一种基于人脸追踪和特征分析的疲劳驾驶预警平台
目录
- 整体描述
-
- 1. 嵌入式端:
- 2.程序端:
- 3. 辅助功能:
- 4. 项目整体工作流程
- 5. 不足之处
- 效果演示
- 程序源码
- 算法篇
-
- 基于AdaBoost级联分类器的人脸/眼睛位置检测算法
- 基于特征脸识别器(EigenFaceRecognizer)的驾驶人身份识别算法
- 基于坐标转换的头部姿态估计算法
- 基于PID算法的舵机云台控制
- 硬件篇
-
- 原型平台简介
整体描述
本文为2020年5月完稿的本科毕业设计的部分内容, 主要包含软件和硬件两个部分.
- 软件部分: 基于OpenCV-Python的图像处理驾驶疲劳检测
- 硬件部分: 基于树莓派4B控制的二自由度舵机云台人脸位置跟踪及蜂鸣器预警
涉及技术:
1. 嵌入式端:
树莓派4B的IO口操作
舵机的角度控制
基于人脸中心位置的舵机PID跟踪控制
设计思路为:
- 由树莓派端作为人脸位置追踪(保证摄像头正对驾驶人脸部)的图像采集平台;
- 由笔记本电脑(PC端)作为图像的实时处理云端计算平台
- 两者通过网线连接, 利用socket技术进行通信

2.程序端:
-
AdaBoost – Haar 级联分类器 人脸检测
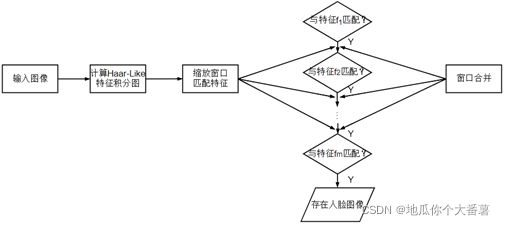
图2 AdaBoost – Haar 级联分类器工作流程 -
面部特征关键点检测 – dlib库(现在用whl+pip装dlib库真的简单,当时不熟悉,记得搭了两天的环境,好像还是用cmake编译的?)

- EigenFaceRecognizer(特征脸识别器) - 驾驶员人脸身份识别 – 用于检测持续驾驶时间

- Head Pose Estimation(头部姿态检测)

- socket通信控制蜂鸣器进行疲劳预警, 视频流传输, 视频堆栈等
3. 辅助功能:
-
树莓派与PC端(可升级为任意云端)进行嵌套字(socket)通信,来解决树莓派的算力不足问题,将图像处理主要运算交给算力强大的云计算(目前的实现是在本地PC端,未来可改进为云端)。
-
建立视频堆栈以抹去未处理的旧视频帧、弹出新视频帧的方法解决了网络摄像头模式下程序处理速度低于视频帧获取速度而导致的视频窗口随着实验时间而延时逐渐加剧的问题。
4. 项目整体工作流程
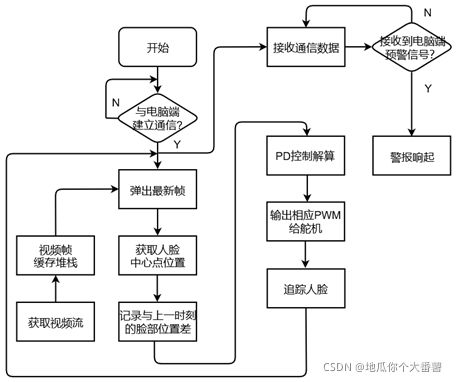

5. 不足之处
- 二自由度舵机云台转动后,导致摄像头不再为在驾驶人正前方的位置,导致头部姿态的估计不准确;
- 驾驶人低头拾物、转头观测等头部大动作运动时,导致脸部、眼部、嘴部等特征检测困难。
- 舵机云台和驾驶人头部两者通常是组合转动,进而导致偏差进一步扩大。
由于设备已经交还学校, 且目前不再研究此方向,因此本项目不再维护. 但仍希望有人在此基础之上能够继续完善和创新,成功后记得@我一下
效果演示
演示视频↗
程序源码
软件端:
程序源码:可脱离树莓派单独运行↗
程序源码:必须联合树莓派通信运行:
# -*- coding: utf-8 -*-
####################################################
# 作者: 刘朝阳
# 时间: 2020.05.01
# 更新时间: 2021.11.25
# 程序参考: https://blog.csdn.net/cungudafa/article/details/103499230
# 功能: 处理拍摄好的驾驶视频. 驾驶视频应包括 驾驶人的眨眼, 哈欠, 瞌睡点头
# 使用说明: 检测 blink, yawn 和 nod 时, 均是满足持续一定时间阈值后才能计入一次
# 待改进之处:
# ①不要用列表存储数据, 改用h5py格式
# ②使用不同摄像头时, 需要重新标定相机内外参, 才能准确预测出头部姿态
# ③在采集驾驶人图像于处理驾驶视频时, 最好保持距离摄像头的距离不变, 光照强度不变
####################################################
import threading #处理多线程的库
import cv2 #opencv2视觉库
import dlib # 人脸识别的库
import numpy as np # 数据处理的库
import os #操作模块
import socket #“嵌套字”-通信模块
import time #time模块
from imutils import face_utils
import imutils
import datetime
from scipy.spatial import distance as dist
import math
import matplotlib.pyplot as plt
# 世界坐标系(UVW):填写3D参考点,该模型参考http://aifi.isr.uc.pt/Downloads/OpenGL/glAnthropometric3DModel.cpp
# 3D人脸模型拟合坐标点
object_pts = np.float32([[6.825897, 6.760612, 4.402142], #33左眉左上角
[1.330353, 7.122144, 6.903745], #29左眉右角
[-1.330353, 7.122144, 6.903745], #34右眉左角
[-6.825897, 6.760612, 4.402142], #38右眉右上角
[5.311432, 5.485328, 3.987654], #13左眼左上角
[1.789930, 5.393625, 4.413414], #17左眼右上角
[-1.789930, 5.393625, 4.413414], #25右眼左上角
[-5.311432, 5.485328, 3.987654], #21右眼右上角
[2.005628, 1.409845, 6.165652], #55鼻子左上角
[-2.005628, 1.409845, 6.165652], #49鼻子右上角
[2.774015, -2.080775, 5.048531], #43嘴左上角
[-2.774015, -2.080775, 5.048531],#39嘴右上角
[0.000000, -3.116408, 6.097667], #45嘴中央下角
[0.000000, -7.415691, 4.070434]])#6下巴角
# 相机坐标系(XYZ):添加相机内参
K = [6.5308391993466671e+002, 0.0, 3.1950000000000000e+002,
0.0, 6.5308391993466671e+002, 2.3950000000000000e+002,
0.0, 0.0, 1.0]# 等价于矩阵[fx, 0, cx; 0, fy, cy; 0, 0, 1]
# 图像中心坐标系(uv):相机畸变参数[k1, k2, p1, p2, k3] 径向畸变参数:k1,k2,k3;切向畸变系数p1,p2
D = [7.0834633684407095e-002, 6.9140193737175351e-002, 0.0, 0.0, -1.3073460323689292e+000]
# 像素坐标系(xy):填写凸轮的本征和畸变系数
cam_matrix = np.array(K).reshape(3, 3).astype(np.float32)
dist_coeffs = np.array(D).reshape(5, 1).astype(np.float32)
# 重新投影3D点的世界坐标轴以验证结果姿势
reprojectsrc = np.float32([[10.0, 10.0, 10.0],
[10.0, 10.0, -10.0],
[10.0, -10.0, -10.0],
[10.0, -10.0, 10.0],
[-10.0, 10.0, 10.0],
[-10.0, 10.0, -10.0],
[-10.0, -10.0, -10.0],
[-10.0, -10.0, 10.0]])
# 绘制正方体12轴 连线
line_pairs = [[0, 1], [1, 2], [2, 3], [3, 0],
[4, 5], [5, 6], [6, 7], [7, 4],
[0, 4], [1, 5], [2, 6], [3, 7]]
def eye_aspect_ratio(eye): #计算眼部纵横比(EAR)
# 垂直眼标志(X,Y)坐标
A = dist.euclidean(eye[1], eye[5])# 计算两个坐标点之间的长度距离
B = dist.euclidean(eye[2], eye[4])# 计算两个坐标点之间的长度距离
# 计算水平之间的欧几里得距离
# 水平眼标志(X,Y)坐标
C = dist.euclidean(eye[0], eye[3])# 计算两个坐标点之间的长度距离
# 眼睛长宽比的计算
EAR = (A + B) / (2.0 * C) #椭圆面积公式为(A+B)/2 * C 2为两项的意思
# 返回眼睛的长宽比
return EAR
def mouth_aspect_ratio(mouth):#计算嘴部纵横比(MAR)
A = np.linalg.norm(mouth[2] - mouth[9]) #68个点中: 51, 59 # 计算两个坐标点之间的长度距离
B = np.linalg.norm(mouth[4] - mouth[7]) # 53, 57
