Hierarchical Fine Extraction Method of Street Tree Information from Mobile LiDAR Point Cloud Data
Abstract
道路场景中行道树几何信息的分类和提取对于城市森林生物量统计和道路安全至关重要。为解决复杂道路场景中行道树的三维精细提取问题,设计并研究了一种基于高斯分布区域生长算法和Voronoi范围约束的道路场景车载LiDAR点云提取行道树几何和森林参数的方法。首先,应用多几何特征过滤掉大量非树木和其他噪声点,如地面点、建筑物、灌木和车辆点;然后,基于树的垂直线特征和基于高斯分布的区域生长算法提取行道树的主干;其次,建立Voronoi多边形约束,以主干质心分割单个树冠区域;最后,基于提取的行道树位置及其三维点,结合几何统计方法,获得单株树木生长参数,用于信息化管理和生物量估算。选取不同典型区域的车载LiDAR点云数据进行实验,验证提出的高斯分布区域生长算法能够实现不同类型行道树生长参数的精细分类和提取,准确率、召回率和F1值分别达到96.34%、97.22%和96.45%。该研究方法可用于复杂道路环境下行道树的三维精细分类提取,进而为城市环境下交通设施的安全管理和森林生物量估算提供支持。
Keywords: 移动激光扫描;树木普查;区域性增长;高斯分布;点云分割
1. Introduction
智能交通无人自主驾驶迫切需要高精度导航地图,通过遥测获取复杂道路场景下特征目标的位置和细节信息是实现精确定位和导航的重要支撑。在交通管理中,道路场景中树木的三维几何、地形和语义信息对于精细车道导航、交通事故分析和车辆安全评估具有一定的参考价值。出于构建高精度导航地图和智能交通管理的需要,快速准确地提取驾驶环境中的相关特征是当前“智慧城市”建设的研究热点。但在数据源层面,像树木这种上下几何特征差异较大的目标,无法通过破译传统的单2D影像精细提取,而目前主流的树木识别提取方法使用3D LiDAR(光探测与测距)作为数据源。激光雷达技术凭借其快速、实时获取周围环境信息的能力,逐渐成为对地观测和目标分类识别的重要数据源之一。激光雷达是一种高精度的传感器,用于测量物体的位置和形状,形成高质量的三维点云图像[1,2],近年来被广泛应用于自动驾驶[3–5],三维建模[6–9],生成高精度地图[10,11],树木生物量估算[12,13]等领域。
行道树提取根据LiDAR数据源的不同分为机载LiDAR和地基LiDAR(包括车载、背包和基站类型)。机载激光雷达点云的特点是采集速度快,地理覆盖范围大;因此,机载激光雷达主要用于树木信息提取和生物量估计,在保留单个树冠范围的同时降低数据成本,并有助于简化树木种群统计数据提取和生物量估计。地基激光雷达点云可以在各个方向上以高精度捕捉树木的几何信息,便于提取单个树木的显著特征,以获得准确的树木参数,用于道路环境精细化管理和蓄积量估计。
目前,基于LiDAR点云数据的树木分类提取包括树干提取和树冠提取两部分。
(1) 树干提取方法可以分为:基于模型的提取方法、基于结构特征的提取方法和基于知识模板匹配的提取方法。
1)基于模型的提取方法:树干呈现圆柱状几何形状。Liang等[14,15]和Cabo等[16]应用3D圆柱模型提取树干; Lehtomaki 等人 [17] 应用不同尺寸半径的同轴圆柱体来适应躯干; Li等[18]采用自适应半径圆柱模型自下而上拟合躯干; Raumonen 等人 [19] 和 Hackenberg 等人 [20] 使用柱状曲面拟合方法;并且还有许多方法应用基于垂直度的 RANSAC(随机样本一致性)线性拟合模型 [21-23]。然而,这种拟合树干的方法受树干点的密度和几何形状的强烈影响,当树干被其他类型的特征点(例如灌木)遮挡或树干被遮挡时,常规模型拟合方法无法完全提取树干。在很大程度上倾斜。
2)基于结构特征的提取方法:树干具有杆状特征,垂直度、密度和连续性高。许多研究已经使用聚类和分割方法来提取基于结构特征的树干。 Lehtomaki 等人 [24] 结合树高、位置和点数的先验知识来聚类和分离树干; Archige 等人 [25] 使用躯干方向和几何信息来分割躯干; Xia等[26]采用多尺度形状和尺寸几何特征实现提取; Tao 等人 [27] 应用 DBSCAN(基于密度的噪声应用空间聚类)按密度区分树干; Hao 等人 [28] 在 z 方向上以分层方式提取点与质心的水平偏差; Wu 等人 [29] 在一定高度范围内搜索上下体素,以实现元音化的躯干提取。 Thanh 等人 [30] 使用水平剖面分析和最小垂直高度标准提取应用主干点,Tang 等人 [31] 应用欧氏距离聚类和最小切割提取。结构特征的计算依赖于邻域点的稀疏性并受噪声点的影响,基于结构特征的提取方法对于小目标树干和不完整的不规则树干提取精度较低。 Hui等[32]提出了一种基于物体图元空间几何特征的行道树提取和分割方法,应用邻域点间的法向量夹角阈值将原始点云划分为不同的图元,通过线性变换提取树干点图元之间的特征和图元边界框的纵横比,可以提高茎检测的鲁棒性和准确性,但对于一些不规则的茎,例如严重弯曲的树干的检测,茎检测的完整性性能还有提升空间点。
