期末考试复习笔记(标红表示重要)
目录
相关系数的比较
数据的类型
回归模型的统计检验与统计意义
参数检验
非参数检验
统计距离
量表
李克特量表
权重
聚类图分析
聚类分析简介
聚类的用途
聚类方法
两步聚类法(TwoStep Cluster)
箱线图分析
中心位置的作用
伪相关
标准化的性质
受(不受)极端值影响的统计指标
数据分组是否会损失信息
平均数与中位数谁的信息量大
举例正(负)相关的变量
相关系数的比较
只是比较可不解释评判标准
| 皮尔逊积差相关系数 | 斯皮尔曼秩相关系数 | 肯德尔等级相关系数 | |
| 适用 | 两个连续变量间呈线性相关,使用Pearson积差相关系数 |
利用两变量的秩次大小作线性相关分析,对原始变量的分布不作要求,属于非参数统计方法,适用于两列变量,而且具有等级变量性质具有线性关系的资料、适用于计算两列登记数据或者不符合积差相关计算条件的两列数据之间的相关,比皮尔逊适用范围更广 | 适用于两个变量均为有序分类的情况,适用于k个评价者或一个评价者先后k次对n件事物进行等级评定的顺序数据,用于量化k个评价者之间的一致性 |
| 评判标准 | |r|≥0.8 为高度相关,0.5≤|r|<0.8为中度相关,0.3≤|r|<0.5为低度相关,|r|<为弱相关 | 肯德尔相关(和谐)系数的取值范围在-1到1之间,当τ为1时,表示两个随机变量拥有一致的等级相关性;当τ为-1时,表示两个随机变量拥有完全相反的等级相关性;当τ为0时,表示两个随机变量是相互独立的;肯德尔和谐系数:当评分者完全无序、不一致时,W=0。当评分者完全一致,W=1。W越接近1,评分者之间一致性越高。 |
注:
1若非等间距测度的连续变量 因为分布不明-可用等级相关/也可用Pearson 相关,对于完全等级离散变量必用等级相关
2当资料不服从双变量正态分布或总体分布型未知或原始数据是用等级表示时,宜用 Spearman 或 Kendall相关。
3 若不恰当用了Kendall 等级相关分析则可能得出相关系数偏小的结论。则若不恰当使用,可能得相关系数偏小或偏大结论而考察不到不同变量间存在的密切关系。对一般情况默认数据服从正态分布的,故用Pearson分析方法。
数据的类型
分类数据:按照现象的某种属性对其进行分类或分组而得到的数据。如,用1表示“男性”,0表示“女性”,但是1和0等只是数据的代码。
顺序数据:只能归于某一有序类别的非数字型数据。如表示受教育程度可以分为小学、初中、高中、大学及以上。
数值数据:包含了可以测量的,可以计数出来的数据。如表示一组青少年的身高体重。
截面数据:指在某一时点收集的不同对象的数据。横截面数据的突出特点就是离散性高。
时间序列数据:指对同一对象在不同时间连续观察所取得的数据。它着眼于研究对象在时间顺序上的变化,寻找空间(对象)历时发展的规律。
回归模型的统计检验与统计意义
参数检验
参数检验是在总体分布形式已知的情况下,对总体分布的参数如均值、方差等进行推断的方法
平均值检验:判断两个样本的均值是否相等
单样本T检验:判断单个样本数据的平均值与某个值的差异性
两独立样本的T检验:指两个样本之间彼此独立没有关联,两个独立样本各自接受相同的测量,主要目的是分析两个独立样本的均值是否有显著差异。自定义分组,莱文方差显著性<0.05,看不假定等方差,反之看假定等方差。
前提:独立性;正态性(样本量相差不大且样本量较大时仍可用T检验);方差齐性(待比较两样本方差相同,样本量大致相等时略微偏离方差齐性对检验结果精度影响不大)
过程:正态性检验-方差齐性检验-均值之差检验
H0: 总体均值之间不存在显著差异
-
