论文阅读课11-TEMPROB:Improving Temporal Relation Extraction with a Globally Acquired Statistical Resource
文章目录
- abstract
- 1.Introduction
- 2.相关工作
- 3 TEMPROB: A Probabilistic Resource for TempRels
-
- 3.1 事件抽取
- 3.2TempRel提取
-
- 3.2.1 features
- 3.2.2 learning
- 3.3 Interence
- 3.4 corpus
- 3.5有趣的统计
- 3.6 极端情况
- 3.7 下列事件的分布
- 4.实验
-
- 4.1 Quality Analysis of TEMPROB
- 4.2 Improving TempRel Extraction
-
- 4.2.1 Improving Local Methods
- 4.2.2 Improving Global Methods
- 5 结论
Improving Temporal Relation Extraction with a Globally Acquired Statistical Resource
系统和数据集
EventCausality
abstract
时间关系抽取(之前,之后,重叠等)是理解以自然语言描述的事件的关键方面。我们认为,这项任务将得益于资源的可用性,该资源以事件通常遵循的时间顺序的形式提供先验知识。本文通过从20年来(1987年至2007年)的《纽约时报》(NYT)文章中提取事件之间的时间关系,来开发这种资源(在新闻领域中获得的概率知识库)。我们表明可以通过此资源改进现有的时间提取系统。作为副产品,我们还显示可以从该资源中检索有趣的统计信息,这可能会有益于其他时间感知任务。拟议的系统和资源均可公开获得1
- Temporal Relation Extraction
- 过去,重叠,未来
- 先验知识:事件遵循时间顺序
- 数据集:NYT(跨度20年)
- 以此改进现有的时间抽取系统
- 副产品:可从NYT中得到有趣的统计信息—可能有益于其他时间感知任务
1.Introduction
时间是知识表示的重要方面。用自然语言,时间信息通常表示为事件之间的关系。对这些关系进行推理可以帮助弄清事情发生的时间,估计事情需要多长时间以及总结一系列事件的时间表。最近举行的几次SemEval研讨会很好地展示了该主题的重要性(Verhagen et al., 2007, 2010; UzZaman et al., 2013; Llorens et al., 2015; Minard et al., 2015; Bethard et al., 2015, 2016, 2017).


- 时间关系抽取的挑战之一:
- 需要的通常遵循时间顺序的先验知识更高级
- 也就是常识
- 没有常识,人也很难知晓时间关系
- 在例1中不知道,因为没有先验知识(事件内容)
- 而例2中有,人类就可以知道时间关系,任务变容易了
- 得证,先验的重要性
- 以前:
- 只用局部特征,不包含人类的先验知识–解决:TEMPROB
- 需要的通常遵循时间顺序的先验知识更高级
时间关系提取中的挑战之一是,它需要事件通常遵循的时间顺序的高级先验知识。在示例1中,我们从CNN的几个摘要中删除了事件,因此我们无法使用对这些事件的先验知识。我们还被告知e1和e2具有相同的时态,而e3和e4具有相同的时态,因此我们无法求助于它们的时态来判断哪个发生较早。结果,即使是人类,也很难弄清这些事件之间的时间关系(以下称为“ TempRels”)。这是因为丰富的时间信息被编码在事件的名称中,并且在做出决策时通常起着不可或缺的作用。在示例1的第一段中,很难理解没有实际事件动词时实际发生的情况。更不用说它们之间的TempRel了。在第二段中,事情变得更加有趣:如果我们有e3:dislike和e4:stop,那么我们很容易知道“我不喜欢”发生在“他们停止专栏”之后。但是,如果我们有e3:ask和e4:help,则e3和e4之间的关系现在相反,而e3在e4之前。我们需要事件名称来确定TempRel。但是,示例1中没有它们。在示例2中,我们显示了完整的句子,由于我们的先验知识,该任务对人类而言变得容易得多,即爆炸通常会导致人员伤亡,并且人们通常会在获得帮助之前询问。受这些示例(实际上很常见)的激励,我们相信在确定事件之间的TempRel时,此类先验知识的重要性。
