Android性能优化——稳定性优化
APP 稳定性的维度
app 稳定一般指的是 app 能正常运行, app 不能正常运行的情况分为两大类,分别是 Crash 和 ANR。
Crash:运行过程中发生的错误,是无法避免的。
ANR:应用再运行时,由于无法在规定的时间段内响应完,系统做出的一个操作。
如何治理 Crash
应用发生 Crash 是由于应用在运行时,应用产生了一个未处理的异常(就是没有被 try catch 捕获的异常)。这会导致 app 无法正常运行。
如果需要解决的话,就需要知道这个未处理的异常是在哪里产生的,一般是通过分析未处理的异常的方法调用堆栈来解决问题。
Android APP 可以分为 2 层,Java 层和 Native 层。所以如何捕获需要分开说。
Java 层获取未处理的异常的调用堆栈
这个需要了解 Java 虚拟机是如何把一个未捕获的异常报上来的。
未捕获的异常,会沿着方法的调用链依次上抛,调用到Thread的dispatchUncaughtException 方法。
//Thread.java
public interface UncaughtExceptionHandler {
void uncaughtException(Thread t, Throwable e);
}
/**
* Dispatch an uncaught exception to the handler. This method is
* intended to be called only by the runtime and by tests.
*
* @hide
*/
// Android-changed: Make dispatchUncaughtException() public, for use by tests.
public final void dispatchUncaughtException(Throwable e) {
// BEGIN Android-added: uncaughtExceptionPreHandler for use by platform.
Thread.UncaughtExceptionHandler initialUeh =
Thread.getUncaughtExceptionPreHandler();
if (initialUeh != null) {
try {
initialUeh.uncaughtException(this, e);
} catch (RuntimeException | Error ignored) {
// Throwables thrown by the initial handler are ignored
}
}
// END Android-added: uncaughtExceptionPreHandler for use by platform.
getUncaughtExceptionHandler().uncaughtException(this, e);
}
public UncaughtExceptionHandler getUncaughtExceptionHandler() {
return uncaughtExceptionHandler != null ?
uncaughtExceptionHandler : group;
}
//ThreadGroup.java
public void uncaughtException(Thread t, Throwable e) {
if (parent != null) {
// 递归调用,可以忽略
parent.uncaughtException(t, e);
} else {
// 交给了 Thread.getDefaultUncaughtExceptionHandler() 来处理未捕获的异常
Thread.UncaughtExceptionHandler ueh =
Thread.getDefaultUncaughtExceptionHandler();
if (ueh != null) {
ueh.uncaughtException(t, e);
} else if (!(e instanceof ThreadDeath)) {
System.err.print("Exception in thread \""
+ t.getName() + "\" ");
e.printStackTrace(System.err);
}
}
}查阅代码发现,发现 ThreadGroup 最终会给 Thread 的 defaultUncaughtExceptionHandler 处理。
private static volatile UncaughtExceptionHandler defaultUncaughtExceptionHandler;
上面的代码显示:Thread 的 defaultUncaughtExceptionHandler 是 Thread 类的一个静态变量。
看到这里,如何捕获 Java 层未处理的异常就很清晰了,给 Thread 设置一个新的defaultUncaughtExceptionHandler,在这个新的 defaultUncaughtExceptionHandler 里面收集需要的信息就可以了。
需要注意的一点是 旧的 defaultUncaughtExceptionHandler 需要保存下来,然后新的defaultUncaughtExceptionHandler 收集信息后,需要再转给旧的defaultUncaughtExceptionHandler 继续处理。
/**
* UncaughtException处理类,当程序发生Uncaught异常的时候,有该类来接管程序,并记录发送错误报告.
*
* @author user
*/
public class CrashHandler implements UncaughtExceptionHandler {
// 系统默认的UncaughtException处理类
private UncaughtExceptionHandler mDefaultHandler;
// CrashHandler实例
@SuppressLint("StaticFieldLeak")
private static final CrashHandler INSTANCE = new CrashHandler();
private static final long SLEEP_TIME = 3000;
/**
* 保证只有一个CrashHandler实例.
*/
private CrashHandler() {
}
/**
* 获取CrashHandler实例 ,单例模式.
*/
public static CrashHandler getInstance() {
return INSTANCE;
}
/**
* 初始化.