C = np.linalg.norm(mouth[0] - mouth[6]) # 49, 55
MAR = (A + B) / (2.0 * C)
return MAR
def get_head_pose(shape):# 头部姿态估计
# (像素坐标集合)填写2D参考点,注释遵循https://ibug.doc.ic.ac.uk/resources/300-W/
# 17左眉左上角/21左眉右角/22右眉左上角/26右眉右上角/36左眼左上角/39左眼右上角/42右眼左上角/
# 45右眼右上角/31鼻子左上角/35鼻子右上角/48左上角/54嘴右上角/57嘴中央下角/8下巴角
image_pts = np.float32([shape[17], shape[21], shape[22], shape[26], shape[36],
shape[39], shape[42], shape[45], shape[31], shape[35],
shape[48], shape[54], shape[57], shape[8]])
# solvePnP计算姿势——求解旋转和平移矩阵:
# rotation_vec表示旋转矩阵,translation_vec表示平移矩阵,cam_matrix与K矩阵对应,dist_coeffs与D矩阵对应。
_, rotation_vec, translation_vec = cv2.solvePnP(object_pts, image_pts, cam_matrix, dist_coeffs)
# projectPoints重新投影误差:原2d点和重投影2d点的距离(输入3d点、相机内参、相机畸变、r、t,输出重投影2d点)
reprojectdst, _ = cv2.projectPoints(reprojectsrc, rotation_vec, translation_vec, cam_matrix,dist_coeffs)
reprojectdst = tuple(map(tuple, reprojectdst.reshape(8, 2)))# 以8行2列显示
# 计算欧拉角calc euler angle
# 参考https://docs.opencv.org/2.4/modules/calib3d/doc/camera_calibration_and_3d_reconstruction.html#decomposeprojectionmatrix
rotation_mat, _ = cv2.Rodrigues(rotation_vec)#罗德里格斯公式(将旋转矩阵转换为旋转向量)
pose_mat = cv2.hconcat((rotation_mat, translation_vec))# 水平拼接,vconcat垂直拼接
# decomposeProjectionMatrix将投影矩阵分解为旋转矩阵和相机矩阵
_, _, _, _, _, _, euler_angle = cv2.decomposeProjectionMatrix(pose_mat)
pitch, yaw, roll = [math.radians(_) for _ in euler_angle]
#pitch = math.degrees(math.asin(math.sin(pitch)))
pitch = math.degrees(pitch)
roll = -math.degrees(roll)
yaw = math.degrees(yaw)
return reprojectdst, euler_angle,pitch,roll,yaw # 投影误差,欧拉角
#使用dlib.get_frontal_face_detector() 获得脸部位置检测器
detector = dlib.get_frontal_face_detector()
#使用dlib.shape_predictor获得脸部特征位置检测器
predictor = dlib.shape_predictor('shape_predictor_68_face_landMARks.dat')
#分别获取左右眼面部标志的 索引
(lStart, lEnd) = face_utils.FACIAL_LANDMARKS_IDXS["left_eye"]
(rStart, rEnd) = face_utils.FACIAL_LANDMARKS_IDXS["right_eye"]
(mStart, mEnd) = face_utils.FACIAL_LANDMARKS_IDXS["mouth"]
#path = 0 #选择打开哪个摄像头,0为本机本地摄像头,下面的是树莓派USB的网络摄像头
path = 'http://192.168.137.102:8080/?action=stream'
tiaoshi = 0 #注释此处代表去用网络助手调试
#tiaoshi = 1 #注释此处代表不用网络助手,用树莓派usb摄像头
#设置通信模块-socket的工作模式是tcp/ip
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
#确保与树莓派Server建立通信,若无,则重试直至成功
while 1:
try:
print("连接树莓派端中...\n" )
if tiaoshi==1:
s.connect(('192.168.1.103',8080)) #网络调试助手用
if tiaoshi==0:
s.connect(('192.168.137.102',8888)) #树莓派用
print("连接成功!\n" )
break
except Exception:
print("连接失败,请确认树莓派端通信程序是否运行!\n")
time.sleep(1)
continue
def LoadImages(data):#data:训练数据所在的目录,要求图片尺寸一样。需要自己创建好后指定
images=[]#初始化
names=[]
labels=[]
label=0
#遍历所有文件夹
for subdir in os.listdir(data): #os.listdir()输出该目录下的所有文件名字
subpath=os.path.join(data,subdir) #连接路径,定位到子文件夹路径
if os.path.isdir(subpath): #如果子文件夹路径存在
#在每一个文件夹中存放着一个人的许多照片
names.append(subdir)#把该文件夹的名字 当成驾驶人名字
#遍历文件夹中的图片文件
for filename in os.listdir(subpath): #os.listdir()输出该目录下的所有文件名字
imgpath=os.path.join(subpath,filename)#连接路径,定位到子文件夹路径
img=cv2.imread(imgpath,cv2.IMREAD_COLOR)
gray_img=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
images.append(gray_img)#把该文件夹下人的灰度图像全放在一起,形成列表
labels.append(label)#给该文件夹下的人打上标签
label+=1 #label 为计数该人采集了多少张脸的数据
images=np.asarray(images)#将数据列表矩阵化,形成一张张单独的图片
#names=np.asarray(names)
labels=np.asarray(labels)#将数据列表矩阵化
#返回值:images:[m,height,width] m为样本数,height为高,width为宽;names:名字的集合; labels:标签集合
return images,labels,names
class Stack:
def __init__(self, stack_size):
self.items = []
self.stack_size = stack_size #设置想要的堆栈大小=3
def is_empty(self):
return len(self.items) == 0
def pop(self):
return self.items.pop()#弹出(最新的)项目
def peek(self):
if not self.isEmpty():
return self.items[len(self.items) - 1]
def size(self):
return len(self.items)#返回项目的长度大小
def push(self, item):
if self.size() >= self.stack_size: #如果项目的长度大小 大于等于 堆栈大小,即表示即将溢出
for i in range(self.size() - self.stack_size + 1):
#(self.size() - self.stack_size + 1) 表示看看要存入的项目比堆栈大多少,既会溢出多少个
self.items.remove(self.items[0])#依次删除堆栈底部(一开始)的值
self.items.append(item)#把最新值加入
def capture_thread(video_path, frame_buffer, lock): #存入视频帧
cap = cv2.VideoCapture(video_path) #开启摄像头
