量级进程的数量是有限的。

- 用户线程模型。
用户线程指的是完全建立在用户空间的线程库上,系统内核不能感知线程存在的实现。用户线程的建立、同步、销毁和调度完全在用户态中完成,不需要内核的帮助。如果程序实现得当,这种线程不需要切换到内核态,因此操作可以是非常快速且低消耗的,也可以支持规模更大的线程数量,部分高性能数据库中的多线程就是由用户线程实现的。这种进程与用户线程之间1:N的关系称为一对多的线程模型。使用用户线程的优势在于不需要系统内核支援,劣势也在于没有系统内核的支援,所有的线程操作都需要用户程序自己处理。线程的创建、切换和调度都是需要考虑的问题,而且由于操作系统只把处理器资源分配到进程,那诸如“阻塞如何处理”、“多处理器系统中如何将线程映射到其他处理器上”这类问题解决起来将会异常困难,甚至不可能完成。因而使用用户线程实现的程序一般都比较复杂,此处所讲的“复杂”与“程序自己完成线程操作”,并不限制程序中必须编写了复杂的实现用户线程的代码,使用用户线程的程序,很多都依赖特定的线程库来完成基本的线程操作,这些复杂性都封装在线程库之中,除了以前在不支持多线程的操作系统中(如DOS)的多线程程序与少数有特殊需求的程序外,现在使用用户线程的程序越来越少了,Java、Ruby等语言都曾经使用过用户线程,最终又都放弃使用它。

- 混合线程模型
线程除了依赖内核线程实现和完全由用户程序自己实现之外,还有一种将内核线程与用户线程一起使用的实现方式。在这种混合实现下,既存在用户线程,也存在轻量级进程。用户线程还是完全建立在用户空间中,因此用户线程的创建、切换、析构等操作依然廉价,并且可以支持大规模的用户线程并发。而操作系统提供支持的轻量级进程则作为用户线程和内核线程之间的桥梁,这样可以使用内核提供的线程调度功能及处理器映射,并且用户线程的系统调用要通过轻量级线程来完成,大大降低了整个进程被完全阻塞的风险。在这种混合模式中,用户线程与轻量级进程的数量比是不定的,即为N:M的关系。许多UNIX系列的操作系统,如Solaris、HP-UX等都提供了N:M的线程模型实现。

对于Sun JDK来说,它的Windows版与Linux版都是使用一对一的线程模型(即内核线程模型)实现的,一条Java线程就映射到一条轻量级进程之中,因为Windows和Linux系统提供的线程模型就是一对一的。
JVM 允许一个应用并发执行多个线程。Hotspot JVM 中的 Java 线程与原生操作系统线程有直接的映射关系。当线程本地存储、缓冲区分配、同步对象、栈、程序计数器等准备好以后,就会创建一个操作系统原生线程。Java 线程结束,原生线程随之被回收。操作系统负责调度所有线程,并把它们分配到任何可用的 CPU 上。当原生线程初始化完毕,就会调用 Java 线程的 run() 方法。当线程结束时,会释放原生线程和 Java 线程的所有资源。
此部分参考资料:https://www.cnblogs.com/kaleidoscope/p/9598140.html
Hotspot JVM 后台运行的系统线程主要有下面几个:
| 线程名 | 功能 |
|---|---|
| 虚拟机线程(VM thread) | 这个线程等到 JVM 到达安全点操作出现。这些操作的类型有:stop-the-world 垃圾回收、线程栈 dump、线程暂停、线程偏向锁(biased locking)解除。具体来说:The VMThread spends its time waiting for operations to appear in the VMOperationQueue, and then executing those operations. Typically these operations are passed on to the VMThread because they require that the VM reach a safepoint before they can be executed. In simple terms, when the VM is at safepoint all threads inside the VM have been blocked, and any threads executing in native code are prevented from returning to the VM while the safepoint is in progress. This means that