但是,大多数现有系统仅利用这些事件的相当局部的特征,不能代表人类对这些事件及其“典型”顺序的先验知识。结果,现有系统几乎总是尝试解决示例1中所示的情况,即使实际上像示例2中那样用输入呈现它们。因此,这项工作的第一个贡献就是以概率知识库的形式构建这种资源,该知识库是由大型《纽约时报》(NYT)语料库构建的。我们在下文中将资源命名为TEMporal关系概率知识库(TEMPROB),该知识库可能会益于许多时间感知任务。表1显示了TEMPROB的一些示例条目。其次,我们表明,可以使用TEMPROB改进现有的TempRel提取系统,无论是局部方法还是全局方法(稍后说明),都可以在基准TimeBank-Dense数据集上显着提高性能(Cassidy等,2014) )。
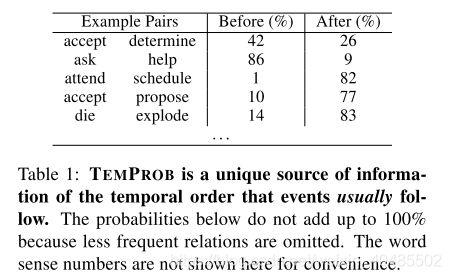
- 本文贡献
- TEMPROB(时间关系概率知识库)
- 来自NYT
- 用于
- 有益于时间感知任务
- 可以用TEMPROB改进现有的时间关系抽取系统(TempRel)
- 局部方法或全局方法均可
- 向时间关系抽取系统中注入先验知识
- TEMPROB(时间关系概率知识库)
2.相关工作
- 事件之间的TempRel可以用边缘标记的图表示,
- 其中节点是事件,
- 边缘用TempRels标记
- (Chambers和Jurafsky,2008; Do等,2012; Ning等,2017)。
- 给定所有节点,我们将进行TempRel提取任务,该任务是将标签分配给时间图中的边缘(通常包括 “vague” or “none” 标签以说明不存在边缘)。
- 分类模型:早期工作包括
- Mani等。 (2006);钱伯斯等。 (2007); Bethard等。 (2007); Verhagen和Pustejovsky(2008),
- 将问题表述为学习用于在不参考其他边的情况下确定局部每个边的标签的分类模型(即局部方法)。
- 缺点:通过这些方法预测的时间图可能会违反时间图应具有的传递特性。
- 例如,给定三个节点e1,e2和e3,本地方法可以将(e1,e2)= before,(e2,e3)= before和(e1,e3)= after分类,这显然是错误的,因为before是传递关系,并且(e1,e2)= before和(e2,e3)= before指示(e1,e3)= before。
- 贪婪方法:
- 最近的最新方法(Chambers等人,2014; Mirza和Tonelli,2016)通过
- 方法:以多步方式增长预测的时间图来规避此问题,
- 其中每次标记新边时,都会对图执行传递图闭合
- 从概念上讲,这是在贪婪地解决结构化预测问题。
- 整数线性规划:
- 另一类使用**整数线性规划(ILP)**的方法
- 全局方法:(Roth和Yih,2004)来获得对该问题的精确推断(即全局方法),
- 其中整个图被同时求解,
- 并且传递特性通过ILP约束自然地得到了强制执行
- (Bramsen等人,2006; Chambers and Jurafsky,2008; Denis and Muller,2011; Do等人,2012)。
- 通过将结构性约束也纳入学习阶段,最新的工作将这一想法进一步推向了新的境界(Ning等人,2017)。
- 如我们前面的示例所示,TempRel提取任务强烈依赖于先验知识。但是,对于产生和利用这种资源的关注非常有限。据我们所知,这项工作中提出的TEMPROB是全新的。
- Jiang et al. (2016) 提出的时间敏感关系(文学领域)是接近的(尽管还是很不一样)。
- Jiang et al. (2016) 从事知识图完成任务。
- 基于YAGO2(Hoffart等,2013)和Freebase(Bollacker等,2008),它手动选择了少数对时间敏感的关系(分别来自YAGO2的10个关系和Freebase的87个关系)。