3)基于知识模板匹配的提取方法:知识模板是特征的组合,不同特征值的阈值组合可以提取不同的特征,根据树干与其他特征目标的组合特征差异来分离树干。 Pu等[33]实现了基于知识特征识别的特征分类,超体素是一种特征融合方法; Wu [29] 等人和 Fan [34] 等人在分割过程中,应用了树干的特征超体素; Li [21,35] 结合先验知识、极点提取和成分分离来区分树木和其他特征; Wang 等人 [36] 应用超体素邻域的 Hough 森林来检测包括树干在内的杆状特征。体素化通常应用于模板匹配方法,但体素化大小的选择对提取结果至关重要。而且这种方法需要大量的先验知识,处理过程比较费时。
(2) 单个树冠点云的获取分为分类和提取两个方面。
1)树冠分类方法:树木的树冠层是区别于其他特征的显着部分,在机器学习分类方法的应用中具有明显不同于其他特征的特征。 Huang等[37]采用欧式聚类对点云进行粗处理,然后应用SVM提取单树; Huang和You [38]使用统计极点描述来符合SVM对不同极点特征(包括树木、路灯、广告牌等)的应用; Wu et al [39] 使用超体素处理,然后应用 SVM 和随机森林处理分别对不同的极点特征进行分类,以及应用 3D 卷积神经网络进行大视场点云分类 [40]。机器学习方法需要大量的人工标注和训练,适用于大场景下的目标分类,针对特定特征时耗时长且提取精度低,且提取精度依赖于样本。
2)树冠提取方法:树冠点云由从树干延伸的树叶和树枝的随意集合组成,用于提取的规则特征较少。目前的树冠提取依赖于树干的位置和几何形状特征,通过区域生长算法和聚类将树冠点归属于指定的树干。 Weinman 等人 [41] 设计了一种平均漂移聚类和形状分析方法来提取路冠点; Xu et al [42]使用自下而上的层次聚类方法; Yadav 等人 [43] 和 Xu 等人 [44] 将树冠点归因于树的顶点。
区域增长算法是最常用的通过树干点提取树冠点的方法。该算法在树提取中的应用涉及两个主要方面的创新:种子点的选择和生长路径(生长约束)的选择。首先是根据局部高程差异和密度选择种子点[45],根据树干靠近冠层水平中心且直径小于冠层的标准选择种子点[46] ,以及使用超体素重心的平面坐标作为生长的种子点 [34]。其次,对于生长路径的选择,研究者设计了竞争区域生长[29]、广度优先搜索算法[34]和对偶生长方法[46],解决冠层间接触或重叠问题,区域生长算法结合 Dijkstra 方法 [47,48] 和 Voronoi 约束 [49-51] 实现单树分割。但树木的形状和大小、树木与激光雷达的距离导致树冠密度分布不均匀以及树干被汽车和绿化带遮挡时树干点缺失,很容易导致种子点位置的不正确选择或面积增长过程中的不完全增长,仍然是改进的瓶颈。
综上所述,上述行道树提取方法存在以下不足:
-
树干的提取依赖于更规则的几何特征,如果树干的某些部分弯曲或严重模糊,则准确性较低;
-
树冠提取的结果很大程度上取决于树干的位置,当树干严重遮挡时无法提取;
-
当树冠与树干之间或树冠与树冠之间存在较大间隙时,不能应用区域生长算法提取树冠层;
-
树木几何参数的信息化是林业调查和三维应用的关键,目前缺乏对树木参数进行细粒度分析的方法。
针对上述现有方法中树干和树冠点密度分布不均匀的问题,提出一种基于高斯分布的移动LiDAR点云和区域生长算法提取道路环境中的树干和树冠,并结合Voronoi (Tyson polygon)约束分割实现重叠单木的自动分割,实现单木的三维精细信息和几何参数提取。
本文的其余部分组织如下:第2节说明了方法,第3节报告了实验领域和结果,第4节报告了讨论。最后,第5节给出了工作的结论。
2. Materials and Methods
2.1. Technical Process
基于移动LiDAR点云数据,设计了一种基于高斯分布的区域生长算法来提取道路环境中的行道树点云。首先,对原始移动LiDAR点云数据进行预处理,包括地面点滤波和基于建筑物立面投影面积的建筑物点云滤波;然后,基于树干的垂直线特征定位单棵树的位置,并基于GDRG算法聚类提取树干点云;其次,基于树干的简单几何规则去除伪树干;然后,再次应用GDRG算法分别提取每棵树的树冠点云。最后,使用Voronoi图约束来划分树组并计算单个树的几何特征。该方法的详细技术流程如图1所示。

