din、bst 深度兴趣网络排序ctr 数据训练;deepctr加载embedding向量;id类型值hash
deepctr 版本0.8.5
数据下载:
链接:https://pan.baidu.com/s/1m7mViwM-KPJxmTLdpotRRg
提取码:obmu
数据说明:
user端特征有5个,分别为["user_id", "gender", "age", "hist_movie_id", "hist_len"];
user_id 为 用户ID特征,离散特征,从1-3表示;gender 为 用户性别特征,离散特征,从1-2表示; age 为 用户年龄特征,离散特征,从1-3表示; hist_movie_id 为 用户观看的movie序列特征,根据观看的时间倒排,即最新观看的movieID排在前面; hist_len 为 用户观看的movie序列长度特征,连续特征;
●movie端特征有2个,为 ["movie_id", "movie_type_id"];
movie_id 为 movieID特征,离散特征,从1-208表示;movie_type_id 为 movieID 类型特征,离散特征,从1-9表示
数据整理
import pandas as pd
with open("samples.txt",'r') as f:
kkk=f.read().splitlines()
user_id=[]
gender=[]
age=[]
hist_movie_id=[]
hist_len=[]
movie_id=[]
movie_type_id=[]
label=[]
for i in kkk:
aa = i.split()
user_id.append(int(aa[0]))
gender.append(int(aa[1]))
age.append(int(aa[2]))
hist_movie_id.append(list(eval(aa[3])))
hist_len.append(int(aa[4]))
movie_id.append(int(aa[5]))
movie_type_id.append(int(aa[6]))
label.append(int(aa[7]))
datas = pd.DataFrame({'user_id':user_id, 'gender':gender,"age":age,"hist_movie_id":hist_movie_id,"hist_len":hist_len,"movie_id":movie_id,"movie_type_id":movie_type_id,"label":label})
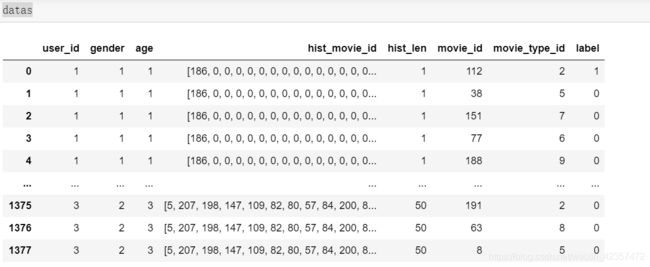
特征模型构建
注意点:
1、feature_columns构建shape要在基础上加1,比如性别为2类,但需要加1,因为是左闭右开区间
2、hist行为序列输入模型需要转化成array([[],[]…[]])格式,np.array(datas[“hist_movie_id”].to_list())
要特别注意的地方是:特征 f 的历史行为序列名为 hist_f 。例如要使用 ‘item_id’, ‘cate_id’ 这两个特征的历史行为序列数据,那么在构造输入数据时,其命名应该加上前缀“hist_” ,即 ‘hist_item_id’, ‘hist_cate_id’。
din
参考:https://blog.csdn.net/VariableX/article/details/108796376
注意:
1、DIN 模型至少需要传入两个参数,一个是 dnn_feature_columns , 用于对所有输入数据进行 embedding;
2、另一个是 history_feature_list,用于指定历史行为序列特征的名字,例如 [“item_id”, “cate_id”]。
import numpy as np
from deepctr.models import DIN
from deepctr.feature_column import SparseFeat, VarLenSparseFeat, DenseFeat,get_feature_names
def get_xy_fd():
feature_columns = [SparseFeat('user_id',1380,embedding_dim=10),SparseFeat(
'gender', 2+1,embedding_dim=4), SparseFeat('age', 4 ,embedding_dim=8), SparseFeat('hist_len', 129 ,embedding_dim=8), SparseFeat('movie_id', 209,embedding_dim=4), SparseFeat('movie_type_id', 10,embedding_dim=4),DenseFeat('hist_len', 1)]
feature_columns += [VarLenSparseFeat(SparseFeat('hist_movie_id', vocabulary_size=209,embedding_dim=8,embedding_name='movie_id'), maxlen=50)
]
behavior_feature_list = ["movie_id"]
feature_dict = {'user_id': datas["user_id"], 'gender': datas["gender"], 'age': datas["age"], 'hist_len': datas["hist_len"],
'movie_type_id': datas["movie_type_id"],'movie_id': datas["movie_id"], 'hist_len': datas["hist_len"], 'hist_movie_id': np.array([ eval(i) for i in datas["hist_movie_id"].to_list()])}
x = {name:feature_dict[name] for name in get_feature_names(feature_columns)}
y = datas["label"]
return x, y, feature_columns, behavior_feature_list
x, y, feature_columns, behavior_feature_list = get_xy_fd()
model8 = DIN(feature_columns, behavior_feature_list)
model8.compile('adam', 'binary_crossentropy',
metrics=['accuracy'])