*/
public void init() {
// 获取系统默认的UncaughtException处理器
mDefaultHandler = Thread.getDefaultUncaughtExceptionHandler();
// 设置该CrashHandler为程序的默认处理器
Thread.setDefaultUncaughtExceptionHandler(this);
}
/**
* 当UncaughtException发生时会转入该函数来处理.
*/
@Override
public void uncaughtException(Thread thread, Throwable ex) {
if (!handleException(ex) && mDefaultHandler != null) {
// 如果用户没有处理则让系统默认的异常处理器来处理
mDefaultHandler.uncaughtException(thread, ex);
} else {
try {
Thread.sleep(SLEEP_TIME);
} catch (InterruptedException exception) {
exception.printStackTrace();
}
// 退出程序
android.os.Process.killProcess(android.os.Process.myPid());
System.exit(1);
}
}
/**
* 自定义错误处理,收集错误信息 发送错误报告等操作均在此完成.
*
* @return true:如果处理了该异常信息;否则返回false.
*/
private boolean handleException(Throwable ex) {
if (ex == null) {
return false;
}
//TODO
//显示异常提示,注意考虑主线程异常和子线程异常两种情况
// 收集设备参数信息
// 保存日志文件
return true;
}
}
永不崩溃的APP
Android开发之打造永不崩溃的APP——Crash防护
能否让APP永不崩溃—小光与我的对决
Android崩溃Crash封装库
Cockroach
Native 层获取未处理的异常的相关信息
Java 层如何收集未处理的异常的信息说过了,我们来看看 Native 层发生未处理的异常的话,是如何处理的。Native 层的处理,需要掌握 linux 的一些知识。
Android 平台 Native 代码的崩溃捕获机制及实现
XCrash(crash, ANR)
如何治理 ANR
ANR 是 Applicatipon No Response 的简称。
那我们如何监控 ANR 呢?以及我们如何分析 ANR 的问题呢?常见的导致 ANR 的原因有哪些呢?
首先,ANR 的原理是 AMS 在 UI 操作开始的时候,会根据 UI 操作的类型开启一个延时任务,如果这个任务被触发了,就表示应用卡死或者响应过慢。这个任务会在 UI 操作结束的时候被移除。
然后,如何分析 ANR 问题呢?
一般 ANR 发生的时候, logcat 里面会打印 ANR 相关的信息,过滤关键字 ANR 就可以看到,这里不做详细分析,可以参考后面的文章。
然后一般会在 /data/anr 目录下面生成 traces.txt 文件,里面一般包含了 ANR 发生的时候,系统和所有应用的线程等信息(需要注意的是,不同的 rom 可能都不一样),通过 logcat 打印的信息和 traces.txt 里面的信息,大部分的 ANR 可以分析出原因,但是呢,也有相当一部分的 ANR 问题无法分析,因为 logcat 和 traces.txt 提供的信息有限,有时候甚至没有特别有用的信息,特别是 Android 的权限收紧, traces.txt 文件在高 Android 版本5.0无法读取,给 ANR 问题的分析增加了不少的困难。不过好在最近发现头条给 ANR 写了一个系列的文章,里面对 ANR 问题的治理方法,个人觉得很好,这里引用一下。