the VM operation can be executed knowing that no thread can be in the middle of modifying the Java heap, and all threads are in a state such that their Java stacks are unchanging and can be examined.The most familiar VM operation is for garbage collection, or more specifically for the “stop-the-world” phase of garbage collection that is common to many garbage collection algorithms. But many other safepoint based VM operations exist, for example: biased locking revocation, thread stack dumps, thread suspension or stopping (i.e. The java.lang.Thread.stop() method) and numerous inspection/modification operations requested through JVMTI.Many VM operations are synchronous, that is the requestor blocks until the operation has completed, but some are asynchronous or concurrent, meaning that the requestor can proceed in parallel with the VMThread (assuming no safepoint is initiated of course).Safepoints are initiated using a cooperative, polling-based mechanism. In simple terms, every so often a thread asks “should I block for a safepoint?”. Asking this question efficiently is not so simple. One place where the question is often asked is during a thread state transition. Not all state transitions do this, for example a thread leaving the VM to go to native code, but many do. The other places where a thread asks are in compiled code when returning from a method or at certain stages during loop iteration. Threads executing interpreted code don’t usually ask the question, instead when the safepoint is requested the interpreter switches to a different dispatch table that includes the code to ask the question; when the safepoint is over, the dispatch table is switched back again. Once a safepoint has been requested, the VMThread must wait until all threads are known to be in a safepoint-safe state before proceeding to execute the VM operation. During a safepoint the Threads_lock is used to block any threads that were running, with the VMThread finally releasing the Threads_lock after the VM operation has been performed. |
| 周期性任务线程 | 这线程负责定时器事件(也就是中断),用来调度周期性操作的执行。 |
| GC线程 | 这些线程支持 JVM 中不同的垃圾回收活动。 |
| 编译器线程 | 这些线程在运行时将字节码动态编译成本地平台相关的机器码。 |
| 信号分发线程 | 这个线程接收发送到 JVM 的信号并调用适当的 JVM 方法处理。 |
此部分参考资料: https://openjdk.java.net/groups/hotspot/docs/RuntimeOverview.html
垃圾回收
GC Roots
可达性分析中GC Roots对象包括下列几种:
- 虚拟机栈引用的对象
- 方法区中类静态属性引用的对象。
- 方法区中常量引用的对象。
- 本地方法栈中JNI引用的对象。
- 虚拟机内部的引用,比如基本数据类型对应的class对象。
- 所有同步锁持有的对象。
- 反应虚拟机内部情况的JMXBean、JVMTI注册的回调,本地代码缓存等。
- 局部回收时,某个区域中的对象完全可能被其他区域的对象所引用,所以关联区域的对象也一并加入GC Roots。
由于目前主流Java虚拟机使用的都是准确式垃圾收集(指虚拟机可以准确知道一段值是代码还是数据),因此虚拟机并不需要一个不漏的检查完所有执行上下文和全局的位置,而是有办法直接得到哪些地方存着对象的引用。Hotspot使用OopMap来完成任务,一旦类加载完成,HotSpot就会把对象内什么偏移量上是什么类型的数据计算出来。
OopMap 记录了栈上本地变量到堆上对象的引用关系。其作用是:垃圾收集时,收集线程会对栈上的内存进行扫描,看看哪些位置存储了 Reference 类型。如果发现某个位置确实存的是 Reference 类型,就意味着它所引用的对象这一次不能被回收。但问题是,栈上的本地变量表里面只有一部分数据是 Reference 类型的(它们是我们所需要的),那些非 Reference 类型的数据对我们而言毫无用处,但我们还是不得不对整个栈全部扫描一遍,这是对时间和资源的一种浪费。
一个很自然的想法是,能不能用空间换时间,在某个时候把栈上代表引用的位置全部记录下来,这样到真正 gc 的时候就可以直接读取,而不用再一点一点的扫描了。事实上,大部分主流的虚拟机也正是这么做的,比如 HotSpot ,它使用一种叫做 OopMap 的数据结构来记录这类信息。
我们知道,一个线程意味着一个栈,一个栈由多个栈帧组成,一个栈帧对应着一个方法,一个方法里面可能有多个安全点。 gc 发生时,程序首先运行到最近的一个安全点停下来,然后更新自己的 OopMap ,记下栈上哪些位置代表着引用。枚举根节点时,递归遍历每个栈帧的 OopMap ,通过栈中记录的被引用对象的内存地址,即可找到这些对象( GC Roots )。
可以把oopMap简单理解成是调试信息。在源代码里面每个变量都是有类型的,但是编译之后的代码就只有变量在栈上的位置了。oopMap就是一个附加的信息,告诉你栈上哪个位置本来是个什么东西。 这个信息是在JIT编译时跟机器码一起产生的。因为只有编译器知道源代码跟产生的代码的对应关系。 每个方法可能会有好几个oopMap,就是根据safepoint把一个方法的代码分成几段,每一段代码一个oopMap,作用域自然也仅限于这一段代码。 循环中引用多个对象,肯定会有多个变量,编译后占据栈上的多个位置。那这段代码的oopMap就会包含多条记录。
通过上面的解释,我们可以很清楚的看到使用 OopMap 可以避免全栈扫描,加快枚举根节点的速度。但这并不是它的全部用意。它的另外一个更根本的作用是,可以帮助 HotSpot 实现准确式 GC 。
但是随着而来的又有一个问题,就是在方法执行的过程中, 可能会导致引用关系发生变化,那么保存的OopMap就要随着变化。如果每次引用关系发生了变化都要去修改OopMap的话,这又是一件成本很高的事情。所以这里就引入了安全点的概念。
什么是安全点?OopMap的作用是为了在GC的时候,快速进行可达性分析,所以OopMap并不需要一发生改变就去更新这个映射表。只要这个更新在GC发生之前就可以了。所以OopMap只需要在预先选定的一些位置上记录变化的OopMap就行了。这些特定的点就是SafePoint(安全点)。由此也可以知道,程序并不是在所有的位置上都可以进行GC的,只有在达到这样的安全点才能暂停下来进行GC。