利用F检验判断两总体的方差是否相同,SPSS采用Levene F方法检验两总体方差是否相同,当方差齐性不满足时,会提供方差齐性校正后的T检验结果
-
根据第一步的结果,决定T统计量和自由度,对T检验的结论做出判断两总体方差未知且相同
配对样本的T检验(非独立两样本的T检验):检验来自两配对总体的均值是否在统计上有显著差异。两组人数相同(数据组数相同),若不同考虑独立样本T检验引入分组变量。
配对设计(paired design)是将受试对象按某些重要特征相近的原则配成对子,每对中的两个个体随机地给予两种处理。
*
常见的配对设计*
- 同一个对象处理前后的变化
- 同一对象两个部位的数据
- 同一样本用两种方法测量的数据
- 配对的两个对象分别接受两种处理后的数据
前提
- 两个样本是配对的。即对象的年龄、性别、体重等非处理因素都相同或近似。两个样本的观察数目相同,观察值顺序不能随意
- 两个样本的总体服从正态分布,大样本情况下,T检验较为稳健
原理:
- 配对T检验时,首先求出每对观察值的差值,得到差值序列
- 然后对差值求均值
- 最后检验差值序列得到的均值,即平均差是否与零有显著差异,可以采用单样本T检验
- 若平均值和零有显著差异,则认为两总体均值间存在显著差异,反之不存在显著差异。
非参数检验
卡方检验:根据样本数据推断总体的分布与某个已知分布是否有显著差异 —吻合性检验,适用于具有明显分类特征的场景
二项分布检验:根据收集到的样本数据,推断总体分布是否服从某个指定的二项分布。其零假设是H0:样本来自的总体与所指定的某个二项分布不存在显著的差异。SPSS二项分布检验的数据是实际收集到的样本数据,而非频数数据。
游程检验:用于判断观察值的顺序是否随机。单样本变量值的随机性检验通过游程(Run)数来实现。所谓游程是样本序列中连续出现的变量值的次数。游程检验是最简单的判断随机性的方法。
单样本K-S检验:它是一个拟合优度检验,研究样本观察值的分布和设定的理论分布是否吻合,通过对两个分布差异的分析确定是否有理由认为样本的观察结果来自所假定的理论分布总体。
原理:K-S检验的基本思路是:先将顺序分类资料数据的理论累积频率分布与观测的经验累积频率分布加以比较,求出它们最大的偏离值,然后在给定的显著性水平上检验这种偏离值是否是偶然出现的。
两独立样本的检验:检验两个样本的分布是否相同。
多个独立样本的检验:用于在总体分布未知的情况下判断多个独立的样本是否来自相同分布的总体
两相关样本检验:在总体分布未知的条件下对样本来自的两相关配对总体是否具有显著差异进行的检验,可以判断两个相关的样本是否来自相同分布的总体
K个相关样本检验:用于在总体分布未知的情况下检验多个相关样本是否来自于相同分布的总体
统计距离
1)统计距离等于数学距离除以标准差
2)两点的统计距离公式
一维统计距离:点X1到X2的统计距离
d=|x1-x2| /s=数学距离/标准差
3)两个均值间的统计距离公式
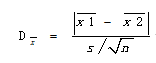
标准误差是平均数的标准差,用于度量均值间的数学距离。
4)统计距离用于衡量变量变化的统计意义,度量变化的显著性,一般经验值,统计距离大于2说明变化有显著的统计意义。
量表
定义:由一组问题构成的用于间接测量人们的态度、看法、意见和性格等主观性较强的内容的测量工具,实质上是一种特殊的调查问卷,它是一种具有结构强度顺序的复合测量,即全部陈述和项目都是按一定的结构顺序来安排,以反映出所测量的概念或态度具有的各种不同的程度。
李克特量表