图 1. 从移动 LiDAR 数据中提取街道树的流程图。
2.2. Non-Tree Points Filtering Pre-Processing
原始点云采用基于坡度的过滤算法进行过滤,候选点T0主要是道路两侧的基础设施目标点云,其中建筑物立面点和部分灌木点也干扰了树干点云的提取。根据建筑立面、车辆和灌木在投影几何尺度上的差异,对建筑立面、车辆、灌木点和树木点等非树木点集进行区分和过滤。
候选点T0是应用欧式距离聚类算法对相对高程阈值h(本文采用1.5 m,h为范围值,约等于标准树高度的1/2左右)进行聚类得到的研究区域,主要用于将部分躯干与树冠分开,以便后续投影)。每个聚类被分层为每个聚类聚类的上部和下部。
聚类的整体和下部在水平面上进行光栅投影,每个聚类包含点云的像素数为整体光栅投影 N 1 N_{1} N1,下部光栅投影 N 2 N_{2} N2,包围区域矩形为 S S S。建筑物、树木和灌木的整体和下部投影如图2所示。

图 2. 不同地物的投影差异(黄色边框代表簇的外矩形)。
a.计算面积差 B 1 B_{1} B1。计算公式如(1)所示。
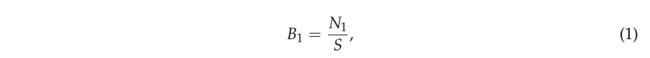
在候选点T0中,建筑物的投影是条状的,外侧矩形内的空栅格占多数,面积差接近0;其他基础设施如树木的投影是圆形的,外侧矩形内没有空栅格,面积差接近1。计算所有投影单元的面积差 k 1 k_1 k1的平均值,然后消除面积差小于 k 1 k_1 k1的投影单元,这样就可以删除建筑点。
b. 比例计算 B 2 B_2 B2.计算公式如(2)所示。
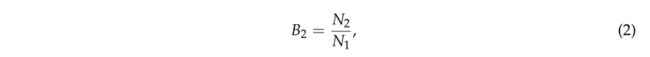
车辆与灌木的比值 B 2 B_2 B2接近1;当树木比例 B 2 B_2 B2接近0时,计算所有投影单元的比例因子k2的平均值,剔除比例因子大于 k 2 k_2 k2的投影像元,即可去除灌木点和车辆点。
去除部分噪声簇后,得到候选点 T 1 T 1 T1。
2.3. Regional Growth Algorithm for Gaussian Distribution (GDRG) to Extract Trunks
候选点 T 1 T 1 T1处行道树的树干部分具有很强的垂直几何特性,可用于提取部分树干点云,定位树干位置。垂直度特征值是通过全局点云的主成分分析 (PCA) [52,53] 和特征值的解来计算的,其计算如下 (3)。
![]()
线性表示0~1范围内各点的垂直特征值; λ1 和 λ2 (λ1 > λ2) 分别是第一和第二特征值。
候选点集包括大量的树木和一些包含路灯、广告牌等杆件的点云。计算垂直线性特征可以提取不同基础设施的极点部分,过滤点云集中不具有垂直特征的部分(如汽车和树冠)。点云的垂直度是根据每个点的邻域点计算的,然后一些点被错误地表示为垂直,例如树冠中的点具有不规则性,并且计算了一些点的垂直特征值以满足阈值,或者树干中的某些点缺乏从同一树干中提取,因为它们被遮挡并且受到未达到阈值的邻域噪声点的影响。
垂直度后提取候选点集T1,得到基础设施点云极部缺失点的点集,提取不完整的主干点集。
本节提出了一种从原始点云数据中提取的点集中寻找缺失杆点的方法,即基于高斯分布的区域生长算法(GDRG)。将提取的点作为种子点,通过高斯分布规律在原始点云中寻找符合规则的点,对生长点进行聚类,合并为一个主干点集。
GDRG算法是一种区间估计方法,关注样本点集合中高斯分布置信区间内的点作为生长的候选种子。高斯分布的置信区间估计涉及创建一个区间,其中包含要在给定概率值下为样本正态分布估计的参数。这个置信区间 [a, b] 是从可能包含总体参数的样本中导出的值的区间,通常通过从样本统计量中加上或减去估计误差来获得。置信区间 a 和 b 的下限和上限在 (4) 中计算。
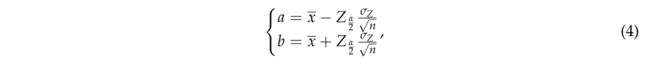
其中 x ˉ \bar{x} xˉ 表示估计参数的平均值; Z a / 2 Z_{a / 2} Za/2表示置信水平为a的正态分布Z值表中的值; n 表示样本数; σ Z \sigma_Z σZ表示样本的标准差,反映了整个样本与样本均值的离散程度; σ Z n \frac{\sigma_{\mathrm{Z}}}{\sqrt{n}} nσZ为样本的标准误差。
种子点是从树干点中选取的,并在邻域中搜索。以搜索到的点集作为样本,样本点与种子点在x和y方向上的差值分别为Δx和Δy,作为区间估计的参数。主干点集分布稳健,可能主干点和种子点参数误差在高斯分布的置信区间内,而离群点误差较大不在置信区间内,置信区间内的点为添加到生长点集。 GDRG算法如图3所示,算法集伪代码见表1。
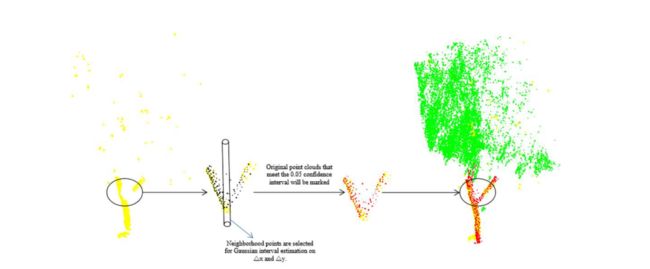
图 3.基于高斯分布的区域生长算法(黄色点代表垂直特征提取的部分树干点,黑色点代表原始数据中的点,红色点代表高斯分布算法生长的树点,绿色点为树冠点)。
表 1. GDRG 的算法表。

