Python实现PDF、WORD文档中文本抽取
目录
一、本期文章学习目的
二、开发环境
三、数据分类
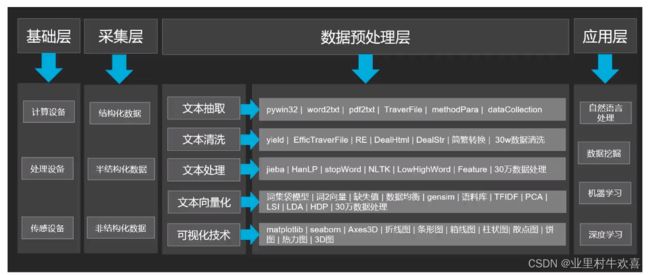
四、知识架构了解
1、数据格式化架构
2、使用工具的差异性
3、数据抽取的ISO架构内容
五、实操代码部分
1、word抽取文字保存为TXT文档
2、pdf抽取文字保存为TXT文档
3、封装文档抽取工具
4、遍历读取文件信息
5、遍历读取文件夹信息,抽取文件夹文档内容保存为TXT文档
一、本期文章学习目的
使用python抽取PDF、WORD文档中文字进行为TXT文件。
二、开发环境
Python3.5.3,系统环境:win10,办公软件office16,编程环境:pycharm+Anaconda3
插件:win32com、os、fnmatch(都可以从Anaconda中安装,这里不演示插件安装了)


三、数据分类



四、知识架构了解
1、数据格式化架构
2、使用工具的差异性
选用免费工具和自己写代码工具的不同点:

3、数据抽取的ISO架构内容
五、实操代码部分
1、word抽取文字保存为TXT文档
2、pdf抽取文字保存为TXT文档
3、封装文档抽取工具
4、遍历读取文件信息
5、遍历读取文件夹信息,抽取文件夹文档内容保存为TXT文档
word-txt

# coding=utf-8
'''
author;Rocky
Description:Word文档信息提取转存TXT
prompt: code in python3 env
function:word文档转存TXT,默认保存在运行环境下面,支持重定义。
参数描述:1、filePath 文件路径。2、savePath:保存路径
'''
import os,fnmatch
from win32com import client as wc
from win32com.client import Dispatch
def word2Txt(filePath,savaPath=''):
#1、切分文件路径为文件目录和文件名
dirs,filename = os.path.split(filePath)
print('输入文档的当前路径和文件名字:',dirs,'\n',filename)
#2、修改切分后的文件后缀
new_name=''
if fnmatch.fnmatch(filename,'*.doc'):
new_name = filename[:-4]+'.txt'
elif fnmatch.fnmatch(filename,'*.docx'):
new_name = filename[:-5]+'.txt'
else:
print('格式不正确,仅支持doc和docx格式')
return
#3、设置新的文件保存路径
if savaPath=='':
savaPath = dirs
else:
savaPath = savaPath
word2TxtPath = os.path.join(savaPath,new_name)
print('转化以后的文件名路径-->',word2TxtPath)
#4、加载文本提取的处理程序,Word - txt
wordapp = wc.Dispatch('Word.Application')
mytxt = wordapp.Documents.Open(filePath)
#5、保存文档文本
mytxt.SaveAs(word2TxtPath,4)
mytxt.Close()
print('转化成功,文件保存为txt文件')
if __name__=='__main__':
filePath = os.path.abspath(r'./1234.docx')#读取项目路径的文档。
word2Txt(filePath)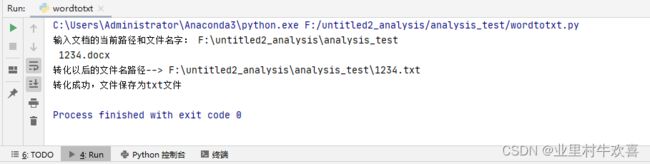
pdf-txt