-
今日头条 ANR 优化实践系列 - 设计原理及影响因素
-
今日头条 ANR 优化实践系列 - 监控工具与分析思路
-
今日头条 ANR 优化实践系列分享 - 实例剖析集锦
-
今日头条 ANR 优化实践系列 - Barrier 导致主线程假死
ANR 分析思路:
在介绍分析思路之前,我们先来说一下分析这类问题需要用到哪些日志,当然在不同的环境下,获取信息能力会有很大差别,如线下环境和线上环境,应用侧和系统角度都有差异;这里我们会将我们日常排查问题常用的信息都介绍一下,便于大家更好的理解,主要包括以下几种:
-
Trace 日志
-
AnrInfo
-
Kernel 日志
-
Logcat 日志
-
Meminfo 日志
-
Raster 监控工具
对于应用侧来说,在线上环境可能只能拿到当前进程内部的线程堆栈(取决于实现原理,参见:Android 系统的 ANR 设计原理及影响因素)以及 ANR Info 信息。在系统侧,几乎能获取到上面的所有信息,对于这类问题获取的信息越多,分析定位成功率就越大,例如可以利用完整的 Trace 日志,分析跨进程 Block 或死锁问题,系统内存或 IO 紧张程度等等,甚至可以知道硬件状态,如低电状态,硬件频率(CPU,IO,GPU)等等。
关键信息解读:
在这里我们把上面列举的日志进行提取并解读,以便于大家在日常开发和面对线上问题,根据当前获取的信息进行参考。
Trace 信息
在前文Android 系统的 ANR 设计原理及影响因素中,我们讲到了在发生 ANR 之后,系统会 Dump 当前进程以及关键进程的线程堆栈,状态(红框所示关键信息,稍后详细说明),示例如下:
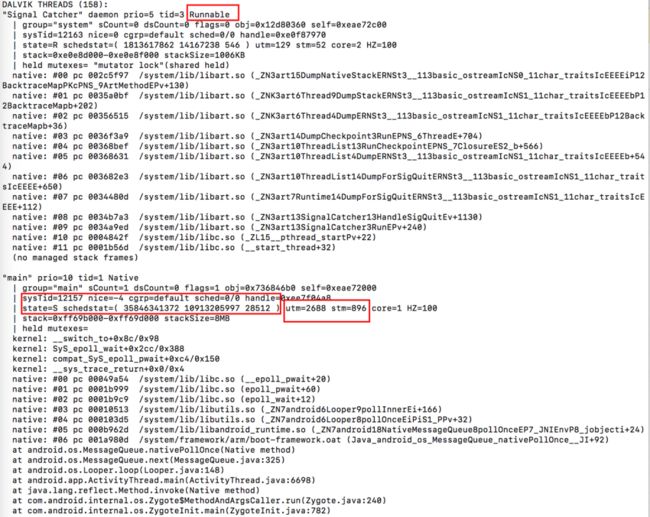
上面的日志包含很多信息,这里将常用的关键信息进行说明,如下:
-
线程堆栈:
-
这个比较好理解,也就是发生 ANR 时,线程正在执行的逻辑,但是很多场景下,获取的堆栈耗时并不长,原因详见Android 系统的 ANR 设计原理及影响因素。
-
-
线程状态:
-
见上图“state=xxx”,表示当前线程工作状态,Running 表示当前线程正在被 CPU 调度,Runnable 表示线程已经 Ready 等待 CPU 调度,如上图 SignalCatcher 线程状态。Native 态则表示线程由 Java 环境进入到 Native 环境,可能在执行 Native 逻辑,也可能是进入等待状态;Waiting 表示处于空闲等待状态。除此之外还有 Sleep,Blocked 状态等等;
-
-
线程耗时:
见上图“utmXXX,stmXXX”,表示该线程从创建到现在,被 CPU 调度的真实运行时长,不包括线程等待或者 Sleep 耗时,其中线程 CPU 耗时又可以进一步分为用户空间耗时(utm)和系统空间耗时(stm),这里的单位是 jiffies,当 HZ=100 时,1utm 等于 10ms。
-
utm: Java 层和 Native 层非 Kernel 层系统调用的逻辑,执行时间都会被统计为用户空间耗时;
-
stm: 即系统空间耗时,一般调用 Kernel 层 API 过程中会进行空间切换,由用户空间切换到 Kernel 空间,在 Kernel 层执行的逻辑耗时会被统计为 stm,如文件操作,open,write,read 等等;
-
core:最后执行这个线程的 cpu 核的序号。
-
线程优先级:
-
nice: 该值越低,代表当前线程优先级越高,理论上享受的 CPU 调度能力也越强。对于应用进程(线程)来说,nice 范围基本在 100~139。随着应用所在前后台不同场景,系统会对进程优先级进行调整,厂商可能也会开启 cpu quota 等功能去限制调度能力;
-
-
调度态:
-
