MUCNetV2:内存瓶颈和计算负载问题一举突破?分类&检测都有较高性能(附源代码下载)...
关注并星标
从此不迷路
计算机视觉研究院

公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式

论文地址:https://arxiv.org/pdf/2110.15352.pdf
源代码:https://mcunet.mit.edu
计算机视觉研究院专栏
作者:Edison_G
MCUNetV2取得了MCU端新的ImageNet分类记录71.8;更重要的是解锁了MCU端执行稠密预测任务的可能性
一、背景
基于微控制器单元 (MCU) 等微型硬件的物联网设备如今无处不在。在如此微小的硬件上部署深度学习模型将使我们能够实现人工智能的民主化。然而,由于内存预算紧张,微型深度学习与移动深度学习有着根本的不同:普通MCU通常具有小于512kB的SRAM,这对于部署大多数现成的深度学习网络来说太小了。即使对于Raspberry Pi 4等更强大的硬件,将推理放入L2缓存(1MB)也可以显着提高能源效率。这些对具有较小峰值内存使用量的高效AI推理提出了新的挑战。
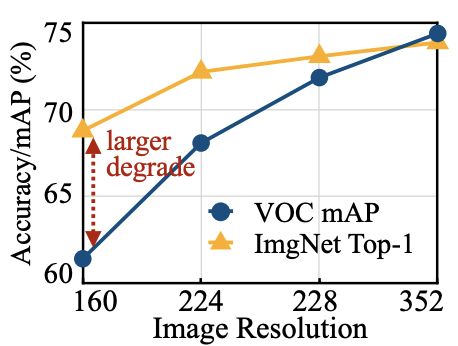
现有工作采用修剪、量化和神经架构搜索来进行高效的深度学习。但是,这些方法侧重于减少参数和FLOP的数量,而不是内存瓶颈。紧张的内存预算限制了特征图/激活大小,限制了我们使用较小的模型容量或较小的输入图像大小。实际上,现有的tinyML工作中使用的输入分辨率通常很小(<224^2),这对于图像分类(例如 ImageNet、VWW)来说可能是可以接受的,但对于像目标检测这样的密集预测任务来说是不可以接受的:如下图图所示,性能与图像分类相比,输入分辨率下物体检测的退化速度要快得多。这种限制阻碍了微型深度学习在许多现实生活任务(例如,行人检测中的应用)。
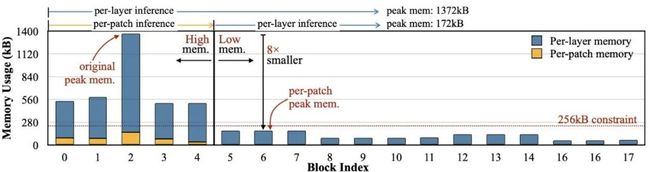
研究者对高效网络设计中每一层的内存使用情况进行了深入分析,发现它们的激活内存分布非常不平衡。以MobileNetV2为例,如下图所示,只有前5个块的内存峰值较高(>450kB),成为整个网络的内存瓶颈。其余13个块的内存使用率较低,可以轻松容纳256kB的MCU。初始内存密集阶段的峰值内存比网络其他部分高8倍。这样的内存模式留下了巨大的优化空间:如果我们能找到一种方法来“绕过”内存密集阶段,我们可以将整体峰值内存减少8倍。
二、前言
由于有限的内存,MCU(MicroController Units, MCU)端的TinyDL极具挑战性。为缓解该问题,研究者提出一种广义的patch-by-patch推理机制,它仅对特征图的局部区域进行处理,大幅降低了峰值内存。然而,常规的实现方式会带来重叠块与计算复杂问题。研究者进一步提出了recptive field redistribution调整感受野与FLOPs以降低整体计算负载。人工方式重分布感受野无疑非常困难!研究者采用NAS对网络架构与推理机制进行联合优化得到了本次分享的MCUNetV2。所提推理机制能大幅降低峰值内存达4-8倍。