李克特量表由美国心理学家李克特在原有的总加量表基础上改进而成的,也称累加量表,是最常用的定距量表,被广泛用于衡量观念、态度或意见,需要构造大量的陈述或说法,李克特量表的尺度形式有多种,常见是五级量表,即五个答项,如“非常同意”、“同意”、“说不准”、 “不同意”、“非常不同意”,另外还会有七级量表,九级量表或四级量表等。其范围从一个极端的态度到另一个极端,如“非常可能”到“根本不可能”。
适用:深入挖掘一个特定主体,详细地找出人们对这一主题的看法。所以,想获取更多信息的时候就可以适用李克特量表
了解群众对于防疫政策的看法
了解脱贫群众对扶贫干部的满意度情况
了解疫情之下民众的心理健康状况
大多数统计方法均只能针对量表使用,如信度分析,效度分析,探索性因子分析等,因此量表与只提供两个答案选项的二元问题相比,李克特式问题可以更精确地反馈出被调查者对该问题的态度,从而收集到更加准确的数据。
权重
因子分析求指标权重
一、导入数据
二、选择【分析】——【降维】——【因子分析】
三、导入变量
四、点击【描述】,勾选【KMO和巴特利特球形度检验】
KMO>0.8说明效度非常高;
KMO>0.7说明效度较好;
KMO>0.6说明效度可以接受;
KMO<0.6说明效度不太好;
KMO<0.5说明效度完全不佳,需要重新修正题项。
五、点击【抽取】,在选项里勾选【碎石图】
六、【旋转】中选择【最大方差法】
七、【得分】中选择【显示因子得分系数矩阵】
八、【选项】中选择【按大小排序】
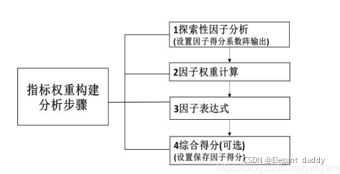
完成探索性因子分析提取因子功能,并且对研究量表进行信效度分析后,就是进行量表权重计算。指标权重构建通常包括四个步骤:因子提取、因子权重计算、因子表达式和综合得分计算等。
聚类图分析
聚类分析简介
按照个体的特征将它们分类,使同一类别内的个体具有尽可能高的同质性,而类别之间则具有尽可能高的异质性。【类内同质,类外异质】
只有采用适当的指标来定量描述研究对象之间的联系的紧密程度,才能得到合理的分类。
假定研究对象均用所谓的“点”来表示。在聚类分析中,一般的规则是将“距离”较小的点归为同一类,将“距离”较大的点归为不同的类。
常见的是对个体分类,也可以对变量分类,但对于变量分类此时一般使用相似系数作为“距离”测量指标【以皮尔逊相关系数为例,低度相关和若相关为一类,中度相关为一类,高度相关为一类】
聚类分析更像是一种建立假设的方法,而对相关假设的检验还需要借助其他统计方法,如判别分析、T-检验、方差分析等,看聚类出来的几个类别是否存在差异。
聚类的用途
- 设计抽样方案(分层抽样)
- 预分析过程(先通过聚类分析达到简化数据的目的,将众多的个体先聚集成比较好处理的几个类别或子集,然后再进行后续的多元分析)
- 细分市场、个体消费行为划分(先聚类,然后再利用判别分析进一步研究各个群体之间的差异)
聚类方法

K均值聚类(K-means Cluster)
方法原理
1.选择或人为指定某些记录作为凝聚点
2.按就近原则将其余记录向凝聚点凝集(此时会得到初始分类,1、2...类等。)
3.计算出各个初始分类的中心位置(均值)【类似分段,由分段均值再聚类】
4.用计算出的中心位置重新进行聚类
方法特点
1.要求已知类别数
2.可人为指定初始位置
3.节省运算时间
4.样本量过大时可考虑
5.只能使用连续性变量
层次聚类(Hierarchical Cluster)
层次聚类属于系统聚类法的一种,其聚类过程可以用树形结构(treelike structure)来描绘的方法。
方法原理
- 先将所有n个变量/观测看成不同的n类
- 然后将性质最接近(距离最近)的两类合并为一类【以皮尔逊系数为例,即高度相关的两类合并为一类】
- 再从这n-1类中找到最接近的两类加以合并