schedstat: 参见“schedstat=( 1813617862 14167238 546 )”,分别表示线程 CPU 执行时长(单位 ns),等待时长,Switch 次数。
-
AnrInfo 信息
除了 Trace 之外,系统会在发生 ANR 时获取一些系统状态,如 ANR 问题发生之前和之后的系统负载以及 Top 进程和关键进程 CPU 使用率。这些信息如果在本地环境可以从 Logcat 日志中拿到,也可以在应用侧通过系统提供的 API 获取(参见:Android 系统的 ANR 设计原理及影响因素),Anr Info 节选部分信息如下:
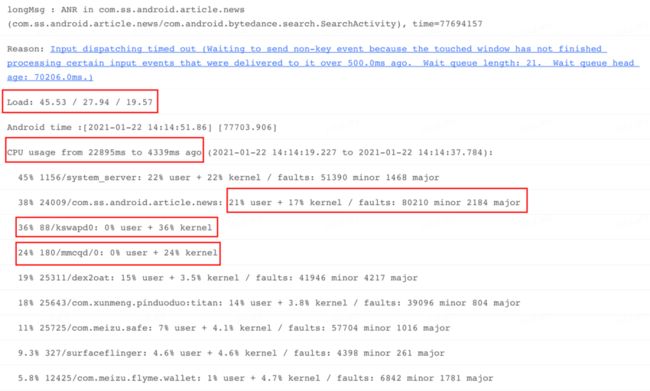
对于上图信息,主要对以下几部分关键信息进行介绍:
-
ANR 类型(longMsg):
-
表示当前是哪种类型的消息或应用组件导致的 ANR,如 Input,Receiver,Service 等等。
-
-
系统负载(Load):
表示不同时间段的系统整体负载,如:"Load:45.53 / 27.94 / 19.57",分布代表 ANR 发生前 1 分钟,前 5 分钟,前 15 分钟各个时间段系统 CPU 负载,具体数值代表单位时间等待系统调度的任务数(可以理解为线程)。如果这个数值过高,则表示当前系统中面临 CPU 或 IO 竞争,此时,普通进程或线程调度将会受到影响。如果手机处于温度过高或低电等场景,系统会进行限频,甚至限核,此时系统调度能力也会受到影响。
此外,可以将这些时间段的负载和应用进程启动时长进行关联。如果进程刚启动 1 分钟,但是从 Load 数据看到前 5 分钟,甚至前 15 分钟系统负载已经很高,那很大程度说明本次 ANR 在很大程度会受到系统环境影响。
-
进程 CPU 使用率:
如上图,表示当前 ANR 问题发生之前(CPU usage from XXX to XXX ago)或发生之后(CPU usage from XXX to XXX later)一段时间内,都有哪些进程占用 CPU 较高,并列出这些进程的 user,kernel 的 CPU 占比。当然很多场景会出现 system_server 进程 CPU 占比较高的现象,针对这个进程需要视情况而定,至于 system_server 进程 CPU 占比为何普遍较高,参见:Android 系统的 ANR 设计原理及影响因素。
minor 表示次要页错误,文件或其它内存被加载到内存后,但是没有被映射到当前进程,通过内核访问时,会触发一次 Page Fault。如果访问的内容还没有加载到内存,那么会触发 major,所以对比可以看到,major 的系统开销会比 minor 大很多。
-
关键进程:
-
kswapd: 是 linux 中用于页面回收的内核线程,主要用来维护可用内存与文件缓存的平衡,以追求性能最大化,当该线程 CPU 占用过高,说明系统可用内存紧张,或者内存碎片化严重,需要进行 file cache 回写或者内存交换(交换到磁盘),线程 CPU 过高则系统整体性能将会明显下降,进而影响所有应用调度。
-
mmcqd: 内核线程,主要作用是把上层的 IO 请求进行统一管理和转发到 Driver 层,当该线程 CPU 占用过高,说明系统存在大量文件读写,当然如果内存紧张也会触发文件回写和内存交换到磁盘,所以 kswapd 和 mmcqd 经常是同步出现的。
-
-
系统 CPU 分布:
如下图,反映一段时间内,系统整体 CPU 使用率,以及 user,kernel,iowait 方向的 CPU 占比,如果发生大量文件读写或内存紧张的场景,则 iowait 占比较高,这个时候则要进一步观察上述进程的 kernel 空间 CPU 使用情况,并通过进程 CPU 使用,再进一步对比各个线程的 CPU 使用,找出占比最大的一个或一类线程。

Logcat 日志:
