2021年5月总结:小tips
1. matplotlib中如何将图例排成多列?
plt.legend(ncol=2)
#ncol参数可以设置,如成两列
2. python 列表降维_如何给列表降维?
oldlist = [[1, 2, 3], [4, 5]]
newlist = [1, 2, 3, 4, 5]
# 法1
newlist = oldlist[0] + oldlist[1]
# 法2
newlist = [i for j in range(len(oldlist)) for i in oldlist[j]]
# 法3
newlist = sum(oldlist,[])
3. colab防止断开连接,设置自动点击
避免断开连接的方法是,通过console的JavaScript来完成,在网页内,按键 Ctrl Shift + I, 跳到cosole的tab,输入以下的内容:
function ConnectButton(){
console.log("Connect pushed");
document.querySelector("#top-toolbar > colab-connect-button").shadowRoot.querySelector("#connect").click()
}
setInterval(ConnectButton,60000);
这会在每60秒过后去点击连接按钮,保持连接。
这样,按照官方的标称,你就可以长时间使用kenerl达12个小时才会断开。
如果执行完毕了,可以停止这个javascript,定义上面那个函数为空就行了:
function ConnectButton(){
};
4. 创建python2的colab
https://colab.research.google.com/#create=true&language=python2
5. torch是否在用gpu?
import torch
a = torch.cuda.is_available()
print(a)
ngpu= 1
# Decide which device we want to run on
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
print(device)
print(torch.cuda.get_device_name(0))
print(torch.rand(3,3).cuda())
6. ubuntu系统查看CPU信息
总核数 = 物理CPU个数 X 每颗物理CPU的核数
总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数
查看物理CPU个数:
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
查看每个物理CPU中core的个数(即核数):
cat /proc/cpuinfo| grep "cpu cores"| uniq
查看逻辑CPU的个数:
cat /proc/cpuinfo| grep "processor"| wc -l
查看CPU信息(型号):
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
查看cpu信息:
cat /proc/cpuinfo
7. ubuntu系统其它常用命令
查看内存大小:
free –m
查看磁盘大小:
df
查看显卡型号:
lspci |grep VGA
查看gpu的内存使用情况:
nvidia-smi
每隔1s刷新一次gpu使用情况:
watch -n 1 nvidia-smi
8. 设置CUDA_VISIBLE_DEVICES
使用python的os模块:
import os
os.environ['CUDA_VISIBLE_DEVICES']='0'
9. python2转python3容易出现的问题
(1)python3的环境对于除法的规则和python2不一样,把/换成//,后者的运算能够保证是int型数据。
(2)bytes 和 str 互相转换:python的str类型在python3中读出来之后默认是byte类型。
str.encode('utf-8')
bytes.decode('utf-8')
10. yield用法
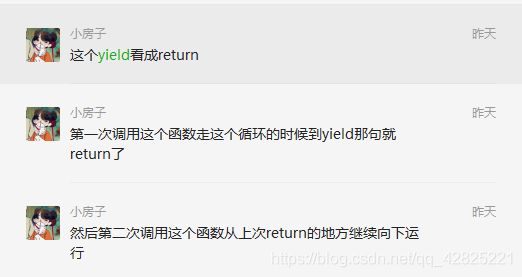
11. matlab作图细节
(1)去掉右边框和上边框的刻度
box off
ax2 = axes('Position',get(gca,'Position'),...
'XAxisLocation','top',...
'YAxisLocation','right',...
'Color','none',...