- 依此类推,直到所有的变量/观测被合为一类
- 使用者再根据具体的问题和聚类结果来决定应当分为几类
特点
- 一旦记录/变量被划定类别,其分类结果就不会再进行更改
- 可以对变量或记录进行聚类
- 变量可以为连续或分类变量(变量虽然可以为连续型或者分类型,但是不能混用,要不就是全分类这样使用,要不就全连续变量聚类)
- 提供的距离测量方法非常丰富
- 运算速度较慢
聚类过程 ,系数代表距离,距离什么含义,要看我们使用了什么距离指标。变量聚类一般默认距离为相关,即变量聚类时区间改为皮尔逊相关性(默认是平方欧氏距离)。一般聚类方法组间联接是最好的;ward法聚类出来会比较平均
度量标准
案例:平方欧式距离最好
变量-皮尔逊相关性最好
在系统聚类中,当每个类别有多于一个的数据点构成时,就会涉及如何定义两个类间的距离问题。根据距离公式不同,可能会得到不同的结果,这也就进一步构成了不同的系统聚类方法。常用的方法有如下几种:
Between-groups linkage(组间平均距离法):又称为类平均法,是用两个类别间各个数据点两两之间的距离的平均来表示两个类别之间的距离,这是SPSS默认的方法。(大量实践表明,该方法是一种非常优秀和稳健的方法,在多数情况下表现最为优异。)
Nearestneighbor(最短距离法):用两个类别中各数据点之间最短的那个距离来表示两个类别之间的距离。
Furthestneighbor(最远距离法):用两个类别中各数据点之间最远的那个距离来表示两个类别之间的距离.
Centroid clustering(重心法):用两个类别的重心之间的距离来表示两个类别之间的距离。
Ward’s method(离差平方和法):是要使得各类别中的离差平方和较小,而不同类别之间的离差平方和较大。使用该方法,将倾向于使得各个类别间的样本尽可能相近。
两步聚类法(TwoStep Cluster)
特点:
- 处理对象:离散变量和连续变量
- 自动决定最佳分类数
- 快速处理大数据集
前提假设:
- 变量间彼此独立
- 分类变量服从多项分布,连续变量服从正态分布(弱相关或服从类似正态分布也可,其会自动剔除异常值)

若以两条红色线划分则可划分为三类,加上黄线则可划分为四类,再加上蓝线则可划分为五类。
箱线图分析
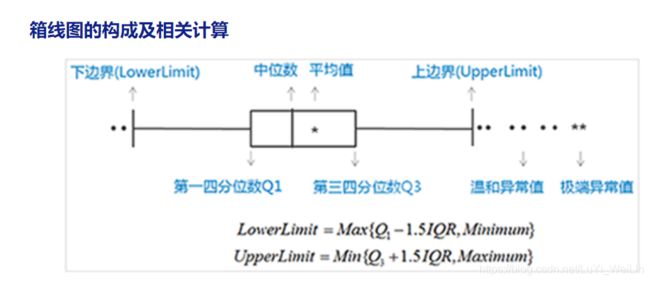
在箱图中,凡是与四分位数值(图中即为方框上下界)的距离超过1.5倍四分位间距的都会被定义为异常值,其中离方框上/下界的距离超过四分位数间距1.5倍的为离群值,在图中以“O”表示;超过3倍的则为极值,用“*”表示。散点旁边默认标出相应案例号备查。
箱型图最远处的边界为四分位数间距1.5倍

中心位置的作用
伪相关
伪相关现象(Spurious correlation),在实际应用中,当我们计算两个理论上完全没有任何关系的变量相关系数时,有时候得到的相关系数较大,而且经过统计经验是显著不为0的,统计上将这种现象称之为伪相关。伪相关又称为虚假关系(Artifact correlation),数学上高度相关,实际中没有统计意义的相关。
出现伪相关现象的原因一:伪相关现象是由于①变量之间都存在某种相同的变化趋势【变量完全不相关,但由于都是连续的增加导致了相关系数】,或者说存在着第三个变量将他们联系在一起,或有潜在变量的存在(潜在变量的影响)【即混淆因素,某变量同时影响了两个变量】,两个变量X,Y都受某个潜在变量Z的影响导致共同反应(common response)。两个经济变量之间的高度相关关系,有时并不是这两个经济变量本身的内在联系所决定的,它完全可能由另外一个变量的“媒介”作用而形成高度相关:忽略了“媒介”作用,理论上为负相关的变量可能得到正相关关系。