#cap.set(cv2.CAP_PROP_FOURCC, cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'))
cap.set(3, 480) #设置图像规格
if not cap.isOpened():
raise IOError("Couldn't open webcam or video")
while True:
return_value, frame = cap.read() #获取布尔值和视频帧
if return_value is not True:
break
lock.acquire() #上锁保护
frame_buffer.push(frame) #添加最新视频帧
lock.release() #解锁
def play_thread(frame_buffer, lock): #处理最新视频帧函数
#初始化各类参数
Driving_Time_Threshold = 85 #最多持续驾驶时长
Pitch_Threshold = 10 #点头的Pitch值的阈值 #不同摄像头采集的pitch阈值Pitch_Threshold设置会有区别
# if path ==0 :
# Pitch_Threshold = 3.5
# else:
# Pitch_Threshold = 11
driving_time = P80_time1 = P80_time2 = nod_time = yawn_time = 0
P80_sum_time1 = []
P80_sum_time2 = []
nod_sum_time = yawn_sum_time = []
nod_flag = yawn_flag = 0
P80_flag1 = P80_counter1 = 0
P80_flag2 = P80_counter2 = 0
yawn_counter = yawns = blink_counter = blinks = nod_counter = nods = 0#初始化各种计数器
alarm_flag = '0' #初始化疲劳驾驶警报标志位
f = 0
last_params = []
EAR_plt = MAR_plt = [] #画图用
X,y,names = LoadImages(data) #加载图像数据
model = cv2.face.EigenFaceRecognizer_create() #特征人脸识别器
model.train(X,y)#进行训练
nod_starttime = P80_starttime1 = datetime.datetime.now()#获取时刻
P80_starttime2 = datetime.datetime.now()#获取时刻
nod_endtime = datetime.datetime.now()#获取时刻
EAR = everybody_EAR_even = EAR_all_per_person = EAR_all_per_person_open = [] #创建一个空列表,用于存放眼睛高度
pitch_all_per_person = []
pitch_even_per_person = []
everybody_pitch_even = []
everybody_EAR_min = []
#遍历每个人的所有图片,提取出眼睛的平均高度
for subdir in os.listdir(data2): #os.listdir()输出该目录下的所有文件名字 到了lzy文件夹的面前(未进去)
EAR_all_per_person_open=EAR_all_per_person= []
subpath=os.path.join(data2,subdir) #连接路径,定位到子文件夹路径 到了lzy文件夹的面前(未进去)
if os.path.isdir(subpath): #如果子文件夹路径存在
for filename in os.listdir(subpath): #os.listdir(subpath)输出该目录下的所有文件名字 lzy进入,到了1、2、3.png了,然后对每一张进行处理
EAR_even_per_person =EAR_min_per_person = []
imgpath=os.path.join(subpath,filename)#连接路径,定位到子文件夹路径
img=cv2.imread(imgpath,cv2.IMREAD_COLOR) #读1.png
grayimg = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
faces = detector(grayimg, 0)#人脸检测,返回faces元组
for k, d in enumerate(faces):#找出每张图片上的人脸 #一个图片上人脸数就1,所以看作没有这句就行
shape = predictor(grayimg,d) #shape存着68特征点
shape_array = face_utils.shape_to_np(shape) #数组化
leftEye = shape_array[lStart:lEnd] #得到眼部索引
rightEye = shape_array[rStart:rEnd]
reprojectdst, euler_angle, pitch,roll,yaw = get_head_pose(shape_array) #重新投影,欧拉角
pitch_all_per_person.append(pitch)
leftEAR = eye_aspect_ratio(leftEye)#计算左眼EAR
rightEAR = eye_aspect_ratio(rightEye) #计算右眼EAR
EAR = (leftEAR + rightEAR) / 2.0#计算左右眼平均EAR
EAR_all_per_person.append(EAR)
#for完全进行完毕后,把lzy文件下的所有眼睛高度存入了
if EAR > 0.13 and EAR < 0.23: #防止闭眼时为0而拉低整体睁眼值 0.13 0.23由实验得出
EAR_all_per_person_open.append(EAR)#把每张图片的高度值放在一起,形成该人所有图片的高度值集合
pitch_even_per_person = np.mean(pitch_all_per_person)
EAR_even_per_person = np.mean(EAR_all_per_person_open)#算lzy眼睛高度的平均值
EAR_min_per_person = np.min(EAR_all_per_person)
everybody_pitch_even.append(pitch_even_per_person)
everybody_EAR_even.append(EAR_even_per_person)#把每个人眼睛的平均值记录
everybody_EAR_min.append(EAR_min_per_person)
print('所有人睁眼EAR平均值:',everybody_EAR_even)
print('所有人闭眼EAR最小值:',everybody_EAR_min)
print('所有人pitch的平均值:',everybody_pitch_even)
starttime = datetime.datetime.now()#获取程序开机时刻的时间
while True:
if frame_buffer.size() > 0:#确保设置了自定义堆栈有大小
#print("detect_thread frame_buffer size is", frame_buffer.size())
lock.acquire()#上锁保护
try:
im_rd = frame_buffer.pop()#弹出最新的视频帧
except Exception:
pass
lock.release()#解锁
# TODO 对新视频帧的算法写在这里
if path == 0:
im_rd = cv2.flip(im_rd,1,dst=None)
im_rd = imutils.resize(im_rd, height=540,width=720)
else:
#im_rd = cv2.flip(im_rd,0,dst=None)
im_rd = cv2.flip(im_rd,1,dst=None)
im_rd = imutils.resize(im_rd,height=640,width=480)#树莓派网络摄像头是360*480
original_img = im_rd.copy() #分析时用original_img,画图时用im_rd
#print(original_img.shape)
#cv2.imshow('original_img',original_img)
# 每帧数据延时1ms,延时为0读取的是静态帧
k = cv2.waitKey(1)
# 灰度化图像
img_gray = cv2.cvtColor(original_img, cv2.COLOR_RGB2GRAY)
# 使用人脸检测器检测每一帧图像中的人脸。并返回人脸数rects。dlib特征提取器的特色输出
faces = detector(img_gray, 0)
# 如果检测到人脸
if (len(faces)==1): #如果有多个人脸就不检测了
# 对每个人脸都标出68个特征点
for i in range(len(faces)):#因为人脸数只有1,所以该句可删除,但为以后增加功能所保留
