车牌识别-字符识别(HOG+SVM)
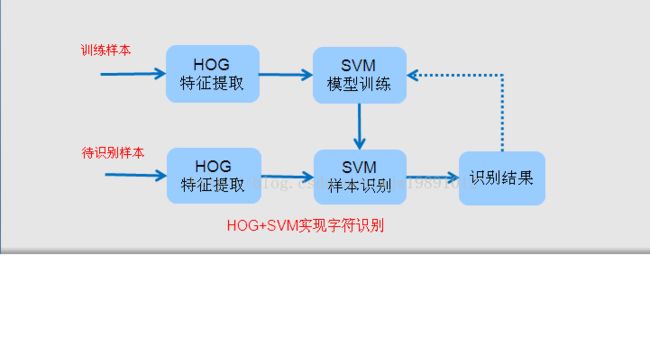
车牌识别-字符识别算法识别架构
实用HOG+SVM算法实现,结合MATLAB进行验证,该算法具有百分之90以上的识别率,具有非常强的实用价值。






字符特征提取相关概念
§概念:
-特征提取是对预处理后的数据进行分析、去粗存精的过程。由于原始图像提取出来的数据量可能会相当大,从大量数据中提取中关键信息转换为若干特征,这个过程就是特征提取。
§字符特征主要有以下几种:
-区域特征,纹理特征,结构特征(几何不变矩、骨架特征、轮廓特征、笔画特征点、13特征点、拓扑特征),统计特征。
§字符特征提取应满足如下三个要求:
-1、具有较强的分类结果,使得类内样本距离小,类间样本距离大;
-2、具有较强的稳定性和鲁棒性,减少外界影响对图像的干扰导致的笔画断裂,粘连等影响;
-3、特征维数不能太高,提取方法不能太复杂,否则特征提取速度过慢,影响车牌识别系统的实时性;
无论是字符样本还是待识别字符,都需要经过特征提取后才能输入到响应
的识别算法中,所以,特征提取时字符识别的第一步。
§近些年来,在图像目标识别领域不断有学者提出新的特征提取方法,如 矩形特征 ( Haar 特征 ) 、尺度不变特征旋转变换 (SIFT 特征 ) 、局部二值模式 (LBP 特征 ) 、梯度方向直方图 (HOG) 特征,这些方法在不同应用领域取得了巨大成功。其中,HOG特征关注目标形状信息分布,在抗目标表观信息变化方面具有明显优势,利用字符形状信息能较好的识别字符。
§算法来源:法国Navneet Dalal 和 Bill Triggs博士在2005的CVPR上发表的 《 Histograms of OrientedGradients for Human Detection 》一文提出以HOG+SVM的思路进行行人检测,效果突出。
§方向梯度直方图(Histogram of Oriented Gradients ):它是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成特征。这种方法是类似于边缘方向直方图,尺度不变特征变换描述子,形状上下文,但不同之处在于它是通过计算密集均匀间隔的网格细胞,应用重叠的局部对比度归一化来提高精度。
§
§HOG思想:HOG特征是一种性能优异的单一窗口目标检测特征,其思想是通过目标的梯度强度在梯度方向上的分布来描述目标对象的局部外观形状特征。HOG特征更加关注目标局部区域内梯度方向直方图分布,保证了HOG特征对尺寸和光照变化的不敏感性,因为通常目标的变化只会出现在较大的尺度范围内。实验结果表明,HOG特征描述子能够有效的克服目标亮度和尺度的变化。
§
§经过验证参阅大量国内外论文并结合MATLAB论证,使用该算法进行字符特征提取具有非常显著的效果。
§主要思想:在一副图像中,局部目标的表象和形状能够被梯度或边缘的方向密度分布很好地描述。
§本质:梯度的直方图统计信息,而梯度主要存在于边缘的地方。
§实现方法:首先将图像分成小的连通区域,我们把它叫细胞单元然后采集细胞单元中各像素点的梯度的或边缘的方向直方图,并分别统计各个细胞直方图的方向特性,最后把这些直方图组合起来就可以构成特征描述器,输送给后端识别算法模块。
§ %% 测试:方向梯度直方图算法演示提取某个样本的特征
§ %% Using HOGFeatures 使用方向梯度直方图算法进行特征提取
§img = imread(testImages{4,3}); % 某个测试样本 testImages {4,3} 为预测样本( 2 )
§ % ExtractHOG features and HOG visualization
§[hog_2x2, vis2x2]= extractHOGFeatures(img, 'CellSize ',[2 2]); % 提取 HOG 特征(特征提取),窗口越小信息量越多,但是越复杂
§[hog_4x4, vis4x4]= extractHOGFeatures(img, 'CellSize ',[4 4]);