根据黄色的点(长出来的点)找出黑色的邻域点(待判断的点)。随机选取一个黄色点作为初始种子点,寻找20个最近邻点,计算邻域点与种子点在x、y方向的距离差,然后计算差值的高斯分布,设成立置信水平为 0.05 置信区间。将满足这个置信区间的点添加到红色点集中,将剩余邻域点集中的下一个最近点作为新的种子点重复生长。当没有要添加的新点或所有要添加的剩余点都不符合置信区间时,算法将终止。
结束生长的点集合P是第一个树干的聚类点集合;在候选点集中重新选取未被生长标记的新的初始种子点,重复该算法得到接下来N个树干的聚类点集合,即中的N个树干的聚类点集合候选点集 T2。
提取的点集经过GDRG算法处理得到候选点集T2。候选点集T2补充了各种杆点集的聚类,但由于冠层点云的不规则生长,仍然存在伪杆点集聚类。
2.4. Single Tree Segmentation Method with Voronoi Range Constraint
2.4.1. Canopy Group Extraction
杆簇在原始点云中标记,冠层点集使用杆点集 T2 作为种子点再次应用 RG(区域生长)算法和优化种子点方法(图 4)。 RG算法做了三处改进:
(1) 由于部分树冠与树干顶点的距离较远,RG算法对树冠的邻域搜索采用最近邻法,以树干顶点为初始点进行生长搜索。
(2) 为防止种子点从树干顶点向下生长到噪声点,初始种子点的下一个冠层候选高度应大于初始种子点高度 h c h_c hc。
(3) 由于部分树冠之间存在较大空隙,因此在初始种子点的下一个树冠候选点的选择中加入了垂直约束,即树干顶点的下一批种子点为最近邻以顶点为圆心,水平半径为R,高度大于 h c h_c hc的圆柱范围内的顶点。