所推MCUNetV2取得了MCU端新的ImageNet分类记录71.8% ;更重要的是,MCUNetV2解锁了MCU端执行稠密预测任务的可能性,如目标检测取得了比已有方案高16.9%mAP@VOC的指标。本研究极大程度上解决了TinyDL的内存瓶颈问题,为图像分类之外的其他视觉应用铺平了道路 。
三、新框架
Patch-based Inference:
现有的推理框架(如TFLite Micro, TinyEngine, MicroTVM)采用layer-by-layer方式运行。对于每个卷积层,推理库首先在SRAM中开辟输入与输出buffer,完成计算后释放输入buffer。这种处理机制更易于进行推理优化,但是SRAM必须保留完整的输入与输出buffer。研究者提出一种patch-based inference机制打破初始层的内存瓶颈问题,见下图。
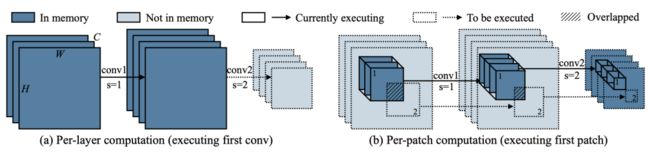
所提patch-based推理则在内存密集阶段以patch-by-patch方式运行 (见上图右)。模型每次仅在小比例区域(比完整区域小10倍)进行计算,这可以有效降低峰值内存占用。当完成该部分后,网络的其他具有较小峰值内存的模块则采用常规的layer-by-layer 方式运行。
以上图stride=1/2的图示为例,对于逐层计算方式,第一层具有大输入输出尺寸,导致非常高内存占用。通过空域拆分计算,以patch-by-patch方式开辟buffer并进行计算,此时我们仅需保存一个块的buffer而非完整特征图。
Computation overhead:
内存节省的代价来自计算负载提升。为与逐层推理相同的输出结果,非重叠输出块需要对应了重叠输入块(见上图b阴影区域)。这种重复性的计算会提升网络整体10-17%计算量,这是低功耗边缘设备所不期望的。
Reducing Computation Overhead by Redistributing the Receptive Field:
计算复杂度与patch方案初始阶段的感受野相关,考虑到patch阶段的输出,越大的感受野对应越大的输入分辨率,进而导致更多的重叠区域与重复计算。对于MobileNetV2来说,如果我们仅考虑下采样,每个输入块的边长为。当提升感受野时,每个输入块需要采用尺寸,导致更大的重叠区域。
研究者提出了重分布(redistribute)感受野以降低计算复杂度,其基本思想在于:
降低patch阶段的感受野;
提升layer阶段的感受野。
降低初始阶段的感受野有助于降低patch部分的输入尺寸与重复计算。然而,某些任务会因感受野较小导致性能下降。因此,我们进一步提升layer部分的感受野以补偿性能损失。