§[hog_8x8, vis8x8]= extractHOGFeatures(img, 'CellSize ',[8 8]);
§ % Show theoriginal image
§figure;
§subplot(2,3,1:3); imshow(img);title( ' 方向梯度直方图对待预测样本特征提取 ')
§ % Visualizethe HOG features 特征提取图
§subplot(2,3,4);
§plot(vis2x2);
§title({ ' CellSize = [2 2]'; [ 'Feature length= ' num2str(length(hog_2x2))]});
§subplot(2,3,5);
§plot(vis4x4);
§title({ ' CellSize = [4 4]'; [ 'Feature length= ' num2str(length(hog_4x4))]});
§subplot(2,3,6);
§plot(vis8x8);
§title({ ' CellSize = [8 8]'; [ 'Feature length= ' num2str(length(hog_8x8))]});
§
§ %% Using HOGFeatures 使用方向梯度直方图算法进行特征提取
§img1 = imread(testImages{6,4}); % 某个测试样本 testImages {4,3} 为预测样本( 2 )
§ % ExtractHOG features and HOG visualization
§[hog_2x2, vis2x2]= extractHOGFeatures(img1, 'CellSize',[2 2]); % 提取 HOG 特征(特征提取),窗口越小信息量越多,但是越复杂
§[hog_4x4, vis4x4]= extractHOGFeatures(img1, 'CellSize',[4 4]);
§[hog_8x8, vis8x8]= extractHOGFeatures(img1, 'CellSize',[8 8]);
§ % Show theoriginal image
§figure;
§subplot(2,3,1:3); imshow(img1);title( ' 方向梯度直方图对待预测样本特征提取 ')
§ % Visualizethe HOG features 特征提取图
§subplot(2,3,4);
§plot(vis2x2);
§title({ ' CellSize = [2 2]'; [ 'Feature length= ' num2str(length(hog_2x2))]});
§subplot(2,3,5);
§plot(vis4x4);
§title({ ' CellSize = [4 4]'; [ 'Feature length= ' num2str(length(hog_4x4))]});
§subplot(2,3,6);
§plot(vis8x8);
§title({ ' CellSize = [8 8]'; [ 'Feature length= ' num2str(length(hog_8x8))]});
MATLAB 系统实现架构
§经过查阅国内外大量论文和结合MATLAB分析验证,提出以下字符识别方案。经前期验证,该算法实现字符识别具有显著效果。
-To illustrate, this paper showshow to classify numerical digits using HOG (Histogram of Oriented Gradient)features [1] and an SVM (Support Vector Machine) classifier. This type ofclassification is often used in many Optical Character Recognition (OCR)applications.