既然安全点决定了GC的时机,那么安全点的选择就至为重要了。安全点太少,会让GC等待的时间太长,太多会浪费性能。所以安全点的选择是以程序“是否具有让程序长时间执行的特征”为标准的,所以我们这里了解一下结果就行了。一般会在如下几个位置选择安全点:
- 循环的末尾
- 方法临返回前 / 调用方法的call指令后
- 可能抛异常的位置
安全点另一方面问题:如何让垃圾收集时所有线程都到达安全点:主要有两种方案:抢先式中断和主动式中断。
抢断式中断就是在GC的时候,让所有的线程都中断,如果这些线程中发现中断地方不在安全点上的,就恢复线程,让他们重新跑起来,直到跑到安全点上。
主动式中断在GC的时候,不会主动去中断线程,仅仅是设置一个标志,当程序运行到安全点时就去轮训该位置,发现该位置被设置为真时就自己中断挂起。所以轮训标志的地方是和安全点重合的,另外创建对象需要分配内存的地方也需要轮询该位置。
但是安全点也不是完美的,对于处于Sleep或者block的线程,无法到达安全点,因此引入了安全区域进行处理。
此部分参考资料:
https://blog.csdn.net/dyingstarAAA/article/details/88559806,https://my.oschina.net/u/1757225/blog/1583822
四种引用类型
- 强引用。即传统引用。
- 软引用。用来描述还有用,但非必须的对象。仅在系统内存即将溢出时回收。SoftReference类。常用于缓存等场景。
- 弱引用。必须程度小于软引用。在下一次垃圾收集时回收。WeakReference类。ThreadLocal类。
- 虚引用。最弱的引用,一个对象是否有虚引用的存在,不会对其生存时间构成影响,也无法通过虚引用获取一个对象实例。虚引用一般用于在一个对象被回收时收到一个系统通知。虚引用一般和一个队列绑定。PhantomReference类。虚引用主要用来跟踪对象被垃圾回收的活动。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象之前,把这个虚引用加入到与之关联的引用队列中。程序如果发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
参考资料:https://zhuanlan.zhihu.com/p/408186038
常见垃圾回收算法
- 标记清除算法(mark-sweep)。标记所有需要回收的对象,并在标记完成后,统一回收所有被标记的对象。会产生内存碎片化严重,后续可能发生大对象不能找到可利用空间的问题,并且如果Java堆中包含大量需要回收的对象,必须进行大量标记和清除的动作。
- 复制算法。 为了解决 Mark-Sweep 算法内存碎片化的缺陷而被提出的算法。按内存容量将内存划分为等大小的两块。每次只使用其中一块,当这一块内存满后将尚存活的对象复制到另一块上去,把已使用的内存清掉。这种算法虽然实现简单,内存效率高,不易产生碎片,但是最大的问题是可用内存被压缩到了原本的一半。且存活对象增多的话,Copying 算法的效率会大大降低。
- 标记整理算法(Mark-Compact)。结合了以上两个算法,为了避免缺陷而提出。标记阶段和 Mark-Sweep 算法相同,标记后不是清理对象,而是将存活对象移向内存的一端。然后清除端边界外的对象。
- 分代收集算法。分代收集法是目前大部分 JVM 所采用的方法,其核心思想是根据对象存活的不同生命周期将内存划分为不同的域,一般情况下将 GC 堆划分为老生代(Tenured/Old Generation)和新生代(Young Generation)。老生代的特点是每次垃圾回收时只有少量对象需要被回收,新生代的特点是每次垃圾回收时都有大量垃圾需要被回收,因此可以根据不同区域选择不同的算法。
目前大部分 JVM 的 GC 对于新生代都采取 Copying 算法,因为新生代中每次垃圾回收都要回收大部分对象,即要复制的操作比较少,但通常并不是按照 1:1 来划分新生代。一般将新生代划分为一块较大的 Eden 空间和两个较小的 Survivor 空间(From Survivor , To Survivor ),每次使用Eden 空间和其中的一块 Survivor 空间,当进行回收时,将该两块空间中还存活的对象复制到另一块 Survivor 空间中,Eden:From Survivor:To Survivor =8:1:1。而老年代因为每次只回收少量对象,因而采用 Mark-Compact 算法。当对象在 Survivor 区躲过一次 GC 后,其年龄就会+1。默认情况下年龄到达 15 的对象会被移到老生代中。