# metrics=['binary_crossentropy'])
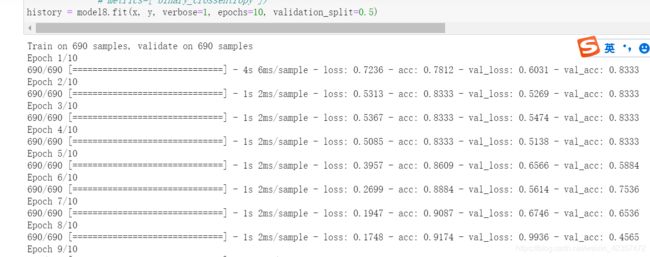
history = model8.fit(x, y, verbose=1, epochs=10, validation_split=0.5)
另外案例(序列必须hist_开头,hist_p_cid_idx,p_cid_idx也必须是为序列的那列名称):
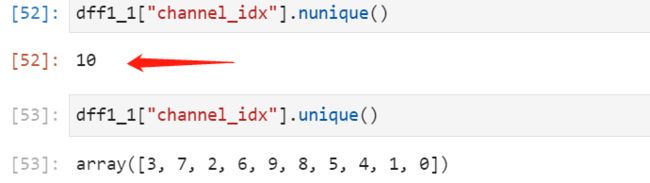
然后SparseFeat的维度一般取得是总共去重后的数,例如下图
from deepctr.models import DIN,BST
from deepctr.feature_column import SparseFeat, VarLenSparseFeat, DenseFeat,get_feature_names
feature_columns = [SparseFeat('channel_idx',10,embedding_dim=30),SparseFeat('is_night', 2,embedding_dim=30),SparseFeat(
'n_dnum_idx', 139582,embedding_dim=30), SparseFeat('p_cid_idx', 28505,embedding_dim=30),DenseFeat('query_title_tfidf', 1),DenseFeat('query_brief_tfidf', 1),DenseFeat('score_minmax', 1),DenseFeat('heat_minmax', 1),
VarLenSparseFeat(SparseFeat('hist_p_cid_idx', vocabulary_size=28505,embedding_name='p_cid_idx', embedding_dim=30), maxlen=20)]
behavior_feature_list = ["p_cid_idx"]
# fixlen_feature_names = get_feature_names(feature_columns)
aaa = [a for a in dff1_1["hist_p_cid_idx"].values.tolist()]
aaa = np.vstack(aaa)
label =dff1_1["label"].values
model_input = {'channel_idx': dff1_1["channel_idx"].values, 'n_dnum_idx': dff1_1["n_dnum_idx"].values, 'p_cid_idx': dff1_1["p_cid_idx"].values, 'query_title_tfidf': dff1_1["query_title_tfidf"].values,
'query_brief_tfidf': dff1_1["query_brief_tfidf"].values, 'is_night': dff1_1["is_night"].values, 'heat_minmax': dff1_1["heat_minmax"].values, 'score_minmax': dff1_1["score_minmax"].values,"hist_p_cid_idx":aaa}
x = {name:model_input[name] for name in get_feature_names(feature_columns)}
model8 = DIN(feature_columns, behavior_feature_list)
# model8 = BST(feature_columns, behavior_feature_list,att_head_num=4)
model8.compile('adam', 'binary_crossentropy',
metrics=['accuracy'])
# metrics=['binary_crossentropy'])
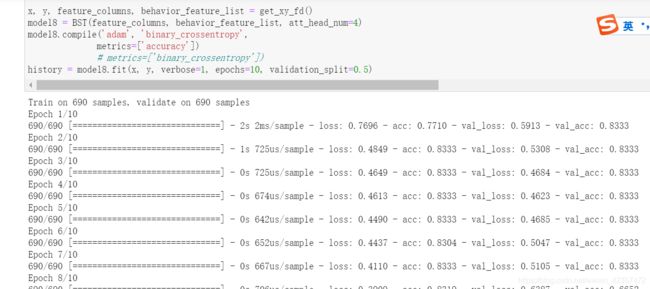
history = model8.fit(x, label, verbose=1, epochs=3, validation_split=0.2)

bst
## bst
def get_xy_fd():
feature_columns = [SparseFeat('user_id',1380,embedding_dim=10),SparseFeat(
'gender', 3,embedding_dim=4), SparseFeat('age', 4 ,embedding_dim=8), SparseFeat('hist_len', 129 ,embedding_dim=8), SparseFeat('movie_id', 209,embedding_dim=4), SparseFeat('movie_type_id', 10,embedding_dim=4),DenseFeat('hist_len', 1)]
feature_columns += [VarLenSparseFeat(SparseFeat('hist_movie_id', vocabulary_size=209,embedding_dim=8,embedding_name='movie_id'), maxlen=50, length_name="seq_length")
]
behavior_feature_list = ["movie_id"]
feature_dict = {'user_id': datas["user_id"], 'gender': datas["gender"], 'age': datas["age"], 'hist_len': datas["hist_len"],
'movie_type_id': datas["movie_type_id"],'movie_id': datas["movie_id"], 'hist_len': datas["hist_len"], 'hist_movie_id':np.array([ eval(i) for i in datas["hist_movie_id"].to_list()]), 'seq_length': datas["hist_len"]}
x = {name:feature_dict[name] for name in get_feature_names(feature_columns)}
y = datas["label"]
return x, y, feature_columns, behavior_feature_list
x, y, feature_columns, behavior_feature_list = get_xy_fd()