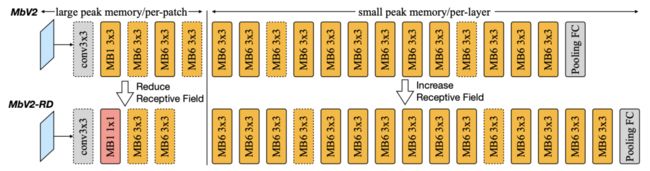
上图给出了以MobileNetV2为例调整前后的架构对比图。在patch推理阶段,采用更小的核与更少的模块,而在layer推理阶段提升模块的数量。
对于两种架构来说,patch推理可以降低SRAM峰值达8倍;原始MobileNetV2设计会导致patch部分42%的计算量增加,整体增加10%;而调整的架构输入尺寸从75下降到了63,整体计算量仅增加3%,模型性能保持同等水平。具体比较见下表:

Joint Neural Architecture and Inference Scheduling Search:
重新分配感受野使我们能够以最小的计算/延迟开销享受内存减少的好处,但策略因不同的主干而有所不同。在设计主干网络(例如,使用更大的输入分辨率)时,减少的峰值内存还允许更大的自由度。为了探索如此大的设计空间,研究者建议以自动化方式联合优化神经架构和推理调度。给定某个数据集和硬件限制(SRAM 限制、Flash 限制、延迟限制等),我们的目标是在满足所有限制条件的同时实现最高准确度。我们有以下要优化的旋钮:
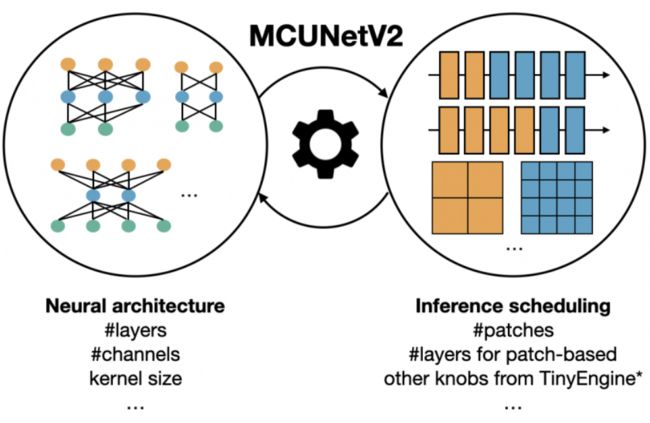
Backbone optimization:研究者参考MCUNet采用了类MnasNet搜索空间,而类MobileNetV3搜索空间因Swish激活函数问题导致难以量化而弃用。作者认为:最佳的搜索空间配置不仅硬件相关,同样任务相关。因此,还将r与w纳入搜索空间。
Inference scheduling optimization:给定模型与硬件约束,将寻找最佳推理机制。框架的推理引擎基于MCUnet中的TinyEngine扩展而来,除了TinyEngine中已有的优化外,还需要确定块数量p与模块数量n以执行patch推理,确保满足SRAM约束。
Joint Search:需要协同设计骨干优化与推理机制。比如,给定相同约束,可以选更小的模型以layer方式推理,或更大的模块以patch方式推理。因此,我们两者纳入优化并采用进化搜索寻找满足约束的最佳组合。
四、实验
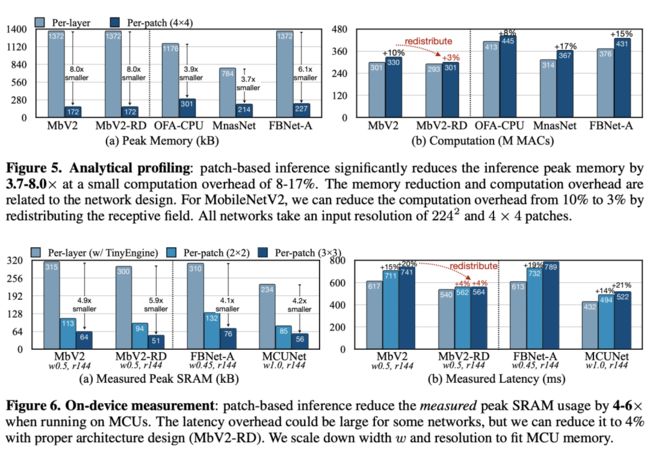
上图1给出了Analytic profiling的结果,它仅与架构有关而与推理框架无关。可以看到:patch推理可以大幅降低峰值内存达3.7-8.0x,仅增加8-17%计算量;对于MobileNetV2,通过重分布感受野可以将额外的计算量从10%降到3%;内存节省与计算降低与网络架构相关,故网络架构与推理引擎的协同设计很有必要 。
上图2给出了on-device profiling的结果,它不仅与架构相关还与硬件相关。可以看到:patch推理可以降低SRAM峰值内存达4-6x 。某些模型可能会因初始阶段的低硬件利用导致更长的推理延迟,但合理的架构设计可以将额外推理延迟降低到4%,相比内存降低完全可以忽略。