目前的分代回收器中,新生代占总空间的1/3,老年代占2/3.。
实际上,并不是内存被耗空的时候才抛出OutOfMemoryException,而是JVM98%的时间都花费在内存回收,每次回收的内存小于2%满足时就抛出异常。
常见的垃圾回收器
- Serial
用于新生代,单线程,STW时间长。 - SerialOld
用于老年代,单线程的。一样有STW。 - ParallelScavenger
在Serial基础上,使用了多线程。 - ParallelOld
应用于老年代,多线程的。一样有STW。 - ParNew
与ParallelScavenger的区别就是,PN能更好的和CMS配合使用,PN的响应时间优先,PS的吞吐量优先。 - CMS
三色标记:
黑色标记:自己已经标记,直接引用的对象区域已经标记
灰色标记:自己标记完成,但引用区域没来得及标记
白色标记:没有遍历到的区域,可以理解为没有标记
三色标记的漏标问题:
原本A引用B,B引用C,在A被标记为黑色后,A建立了指向C的引用,且B指向C的引用断开。此时A已经被标记为黑色,则不会再便利A的引用,且B对C的引用已经断开。这样会造成C未被标记,被垃圾回收,造成空指针问题。
CMS解决方式:
当发生A引用C<黑色对象指向了白色对象>的情况。此时将A标记为灰色。并且在全部标记结束后,会有一个remark阶段,必须从头扫描一遍。发生在重新标记阶段,所以在这个阶段必须STW。
CMS有4个主要阶段:初始标记阶段、并发标记阶段、重新标记阶段、并发清理阶段。
初始标记阶段:开始一个短暂的STW,然后进行初始标记,初始标记只标记根节点,所以这个STW时间很短。这个阶段是单线程的。
并发标记阶段:据说GC大部分时间都浪费在这,所以这一步是和工作线程同时运行的。一边产生垃圾,一边标记垃圾。
重新标记阶段:开始一个短暂的STW,把在并发标记阶段,工作线程产生的垃圾重新标记一下,这个STW时间也很短。这个阶段是多线程的。
并发清理阶段:工作线程和垃圾回收线程同时运行,把这个时候工作线程产生的垃圾叫做浮动垃圾,浮动垃圾就要等到下一次CMS清理了。CMS标记的一个实例:
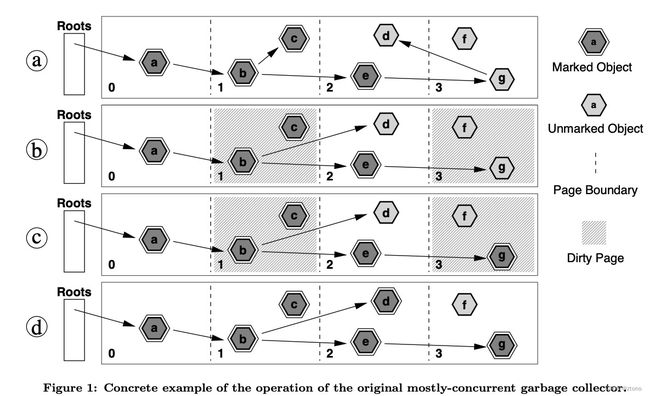
CMS是老年代的垃圾回收器,在老年代分配不下的时候,触发CMS。
CMS的最大问题:CMS会使内存碎片化,老年代产生了很多的碎片,然后从年轻代过来的对象无法找到空间,造成了promotion failed。这时候,CMS既没有机会进行垃圾回收,又放不下新来的对象,在这种情况下,CMS会调用SerialOld来进行垃圾回收。 - G1
G1在逻辑上分代,在物理上不分代。G1引入了分而治之的思想,把内存分为一个一个的小块(region)。每个region逻辑上属于下面四种分代中的一种。
四种分代:
a.Old区:老对象
b.Survivor区:存活对象
c.Eden区:新生对象
d.Humongous区:大对象,如果这个对象特别大,可能会跨两个region。
针对三色标记漏标问题,G1解决方案是:
当发生B指向C的引用<指针>断开的时候。将这个引用<指针>记录在一个特定区域。垃圾回收线程在扫描的时候会查看这个区域的增量数据。发现有增量数据。会看C此时还有没有对象指向他,如果有则将区域C标记为灰色。否则不标记<视为可回收垃圾>。 - ZGC
逻辑和物理上都不分代,在并发标记的时候采用的是颜色指针。42位记录地址,4位代表状态,18位的空闲。
垃圾回收器的选择
按内存大小分:

类加载机制
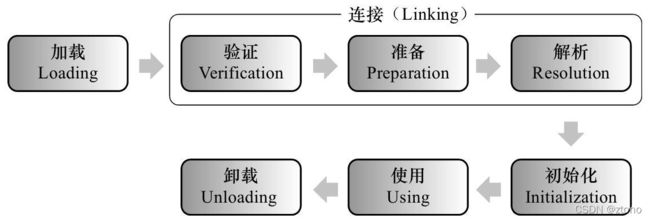
上图为JVM加载Java类的过程。
加载
加载是类加载过程中的一个阶段,这个阶段会在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的入口。注意这里不一定非得要从一个Class文件获取,这里既可以从ZIP包中读取(比如从jar包和war包中读取),从网络中获取(Web Applet),可以在运行时计算生成(动态代理),也可以由其它文件生成(比如将JSP文件转换成对应的Class类),从数据库读取(例如某些中间件服务器),从加密文件中获取(用来防止Class文件被窥探)。用户可以通过自定义的ClassLoader来完成类的加载。