# coding=utf-8
'''
author;Rocky
Description:pdf,PDF文档信息提取转存TXT
prompt: code in python3 env
function:文档信息转存TXT,默认保存在运行环境下面,支持重定义。
参数描述:1、filePath 文件路径。2、savePath:保存路径、
'''
import os,fnmatch
from win32com import client as wc
from win32com.client import Dispatch
def pdf2Txt(filePath,savaPath=''):
#1、切分文件路径为文件目录和文件名
dirs,filename = os.path.split(filePath)
print('输入文档的当前路径和文件名字:',dirs,'\n',filename)
#2、修改切分后的文件后缀
new_name=''
if fnmatch.fnmatch(filename,'*.pdf'):
new_name = filename[:-4]+'.txt'
elif fnmatch.fnmatch(filename,'*.PDF'):
new_name = filename[:-4]+'.txt'
else:
print('格式不正确,仅支持pdf和PDF格式')
return
#3、设置新的文件保存路径
if savaPath=='':
savaPath = dirs
else:
savaPath = savaPath
pdf2TxtPath = os.path.join(savaPath,new_name)
print('转化以后的文件名路径-->',pdf2TxtPath)
#4、加载文本提取的处理程序,Word - txt
wordapp = wc.Dispatch('Word.Application')
mytxt = wordapp.Documents.Open(filePath)
#5、保存文档文本
mytxt.SaveAs(pdf2TxtPath,4)
mytxt.Close()
print('转化成功,文件保存为txt文件')
if __name__=='__main__':
filePath = os.path.abspath(r'./erp.pdf')#当前项目文档下的路径
pdf2Txt(filePath)
封装Word\pdf-txt的工具

# coding=utf-8
'''
author;Rocky
Description:文档信息提取转存TXT(PDF、word文档)
prompt: code in python3 env
function:PDF、pdf、doc、docx文档转存TXT,默认保存在运行环境下面,支持重定义。
参数描述:1、filePath 文件路径。2、savePath:保存路径 3、filename 文件名字 4、typename文件后缀
'''
import os,fnmatch
from win32com import client as wc
from win32com.client import Dispatch
def file2Txt(filePath,savaPath=''):
try:
#1、切分文件路径为文件目录和文件名
dirs,filename = os.path.split(filePath)
print('输入文档的当前路径和文件名字:',dirs,'\n',filename)
#2、修改切分后的文件后缀
typename = os.path.splitext(filename)[-1].lower()#获得文件后缀
new_name = trantype(filename,typename)
#3、设置新的文件保存路径
if savaPath=='':
savaPath = dirs
else:
savaPath = savaPath
file2TxtPath = os.path.join(savaPath,new_name)
print('转化以后的文件名路径-->',file2TxtPath)
#4、加载文本提取的处理程序,Word、PDF - txt
wordapp = wc.Dispatch('Word.Application')
mytxt = wordapp.Documents.Open(filePath)
#5、保存文档文本
mytxt.SaveAs(file2TxtPath ,4)
mytxt.Close()
print('转化成功,文件保存为txt文件')
except Exception as e :
pass
#6、定义函数,重命名文件名字
def trantype(filename,typename):
new_name=''
if typename == '.pdf':
if fnmatch.fnmatch(filename,'*.pdf'):
new_name = filename[:-4] + '.txt'
else: return
elif typename == '.doc' or typename == '.docx':
if fnmatch.fnmatch(filename,'*.doc') :
new_name = filename[:-4] + '.txt'
elif fnmatch.fnmatch(filename, '*docx'):
new_name = filename[:-5] + '.txt'
else:return
else:
print('警告:\n 您输入的文件不合法,本程序抽取doc,docx,pdf,PDF程序文件,请输入正确格式')
return
return new_name
if __name__=='__main__':
filePath = os.path.abspath(r'./1234.docx')
file2Txt(filePath)
遍历文档,读取文件件中文档信息

# coding=utf-8
'''
author;Rocky
Description:遍历文档,打印文档的名字
prompt: code in python3 env
function:将文档里面的文档名字打印出来,并计算所有需要时间。默认保存在运行环境下面,支持重定义。
参数描述:1、time_start 开始时间。2、time_end 结束时间 3、 rootDir目录文件
'''
import os,fnmatch
from win32com import client as wc
from win32com.client import Dispatch
import time
class TraversalFun():
#1、初始化,rootdir目录文件路径
def __init__(self,rootDir):
self.rootDir = rootDir
#2、遍历目录文件
def TraversalDir(self):
TraversalFun.AllFiles(self, self.rootDir)
#3、递归算法遍历所有文件,并打印文件名
def AllFiles(self,rootDir):
for lists in os.listdir(rootDir):
path = os.path.join(rootDir,lists)
if os.path.isfile(path):
print(os.path.abspath(path))
elif os.path.isdir(path):
TraversalFun.AllFiles(self,path)
if __name__ == '__main__':
time_start = time.time()
rootDir = r"../2010"
tra = TraversalFun(rootDir)
tra.TraversalDir()
time_end = time.time()
print('totally cost:',(time_end - time_start),'s')
遍历整个文档,将pdf,word-txt保存