- wasBornIn→diedIn
- graduateFrom→workAt
- 本文与Jiang的差别
- 一,规模差异:
- 蒋等。 (2016年)只能提取少量关系(<100),但我们研究的是通用语义框架(数以万计)以及其中任何两个之间的关系,我们认为它们具有更广泛的应用。
- 第二,粒度差异:
- Jiang等人中最小的粒度。 (2016)是一年,即只有当两个事件在不同年份发生时,他们才能知道它们的时间顺序,但是我们可以处理隐式时间顺序,而不必参考事件的物理时间点(即粒度可以任意小)。
- 第三,领域的差异:
- 江等。 (2016年)从结构化知识库(事件明确地锚定到某个时间点)中提取时间敏感关系,
- 我们从非结构化自然语言文本(其中物理时间点甚至不存在于文本中)中提取关系。
- 我们的任务更加笼统,它使我们能够提取出更多的关系,正如上面的第一个差异所反映的那样。
- 一,规模差异:
- VerbOcean(Chklovski和Pantel,2004),
- 它使用人工设计的词汇-句法模式(总共有12种这样的模式)来提取动词对之间的时间关系,这与本文提出的自动提取方法相反。
- 在VerbOceans中考虑的唯一词间关系是之前的,
- 而我们还考虑了诸如之后,包含,包含,相等和模糊的关系。
- 数量少:正如预期的那样,VerbOcean中的动词总数和之前的关系分别约为3K和4K,两者都比TEMPROB小得多,TEMPROB包含51K个动词框架(即,已消除歧义的动词),920万个条目以及最多总共80M个时间关系。
- Jiang et al. (2016) 提出的时间敏感关系(文学领域)是接近的(尽管还是很不一样)。
3 TEMPROB: A Probabilistic Resource for TempRels
3.1 事件抽取
提取事件及其之间的关系(例如,共指,因果关系,蕴含性和时间性)一直是NLP社区中的一个活跃领域。一般而言,事件被认为是与参与该动作的相应参与者相关联的动作。在这项工作中(Peng and Roth,2016; Peng et al。,2016; Spiliopoulou et al。,2017),我们考虑基于语义框架的事件,可以通过现成的语义角色标记(SRL)直接检测)工具。这与以前的事件检测工作非常吻合(Hovy等,2013; Peng等,2016)。
取决于感兴趣的事件,SRL结果通常是事件的超集,需要随后进行过滤(Spiliopoulou等,2017)。例如,在ERE(Song等人,2015)和事件块检测(Mitamura等人,2015)中,事件仅限于一组预定类型(例如“业务”,“冲突”和“司法”)。 );在TempRels的背景下,现有的数据集更多地侧重于谓语动词而不是名词4(Pustejovsky等,2003; Graff,2002; UzZaman等,2013)。因此,由于很难获得名词性事件的TempRel注释,因此本文仅着眼于动词语义框架,而在下文中,我们将“动词(语义框架)”与“事件”互换使用。
- 事件抽取:使用现有工具(SRL)
- 结果通常是事件的超集
- 需要过滤
- 在TEmpRels背景下:
- 将动词(语义框架)与事件互相使用
3.2TempRel提取
3.2.1 features
- 我们采用TempRel提取中常用的特征集(Do等,2012; Ning等,2017),
- (i)每个单独动词及其相邻三个词的词性(POS)标签。
- (ii)两者之间的距离,以tokens数量表示。
- (iii)事件提及之间的情态动词(即,意愿,意愿,可以,可能,可能和可能)。
- (iv)事件提及之间的时间联系词(例如,之前,之后和之后)。
- (v)这两个动词是否在WordNet的同义词集中具有共同的同义词(Fellbaum,1998)。
- (vi)输入事件提及是否具有从WordNet派生的通用派生形式。
- (vii)介词短语的主词分别覆盖每个动词。
3.2.2 learning
- 目标:需要训练一个可以在每个文档中注释TempRel的系统
- 数据集:,TimeBank-Dense数据集(TBDense)(Cassidy等人,2014)