对于数据类来说,其空间是Java直接在内存中动态构造的,但是类加载器还是得加载其中的元素类型。其遵循一下规律。
- 如果数组的组件类型是引用类型。递归采用本节定义的加载过程去加载组件类型。数组C将会标识再加载该组件类型的类加载器的类名称空间上(因为一个类型必须与类加载器一起确定其唯一性)。
- 如果数组的组件类型不是引用类型,例如(int),Java虚拟机会把数组C标记为与引导类加载器管理。
- 数组类的可访问行与它的组件类型的可访问行一致。如果组件类型不是引用类型,他的数组类的可访问行将默认为public,可被所有的类和接口访问到,
验证
这一阶段的主要目的是为了确保Class文件的字节流中包含的信息是否符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
验证主要包括:
- 文件格式验证。主要是字节流是否符合Class文件格式的规范。
- 元数据验证。对字节码所描述的信息进行语义分析,以保证其描述的信息符合Java语言规范。
- 字节码验证。通过数据流分析和控制流分析,确认程序语义是合法的,符合逻辑的,不会危害虚拟机。
- 符号引用验证。发生在虚拟机将符号引用转换为直接引用的时候。
准备
准备阶段是正式为类变量(被static修饰的变量)分配内存并设置类变量的初始值阶段,即在方法区中分配这些变量所使用的内存空间。
解析
解析阶段是指虚拟机将常量池中的符号引用替换为直接引用的过程。符号引用主要有CONSTANT_Class_info, Constant_Fieldref_Info,Constant_Methodref_Info等类型的常量。
符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能够无歧义的定位到目标即可。例如,在Class文件中它以CONSTANT_Class_info、CONSTANT_Fieldref_info、CONSTANT_Methodref_info等类型的常量出现。符号引用与虚拟机的内存布局无关,引用的目标并不一定加载到内存中。在Java中,一个java类将会编译成一个class文件。在编译时,java类并不知道所引用的类的实际地址,因此只能使用符号引用来代替。比如org.simple.People类引用了org.simple.Language类,在编译时People类并不知道Language类的实际内存地址,因此只能使用符号org.simple.Language(假设是这个,当然实际中是由类似于CONSTANT_Class_info的常量来表示的)来表示Language类的地址。各种虚拟机实现的内存布局可能有所不同,但是它们能接受的符号引用都是一致的,因为符号引用的字面量形式明确定义在Java虚拟机规范的Class文件格式中。
此部分参考资料:https://www.cnblogs.com/shinubi/articles/6116993.html
初始化
初始化阶段是类加载最后一个阶段,前面的类加载阶段之后,除了在加载阶段可以自定义类加载器以外,其它操作都由JVM主导。到了初始阶段,才开始真正执行类中定义的Java程序代码。类初始化主要执行类构造器
以下几种情况不会进行初始化:
- 通过子类引用父类的静态字段,只会触发父类的初始化,而不会触发子类的初始化。
- 定义对象数组,不会触发该类的初始化。
- 常量在编译期间会存入调用类的常量池中,本质上并没有直接引用定义常量的类,不会触发定义常量所在的类。
- 通过类名获取Class对象,不会触发类的初始化。
- 通过Class.forName加载指定类时,如果指定参数initialize为false时,也不会触发类初始化,其实这个参数是告诉虚拟机,是否要对类进行初始化。
- 通过ClassLoader默认的loadClass方法,也不会触发初始化动作。
类加载器和双亲委派模型
- 启动类加载器(Bootstrap ClassLoader)。C++实现,负责加载 JAVA_HOME\lib 目录中的,或通过-Xbootclasspath参数指定路径中的,且被虚拟机认可(按文件名识别,如rt.jar)的类。
- 扩展类加载器(Extension ClassLoader)。负责加载 JAVA_HOME\lib\ext 目录中的,或通过java.ext.dirs系统变量指定路径中的类库。
- 应用程序类加载器(Application ClassLoader)。负责加载用户路径(classpath)上的类库。