图 4.优化种子点法的 RG 算法种子点,圆柱体上的箭头代表候选点后续的生长方向)。
2.4.2. Pseudo-trunk Identification
上面 2.3 节中提取的树干有部分伪树干点集。考虑到研究区域中可能存在过于模糊的树干,无法提取正确的树干并长出树冠,伪极部分和伪树干点在通过伪极长出完整的树冠后识别树木。
伪树干是通过应用树冠到树干匹配的方法来识别的。每个成熟的树冠簇都有 N 个树干。对每个冠层中的伪树干点集合应用最小包围盒计算几何特征,并对不同特征设置几何规则阈值,剔除不满足阈值条件的伪树干点集合。几何规则包括: (1) Volume V,计算每组杆簇点的矩形最小包围盒的体积;该规则适用于路灯和广告牌的识别。(2) 高差 h d h_d hd,聚类簇杆部围框最低点到最高点的高差;该规则适用于部分噪声点的识别。 (3) Groundedness h g h_g hg,计算每个区域的平均DEM和聚类簇的最小包围盒最低点之间的高程差。排除大于阈值的伪簇簇,该规则对树冠伪树干的识别有效。
通过以上三个规则过滤后识别出符合条件的杆簇,并将正确的树干匹配到相应的树冠上。如果树冠没有匹配的树干,则树的树干点严重缺失;如果一个树冠簇有多个树干,冠层区域可能与树组重叠,是后续单木分割的重点。
2.4.3. Single Tree Segmentation Method with Voronoi Range Constraint
实验区内存在阵列间重叠情况,树木靠得很近或树冠生长方向相反,相互重叠遮荫,导致该区域生长后多棵树聚为一类。为了划分单棵树,本文应用 Voronoi 图(泰森多边形)[52]来解决多棵树相互重叠的问题。
每个树干簇的 3D 重力的解决方案用于表示每棵树的真实位置,并且重力显示为 3D 点。由于候选点中树点集合上方没有噪声点,并且每棵树的高度不一样,导致每个素数的坐标高度不一致。本节方法的主要目的是分割重叠的树群,如果用重力坐标创建3D Voronoi图,可能会导致不同树冠的过度分割,所以重力是2D投影的。二维Voronoi图根据n个引力在欧氏平面上的位置,自动将平面划分为以引力为中心的n个多边形区域,多边形互不重叠且相邻。
2D质心投影后,对同一高度的2D质心点创建Voronoi图,确定单棵树所属平面的范围,然后将所有具有高度信息的冠层点在获得飞机。如图5所示,以实验区树干质心点建立Voronoi图区间分区。
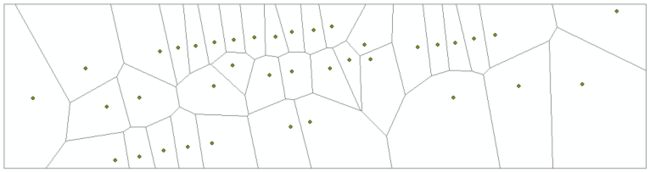
图 5.Voronoi图对重叠树的分割(黑色点代表树干质心点的平面投影)
在通过噪声点过滤过程过滤候选点之后,消除树冠范围内的灌木点,并且用Voronoi图区域创建的每个多边形缓冲区中的候选点仅包含树点。分别提取每个缓冲区中的候选点,实现单棵树的自动分割,得到单棵树点簇T3。
2.5. Calculation of Tree Geometry Parameters
(1)行道树位置。在2.4.3节中,求解了树干质心在XOY平面上的投影坐标,以表示行道树的位置。
(2) 胸径尺寸。躯干簇在 XOY 平面上投影后的栅格单元直径即为胸径尺寸。
(3) 躯干高度。树干簇顶点的高度就是树干的高度。
(4) 树冠宽度。将提取出的树冠投影到XOY平面上近似为圆形,通过圆的面积公式计算出的直径即为每棵树的树冠宽度。
(5) 树高。树冠顶点的高度。
3. Results
3.1. Data Sources and Threshold Parameters
本文的实验区域是来自2021年第七届全国LiDAR大会数据处理大赛竞赛数据的车载LiDAR城市环境数据,是SSW-2车载激光扫描仪激光点云获取的河南工业大学测绘学院和土木工程学院周边的道路场景,特征包括地面、行道树、建筑物、绿化带、公共基础设施、行人等。其中,有独立的行道树,有相连的行道树,也有行道树与路灯等交叉现象;因为少量的行道树点云由于遮挡等原因,会有一些缺失。
由于存在不同的树种,本研究根据三种树木在当前实验区的分布情况(包括小杨树、大杨树和柳树),将实验区分为三个部分(图6)。实验区S1和S2以小杨树为主,有少量大杨树,而实验区S3主要是柳树和大杨树。三个树种的几何特征各不相同,小杨树具有与道路环境中常见树木相同的特征,表现为形状规则的树干,树冠较密;大杨树与小杨树的不同之处在于,树冠具有更多的枝叶,但叶片之间的间隙更大,就点云的形态而言,树冠远不如小杨树密集;与其他物种的生长方向相反,柳树有下垂的树冠,与其他物种相反,柳树树冠下垂,并显示出向下延伸的趋势,点云模式显示树枝从树顶垂直向下延伸,遮挡了树干的一部分。
三个实验区的点云数据和不同树种的表示见图6,实验区数据的统计信息见表2。
表 2. 点云数据信息统计结果。

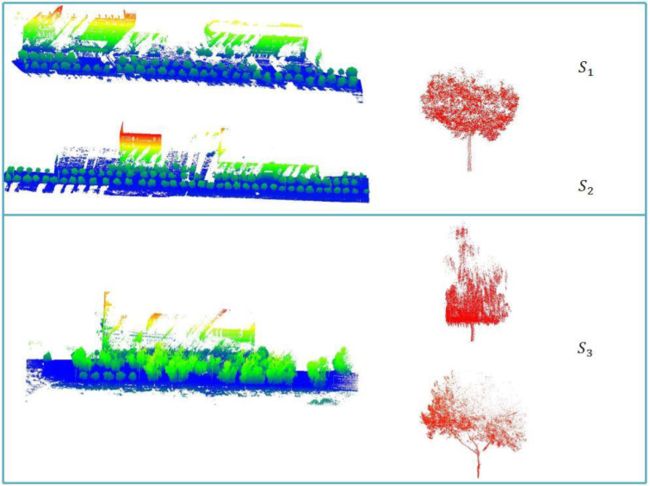
图 6.研究区概况:左为三个研究区示意图,右为各研究区主要树种(研究区S1和S2中树种为小杨树)树;S3 是柳树和大杨树)。
本文主要算法的参数阈值统计如表3所示,线性特征线性度阈值大于0.8。
表 3. 算法参数阈值设置。