- 质量最好
- 标签集R:before, after, includes, included, equal, vague
- 训练集:
- 抽取所有动词语义框架
- 仅保留与事件匹配的那些语义框架
- 算法
- the averaged perceptron algorithm (Freund and Schapire, 1998) implemented in the Illinois LBJava package (Rizzolo and Roth, 2010)
- 两个分类器
- 一个用于相同的句子关系
- 一个用于相邻的 句子关系
- 两个分类器
- the averaged perceptron algorithm (Freund and Schapire, 1998) implemented in the Illinois LBJava package (Rizzolo and Roth, 2010)
利用上面定义的特征,我们需要训练一个可以在每个文档中注释TempRel的系统。就其高密度TempRel而言,TimeBank-Dense数据集(TBDense)(Cassidy等人,2014)是已知质量最高的,并且是TempRel提取任务的基准数据集。它包含36个来自TimeBank的文档(Pustejovsky等,2003),这些文档使用(Cassidy等,2014)中提出的密集事件排序框架进行了重新注释。在本研究中,我们遵循其之前,之后,包含,包含,相等和模糊的标签集(用R表示)。
- 训练集
由于TBDense中事件注释的细微差异,我们按以下方式收集训练数据。我们首先从TBDense的原始文本中提取所有动词语义框架。然后,我们仅在TBDense中保留与事件匹配的那些语义框架(此阶段中保留了约85%的语义框架)。这样,我们可以简单地使用TBDense中提供的TempRel注释。此后,除非另有说明,否则本文中使用的TBDense数据集均指该版本。
我们将TempRel按每个关系的两个事件的句子距离进行分组5。然后,我们使用在伊利诺伊州LBJava软件包(Rizzolo和Roth,2010)中实现的平均感知器算法(Freund和Schapire,1998)从上述训练数据中学习。由于在TBDense中仅注释了句子距离为0或1的关系,因此我们将有两个分类器,一个分类器用于相同的句子关系,一个分类器用于相邻的句子关系。
- 三重交叉验证
- 请注意,TBDense最初分为Train(22个文档),Dev(5个文档)和Test(9个文档)。在随后的所有分析中,我们将Train和Dev结合在一起,并对27个文档(总共约10K关系)进行了3倍交叉验证,以调整任何分类器中的参数。
3.3 Interence
生成TEMPROB时,我们需要处理大量文章,因此由于其计算效率高,我们采用了前面所述的贪婪推断策略(Chambers等人,2014; Mirza和Tonelli,2016)。具体来说,我们在邻近句子关系分类器之前应用相同句子关系分类器。每当在本文中添加新关系时,将立即执行可传递图闭包。这样,如果在闭合阶段已经对边缘进行了标记,则不会再次对其进行标记,因此可以避免冲突。
- 策略:贪婪推断策略(Chambers等人,2014; Mirza和Tonelli,2016)
- 效率高
- 先用相同句子关系分类器
- 再用相邻句子关系分类器
- 添加新关系:执行传递图闭包
- 可避免冲突: 如果在闭合阶段已经对边缘进行了标记,则不会再次对其进行标记
3.4 corpus
如前所述,我们将用来构建TEMPROB的源语料库由20年(1987-2007)的NYT文章组成。它包含超过一百万个文档,我们使用Amazon Web Services(AWS)云上的Illinois Curator软件包(Clarke等人,2012)从每个文档中提取事件和相应的功能。总共,我们在NYT语料库中发现了51K个独特的动词语义框架和80M个关系(其中15K个动词框架提取了20多个关系,而9K个动词框架则提取了100多个关系)。
3.5有趣的统计
- 符号

- 容易混淆
- 时间上的先后T-Before
- 文本上(物理上)的先后P-Before