'XColor','k','YColor','k');
set(ax2,'YTick', []);
set(ax2,'XTick', []);
box on
(2)背景设为白底
set(0,'defaultfigurecolor','w');
12. tensorflow-gpu动态调用内存
config = tf.ConfigProto(allow_soft_placement=True, allow_soft_placement=True)
config.gpu_options.per_process_gpu_memory_fraction = 0.4 #占用40%显存
sess = tf.Session(config=config)
记录设备指派情况 : tf.ConfigProto(log_device_placement=True)
设置tf.ConfigProto()中参数log_device_placement = True,可以获取到 operations 和 Tensor 被指派到哪个设备(几号CPU或几号GPU)上运行,会在终端打印出各项操作是在哪个设备上运行的。
自动选择运行设备 : tf.ConfigProto(allow_soft_placement=True)
在tf中,通过命令 with tf.device('/cpu:0'):,允许手动设置操作运行的设备。如果手动设置的设备不存在或者不可用,就会导致tf程序等待或异常,为了防止这种情况,可以设置tf.ConfigProto()中参数allow_soft_placement=True,允许tf自动选择一个存在并且可用的设备来运行操作。
限制GPU资源使用:
为了加快运行效率,TensorFlow在初始化时会尝试分配所有可用的GPU显存资源给自己,这在多人使用的服务器上工作就会导致GPU占用,别人无法使用GPU工作的情况。
tf提供了两种控制GPU资源使用的方法,一是让TensorFlow在运行过程中动态申请显存,需要多少就申请多少;第二种方式就是限制GPU的使用率。
(1)动态申请显存
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.Session(config=config)
(2)限制GPU使用率
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.4 #占用40%显存
session = tf.Session(config=config)
或者
gpu_options=tf.GPUOptions(per_process_gpu_memory_fraction=0.4)
config=tf.ConfigProto(gpu_options=gpu_options)
session = tf.Session(config=config)
13. 调优方法:学习率调参大法:warmup
warmup
warmup是一种学习率优化方法(最早出现在ResNet论文中)。在模型训练之初选用较小的学习率,训练一段时间之后(如:10epoches或10000steps)使用预设的学习率进行训练。
- 因为模型的weights是随机初始化的,可以理解为训练之初模型对数据的“理解程度”为0(即:没有任何先验知识),在第一个epoches中,每个batch的数据对模型来说都是新的,模型会根据输入的数据进行快速调参,此时如果采用较大的学习率的话,有很大的可能使模型对于数据“过拟合”(“学偏”),后续需要更多的轮次才能“拉回来”;
- 当模型训练一段时间之后(如:10epoches或10000steps),模型对数据具有一定的先验知识,此时使用较大的学习率模型就不容易学“偏”,可以使用较大的学习率加速模型收敛;
- 当模型使用较大的学习率训练一段时间之后,模型的分布相对比较稳定,此时不宜从数据中再学到新特点,如果仍使用较大的学习率会破坏模型的稳定性,而使用小学习率更容易获取local optima。
14.pytorch GPU 计算过程中出现内存耗尽
pytorch GPU 计算过程中出现内存耗尽
Pytorch GPU运算过程中会出现:“cuda runtime error(2): out of memory”这样的错误。通常,这种错误是由于在循环中使用全局变量当做累加器,且累加梯度信息的缘故,用官方的说法就是:“accumulate history across your training loop”。在默认情况下,开启梯度计算的Tensor变量是会在GPU保持他的历史数据的,所以在编程或者调试过程中应该尽力避免在循环中累加梯度信息。
total_loss=0
for i in range(10000):
optimizer.zero_grad()
output=model(input)
loss=criterion(output)
loss.backward()
optimizer.step()
total_loss+=loss
#这里total_loss是跨越循环的变量,起着累加的作用,
#loss变量是带有梯度的tensor,会保持历史梯度信息,在循环过程中会不断积累梯度信息到tota_loss,占用内存
以上例子的修正方法是在循环中的最后一句修改为:total_loss+=float(loss),利用类型变换解除梯度信息,这样,多次累加不会累加梯度信息。
15. torch中tensor存至txt/mat
假设result1为tensor格式,首先将其化为array格式(注意只变成numpy还不行),之后存为txt和mat格式.
import scipy.io as io
result1 = np.array(result1)
np.savetxt('npresult1.txt',result1)
io.savemat('save.mat',{'result1':result1})