# enumerate方法同时返回数据对象的索引和数据,k为索引,d为faces中的对象
for k, d in enumerate(faces):
try:
roi_gray=img_gray[d.top():d.bottom(),d.left():d.right()]#选取特定区域
roi_gray=cv2.resize(roi_gray,(92,112))
params=model.predict(roi_gray) #此处为特征人脸识别器的,不是dlib的,返回两个元素的数组,第一个是识别个体的标签,第二个是置信度(越小匹配度越高,0表示完全匹配)
except:
continue
# 用矩形框出人脸
#cv2.rectangle(im_rd, (d.left(), d.top()), (d.right(), d.bottom()), (0, 255, 255))
if params[0]!=last_params: #如果换了驾驶人,清空一切记录
pass
last_params = params[0] #记录上一时刻驾驶人的身份
# 使用dlib预测器得到68点数据的坐标
shape = predictor(original_img, d)#shape存着68特征点
shape_array = face_utils.shape_to_np(shape)#将脸部特征信息转换为数组array的格式
#提取左眼、右眼和嘴巴的所有坐标
leftEye = shape_array[lStart:lEnd]
rightEye = shape_array[rStart:rEnd]
mouth = shape_array[mStart:mEnd]
#使用cv2.convexHull获得凸包位置,使用drawContours画出轮廓位置进行画图操作 #把嘴巴、眼睛特征点连起来
leftEyeHull = cv2.convexHull(leftEye) #形成凸包
rightEyeHull = cv2.convexHull(rightEye)
cv2.drawContours(im_rd, [leftEyeHull], -1, (0, 255, 0), 1) # 连线画出
cv2.drawContours(im_rd, [rightEyeHull], -1, (0, 255, 0), 1)
mouthHull = cv2.convexHull(mouth)#形成凸包
cv2.drawContours(im_rd, [mouthHull], -1, (0, 255, 0), 1)# 连线画出
# 圆圈显示每个特征点
for i in range(68):
cv2.circle(im_rd, (shape.part(i).x, shape.part(i).y), 2, (0, 255, 0), -1, 8)
reprojectdst, euler_angle, pitch,roll,yaw = get_head_pose(shape_array) #重新投影,欧拉角
# 绘制正方体12轴
for start, end in line_pairs:
cv2.line(im_rd, reprojectdst[start], reprojectdst[end], (0, 0, 255))
'''######################################## 计算眨眼计数 #############################'''
leftEAR = eye_aspect_ratio(leftEye)
rightEAR = eye_aspect_ratio(rightEye)
EAR = (leftEAR + rightEAR) / 2.0
if EAR < 0.2:
blink_counter += 1
else:
if blink_counter >= 3: #如果连续检测EAR<0.2就:
blinks += 1
blink_counter = 0 #清零计数器
if round(driving_time)%60 == 0:
if blinks >= 20:
alarm_flag = 'blinks_waring'
# s.send(alarm_flag.encode('utf8')) #发送警报
blinks = 0 #清空眨眼次数
###################################################################################
'''######################################## P80标准: #############################'''
#定义两个常数 T1是睁眼程度20%,T2是睁眼程度80%
T1=everybody_EAR_min[params[0]]+0.2*(everybody_EAR_even[params[0]]-everybody_EAR_min[params[0]]) #睁眼程度20%
T2=everybody_EAR_min[params[0]]+0.8*(everybody_EAR_even[params[0]]-everybody_EAR_min[params[0]]) #睁眼程度80%
#先算t3-t2
if EAR < T1 and abs(pitch) < 10 and abs(yaw) < 20 and abs(roll) < 20 and P80_flag1 == 0:
#abs(pitch) < 10 and abs(yaw) < 20 and abs(roll) < 20是为了只目视前方时计算t3-t2
#P80_flag1 为标志位,作用是使程序仅在从睁眼到闭眼时为开始。防止从闭眼到睁眼时为开始。该作用详情见PERCLOS的图像
P80_counter1 += 1
if EAR < T1 and P80_counter1 >= 1: #连续1次以上 EAR
P80_starttime1 = datetime.datetime.now()
P80_counter1 = 0
P80_flag1 = 1
elif P80_flag1 == 1: #防止从闭眼(到睁眼)时记录
P80_endtime1 = datetime.datetime.now()
if (P80_endtime1 - P80_starttime1).seconds > 0 and P80_flag1 == 1:
P80_time1 = (P80_endtime1 - P80_starttime1).seconds
P80_sum_time1.append(P80_time1)
P80_flag1 = 0
else:
P80_counter1 = 0
#再算t4-t1 #原理通 计算t3-t2
if EAR < T2 and abs(pitch) < 10 and abs(yaw) < 20 and abs(roll) < 20 and P80_flag2 == 0:
P80_counter2 += 1
if EAR < T2 and P80_counter2 >= 1:
P80_starttime2 = datetime.datetime.now()
P80_counter2 = 0
P80_flag2 = 1
elif P80_flag2 == 1:
P80_endtime2 = datetime.datetime.now()
if (P80_endtime2 - P80_starttime2).seconds > 0 and P80_flag2 == 1:
P80_time2 = (P80_endtime2 - P80_starttime2).seconds
P80_sum_time2.append(P80_time2)
P80_flag2 = 0
else:
P80_counter2 = 0
#计算PERCOLS的值f
try: #防止除以0
f =round( sum(P80_sum_time1)/(sum(P80_sum_time2)) , 2 )
except:
pass
if round(driving_time)%60 == 0:
if f > 0.5:
alarm_flag = 'P80_waring'
# s.send(alarm_flag.encode('utf8')) #发送
P80_sum_time1 = []
P80_sum_time2 = []
f = 0
print('小于20%的时间: ',sum(P80_sum_time1),' s')
print('小于80%的时间: ',sum(P80_sum_time2),' s')
print('当前驾驶人的EAR: ',EAR,'\n')
print('T1:',T1,'; ','t2:',T2,'\n')
##################################################################################
'''######################################## 计算 M A R #################################'''
MAR = mouth_aspect_ratio(mouth)
if MAR > 0.75 and yawn_flag == 0:
yawn_counter += 1
if MAR > 0.75 and yawn_counter>= 3: #连续3次MAR>0.75 且此时还是MAR>0.75