原因二:两个不平稳的时间序列之家的相关可能产生伪相关。伪相关导致伪回归。用协整的方法避免时间序列的伪相关。可用散点图识别极端值产生的伪相关。
原文链接:https://blog.csdn.net/weixin_45662626/article/details/107837860
标准化的性质
在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。数据无量纲化处理主要解决数据的可比性。
1.经标准化的各指标值都处于同一个数量级上,可以进行综合测评分析
2.若原始数据分布是正态分布,则标准化后一定是标准正态分布,反之,则不是标准正态分布,比如原始数据是均匀分布,标准化后仍是均匀分布,所以Z-score标准化不会改变原始数据的分布。
受(不受)极端值影响的统计指标
不受影响的
稳健统计量:
中位数:不受极端值影响
众数:不受极端值影响;当数据具有明显的集中趋势时,代表性好
四分位差:样本上、下四分位数之差称为四分位数(半极差),受极端值影响小
峰度:指的是频数分布曲线的高峰的形态,也就是反映曲线的尖削程度的测度。
偏度:反映频数分布偏态方向和程度的测度,正态分布偏度=0,均值大于中位数的称为右偏,也可以理解伪长尾在右侧。同理可知,负偏也叫左偏。如果数据是右偏分布,说明数据存在极大值,必然拉动平均数向极大值一方靠。 如果数据是左偏分布,说明数据存在极小值,必然拉动平均数向极小值一方靠。

易受影响的
平均数:容易受极端值影响
度量数据离散趋势的统计指标:方差、标准差、极差、平均差
变异系数:标准差与平均数之比,也称离散系数,衡量相对相对离中程度。
数据分组是否会损失信息
是的,数据分组会导致信息损失。简言之,三个原因:分组方法是否合理?数据是否是原始数据?两个变量在数字上的虚假相关是否符合常识?样本是否具有代表性?(样本有偏,不能简单推广)
例子:人口密度与经济发展水平,低收入和高收入国家分组;高收入国家组内人口密度;
这一例子揭示了统计分析中的两个常见现象,第一是分组数据往往能够提供更加平滑更加漂亮的中间数据,第二是在组内差异非常大的情况下,计算组内均值不仅是毫无意义的问题,还会导致错误结果。
首先,分组的基本依据是组内数据同质性,这一性质一般来说只能近似成立,许多场合下甚至只是研究者的个人判断。其次,在实际生活中使用的数据常常是分组之后的数据,而不是原始数据,如研究企业数据时,能够拿到的公开数据已经根据企业规模进行了分组处理,这样就损失了大量信息,甚至可能被误导;再次,两个变量在数字上的虚假相关可能与常识相悖;最后,样本可能不具有代表性,样本特征不能推广到总体。
第一,分组的基本依据是组内数据同质性。这个性质一般来说只能近似成立,许多场合下甚至只是研究者的个人判断。关注分组之后对于各种指标的组内同质性有助于我们避免一些错误。
第二,尽量使用原始数据而不是分组之后的数据。
第三,对分析对象和环境做更加全面的考察。
第四,注意样本的代表性。样本的特征能否随意推广到总体,这是一个基本问题。
参考:论数据分组的误导作用 - 豆丁网
平均数与中位数谁的信息量大
中位数的信息量大。
平均数是总体均值很好的估计,中位数是对总体中心很好的估计,如果数据是来自某对称未知分布时,估计均值和估计中心是等价的,这时候中位数的效率要比均值低不少。
1.平均数是通过计算得到的,因此它会因每一个数据的变化而变化。
2.中位数是通过排序得到,它不受最大、最小两个极端数值的影响,中位数在一定程度上综合了平均数与中位数的优点,具有比较好的代表性。
举例正(负)相关的变量
正相关: