第4节:alphapose项目运行和参数
注:B站有相应视频,点击此链接即可跳转观看https://www.bilibili.com/video/BV1hb4y117mu/
第4节:运行和参数
4.1 webcam_demo.py
alphapose可以运行图片、视频、实时画面,他们的原理是一样的,只不过参数设置有些不同,我们以实时画面为例为大家进行讲解,运行实时画面部分主要包含在webcam_demo.py中,人体检测和姿态估计的函数,如代码清单4.1-1所示。
代码清单4.1-1
#导入各种依赖项
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import torchvision.transforms as transforms
import torch.nn as nn
import torch.utils.data
import numpy as np
from opt import opt
from dataloader_webcam import WebcamLoader, DetectionLoader, DetectionProcessor, DataWriter, crop_from_dets, Mscoco
from yolo.darknet import Darknet
from yolo.util import write_results, dynamic_write_results
from SPPE.src.main_fast_inference import *
from SPPE.src.utils.img import im_to_torch
import os
import sys
from tqdm import tqdm
import time
from fn import getTime
import cv2
from pPose_nms import write_json
args = opt
args.dataset = 'coco'#数据集是coco
#循环操作
def loop():
n = 0
while True:
yield n
n += 1
if __name__ == "__main__":
webcam = args.webcam#调用摄像头
mode = args.mode#选择检测模式,有快速、正常、精确三个模式,默认是正常模式
#如果不存在输出路径,就新建一个输出路径,默认输出路径为"examples/res/"
if not os.path.exists(args.outputpath):
os.mkdir(args.outputpath)
#加载输入的视频
data_loader = WebcamLoader(webcam).start()#调用摄像头,获取输入图像信息。
(fourcc,fps,frameSize) = data_loader.videoinfo()#输出摄像头捕捉到的信息
#加载检测器
print('Loading YOLO model..')
sys.stdout.flush()
#调用目标检测器,检测图像中的人体
det_loader = DetectionLoader(data_loader, batchSize=args.detbatch).start()
det_processor = DetectionProcessor(det_loader).start()#进行人体姿态估计
#加载人体姿态估计模型
pose_dataset = Mscoco()#生成人体姿态估计模型
if args.fast_inference:#选择模型模式
pose_model = InferenNet_fast(4 * 1 + 1, pose_dataset)
else:
pose_model = InferenNet(4 * 1 + 1, pose_dataset)
pose_model.cuda()
pose_model.eval()
#保存数据
save_path = os.path.join(args.outputpath, 'AlphaPose_webcam'+webcam+'.avi')#生成保存视频的路径
writer = DataWriter(args.save_video, save_path, cv2.VideoWriter_fourcc(*'XVID'), fps, frameSize).start()#保存检测结果
runtime_profile = {#记录检测时间
'dt': [],
'pt': [],
'pn': []
}
print('Starting webcam demo, press Ctrl + C to terminate...')
sys.stdout.flush()
im_names_desc = tqdm(loop())#通过进度条将处理情况进行可视化展示
batchSize = args.posebatch#姿态估计最大批量,默认80。
for i in im_names_desc:
try:
start_time = getTime()
with torch.no_grad():#只进行前向计算,不进行求导
(inps, orig_img, im_name, boxes, scores, pt1, pt2) = det_processor.read()#读取下一帧信息
if boxes is None or boxes.nelement() == 0:#如果图中不存在人体,进行下面的输出
writer.save(None, None, None, None, None, orig_img, im_name.split('/')[-1])
continue
ckpt_time, det_time = getTime(start_time)#获取开始时间
runtime_profile['dt'].append(det_time)#检测时间
#进行人体姿态估计
datalen = inps.size(0)
leftover = 0
if (datalen) % batchSize:
leftover = 1
num_batches = datalen // batchSize + leftover
hm = []
for j in range(num_batches):
inps_j = inps[j*batchSize:min((j + 1)*batchSize, datalen)].cuda()
hm_j = pose_model(inps_j)#进行人体姿态估计
hm.append(hm_j)
hm = torch.cat(hm)
ckpt_time, pose_time = getTime(ckpt_time)#获取ckpt_time时间
runtime_profile['pt'].append(pose_time)#人体姿态估计的时间
hm = hm.cpu().data
writer.save(boxes, scores, hm, pt1, pt2, orig_img, im_name.split('/')[-1])#保存信息
ckpt_time, post_time = getTime(ckpt_time)
runtime_profile['pn'].append(post_time)#后处理的时间
if args.profile:#在屏幕输出处添加速度分析
im_names_desc.set_description(
'det time: {dt:.3f} | pose time: {pt:.2f} | post processing: {pn:.4f}'.format(
dt=np.mean(runtime_profile['dt']), pt=np.mean(runtime_profile['pt']), pn=np.mean(runtime_profile['pn']))
)
except KeyboardInterrupt:#按ctrl+c退出程序
break
print(' ')
print('===========================> Finish Model Running.')
if (args.save_img or args.save_video) and not args.vis_fast:
print('===========================> Rendering remaining images in the queue...')
print('===========================> If this step takes too long, you can enable the --vis_fast flag to use fast rendering (real-time).')