3.6 极端情况
- 极端情况
- 某些事件在语料库中几乎总是被标记为T-Before或T-After(如table 2)
- η b = C ( v i , v j , b e f o r e ) C ( v i , v j , b e f o r e ) + C ( v i , v j , a f t e r ) , η a = 1 − η b C − − 统 计 计 数 , r ∈ R C ( v i , v j , r ) = Σ i = 1 N Σ ( v m , v n , r m n ) ∈ E i L { v m = v i & v n = v j & r m n = r } \eta_b=\frac{C(v_i,v_j,before)}{C(v_i,v_j,before)+C(v_i,v_j,after)},\eta_a=1-\eta_b\\C--统计计数,r\in R\\ C(v_i,v_j,r)=\Sigma_{i=1}^N \Sigma_{(v_m,v_n,r_{mn})\in E_i}L_{\{v_m=v_i\&v_n=v_j\&r_{mn}=r\}} ηb=C(vi,vj,before)+C(vi,vj,after)C(vi,vj,before),ηa=1−ηbC−−统计计数,r∈RC(vi,vj,r)=Σi=1NΣ(vm,vn,rmn)∈EiL{vm=vi&vn=vj&rmn=r}
- 重要的是,如果想了解动词的时间含义,能够捕捉其时间顺序,而不是简单地获取其物理顺序。
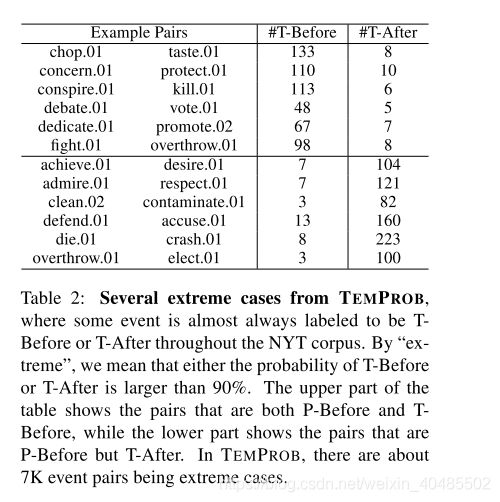
我们认为表2中的示例具有直觉上的appeal:chop发生在味道之前,清洁发生在污染之后,等等。更有趣的是,在表格的下部,我们显示了物理顺序不同于时间顺序的对:例如,当实现是P-Before欲望时,在大多数情况下它仍被标记为T-After(104) (111次)中,这在直觉上是正确的。实际上,例如在TBDense数据集中(Cassidy等人,2014),大约30%-40%的P-Before对是T-After。因此,
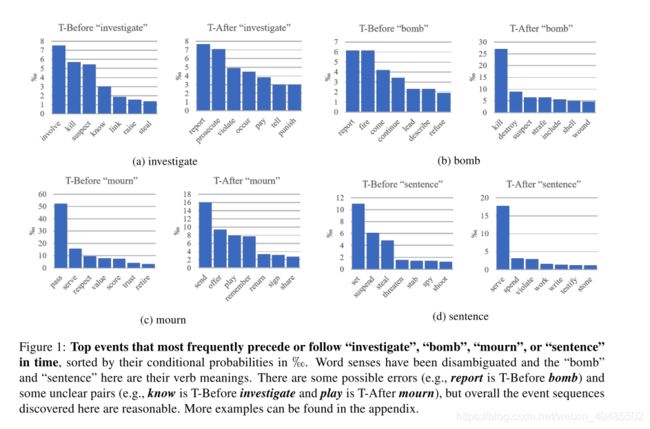
3.7 下列事件的分布
- 对每一个动词v, C ( v , r ) = Σ v i ∈ V C ( v , v i , r ) P ( v , T − B e f o r e , v ′ ∣ v , T − B e f o r e ) = C ( v , v ′ , b e f o r e ) C ( v , b e f o r e ) P ( v , T − A f t e r , v ′ ∣ v , T − A f t e r ) = C ( v , v ′ , a f t e r ) C ( v , a f t e r ) C(v,r)=\Sigma_{v_i\in V}C(v,v_i,r)\\ P(v,T-Before ,v'|v,T-Before)=\frac{C(v,v',before)}{C(v,before)}\\ P(v,T-After ,v'|v,T-After)=\frac{C(v,v',after)}{C(v,after)} C(v,r)=Σvi∈VC(v,vi,r)P(v,T−Before,v′∣v,T−Before)=C(v,before)C(v,v′,before)P(v,T−After,v′∣v,T−After)=C(v,after)C(v,v′,after)
对于特定动词,例如v = investigate,每个动词均按上述两个条件概率排序。然后,在时间上位于v之前或之后的最可能动词如图1所示,其中y轴是相应的条件概率。我们可以看到合理的事件序列,例如{参与,杀死,怀疑,窃取调查报告,起诉,支付,惩罚},这表明可以将TEMPROB用于事件序列预测或故事完结任务。在T-Before调查清单(图1a),炸弹的T-Before清单(图1b)和在T-After哀悼清单(图1c)中也有可疑的配对。 )。由于此处未考虑这些动词框架的论点,因此这几对看似反直觉的对是来自系统错误还是来自特殊上下文,需要进一步研究。
4.实验