yawn_starttime = datetime.datetime.now()
yawn_flag = 1
elif MAR <= 0.75 :
if (sum(yawn_sum_time)) >= 2: #如果上次张嘴时间>2s就 :
yawns += 1
yawn_sum_time = []
yawn_counter = 0
elif yawn_flag == 1: #闭嘴时结束清空上次计时
yawn_endtime = datetime.datetime.now()
if (yawn_endtime - yawn_starttime).seconds > 0 and yawn_flag ==1:
yawn_time = (yawn_endtime - yawn_starttime).seconds
yawn_sum_time.append(yawn_time)
yawn_flag = 0
if round(driving_time)%60 == 0:
if yawns >= 3:
alarm_flag = 'yawns_waring'
# s.send(alarm_flag.encode('utf8'))
yawns = 0
'''
MAR_plt.append(MAR) #画折线图像
plt.grid(True)
plt.plot(MAR_plt)
plt.ylim(0.1,1)
plt.show()
'''
#######################################################################################
'''######################################## 计算点头次数 #############################'''
print(pitch - everybody_pitch_even[params[0]]) #打印出 当前Pitch和正常情况下的Pitch 之差
if (pitch - everybody_pitch_even[params[0]]) >= Pitch_Threshold and nod_flag == 0:
#nod_flag 为标志位,防止从低头到抬头时记为开始
nod_counter += 1
if (pitch - everybody_pitch_even[params[0]]) >= Pitch_Threshold and nod_counter >= 3: #如果差值连续3次以上大于阈值Pitch_Threshold
nod_starttime = datetime.datetime.now()
nod_flag = 1
elif (pitch - everybody_pitch_even[params[0]]) < Pitch_Threshold :
if (sum(nod_sum_time)) >= 1:
nods += 1
nod_sum_time = []
nod_counter = 0
elif nod_flag == 1: #从低头到抬头时 结束、清空计时
nod_endtime = datetime.datetime.now()
if (nod_endtime - nod_starttime).seconds > 0 and nod_flag == 1:
nod_time = (nod_endtime - nod_starttime).seconds
nod_sum_time.append(nod_time)
nod_flag = 0
if round(driving_time)%60 == 0:
if nods >= 3:
alarm_flag = 'nods_waring'
# s.send(alarm_flag.encode('utf8'))
nods = 0
##################################################################################
'''######################################## 驾驶时长标准 ###########################'''
if driving_time > Driving_Time_Threshold: #超过规定的持续驾驶时间
alarm_flag = 'Long_Time_For_Driving'
# s.send(alarm_flag.encode('utf8'))
pass
##################################################################################
if path == 0: #在窗口上显示:
'''######################################## 显示驾驶人身份和驾驶时长 ###########################'''
cv2.putText(im_rd,"Driver identity: {}".format(names[params[0]]),(10,60),cv2.FONT_HERSHEY_SIMPLEX,0.6,(0, 0, 255),2) #直接在Haar返回的人脸上画
cv2.putText(im_rd,"Driving time:{} s".format(driving_time),(10,90),cv2.FONT_HERSHEY_SIMPLEX,0.6,(0, 0, 255),2) #直接在Haar返回的人脸上画
'''######################################## 显示头部状态角度 ###########################'''
cv2.putText(im_rd, "Pitch:{}".format(round(pitch,2)), (int(20+im_rd.shape[1]*0.25), 30), cv2.FONT_HERSHEY_SIMPLEX,0.6, (0, 255, 0), thickness=2)# GREEN
cv2.putText(im_rd, "Yaw:{}".format(round(yaw,2)), (int(20+im_rd.shape[1]*0.25), 60), cv2.FONT_HERSHEY_SIMPLEX,0.6, (0, 255, 0), thickness=2)# BLUE
cv2.putText(im_rd, "Roll:{}".format(round(roll,2)), (int(20+im_rd.shape[1]*0.25), 90), cv2.FONT_HERSHEY_SIMPLEX,0.6, (0, 255, 0), thickness=2)# RED
'''######################################## 显示疲劳特征 ###########################'''
cv2.putText(im_rd, "EAR:{}".format(round(EAR,2)), (int(20+im_rd.shape[1]*0.5),30),cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255,0,0), 2)
cv2.putText(im_rd, "MAR:{}".format(round(MAR,2)), (int(20+im_rd.shape[1]*0.5),60),cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255,0,0), 2)
if EAR > 0.2 :
cv2.putText(im_rd, "eyes_state: {}".format('Open'), (int(20+im_rd.shape[1]*0.5),90),cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255,0,0), 2)
else:
cv2.putText(im_rd, "eyes_state: {}".format('Close'), (int(20+im_rd.shape[1]*0.5),90),cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255,0,0), 2)
cv2.putText(im_rd, "Nod duration: {} s".format(sum(nod_sum_time)), (int(20+im_rd.shape[1]*0.5),120),cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255,0,0), 2)
cv2.putText(im_rd, "Yawn duration: {} s".format(sum(yawn_sum_time)), (int(20+im_rd.shape[1]*0.5),150),cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255,0,0), 2)
'''######################################## 显示疲劳判断值 ###########################'''