while(writer.running()):
pass
writer.stop()#停止
final_result = writer.results()
write_json(final_result, args.outputpath)
4.1.1 运行流程
用pycharm打开alphapose文件,进入webcam_demo.py文件中。
1.右键单击run开始运行,如图4.1.1-1,第一次运行时间较长,耐心等待。
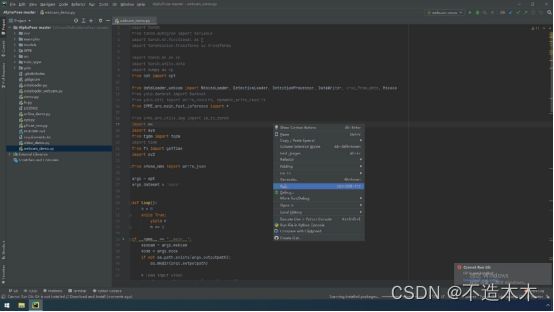
图4.1.1- 1
2.我们观察到,下面数据在运行但是我们看不到画面,这是因为我们并没有指定电脑摄像头,点击右上角的红色按钮,停止运行,如图4.1.1-2。
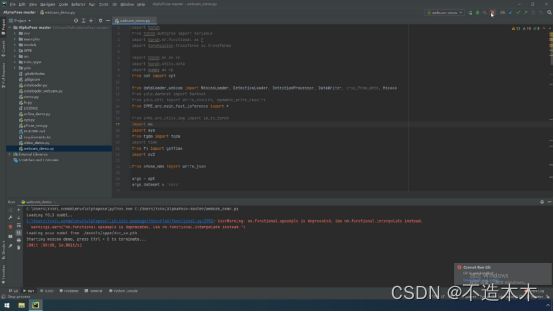
图4.1.1- 2
3.打开redme,我们找到webcam_demo.py的运行参数,复制,如图4.1.1-3。
 图4.1.1- 3
图4.1.1- 3
4.打开edit configuration,粘贴到parameters。点击apply,点击ok,如图4.1.1-4,4.1.1-5。
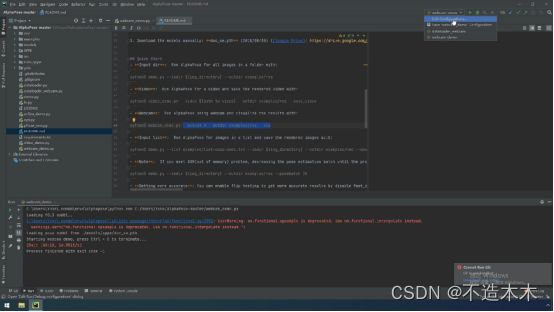 图4.1.1- 4
图4.1.1- 4
 图4.1.1- 5
图4.1.1- 5
5.回到webcam_demo.py再次运行,等待一会,我们发现运行结果报错,暂停运行,我们分析出错原因,发现是因为参数数值设置错误,如图4.1.1-6。
 图4.1.1- 6
图4.1.1- 6
7.我们点击错误定位连接,将参数直接修改为0.5,如图4.1.1-7。
 图4.1.1- 7
图4.1.1- 7
再次运行,我们发现还是刚刚的错误,还是将此函数的两个参数修改为0.5,如图4.1.1-8。
 图4.1.1- 8
图4.1.1- 8
9.修改完成后,重新运行,这时我们可以看到webcam_demo.py可以正常运行了,打开下面的可视化窗口,当摄像头区域中出现人体时,可以检测出人体的姿态,我们可以在摄像头范围内移动,观察检测效果。
4.2 参数设置
4.2.1 参数
–indir 输入图像所在位置的路径。将处理路径目录中的所有图像。
–list 输入图像的文本文件列表
–video 读取视频并逐帧处理视频
–outdir 存储姿势估计结果位置的路径
–vis 对输入图像进行可视化
–save_img 将输出图像保存到outdir/vis文件夹中
–save_video 保存输出视频
–vis_fast 使用加速模式。默认不加速
–format 输出结果的格式。默认COCO格式。可选择“cmu”(CMU-Pose格式 )和“open”(OpenPose格式)
–conf 置信度阈值。降低该值可以提高精度,但会降低速度。默认值为0.1
–nms 非极大值抑制阈值。增大该值可以提高精度,但会降低速度。默认值为0.6。
–detbatch 目标检测的批量大小
–posebatch 姿态估计的批量大小。如果遇到OOM问题,请减小此值
–sp 单进程运行。Windows用户需要使用
–inp_dim 目标检测输入图像的大小,应该是32的倍数。默认值为608
4.2.2 运行代码
对目录所有图片进性alphapose估计,将运行结果用CMU-Pose格式保存并保存图片
python3 demo.py --indir examples/demo/ --outdir examples/results/ --save_img --format cmu
对一个视频进行估计,保存视频并且使用加速模式
python3 video_demo.py --video examples/input.mp4 --outdir examples/results/ --save_video --vis_fast
对一个视频进行估计,通过增加置信度和减小NMS阈值来加速
python3 video_demo.py --video examples/input.mp4 --outdir examples/results/ --conf 0.5 --nms 0.45