在上面,我们已经解释了TEMPROB的构造,并从中展示了一些有趣的示例,这些示例旨在可视化其正确性。在本节中,我们首先对TEMPROB中获得的先验数据的正确性进行量化,然后说明TEMPROB可用于改进现有的TempRel提取系统。
4.1 Quality Analysis of TEMPROB
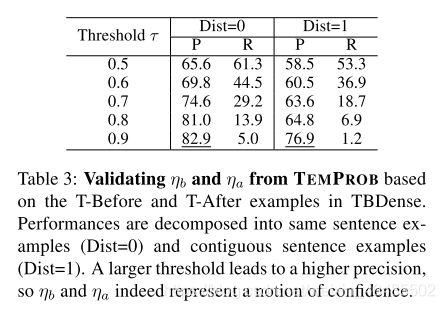

- η b 和 η a \eta_b和\eta_a ηb和ηa的值确实表示置信度级别
在表2中,我们显示了使用 η b 或 η a > 0.9 \eta_b或\eta_a>0.9 ηb或ηa>0.9的示例。我们认为它们似乎是正确的。在这里,我们基于TBDense量化 η b 和 η a \eta_b和\eta_a ηb和ηa的“正确性”。具体来说,我们收集了所有的T-Before和T-After金对。令为常数阈值。想象一个naive的预测器,对于每对事件vi和vj,如果为 η b > τ \eta_b>\tau ηb>τ,它将预测为T-Before;如果为 η a > τ \eta_a>\tau ηa>τ,则预测为T-After ;否则,它预测是的T-Vague。我们期望较高的 η b ( 或 η a ) \eta_b(或\eta_a) ηb(或ηa)表示对标记为T-Before(或T-After)的实例的较高置信度。
表3显示了该预测器的性能,该性能符合我们的预期,因此证明了TEMPROB的有效性。随着我们逐渐增加表3中τ的值,精度以与τ大致相同的速度增加,这表明TEMPROB的 η b 和 η a \eta_b和\eta_a ηb和ηa的值确实表示置信度级别。由于τ较大时,更多示例被标记为T-Vague,因此召回率也有望降低。
- 另一个数据集上EventCausality
- 不在TempRel域中的另一个数据集。相反,我们下载了EventCausality数据集8(Do等,2011)。
- 改为TempRel的数据集
- 对于每个因果相关的对e1和e2,如果EventCausality注释e1导致e2,我们将其更改为T-Before;
- 如果EventCausality注释e1是由e2引起的,我们将其更改为T-after。
- 假设:基于原因事件为结果事件发生之前发生
- 因此它也可以用于评估TEMPROB的质量。
- 我们采用了与和表4相同的表3中的预测变量,将其与两个基线进行了比较:
- i)始终预测T-Before和(ii)始终预测T-After。
- 首先,表4中的准确性(66.2%)与表3中的准确性相当,从而确认了TEMPROB统计数据的稳定性。
- 其次,通过直接使用TEMPROB的在先统计信息和,我们可以提高两个标签的精度,相对于两个基线(“ T-Before”为17.0%,“ T-After”为15.9%)具有显着的裕度。 总体而言,准确性提高了11.5%。
4.2 Improving TempRel Extraction
- TEMPROB的最初目的:是改善TempRel提取。
- 我们从两个角度进行说明:从TEMPROB获得的先验分布如何有效
- (i)作为局部方法的特征和
- (ii)作为全局方法的正则化项。
- 以下结果是根据TB-Dense的测试样本评估的(Cassidy等,2014)。
4.2.1 Improving Local Methods
- baseline:3.2.1提到的基本特征
- 对比:3.2.1+TEMPROB得到的先验分布
- 先验分布 f r ( v i , v j ) = C ( v i , v j , r ) σ r ′ ∈ R C ( v i , v j , r ′ ) , r ∈ R f_r(v_i,v_j)=\frac{C(v_i,v_j,r)}{\sigma_{r'\in R}C(v_i,v_j,r')},r\in R fr(vi,vj)=σr′∈RC(vi,vj,r′)C(vi,vj,r),r∈R
- 分类器:the averaged perceptron algorithm (Freund and Schapire, 1998)
- 3-fold cross validation.