在 log 日志中,我们除了可以观察业务信息之外,还有一些关键字也可以帮我们去推测当前系统性能是否遇到问题,如下图, “Slow operation”,“Slow delivery” 等等。
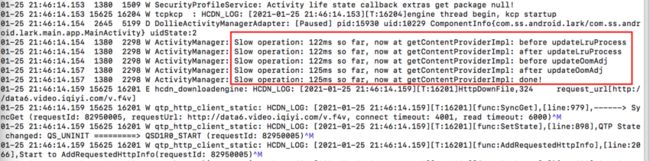
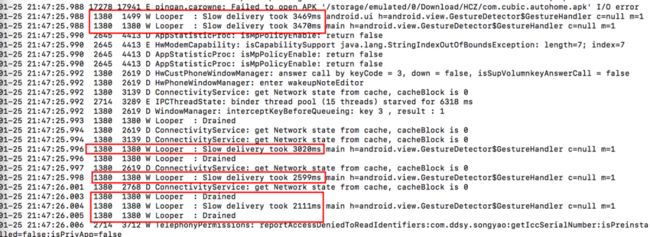
Slow operation
Android 系统在一些频繁调用的接口中,分别在方法前后利用 checktime 检测,以判断本次函数执行耗时是否超过设定阈值,通常这些值都会设置的较为宽松,如果实际耗时超过设置阈值,则会给出“Slow XXX”提示,表示系统进程调度受到了影响,一般来说系统进程优先级比较高,如果系统进程调度都受到了影响,那么则反映了这段时间内系统性能很有可能发生了问题。
Kernel 日志:
对于应用侧来说,这类日志基本是拿不到的,但是如下是在线下测试或者从事系统开发的同学,可以通过 dmesg 命令进行查看。对于 kernel 日志,我们主要分析的是 lowmemkiller 相关信息,如下图:

Lowmemkiller:
从事性能(内存)优化的同学对该模块都比较熟悉,主要是用来监控和管理系统可用内存,当可用内存紧张时,从 kernel 层强制 Kill 一些低优先级的应用,以达到调节系统内存的目的。而选择哪些应用,则主要参考进程优先级(oom_score_adj),这个优先级是 AMS 服务根据应用当前的状态,如前台还是后台,以及进程存活的应用组件类型而计算出来的。例如:对于用户感知比较明显的前台应用,优先级肯定是最高的,此外还有一些系统服务,和后台服务(播放器场景)优先级也会比较高。当然厂商也对此进行了大量的定制(优化),以防止三方应用利用系统设计漏洞,将自身进程设置太高优先级进而达到保活目的。
消息调度时序图:

如上图,在我们分析完系统日志之后,会进一步的锁定或缩小范围,但是最终我们还是要回归到主线程进一步的分析 Trace 堆栈的业务逻辑以及耗时情况,以便于我们更加清晰的知道正在调度的消息持续了多长时间。但是很多情况当前 Trace 堆栈并不是我们期待的答案,因此需要进一步的确认 ANR 之前主线程的调度信息,评估历史消息对后续消息调度的影响,便于我们寻找“真凶”。
当然,有时也需要进一步的参考消息队列中待调度消息,在这些消息里面,除了可以看到 ANR 时对应的应用组件被 Block 的时长之外,还可以了解一下都有哪些消息,这些消息的特征有时对于我们分析问题也会提供有力的证据和方向。
分析思路
在上面我们对各类日志的关键信息进行了基本释义,下面就来介绍一下,当我们日常遇到 ANR 问题时,是如何分析的,总结思路如下:
-
分析堆栈,看看是否存在明显业务问题(如死锁,业务严重耗时等等),如果无上述明显问题,则进一步通过 ANR Info 观察系统负载是否过高,进而导致整体性能较差,如 CPU,Mem,IO。然后再进一步分析是本进程还是其它进程导致,最后再分析进程内部分析对比各个线程 CPU 占比,找出可疑线程。
-
综合上述信息,利用监控工具收集的信息,观察和找出 ANR 发生前一段时间内,主线程耗时较长的消息都有哪些,并查看这些耗时较长的消息执行过程中采样堆栈,根据堆栈聚合展示,进一步的对比当前耗时严重的接口或业务逻辑。
以上分析思路,进一步细分的话,可以分为以下几个步骤:
-
一看 Trace:
-
死锁堆栈: 观察 Trace 堆栈,确认是否有明显问题,如主线程是否与其他线程发生死锁,如果是进程内部发生了死锁,那么恭喜,这类问题就清晰多了,只需找到与当前线程死锁的线程,问题即可解决;
-
业务堆栈: 观察通过 Trace 堆栈,发现当前主线程堆栈正在执行业务逻辑,你找到对应的业务同学,他承认该业务逻辑确实存在性能问题,那么恭喜,你很有可能解决了该问题,为什么只是有可能解决该问题呢?因为有些问题取决于技术栈或框架设计,无法在短时间内解决。如果业务同学反馈当前业务很简单,基本不怎么耗时,而这种场景也是日常经常遇到的一类问题,那么就可能需要借助我们的监控工具,追溯历史消息耗时情况了;
