基于Paddle的计算机视觉入门教程——第9讲 MobilenetV3网络详解
B站教程地址
https://www.bilibili.com/video/BV18b4y1J7a6/
介绍
Mobilenet是由Google公司创造的网络系列,目前已经发布至V3版本,每一次版本更新都是在前一次网络上的优化修改。Mobilenet主打的是轻量级网络,也就说网络参数量较少,执行速度较快,也更容易部署到终端设备上。在移动端和嵌入式设备上也有了很多的应用。
MobilenetV3对MobilenetV2进行了一系列小的修改,实现了精度的再次突破,速度也有所提升。
主要结构
深度可分离卷积
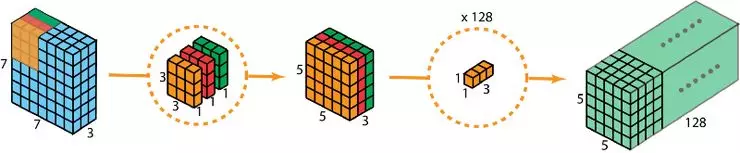
MobilenetV3的主体部分大量使用了深度可分离卷积,在上一讲中我们做了详细的介绍。再次指出,这种卷积结构极大地减少了参数量,对于轻量级的网络是非常有利的。
SE注意力机制
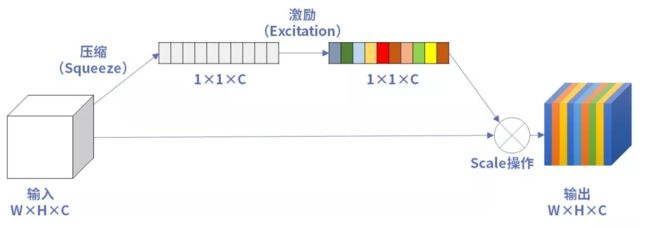
在MobilenetV3的基础结构中,使用了SE注意力机制,这一点我们上一讲也做了介绍。因为SE注意力机制会增加少量的参数,但对于精度有提升,所有MobilenetV3中对某些层加入了SE注意力机制,追求精度和参数量的平衡。而且对初始的注意力机制做了一定的修改,主要体现在卷积层和激活函数。
新型的激活函数
MobilenetV3中使用了Hardswish激活函数,代替了Swish激活。

从公式上来看,Hardswish代替了指数函数,从而降低了计算的成本,使模型轻量化。
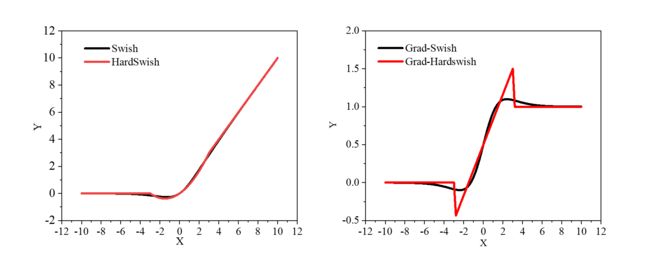
做出函数图像和梯度图像,可以看出原函数非常接近。在梯度图上Hardswish存在突变,这对于训练是不利的,而swish梯度变化平滑。也就是说Hardswish加快了运算速度,但是不利于提高精度。MobilenetV3经过多次实验,发现Hardswish在更深的网络中精度损失较小,最终选用在网络的前半部分使用了Relu激活,在深层网络中使用了Hardswish激活。
修改了尾部结构
MobilenetV3修改了MobilenetV2的尾部结构,具体修改如下:

MobilenetV2最后的尾部使用了四层卷积层再接了一个平均池化,MobilenetV3仅通过一个卷积层修改通道数后,直接接了平均池化层。这也大大减少了网络的参数量,在实验中发现,精度并没有降低。
整体网络
经过以上的一些小的修改后,MobilenetV3的整体网络形式就非常清晰了,它的通用结构单元如下:
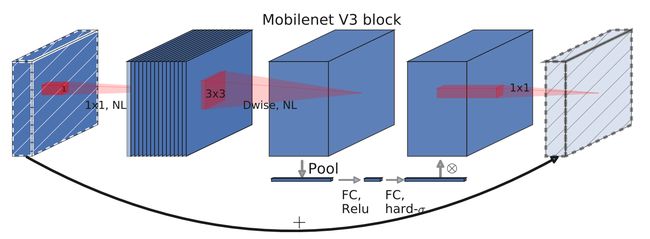
整体网络就是由多个这样的单元堆叠而成。MobilenetV3有large和small两个版本,我们以large为例分析。
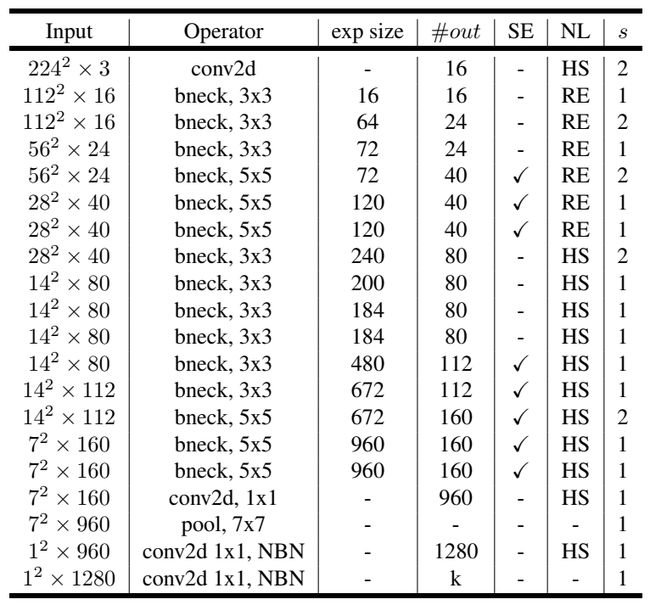
表中input表示输出的shape,exp size表示扩大的通道数,out表示输出通道数,SE表示是否使用SE注意力机制,NL表示使用的激活函数,S表示卷积的步长。
bneck就是第一个图所示的格式,可以看到中间重复使用了多次。先使用一个卷积层,把通道数扩充到16,之后通过多个bneck充分提取特征,然后接着使用一个尾部结构,最后输出一个类别数的矩阵。因为目前写论文通常使用的是imagenet数据集,是一个1000类别的庞大分类数据集,所以官方网络一般最后输出的维度都是1000。
使用PaddleClas训练MobilenetV3
数据集下载链接:
链接:https://pan.baidu.com/s/1ZSHQft4eIpYHliKRxZcChQ
提取码:hce7
PaddleClas是依赖于paddle的视觉分类套件,其中集成了很多分类的典型网络,我们使用PaddleClas中的MobilenetV3训练一下垃圾分类任务。
PaddleClas中MobileNetV3整体的代码实现如下:
class MobileNetV3(TheseusLayer):
"""
MobileNetV3
Args:
config: list. MobileNetV3 depthwise blocks config.