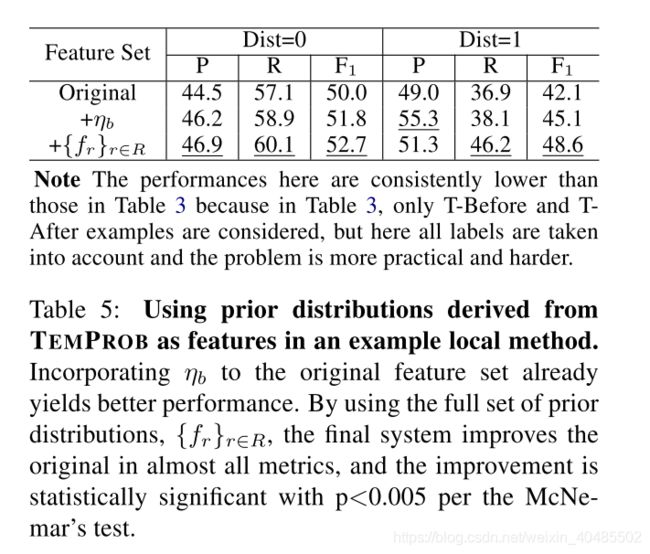
4.2.2 Improving Global Methods
如前所述。如图2所示,许多系统通过整数线性规划(ILP)采用全局推断方法(Roth和Yih,2004),以在整个时间图上施加传递约束(Bramsen等,2006; Chambers和Jurafsky,2008; Denis和Muller, 2011; Do等,2012; Ning等,2017)。除了第二节中所示的用法。 4.2.1中,TEMPROB的先前分布也可以用于规范化常规ILP公式。具体来说,在每个文档中,让为事件i和事件j的关系r的指示符函数;令为从本地分类器获得的相应softmax分数(取决于i和j之间的句子距离)。那么,全局推理的ILP目标是
- 全局方法:ILP(整数线性规划采用全局推断–>时间图+传递约束
- +TEMPROB:先验分布用于ILP公式
- 在每个文档中,事件i和事件j的关系r的指示符函数 L r ( i j ) ∈ ( 0 , 1 ) L_r(ij)\in(0,1) Lr(ij)∈(0,1)
- x r ( i j ) ∈ [ 0 , 1 ] x_r(ij)\in[0,1] xr(ij)∈[0,1]:从本地分类器获得的相应softmax分数
- 目标函数: L ^ = a r g m a x L Σ i j ∈ ϵ Σ r ∈ R ( x r ( i j ) + λ f r ( i j ) ) L r ( i j ) s . t . ( u n i q u e n e s s ) : Σ r L r ( i j ) = 1 ( s y m m e t r y ) : L r ( i j ) = L r ˉ ( j i ) ( t r a n s i t i v i t y ) 传 递 性 : L r 1 ( i j ) + L r 2 ( j k ) − Σ m = 1 M L r 3 m ( i k ) ≤ 1 \hat{L}=argmax_L\Sigma_{ij\in\epsilon}\Sigma_{r\in R}(x_r(ij)+\lambda f_r(ij))L_r(ij)\\ s.t.