3.2. Experimental Results
三个研究区域的过滤预处理结果如图 6 所示(S1、S3 和 S2 分别在图 6 中逆时针显示)。在较平坦的校区,坡度滤波对去除地面点非常有效,本研究建立的去除建筑物、车辆、行人等噪声点的规则也具有一定的适用性,包括面积差B1和尺度两个指标计算 B2。从图 7 中可以看出,具有更符合建筑物、灌木和车辆特征的聚类的点云已被删除。但是还有一些点没有被去除,比如图7中蓝色圆圈中建筑物的残留点。由于对建筑物整体扫描不完整,一些小的建筑物部分从整体中分离出来应用欧几里得聚类后聚类,这样的小部分满足过滤器预处理的规则,在这一步不被淘汰。
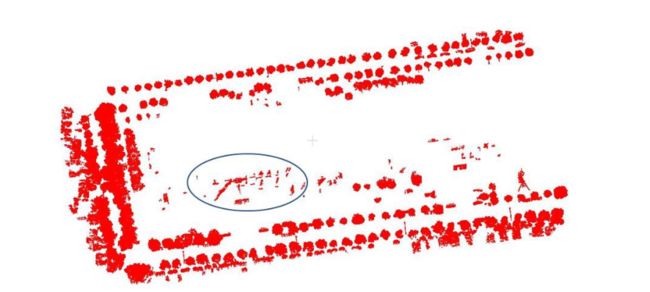
图 7.过滤和预处理结果(蓝色圆圈中的建筑物残留物)。
滤波预处理留下的非树点包括一些与树干紧密相连的建筑物点和自行车点等。建筑点没有被排除在面积差投影过滤B1中,因为顶表面具有投影宽度。靠近树的自行车点与树干在同一个聚类中,并且因为满足阈值条件而保留在比例计算过滤B2中。
在基于GDRG算法的垂直线提取(线性)过程和主干点提取过程之后获得的结果如图8所示。过滤预处理留下的建筑点通过垂直线性提取过程进一步简化,保留了门、窗、柱等更清晰表达的构件。采用垂直线提取法提取树干附近的自行车,去除与树干点的连接,只保留少量自行车点。

图 8. 基于GDRG算法的树干提取
GDRG算法随后被设计为使用具有垂直线特性的点作为初始种子点,从原始数据中提取完整的杆点集,而主干点集占杆点集的大部分。GDRG算法适用于各种不规则主干,区域生长的算法比之前提出的基于类圆柱模型的拟合方法更适合不规则聚类的提取,因为区域生长采用了邻域点规划的思想,将符合条件的点标记为同一类,同时也考虑了邻域点过拟合的情况。因此,本文在区域生长算法中加入了邻域点高斯分布的约束。GDRG算法以初始种子点为参考点,通过将后续候选种子点的邻域点加入初始种子点集合,并进行高斯分布置信区间(α = 0.05)判断,不断剔除不合格点,从而得到最终的鲁棒主干点集合。此外,当一些树冠点被添加到初始种子点集合中并且在x和y方向上执行高斯分布判断时,不满足阈值间隔的树冠点将被消除。同时,从垂直线特征中提取的种子点不包含树冠点,因此GDRG算法可以考虑过拟合问题,提取完整的候选树干集。
由于并非所有具有垂直线性特征的点都是主干点,例如图9中的三种情况,所以图9a中的路灯杆具有垂直特征,并且在应用GDRG算法之后提取了完整的路灯;对于图9b中的建筑物的剩余点,在应用相同的面积增长之后,一些门柱符合特征规则并且一些门窗轮廓点被提取;图9c的情况存在于S3,那里柳树的垂直特征明显,提取的簇多于树干,聚集在树干周围,容易干扰树干的正确识别。因此,本文设计了一种消除伪主干的方法,主干点分布结果如图10所示。在几何规则的约束下,包括体积V、高度差hd和可接地性hg,识别并消除了伪树干,但一些簇更接近地面且尺寸更大,导致一棵树具有多个树干。

图 9. 提取伪树干。

图 10. 研究区域的树干提取结果。
基于伪树干顶点生长树冠并识别伪树结果(单棵树提取结果)的结果如图11所示。具有优化种子点的RG算法用于提取主干点之间具有大间隙的树。使用最近邻、垂直约束和高度约束来寻找种子点将避免区域生长算法的一个缺陷,即种子点沿着导致死循环或不完全生长的生长方向前进,以确保整个生长方向沿着主干位置从下向上级联,并减少朝向相邻树生长的机会。

图 11. 单树提取结果。
提取冠层组后,研究区内仍有许多重叠的冠层。图12显示了通过生成带有树干质量的V oronoi图来自动划分部分重叠树木范围的结果。尽管重叠的树之间的一些点的属性是有争议的,但是自动分割远远优于分割的人工视觉解释。

图 12. Voronoi图约束下的单木分割结果。(a)表示未分割的树点,(b)表示Voronoi图分割后用不同颜色表示的单棵树结果。
本文中的方法对三个数据集进行实验,基于原始移动LiDAR数据,以人工视觉检查分离的单棵树作为真实参考数据,同时选择三个度量标准,Pre准确度、Rec召回率和F1分数,以定量评估树提取实验的结果,这些结果在等式(5)至(7)中计算。
![]()

TP表示从研究区域提取的单棵树数量的真实值;FP表示通过本文的算法从研究区域提取的非树木的数量;FN表示本文中的算法未能从研究区域中提取的单棵树的数量。用本文方法从三个研究区提取单木的结果见图11,定量评价结果见表4。
表 4. 实验结果的精度评估。