-
IPC Block 堆栈: 观察通过 Trace 堆栈,发现主线程堆栈是在跨进程(Binder)通信,那么这个情况并不能当即下定论就是 IPC block 导致,实际情况也有可能是刚发送 Binder 请求不久,以及想要进一步的分析定位,这时也需要借助我们的自研监控工具了;
-
系统堆栈: 通过观察 Trace,发现当前堆栈只是简单的系统堆栈,想要搞清楚是否发生严重耗时,以及进一步的分析定位,如我们常见的 NativePollOnce 场景,那么也需要借助我们的自研监控工具进一步确认了。
-
-
二看关键字:Load,CPU,Slow Operation,Kswapd,Mmcqd,Kwork,Lowmemkiller 等等
刚才我们介绍到,上面这些关键字是反应系统 CPU,Mem,IO 负载的关键信息,在分析完主线程堆栈信息之后,还需要进一步在 ANRInfo,logcat 或 Kernel 日志中搜索这些关键字,并根据这些关键字当前数值,判断当前系统是否存在资源(CPU,Mem,IO)紧张的情况;
-
三看系统负载分布:观察系统整体负载:User,Sys,IOWait
通过观察系统负载,则可以进一步明确是 CPU 资源紧张,还是 IO 资源紧张;如果系统负载过高,一定是有某个进程或多个进程引起的。反之系统负载过高又会影响到所有进程调度性能。通过观察 User,Sys 的 CPU 占比,可以进一步发分析当前负载过高是发生在应用空间,还是系统空间,如大量调用逻辑(如文件读写,内存紧张导致系统不断回收内存等等),知道这些之后,排查方向又会进一步缩小范围。
-
四看进程 CPU:观察 Top 进程的 CPU 占比
从上面分析,在我们知道当前系统负载过高,是发生在用户空间还是内核空间之后,那么我们就要通过 Anrinfo 的提供的进程 CPU 列表,进一步锁定是哪个(些)进程导致的,这时则要进一步的观察每个进程的 CPU 占比,以及进程内部 user,sys 占比。
-
在分析进程 CPU 占比过程,有一个关键的信息,要看统计这些进程 CPU 过高的场景是发生在 ANR 之前的一段时间还是之后一段时间,如下图表示 ANR 之前 4339ms 到 22895ms 时间内进程的 CPU 使用率。

-
五看 CPU 占比定线程 :对比各线程 CPU 占比,以及线程内部 user 和 kernel 占比
在通过系统负载(user,sys,iowait)锁定方向之后,又通过进程列表锁定目标进程,那么接下来我们就可以从目标进程内部分析各个线程的(utm,stm),进一步分析是哪个线程有问题了。
在 Trace 日志的线程信息里可以清晰的看到每个线程的 utm,stm 耗时。至此我们就完成了从系统到进程,再到进程内部线程方向的负载分析和排查。当然,有时候可能导致系统高负载的不是当前进程,而是其他进程导致,这时同样会影响其他进程,进而导致 ANR。
-
六看消息调度锁定细节 :
-
在分析和明确系统负载是否正常,以及负载过高是哪个进程引起的结论之后,接下来便要通过我们的监控工具,进一步排查是当前消息调度耗时导致,历史消息调度耗时导致,还是消息过于频繁导致。同时通过我们的线程 CheckTime 调度情况分析当前进程的 CPU 调度是否及时以及影响程度,在锁定上述场景之后,再进一步分析耗时消息的采样堆栈,才算找到解决问题的终极之钥。当然耗时消息内部可能存在一个或多个耗时较长的函数接口,或者会有多个消息存在耗时较长的函数接口,这就是我们前文中提到的:“发生 ANR 时,没有一个消息是无辜的”
-
更多信息:
除了上面的一些信息,我们还可以结合 logcat 日志分析 ANR 之前的一些信息,查看是否存在业务侧或系统侧的异常输出,如搜索“Slow operation”,"Slow delivery"等关键字。也可以观察当前进程和系统进程是否存在频繁 GC 等等,以帮忙我们更全面的分析系统状态。