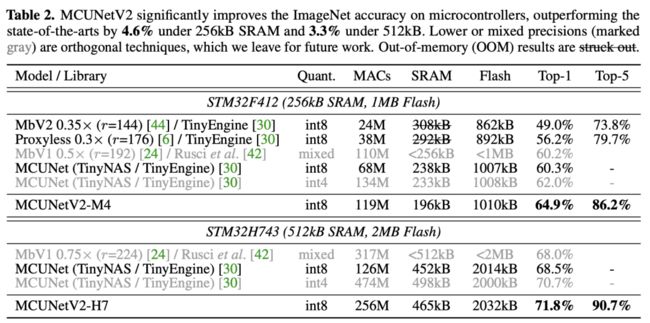
上表给出了ImageNet上的分类性能,从中可以看到:在256kB SRAM/1MB Flash硬件下,MCUNetV2具有比MCUnet高4.6%top1精度、低18%的峰值SRAM的性能。在512kB SRAM/2MB Flash硬件下,MCUNet取得了新的ImageNet记录71.8%(限商用MCU),以3.3%超出了此前同等量化策略方案。
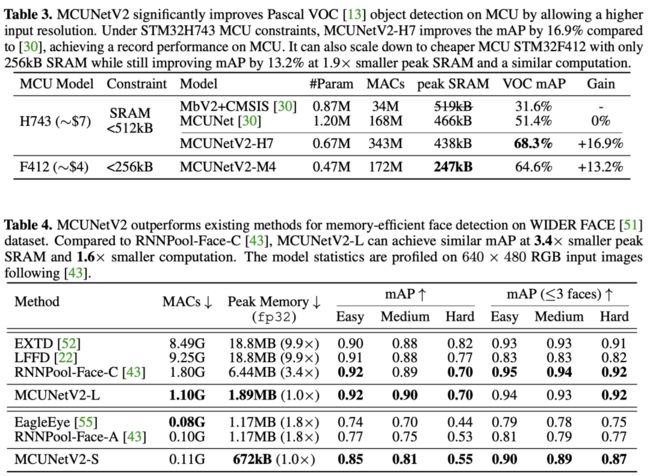
在H7 MCU上,相比MCUNet,MCUNetV2-H7的性能提升达16.7%mAP;在更廉价的M4MCU上,MCUNetV2-M4仍可提升13.2%mAP指标,峰值SRAM降低1.9x。
MUCNetV2-M4与MCUNet具有相似的计算量,但更高的性能。这是因为:patch推理导致的扩展搜索空间使得我们可以在更大的输入分辨率与更小的模型中作出更佳的选择。
在不同尺度下,MCUNetV2均优于现有方案;MCUNetV2-L取得了同等检测性能,但峰值内存被RNNPool-Face-C小3.4x,比LFFD小9.9x;计算量分别小1.6x与8.4x;MCUNetV2-S同样具有比RNNPool-Face-A与EagleEye小1.8x的峰值内存。下图还给出了检测效果的对比,MCUNetV2的鲁棒性更强。

Memory Distributions of Efficient Models
© THE END
转载请联系本公众号获得授权
![]()
计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
旋转角度目标检测的重要性!!!(附源论文下载)
双尺度残差检测器:无先验检测框进行目标检测(附论文下载)
Fast YOLO:用于实时嵌入式目标检测(附论文下载)
Micro-YOLO:探索目标检测压缩模型的有效方法(附论文下载)
目标检测干货 | 多级特征重复使用大幅度提升检测精度(文末附论文下载)
多尺度深度特征(下):多尺度特征学习才是目标检测精髓(论文免费下载)
多尺度深度特征(上):多尺度特征学习才是目标检测精髓(干货满满,建议收藏)
ICCV2021目标检测:用图特征金字塔提升精度(附论文下载)
CVPR21小样本检测:蒸馏&上下文助力小样本检测(代码已开源)
半监督辅助目标检测:自训练+数据增强提升精度(附源码下载)
目标检测干货 | 多级特征重复使用大幅度提升检测精度(文末附论文下载)
目标检测新框架CBNet | 多Backbone网络结构用于目标检测(附源码下载)
CVPR21最佳检测:不再是方方正正的目标检测输出(附源码)
Sparse R-CNN:稀疏框架,端到端的目标检测(附源码)