model8 = BST(feature_columns, behavior_feature_list, att_head_num=4)
model8.compile('adam', 'binary_crossentropy',
metrics=['accuracy'])
# metrics=['binary_crossentropy'])
history = model8.fit(x, y, verbose=1, epochs=10, validation_split=0.5)
另外案例:
1、seq_length # the actual length of the behavior sequence,比如[1,4,0,0,0]长度2,[9,0,0,0,0]长度1
## seq_length
#
def combine15(x):
hist_p_cid_idx = x["hist_p_cid_idx"].tolist()
counts = hist_p_cid_idx.count(0)
return (20-counts)
dff1_1['seq_length'] = dff1_1.apply(lambda x: combine15(x),axis=1)
#bst
from deepctr.models import DIN,BST
from deepctr.feature_column import SparseFeat,DenseFeat,VarLenSparseFeat,get_feature_names
from tensorflow.keras.metrics import AUC
feature_columns = [SparseFeat('channel_idx',10,embedding_dim=30),SparseFeat('is_night', 2,embedding_dim=30),SparseFeat(
'n_dnum_idx', 139582,embedding_dim=30), SparseFeat('p_cid_idx', 28505,embedding_dim=30),DenseFeat('query_title_tfidf', 1),DenseFeat('query_brief_tfidf', 1),DenseFeat('score_minmax', 1),DenseFeat('heat_minmax', 1),
VarLenSparseFeat(SparseFeat('hist_p_cid_idx', vocabulary_size=28505,embedding_name='p_cid_idx', embedding_dim=28), maxlen=20,length_name="seq_length")]
behavior_feature_list = ["p_cid_idx"]
# fixlen_feature_names = get_feature_names(feature_columns)
aaa = [a for a in dff1_1["hist_p_cid_idx"].values.tolist()]
aaa = np.vstack(aaa)
label =dff1_1["label"].values
seq_length = dff1_1["seq_length"].values
model_input = {'channel_idx': dff1_1["channel_idx"].values, 'n_dnum_idx': dff1_1["n_dnum_idx"].values, 'p_cid_idx': dff1_1["p_cid_idx"].values, 'query_title_tfidf': dff1_1["query_title_tfidf"].values,
'query_brief_tfidf': dff1_1["query_brief_tfidf"].values, 'is_night': dff1_1["is_night"].values, 'heat_minmax': dff1_1["heat_minmax"].values, 'score_minmax': dff1_1["score_minmax"].values,"hist_p_cid_idx":aaa,'seq_length': seq_length}
x = {name:model_input[name] for name in get_feature_names(feature_columns)}
model9 = BST(feature_columns, behavior_feature_list,att_head_num=4)
model9.compile('adam', 'binary_crossentropy',
metrics=['accuracy', AUC(name='auc')])
# metrics=['binary_crossentropy'])
history = model9.fit(x, label, verbose=1, epochs=3, validation_split=0.2)

deepctr加载embedding向量
参考:https://deepctr-doc.readthedocs.io/en/latest/FAQ.html#how-to-use-pretrained-weights-to-initialize-embedding-weights-and-frozen-embedding-weights
SparseFeat:embeddings_initializer矩阵初始化(默认是使用tensorflow.python.keras.initializers.initializers_v2.RandomNormal);trainable矩阵可训练
import tensorflow as tf
from deepctr.models import DeepFM
from deepctr.feature_column import SparseFeat,get_feature_names
pretrained_item_weights = np.random.randn(60,4)
pretrained_weights_initializer = tf.initializers.identity(pretrained_item_weights)
feature_columns = [SparseFeat('user_id',120,),SparseFeat('item_id',60,embedding_dim=4,embeddings_initializer=pretrained_weights_initializer,trainable=False)]
fixlen_feature_names = get_feature_names(feature_columns)
user_id = np.array([[1],[0],[1]])
item_id = np.array([[30],[20],[10]])
label = np.array([1,0,1])
model_input = {'user_id':user_id,'item_id':item_id,}
model = DeepFM(feature_columns,feature_columns)
model.compile('adagrad','binary_crossentropy')
model.fit(model_input,label)
**** long dense feature vector as a input to the model
from deepctr.models import DeepFM
from deepctr.feature_column import SparseFeat, DenseFeat,get_feature_names
import numpy as np
feature_columns = [SparseFeat('user_id',120,),SparseFeat('item_id',60,),DenseFeat("pic_vec",5)]
fixlen_feature_names = get_feature_names(feature_columns)
user_id = np.array([[1],[0],[1]])
item_id = np.array([[30],[20],[10]])
pic_vec = np.array([[0.1,0.5,0.4,0.3,0.2],[0.1,0.5,0.4,0.3,0.2],[0.1,0.5,0.4,0.3,0.2]])
label = np.array([1,0,1])
model_input = {'user_id':user_id,'item_id':item_id,'pic_vec':pic_vec}
model = DeepFM(feature_columns,feature_columns)
model.compile('adagrad','binary_crossentropy')
model.fit(model_input,label)
id类型值hash(SparseFeat和VarLenSparseFeat一般可以操作)
*** use_hash实际调用的是tf.compat.v1.string_to_hash_bucket_fast函数
3是bucket数,hash到3个桶

SparseFeat(‘user’,2,embedding_dim=10,use_hash=True)
*** 2是vocabulary_size,embedding_dim=10===》初始化成维度是2行10维度的矩阵;use_hash为True后可以更改vocabulary_size,把改小点,比如100000个id可以改成100个训练,如果use_hash为False的时候vocabulary_size就不能随意改小,必须与id数量相同才行
import numpy as np
from deepctr.models import DIN
from deepctr.feature_column import SparseFeat, VarLenSparseFeat, DenseFeat,get_feature_names
def get_xy_fd():
feature_columns = [SparseFeat('user',2,embedding_dim=10,use_hash=True),SparseFeat(
'gender', 2,embedding_dim=4), SparseFeat('item_id', 3 + 1,embedding_dim=8), SparseFeat('cate_id', 2 + 1,embedding_dim=4),DenseFeat('pay_score', 1)]
feature_columns += [VarLenSparseFeat(SparseFeat('hist_item_id', vocabulary_size=3 + 1,embedding_dim=8,embedding_name='item_id'), maxlen=4),
VarLenSparseFeat(SparseFeat('hist_cate_id', 2 + 1,embedding_dim=4, embedding_name='cate_id'), maxlen=4)]
print(feature_columns)
behavior_feature_list = ["item_id", "cate_id"]
uid = np.array([0, 1, 2])
ugender = np.array([0, 1, 0])
iid = np.array([1, 2, 3]) # 0 is mask value
cate_id = np.array([1, 2, 2]) # 0 is mask value
pay_score = np.array([0.1, 0.2, 0.3])
hist_iid = np.array([[1, 2, 3, 0], [3, 2, 1, 0], [1, 2, 0, 0]])
hist_cate_id = np.array([[1, 2, 2, 0], [2, 2, 1, 0], [1, 2, 0, 0]])
feature_dict = {'user': uid, 'gender': ugender, 'item_id': iid, 'cate_id': cate_id,
'hist_item_id': hist_iid, 'hist_cate_id': hist_cate_id, 'pay_score': pay_score}
print(get_feature_names(feature_columns))
x = {name:feature_dict[name] for name in get_feature_names(feature_columns)}
print(x)
y = np.array([1, 0, 1])
return x, y, feature_columns, behavior_feature_list
x, y, feature_columns, behavior_feature_list = get_xy_fd()
model8 = DIN(feature_columns, behavior_feature_list)
model8.compile('adam', 'binary_crossentropy',
metrics=['binary_crossentropy'])
history = model8.fit(x, y, verbose=1, epochs=10, validation_split=0.5)