4. Discussion
4.1. Comparative Analysis
为了客观地评估我们的方法在2021年第七届全国LiDAR会议数据处理竞赛数据中分割单个行道树的性能,选择了Hui等人[32]的最新验证方法进行比较分析,他们使用了与本文相同的实验区域。惠等人提出了一种基于对象图元空间几何特征的行道树提取与分割方法,该方法应用邻域点间的法向量角度阈值将原始点云划分为不同的图元,通过图元间的线特征和图元包围盒的长宽比提取主干点,并提出了一种体素最短路径分析方法来获得单棵树的优化分离结果。Hui等人的方法分别使用提取率、匹配率、委托误差、遗漏误差和F1值五个度量来评价单棵树分割结果的准确性,与本文的准确性评价度量略有不同。其中匹配率与本文中的召回率相同,F1分数与F1分数相同,准确度Pre等于1减去佣金误差。表5显示了Hui等人的方法准确度转换评估的结果以及与我们的方法的比较。
表 5. 精度评估结果的比较。

从表 4 可以看出,两种提取单树的方法在召回率上的差异并不显着,而我们的方法的准确率远大于 Hui 等人的方法表明这两种方法都提供了更完整的提取实验区的行道树,但我们的方法的优点是较少将其他非树点识别为单树。由于Hui等人的方法提出的原始连通性,提取了一些与树点相连的非树点,进而影响了提取的准确性。此外,实验区S3内垂柳较多,这些贴近地面的柳枝常被误认为树枝,从而增加了错误提取行树的数量[32],导致采用Hui 等人 相比之下,我们提出了一种伪树干识别方法,通过将候选树干簇与垂饰区分开来的几何特征和基础性,提高了 S3 中柳树提取的准确性。此外,在不规则树干(树干)点提取的完整性方面,Hui等人通过图元之间的线性特征和图元边界框的纵横比提取树干点的方法适用于倾斜树干提取。然而,实验区S3中存在树干部分弯曲的柳树,Hui等人的方法只能提取部分树干点,而其余树干点在树点规划时被规划成完整的单树。随后基于原始连接提取,但我们的 GDRG 算法在主干提取的完整性方面仍然优于 Hui 等人的方法。
4.2. Causes of Tree Errors and Missing Extractions
- 树木过于靠近建筑物。这类FN误差主要出现在S1和S3中,如图13(每个蓝圈五棵树),当树冠离建筑物太近时,欧式距离聚类在滤波预处理中的应用步骤将导致树木和建筑物合并为一个簇,并在下一步的投影规则处理中进行过滤。由于树木离建筑物太近,S1 和 S3 中错过的树木数量分别为 10 和 6。从图11可以看出,如果树木在忽略建筑物的影响后表现为重叠组,则GDRG算法后续提取单棵树的树干将被正确提取并得到显着改善。研究区S1和S3的召回率分别提高了约10.87%和11.76%。

图 13. 建筑物附近树木的精度误差。
过滤预处理步骤是树提取之前的二次算法,本文的关键算法是在后续的提取中,因此如果替换部分预处理过程或增加一定的规则约束可以解决此类问题。解决预处理问题后研究区S1的提取精度明显提高,说明本文算法对S1中具有形状和分布规律的树木提取结果具有较高的适用性。
2)树相关部分的错误提取。在研究区域 S1 和 S2 中,连接到树的部分基础设施被识别为提取的相同集群。图 14a 中所示的路灯杆未被识别为伪树干,因为它被部分遮挡并且部分杆在树内,因此通过应用 GDRG 算法在树冠生长时同时提取悬垂杆。如图 14b 所示,广告牌的顶部连接到树冠,广告牌杆的小尺寸被识别为伪树干,广告牌部分的树冠生长导致错误提取。

图 14. 基础设施点的错误提取。
- 主干点没有提取,因为它们不重要。 S2 中未提取的树木是由于树干点数量较少,因为这些树的树干未通过应用 GDRG 算法提取,或者树干簇的体积未达到被识别为路灯的阈值伪极识别中的极点被拒绝;因此,不可能在树干的基础上种植树冠,从而导致提取缺失。
另一种无法提取和分割单棵树的情况出现在S3中,其中图15a所示的五棵树(用不同颜色表示)经过算法处理得到图15b所示的三棵分割不充分的树(红框表示不同)分割结果)。蓝色和黄色树的过度生长问题是由于红色和绿色树干与线性特征匹配的点较少,因此被伪树干识别所消除。一旦其他三棵树长大,用于 Voronoi 约束的单树分割需要五个树干质心,但实际计算结果只有三个树干质心,并且用三个树干质心创建的三个 Voronoi 图范围错误地分割了五棵树。

图 15. 分割结果下的柳树。
4.3. Comparative Advantages of Our Extraction Method
1)面向躯干弯曲的问题。本文研究区域内存在许多形状不规则的树干,由于车载激光雷达沿道路扫描无法获得完整的树干背面点,导致部分树干在其水平投影中呈现圆形。基于模型的提取方法,例如梁等人[14,15]和等人[16]使用3D圆柱模型提取树干所采用的方法,会受到树干点的密度和几何形状的影响,这些方法将无法应用于本文研究区域中弯曲树干的提取。图16显示了研究区域内的一棵柳树,其树干形状不规则。当弯曲树干点的距离阈值大于拟合半径时,从该点开始的所有树干点都不能被提取,但是本文中的算法仍然可以提取整个树干。与模型拟合方法相反,虽然不规则主干点不能通过仅应用单一特征提取方法(例如,本文中的垂直线特征)来提取,但是提取的特征点可以用于定位主干点,并且剩余的主干点可以通过应用GDRG算法以使用特征主干点作为种子点来提取。同时,高斯分布规则防止了从原始数据中错误提取冠点树。在主干点和冠点之间的临界区域,虽然在主干点的邻域中存在一些冠点,但是这些冠点不在高斯分布的置信区间内,从而避免了种子点在冠点的方向上生长。