cv2.putText(im_rd, "Blinks:{}".format(blinks), (int(30+im_rd.shape[1]*0.75),30),cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255,255,0), 2)
cv2.putText(im_rd, "Yawns:{}".format(yawns), (int(30+im_rd.shape[1]*0.75),60),cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255,255,0), 2)
cv2.putText(im_rd, "Nods:{}".format(nods), (int(30+im_rd.shape[1]*0.75),90),cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255,255,0), 2)
cv2.putText(im_rd, "PERCOLS:{}".format(f), (int(30+im_rd.shape[1]*0.75),120),cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255,255,0), 2)
else:
'''######################################## 显示驾驶人身份和驾驶时长 ###########################'''
cv2.putText(im_rd,"Driver identity: {}".format(names[params[0]]),(10,60),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0, 0, 255),2) #直接在Haar返回的人脸上画
cv2.putText(im_rd,"Driving time:{} s".format(driving_time),(10,90),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0, 0, 255),2) #直接在Haar返回的人脸上画
'''######################################## 显示头部状态角度 ###########################'''
cv2.putText(im_rd, "Pitch:{}".format(round(pitch,2)), (int(40+im_rd.shape[1]*0.25), 30), cv2.FONT_HERSHEY_SIMPLEX,0.5, (0, 255, 0), thickness=2)# GREEN
cv2.putText(im_rd, "Yaw:{}".format(round(yaw,2)), (int(40+im_rd.shape[1]*0.25), 60), cv2.FONT_HERSHEY_SIMPLEX,0.5, (0, 255, 0), thickness=2)# BLUE
cv2.putText(im_rd, "Roll:{}".format(round(roll,2)), (int(40+im_rd.shape[1]*0.25), 90), cv2.FONT_HERSHEY_SIMPLEX,0.5, (0, 255, 0), thickness=2)# RED
'''######################################## 显示疲劳特征 ###########################'''
cv2.putText(im_rd, "EAR:{}".format(round(EAR,2)), (int(15+im_rd.shape[1]*0.5),30),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,0,0), 2)
cv2.putText(im_rd, "MAR:{}".format(round(MAR,2)), (int(15+im_rd.shape[1]*0.5),60),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,0,0), 2)
if EAR > 0.2 :
cv2.putText(im_rd, "eyes_state: {}".format('Open'), (int(15+im_rd.shape[1]*0.5),90),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,0,0), 2)
else:
cv2.putText(im_rd, "eyes_state: {}".format('Close'), (int(15+im_rd.shape[1]*0.5),90),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,0,0), 2)
cv2.putText(im_rd, "Nod time:{} s".format(sum(nod_sum_time)), (int(15+im_rd.shape[1]*0.5),120),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,0,0), 2)
cv2.putText(im_rd, "Yawn time:{} s".format(sum(yawn_sum_time)), (int(15+im_rd.shape[1]*0.5),150),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,0,0), 2)
'''######################################## 显示疲劳判断值 ###########################'''
cv2.putText(im_rd, "Blinks:{}".format(blinks), (int(20+im_rd.shape[1]*0.75),30),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,255,0), 2)
cv2.putText(im_rd, "Yawns:{}".format(yawns), (int(20+im_rd.shape[1]*0.75),60),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,255,0), 2)
cv2.putText(im_rd, "Nods:{}".format(nods), (int(20+im_rd.shape[1]*0.75),90),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,255,0), 2)
cv2.putText(im_rd, "PERCOLS:{}".format(f), (int(20+im_rd.shape[1]*0.75),120),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255,255,0), 2)
# 只检测到一个人脸-正常运行中
cv2.putText(im_rd, 'Working', (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)
elif (len(faces)==0):
# 如果没有检测到人脸
cv2.putText(im_rd, "No Face", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)
else:
#如果检测到有多个人脸
cv2.putText(im_rd, "Too Many Faces!", (10, im_rd.shape[0]*0.5), cv2.FONT_HERSHEY_SIMPLEX, 1.3, (255, 0, ), 2)
endtime = datetime.datetime.now()
driving_time= (endtime - starttime).seconds #持续驾驶时间
# 窗口显示视频帧
cv2.imshow("camera", im_rd)
Key = cv2.waitKey(10)
# 按下Esc键退出
if (Key == 27):
break
# 删除建立的窗口
cv2.destroyAllWindows()
s.close() #关闭socket
if __name__ == '__main__':
data='./face_data' #路径
data2='./face_data2'
frame_buffer = Stack(3) #设置堆栈大小
lock = threading.RLock()
t1 = threading.Thread(target=capture_thread, args=(path, frame_buffer, lock)) #capture_thread-存视频帧函数的线程
t1.start()
t2 = threading.Thread(target=play_thread, args=(frame_buffer, lock)) #play_thread-处理最新视频帧函数的线程
t2.start()