# coding=utf-8
'''
author;Rocky
Description:抽取文档中的word,pdf文档中的文字,转化为TXT保存。
prompt: code in python3 env
function:将文档里面的文档名字打印出来,并计算所有需要时间。默认保存在运行环境下面,支持重定义。
参数描述: 1、filePath 文件路径。2、savePath:保存路径 3、filename 文件名字 4、typename文件后缀 ,5、time_start 开始时间。6、time_end 结束时间 7、 rootDir目录文件
'''
import os,fnmatch
from win32com import client as wc
from win32com.client import Dispatch
import time
import ExtractTxt as ET #提取PDF、word文档的功能模块
class TraversalFun():
#1、初始化,rootdir目录文件路径
def __init__(self,rootDir,func=None,saveDir=''):
self.rootDir = rootDir#目标文件路径
self.func = func#参数方法,实现文本抽取
self.saveDir = saveDir#文件夹保存路径
#2、遍历目录文件
def TraversalDir(self):
#切分文件目录和文件名
dirs,filename=os.path.split(self.rootDir)
#保存目录
saveDir=""
if self.saveDir=="":
save_dir = os.path.abspath(os.path.join(dirs,'new_',filename))
else: save_dir = self.saveDir
#创建保存路径
if not os.path.exists(save_dir):
os.makedirs(save_dir)
print("保存目录:\n",save_dir)
#遍历文件抽取Txt文本内容
TraversalFun.AllFiles(self, self.rootDir,save_dir)
#3、递归算法遍历所有文件,并打印文件名(并非目录文件)
def AllFiles(self,rootDir,save_dir=''):
#获取根目录下面所有文件
for lists in os.listdir(rootDir):
path = os.path.join(rootDir,lists)
#核心算法,对文件的类型文本进行信息抽取并保存
if os.path.isfile(path):
self.func(os.path.abspath(path),os.path.abspath(save_dir))
#递归遍历整个目录
if os.path.isdir(path):
newsave_dir = os.path.join(save_dir,lists)
if not os.path.exists(newsave_dir):
os.mkdir(newsave_dir)
TraversalFun.AllFiles(self,path,newsave_dir)
if __name__ == '__main__':
time_start = time.time()
rootDir = os.path.abspath(r'../2010')
tra = TraversalFun(rootDir,ET.file2Txt)#调用ET的file2Txt的方法
tra.TraversalDir()
time_end = time.time()
print('totally cost:',(time_end - time_start),'s')
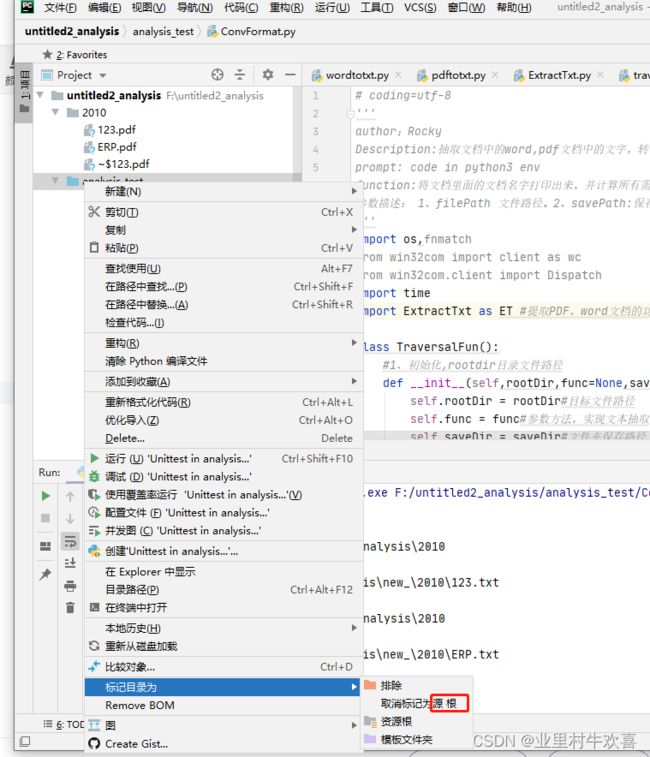
注意:调用项目中的ExtractTxt模块时,需要重新加载标记目录为源根文件夹。才可以使用封装的python写的模块(图片是标记后的截图) 其次转化过程中,word文档会提醒是否将文档转化,需要点击确定。
总结:win32插件实际使用python的office模块进行调用,将文档转化为txt文件。使用os模块读取文件路径进行写入。注意模块之间封装使用,可以调用加入新的代码段中。
特别感谢网友文章参考:
可以学习到什么东西,Python数据预处理(一)一抽取多源数据文本信息教程-慕课网
win32com操作大全(含常见错误解决办法) - 知乎