§样本制作是个极为繁琐冗余的过程,时间有限,为了验证本算法的可行性,所以只做了0-9的数字样本作为测试验证。虽然这不包括所有的字符(数字,字母,汉字),但是也有足够的数据来训练和测试分类,并表明该方法的可行性。
§训练样本:
-范围0-9,每个字符有100个不同的切割形态,一共10*100,每个样本图像大小为16*16。
§待识别样本:
-范围0-9,每个字符有12个不同的样本,且和样本库不一样,一共为10*12,每个样本图像大小为16*16。
§训练样本选择的两条基本原则:
-1、它可以极大地影响输出,并且能够被检测和提取出来;
-2、变量之间的关联性尽可能少,最理想状态是变量间均独立;
SVM 模型训练
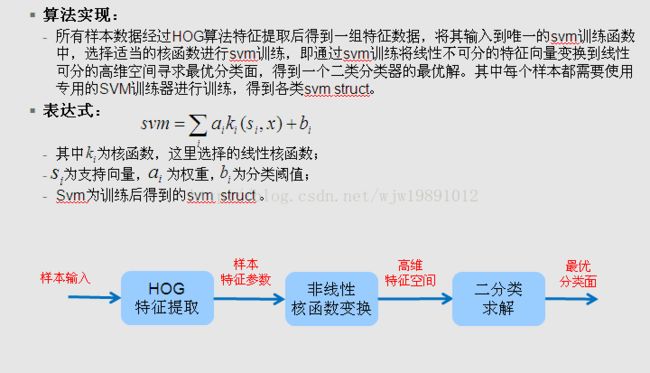
MATLAB中SVM训练函数表达式
§SVMStruct = svmtrain(Training,Group)
-Training:特征提取后的训练数据(每一行对应提取的数据;每一列对应一个特征或者变量
-Group:分组变量,它可以是一个分类,数字,或者逻辑矢量
-SVMStruct:分类器训练支持向量机的信息结构体
-
§根据样本训练后得到的SVM结构体,里面包含了所有字符在特征空间中二分类的最优分类面的解,提供给svm 预测分类。
§ %% 训练分类器 -------- 部分代码 --------
§cellSize = [4 4]; % 实际中用的是 4X4 的 cell
§hogFeatureSize =length(hog_4x4); % 复制一个模板给后端训练,特征向量: 4X4cell 有 324 个
§digits = char( '0'):char( '9');
§ for d =1:numel(digits) % 循环 10 次
§ numTrainingImages =size(trainingImages,1); % 预加载训练数据
§trainingFeatures = zeros(numTrainingImages,hogFeatureSize, 'single ');
§ % 对训练数据进行特征提取,作为分类器的参数
§ for i =1:numTrainingImages % 每一个字符 200 次特征提取
§ img = imread(trainingImages{i,d});
§ img = preProcess(img);
§ trainingFeatures(i,:) = extractHOGFeatures(img, 'CellSize',cellSize); % 得到特征矩阵
§ end
§svm(d)= svmtrain(trainingFeatures,trainingLabels(:,d));
§ % 对提取后的特征进行 SVM 训练,使用线性核函数进行分类
§ end
车牌识别系统指标
§(1)正确率R
-正确率R= (识别正确的车牌数/定位正确的车牌总数)*100%
-正确率反应了字符分割、字符识别的准确率。
§(2)检测率Rs
-检测率Rs =(定位正确的车牌数/真实车牌总数)*100%
-检测率反映了车牌定位算法的优劣,检测率是定位正确的车牌数量与真实车牌总数的比值。
§ (3)误检率Rw
-误检率Rw =(定位出来的伪车牌数/真实车牌总数)*100%
-误检率反映车牌定位出来的伪车牌占真实车牌总数的情况。
§ (4)识别速度T
-车牌识别系统有实时性的要求,要求车牌识别过程,从车牌定位到字符识别速度越快越好。
提高 SVM 识别率若干意见
§1、丰富样本库,使样本之间尽可能独立,具备代表性,样本包含尽可能多的情况;
§
§2、样本库需要不断升级改进,当认为判断识别出错时,需要使用SVM做纠正训练,调整参数;
§
§3、在保证速度的前提下,可适当增加特征向量的维数以提高识别速率;
§
§4、增加负样本集进行逆训练;