硬件端: 程序源码↗:Raspberry Pi 4B + Stack + Servo + socket.py
# -*- coding: utf-8 -*-
########################################################################################
# 作者: 刘朝阳
# 时间: 2020.05.01
# 更新时间: 2021.11.25
# 功能: 利用树莓派4B的GPIO产生PWM, 通过PID算法控制二自由度舵机追踪驾驶人的人脸位置
# 辅助功能: 人脸检测; socket与电脑通信(通过光纤网线); 视频堆栈; 蜂鸣器
########################################################################################
from __future__ import division #对未来版本兼容 只能放第一句
import Adafruit_PCA9685 #舵机控制库 pwm、频率等
import time #time库,用于延时
import cv2
import threading
import socket
import RPi.GPIO as GPIO #树莓派的gpio库
GPIO.setmode(GPIO.BCM) #gpio的排序定义方式
GPIO.setup(16, GPIO.OUT) #16为蜂鸣器io口
GPIO.output(16,True) #ture为不响,详细见电路原理图
#----------------------------通信程序分割线-------------------------------------
#设置socket的模式是tcp/ip
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
#这里我们就用到了静态ip
#请根据自身情况自行修改port ,根据电脑ip不同而改
address='192.168.137.102'
port =8888
#绑定地址和端口号
s.bind((address,port))
#设置允许接入的服务器的个数
s.listen(2)
print("请运行电脑端的通信程序,确保通信已建立后程序才会运行!")
sock,addr=s.accept()
#初始化PCA9685和舵机
pwm = Adafruit_PCA9685.PCA9685()
pwm.set_pwm_freq(60) #设置pwm频率
time.sleep(0.5) #延时0.5s
pwm.set_pwm(1,0,90) # 参数:(通道(哪一个舵机)、(0)、(脉冲数))1为下面的舵机
time.sleep(0.5)
pwm.set_pwm(2,0,325) #此处为控制Y轴(俯仰),脉冲数越大,舵机越向下 设置以在实验室调好的为准,这个325是以前调的
time.sleep(1)
#初始化、引入分类器
face_cascade = cv2.CascadeClassifier( '123.xml' )
eye_cascade = cv2.CascadeClassifier('eye.xml')
#初始化各个参数,之后用到处详细介绍
x=y=w=h=0
thisError_x=lastError_x=0
thisError_y=lastError_y=0
Y_P = 425 #舵机开始初试位置设置
X_P = 425 #舵机开始初试位置设置
#控制舵机的详细函数
def Servo():
while True:
CON=0
if CON==0: #CON=0 代表是一开机时的初试中位
pwm.set_pwm(1,0,650-X_P+200)
pwm.set_pwm(2,0,650-Y_P+200)
CON=1
else:
pwm.set_pwm(1,0,650-X_P) #正常工作时的PWM获取输出 X为下面的舵机轴
pwm.set_pwm(2,0,650-Y_P) #正常工作时的PWM获取输出 Y为上面的舵机轴
class Stack: #设置视频堆栈
def __init__(self, stack_size):
self.items = []
self.stack_size = stack_size #设置想要的堆栈大小=3
def is_empty(self):
return len(self.items) == 0
def pop(self):
return self.items.pop() #弹出(最新的)项目
def peek(self):
if not self.isEmpty():
return self.items[len(self.items) - 1] #返回去掉最后一帧的项目
def size(self):
return len(self.items) #返回项目的长度大小
def push(self, item):
if self.size() >= self.stack_size: #如果项目的长度大小 >= 堆栈大小,即表示即将溢出时
for i in range(self.size() - self.stack_size + 1):
#(self.size() - self.stack_size + 1) 表示看看要存入的项目比堆栈大多少,既会溢出多少个
self.items.remove(self.items[0])#依次删除堆栈底部(一开始)的值
self.items.append(item)#把最新值加入
def capture_thread(video_path, frame_buffer, lock): #存入视频帧函数
print("capture_thread start")
#cap = cv2.VideoCapture(0) #选择开启哪个摄像头
cap = cv2.VideoCapture('http://192.168.137.102:8080/?action=stream') #选择开启哪个摄像头
cap.set(3, 640) #设置图像规格
cap.set(4, 480)
if not cap.isOpened():
raise IOError("摄像头不能被调用")
while True:
return_value, frame = cap.read() #获取布尔值和视频帧
if return_value is not True:
break
lock.acquire() #上锁保护
frame_buffer.push(frame) #添加最新视频帧
lock.release() #解锁
if cv2.waitKey(1)==27: #如果按esc则退出
break
cap.release()
cv2.destroyAllWindows()
def play_thread(frame_buffer, lock): #显示视频帧函数,对最新弹出的视频帧处理函数
print("detect_thread start")
print("detect_thread frame_buffer size is", frame_buffer.size())
global thisError_x,lastError_x,thisError_y,lastError_y,Y_P,X_P
while True:
try:
t=sock.recv(1024).decode('utf8') #接收socket函数,接收的值存入 t (alarm_flag)
if t =='1':
print('请勿疲劳驾驶')
GPIO.output(16,False) #Flase为响
cv2.waitKey(1)
elif t=='0':
GPIO.output(16,True) #True为不响
else:
GPIO.output(16,True) #True为不响
except Exception:
continue
if frame_buffer.size() > 0:#确保设置了自定义堆栈有大小
#print("detect_thread frame_buffer size is", frame_buffer.size())
lock.acquire() #上锁保护
frame = frame_buffer.pop() #弹出最新的视频帧
lock.release()# 解锁
#cv2.waitKey(100)
# TODO 算法
frame = cv2.flip(frame,0,dst=None) #图像上下反转
frame = cv2.flip(frame,1,dst=None) #图像左右反转
gray= cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)#灰度化图像
#对灰度图进行.detectMultiScale()
faces=face_cascade.detectMultiScale( #创建了一个 faces 的向量元组,已经找到了人脸位置
gray, #具体参数可以搜索 “python中face_cascade.detectMultiScale 参数调节”
scaleFactor=1.3, #越小越精确且计算量越大
minNeighbors=2, #连接几次检测出人脸 才认为是真人脸
minSize=(300, 300) #你认为图像中人脸最小的大小,调大有利于减少误判,但可能把小于此值的人脸排除)
if len(faces)>0: #如果人脸数大于0
#print('face found!')