图 16. 树干弯曲的结果(红点代表通过我们的方法提取的树干点)。
2)面向低冠层点密度的问题。以图 17 中的白杨树为例,Yue 等人[46]根据局部高差和密度选择种子点的方法只能提取一些距离顶点较近的树冠点由于大多数树冠点和树干点之间的间距很大,树干的;李等[47]根据树干靠近树冠水平中心且直径小于树冠的标准选取种子点,但杨树因树冠点缺失或分布不规则而无法提取树干点. Li等[47]选择种子点的依据是树干靠近树冠水平中心且直径小于树冠,但杨树因树冠点缺失或分布不规则导致中心偏移较大,在这种情况下,李等人的方法无法提取树干点。

图 17. 具有大冠层间隙的树木的提取结果。
本文采用提取的树干顶点作为初始点优化种子点的RG算法可以解决大部分大冠层间隙问题。
3)面向严重的主干点缺失问题。当树干点严重缺失时,无法应用树干点的显着特征,因此上述三种提取树干点的方法都无法提取树干和树冠点。本文方法主要解决杨树树干点缺失的提取问题,提取结果见图18(红框内的点为非树干树的提取结果)。部分顶部树干点隐藏在树冠中,在树冠提取步骤中基于树干顶部点通过应用具有优化种子点的GDRG算法提取树干。然而,在伪极点识别中拒绝了树干点,导致部分树冠与树干不匹配,但 S3 中的柳树树干大部分隐藏在簇和树冠中,提取的树干点被识别为伪树干由于不符合体积和高度规则,柳树重叠导致多棵柳树共享同一树干,因此遗漏柳树树干点的问题一直没有解决。

图 18. 无树干杨树的提取结果。
4.4. Error Analysis of T ree Parameter Extraction
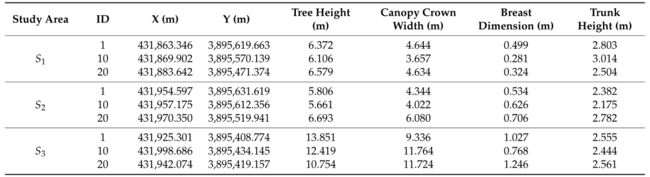
本文统计了研究区树木的四个参数:树心位置、树高、树冠宽度、胸径和树干高度。表6为分别截取的编号为1、10、20的三个实验块所代表的树的参数信息
表 6. 树木几何参数统计表
在本文中,我们只对树木的位置进行误差分析,因为实验区树木的几何形状并不完全规则,容易导致参数整体误差较大。树干高度和树高误差容易受到噪声点的影响,当用相应的参数值识别噪声点时,误差会大幅增加;树冠宽度由Voronoi约束自动分割,重叠树组中树冠点的归属是造成树冠宽度错误的主要原因;常规躯干的胸径误差较小,但弯曲躯干计算的胸径是真实胸径的倍数,容易造成较大的粗差。
三个研究区树木中心的总体误差如表7所示,可以看出S3的总体误差为2.378 m,与S1和S2相差较大,因为部分柳树的树干没有被提取在S3的单树提取结果中,这部分柳树的树冠被归因于相邻的有树干的柳树,因此这种柳树与相邻的柳树共享同一树干,如欠分割的柳树在图 15b 中。因此,在计算位置标准差时,会计算真实值中躯干中心与共用躯干的距离标准差,造成较大的粗差,影响整体误差。
表 7. 中心位置的标准偏差。

S1和S2中树木的质心距离误差在15cm以内,S1的整体误差仅达到3.4cm,表明本文的GDRG算法对提取单杨树树干的适用性。
5. Conclusions
本文提出了一种基于区域生长高斯分布 (GDRG) 算法的车载 LiDAR 点云中路边树木自动细化提取技术。设计和研究了路边单棵树分割和参数信息化的统计方法,包括基于树干点和优化种子点的GDRG算法、树冠点Voronoi图约束的单棵树分割和树木几何参数计算,可为路边单树分割和参数信息化提供支持。环境安全信息化、道路安全信息管理和森林生物量估算。该方法在一定程度上解决了弯曲或不规则树干分类提取、树冠点密度小导致结果完整性不高、树干点缺失严重等问题。同时,由于建筑物和树木的联系,我们的方法在柳树组的分割和提取中参数阈值较多,准确率较低;这些问题有待今后进一步研究。在应用方面,行道树点云几何参数的准确提取只是方程式的一部分。扫描过程中由于点被遮挡而导致目标点丢失的问题,也需要对丢失点进行跟踪补全。提取的点用于3D重建,满足高精度地图构建的需要。
论文链接
References