当一个类收到了类加载请求,他首先不会尝试自己去加载这个类,而是把这个请求委派给父类去完成,每一个层次类加载器都是如此,因此所有的加载请求都应该传送到启动类加载其中,只有当父类加载器反馈自己无法完成这个请求的时候(在它的加载路径下没有找到所需加载的Class),子类加载器才会尝试自己去加载。 采用双亲委派的一个好处是比如加载位于rt.jar包中的类java.lang.Object,不管是哪个加载器加载这个类,最终都是委托给顶层的启动类加载器进行加载,这样就保证了使用不同的类加载器最终得到的都是同样一个Object对象。

双亲委派模型的好处:
- 安全性,避免了核心类被替换
- 避免了类的重复加载,因为同一个类可以被不同的classLoader加载。
一些特点:
1.全盘负责,当一个类加载器负责加载某个Class时,该Class所依赖的和引用的其他Class也将由该类加载器负责载入,除非显示使用另外一个类加载器来载入。
2.父类委托,先让父类加载器试图加载该类,只有在父类加载器无法加载该类时,才使用本类加载器从自己的类路径中加载该类。
3.缓存机制,缓存机制将会保证所有加载过的Class都会被缓存,当程序中需要使用某个Class时,类加载器先从缓存区寻找该Class,只有缓存区不存在,系统才会读取该类对应的二进制数据,并将其转换成Class对象,存入缓存区。这就是为什么修改了Class后,必须重启JVM,程序的修改才会生效。
java对象内存相关
内存分配机制
类加载完成后会在java堆中划分区域分配给对象。分配包含两种方式:
- 指针碰撞。如果Java堆的内存是规整,即所有用过的内存放在一边,而空闲的放在另一边。分配内存时将位于中间的指针指示器向空闲的内存移动一段与对象大小相等的距离,这样便完成分配内存工作。
- 空闲列表。如果Java堆的内存不是规整的,则需要由虚拟机维护一个列表来记录哪些内存是可用的,这样在分配的时候可以从列表中查询到足够大的内存分配给对象,并在分配后更新列表记录。
选择哪种分配方式是由 Java 堆是否规整来决定的,而 Java 堆是否规整又由所 采用的垃圾收集器是否带有压缩整理功能决定。
那怎么解决内存分配的并发问题呢?
一方面对分配内存空间的行为进行同步处理(采用CAS+失败重试来保证同步);
另一方面给每个进程在java堆中预分配一小块空间(TLAB,Thread Local Allocation Buffer),对象现在tlab上分配空间而TLAB的分配才需要用到同步锁。
从分区角度看,内存一般在eden区分配,如果空间不够进行一次minor GC,如果还不够则启用担保机制在老年代分配。特别的,对于大对象,直接进入老年代。
访问内存中的对象
目前有两种方式:句柄访问和直接指针。
句柄访问是指:Java堆中划分出一块内存来作为句柄池,引用中存储对象的句柄地址,而句柄中包含了对象实例数据(实例池)与对象类型数据(方法区)各自的具体地址信息。这种方法的优势:引用中存储的是稳定的句柄地址,在对象被移动(垃圾收集时移动对象是非常普遍的行为)时只会改变句柄中的实例数据指针,而引用本身不需要修改。
直接指针:如果使用直接指针访问,引用中存储的直接就是对象地址,那么Java堆对象内部的布局中就必须考虑如何放置访问类型数据的相关信息。优势:速度更快,节省了一次指针定位的时间开销。由于对象的访问在Java中非常频繁,因此这类开销积少成多后也是非常可观的执行成本。HotSpot中采用的就是这种方式。
JVM调优
JVM调优可以考虑在以下几个方面进行:
线程池:解决用户响应时间长的问题
连接池
JVM启动参数:调整各代的内存比例和垃圾回收算法,提高吞吐量
程序算法:改进程序逻辑算法提高性能
GC调优
在GC调优之前,我们需要记住下面的原则:
- 多数的Java应用不需要在服务器上进行GC优化;
- 多数导致GC问题的Java应用,都不是因为我们参数设置错误,而是代码问题;
- 在应用上线之前,先考虑将机器的JVM参数设置到最优(最适合);
- 减少创建对象的数量;
- 减少使用全局变量和大对象;
- GC优化是到最后不得已才采用的手段;
- 在实际使用中,分析GC情况优化代码比优化GC参数要多得多;
GC优化的目的有两个:
- 将转移到老年代的对象数量降低到最小;
- 减少full GC的执行时间;
为了达到上面的目的,一般地,你需要做的事情有:
- 减少使用全局变量和大对象;
- 调整新生代的大小到最合适;
- 设置老年代的大小为最合适;
- 选择合适的GC收集器;