scale: float=1.0. The coefficient that controls the size of network parameters.
class_num: int=1000. The number of classes.
inplanes: int=16. The output channel number of first convolution layer.
class_squeeze: int=960. The output channel number of penultimate convolution layer.
class_expand: int=1280. The output channel number of last convolution layer.
dropout_prob: float=0.2. Probability of setting units to zero.
Returns:
model: nn.Layer. Specific MobileNetV3 model depends on args.
"""
def __init__(self,
config,
scale=1.0,
class_num=1000,
inplanes=STEM_CONV_NUMBER,
class_squeeze=LAST_SECOND_CONV_LARGE,
class_expand=LAST_CONV,
dropout_prob=0.2,
return_patterns=None):
super().__init__()
self.cfg = config
self.scale = scale
self.inplanes = inplanes
self.class_squeeze = class_squeeze
self.class_expand = class_expand
self.class_num = class_num
self.conv = ConvBNLayer(
in_c=3,
out_c=_make_divisible(self.inplanes * self.scale),
filter_size=3,
stride=2,
padding=1,
num_groups=1,
if_act=True,
act="hardswish")
self.blocks = nn.Sequential(* [
ResidualUnit(
in_c=_make_divisible(self.inplanes * self.scale if i == 0 else
self.cfg[i - 1][2] * self.scale),
mid_c=_make_divisible(self.scale * exp),
out_c=_make_divisible(self.scale * c),
filter_size=k,
stride=s,
use_se=se,
act=act) for i, (k, exp, c, se, act, s) in enumerate(self.cfg)
])
self.last_second_conv = ConvBNLayer(
in_c=_make_divisible(self.cfg[-1][2] * self.scale),
out_c=_make_divisible(self.scale * self.class_squeeze),
filter_size=1,
stride=1,
padding=0,
num_groups=1,
if_act=True,
act="hardswish")
self.avg_pool = AdaptiveAvgPool2D(1)
self.last_conv = Conv2D(
in_channels=_make_divisible(self.scale * self.class_squeeze),
out_channels=self.class_expand,
kernel_size=1,
stride=1,
padding=0,
bias_attr=False)
self.hardswish = nn.Hardswish()
self.dropout = Dropout(p=dropout_prob, mode="downscale_in_infer")
self.flatten = nn.Flatten(start_axis=1, stop_axis=-1)
self.fc = Linear(self.class_expand, class_num)
if return_patterns is not None:
self.update_res(return_patterns)
self.register_forward_post_hook(self._return_dict_hook)
def forward(self, x):
x = self.conv(x)
x = self.blocks(x)
x = self.last_second_conv(x)
x = self.avg_pool(x)
x = self.last_conv(x)
x = self.hardswish(x)
x = self.dropout(x)
x = self.flatten(x)
x = self.fc(x)
return x
具体训练也很简单,我们只需要修改相应的配置文件,存放在ppcls/config目录下。对于训练自己的数据集,着重需要修改数据集的相关参数,batch_size以及输出图像的大小等,其他根据自己的需求进行修改。
训练的方法是使用命令行命令。
训练命令:
python tools/train.py -c ./ppcls/configs/quick_start/MobileNetV3_large_x1_0.yaml -o Arch.pretrained=True -o Global.device=gpu
断点训练命令:
python tools/train.py -c ./ppcls/configs/quick_start/MobileNetV3_large_x1_0.yaml -o Global.checkpoints="./output/MobileNetV3_large_x1_0/epoch_5" -o Global.device=gpu
预测命令:
python tools/infer.py -c ./ppcls/configs/quick_start/MobileNetV3_large_x1_0.yaml -o Infer.infer_imgs=./188.jpg -o Global.pretrained_model=./output/MobileNetV3_large_x1_0/best_model
参考资料
https://arxiv.org/abs/1905.02244
https://github.com/PaddlePaddle/PaddleClas
https://blog.csdn.net/qq_42617455/article/details/108165206