#temp = (x,y,w,h)
for(x,y,w,h) in faces: #(x,y)为人脸区域左上角的坐标,w、h为人脸区域的宽、高
cv2.rectangle(frame,(x,y),(x+h,y+w),(0,255,0),2) #画矩形
eyeh=int(h/2) #仅保留上半脸
fac_gray = gray[y: (y+eyeh), x: (x+w)] #将脸部全部灰度化
eye_result = [] #清空眼睛位置坐标
eye = eye_cascade.detectMultiScale(fac_gray, 1.1, 7) #眼睛检测器,具体参数可以搜索 “python中eye_cascade.detectMultiScale 参数调节”
for (ex, ey, ew, eh) in eye:
eye_result.append((x+ex, y+ey, ew, eh)) #(x,y)为眼睛区域左上角的坐标,w、h为眼睛区域的宽、高
for (ex, ey, ew, eh) in eye_result:
cv2.rectangle(frame, (ex, ey), (ex+ew, ey+eh), (0, 255, 0), 2)
result=(x,y,w,h) #提取出xywh
x=result[0]+w/2 #即 x=x+w/2 定位到人脸图像的正中央,把x当作人脸中央
y=result[1]+h/2 #即 y=y+h/2 定位到人脸图像的正中央,把y当作人脸中央
thisError_x=x-320 # 计算人脸中央距离整体图像中央的差距(x方向)
if thisError_x <10 and thisError_x >-10: #设置死区,小于此值认为现在就在中间
thisError_x = 0
thisError_y=y-240
if thisError_y <10 and thisError_y >-10:
thisError_y = 0
#if thisError_x > -20 and thisError_x < 20 and thisError_y > -20 and thisError_y < 20:
# facebool = False
#自行对P和D两个值进行调整
pwm_x = thisError_x*7+7*(thisError_x-lastError_x) #PD计算
pwm_y = thisError_y*7+7*(thisError_y-lastError_y)
lastError_x = thisError_x #把现在的误差记录下来,当作下次程序中上次误差
lastError_y = thisError_y
XP=pwm_x/100 #缩小
YP=pwm_y/100
X_P=X_P+int(XP) #注意有没有下划线“_”
Y_P=Y_P+int(YP)
if X_P>670: X_P=650 #限位,防止转太多
if X_P<0: X_P=0
if Y_P>650: Y_P=650
if X_P<0: Y_P=0
cv2.imshow("capture", frame)
s.close()
if __name__ == '__main__':
path = 0 #这个path没用了,在capture_thread函数的cap中从新选择
frame_buffer = Stack(3) #设置堆栈大小
lock = threading.RLock()
t1 = threading.Thread(target=capture_thread, args=(path, frame_buffer, lock)) #capture_thread-存入视频帧函数的线程
t1.start()
t2 = threading.Thread(target=play_thread, args=(frame_buffer, lock))#play_thread-处理最新帧函数的线程
t2.start()
tid=threading.Thread(target=Servo) # Servo- 舵机pwm输出函数的线程
tid.setDaemon(True)
tid.start()
算法篇
基于AdaBoost级联分类器的人脸/眼睛位置检测算法
基于AdaBoost级联分类器的人脸/眼睛位置检测算法概述
Haar级联分类器概述
基于特征脸识别器(EigenFaceRecognizer)的驾驶人身份识别算法
基于特征脸的人脸识别算法概述
基于坐标转换的头部姿态估计算法
基于特征脸的人脸识别算法概述
基于PID算法的舵机云台控制
基于PID的树莓派控制二自由度舵机人脸追踪云台设计
硬件篇
原型平台简介
| 类型 | 参数 |
|---|---|
| 处理器 | Intel® Core™ 7th i5 2.50GHz |
| GPU | GTX1050 2GB |
| RAM | 8GB |
| 操作系统 | Windows10 |
| 编程语言 | Python3.6/3.7 |
| 主要算法库 | OpenCV-3.2.0, Dlib-19.7.0/19.7.99 |
| 集成开发环境 | Spyder4 |
| 类型 | 参数 |
|---|---|
| 处理器 | 博通BCM2711 64位-1.5GHz四核 |
| GPU | Broadcom VideoCore VI @500MHz |
| RAM | 1GB |
| USB接口 | 双3.0/双2.0 |
| WIFI网络 | 802.11AC无线2.4GHz/5GHz双频 |
| 有线网络 | 千兆以太网 |
| 供电接口 | Type C |
| 电力需求 | 5V 3A |
| 操作系统 | Raspberry Pi |
| 编程语言 | Python2.7 |
| 主要算法库 | OpenCV-2.4.10 |
| 集成开发环境 | Spyder3 |
| 类型 | 参数 |
|---|---|
| 型号 | HF857 |
| 帧率 | 30fps |
| 像素 | 工业级高清30万像素 |
| 分辨率 | 640×480(设定) |
| 电力需求 | 5V, 70-100mA |
| 接口类型 | USB2.0 免驱动 |
| 输出格式 | MJPG/ YUV |
| 类型 | 参数 |
|---|---|
| 舵机类型 | 数字舵机 |
| 可转角度 | 180° |
| 额定力矩 | 0.9Kgf·cm |
| 电力需求 | 4.8V, 3mA |
| 齿轮材质 | 金属齿轮 |