(uniqueness):\Sigma_rL_r(ij)=1\\ (symmetry):L_r(ij)=L_{\bar{r}}(ji)\\ (transitivity)传递性:L_{r_1}(ij)+L_{r_2}(jk)-\Sigma_{m=1}^ML_{r_3^m}(ik)\leq 1 L^=argmaxLΣij∈ϵΣr∈R(xr(ij)+λfr(ij))Lr(ij)s.t.(uniqueness):ΣrLr(ij)=1(symmetry):Lr(ij)=Lrˉ(ji)(transitivity)传递性:Lr1(ij)+Lr2(jk)−Σm=1MLr3m(ik)≤1
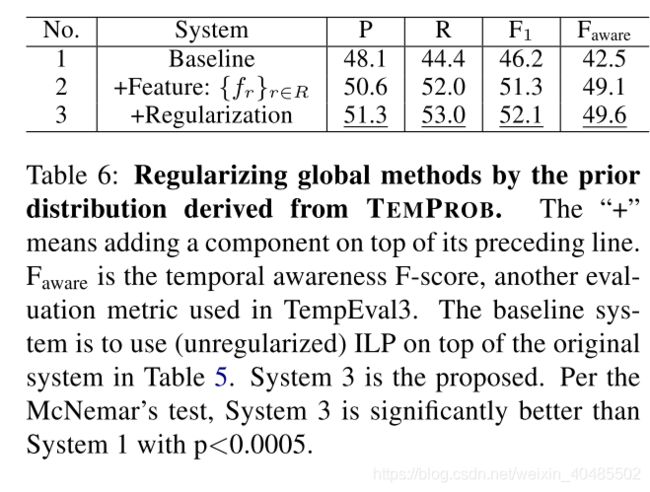
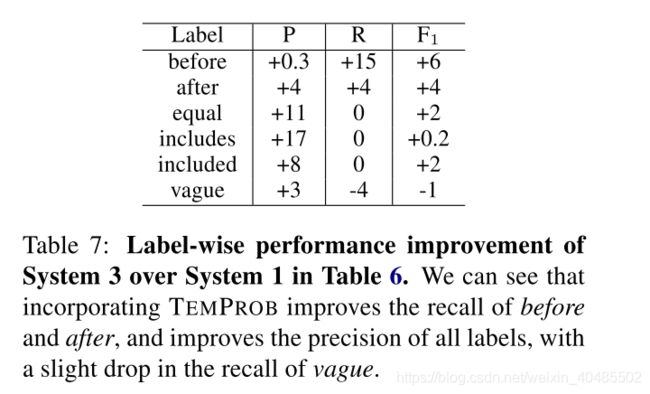
- 无gold properties ,也比最新的model( CAEVO)好

对于对完整的TBDense数据集感兴趣的读者,我们还进行了如下幼naive的扩充。回想一下,系统3仅对完整的TBDense数据集的子集进行预测。我们保留了这一预测子集,并填补了Ning等人遗漏的预测。 (2017)。将该天真增强的提议系统的性能与CAEVO和Ning等进行了比较。 (2017)在完整的TBDense数据集上。我们可以看到,用我们提出的系统Ning等人的预测代替。 (2017)获得了更好的精度,召回率,F1和认知度F1,这是该数据集上所有已报告绩效的最新技术水平。请注意,第4-5行的意识F1得分与Ning等人报道的值一致。 (2017)。据我们所知,表8中的结果是文献中第一个报告这两个指标的性能的结果,并且有希望看到所提出的方法在两个指标上均优于最新方法。
5 结论
时间关系(TempRel)提取在NLP中是一项重要且具有挑战性的任务,部分原因是它对先验知识的强烈依赖。受实际示例的启发,本文认为事件通常遵循的时间顺序资源很有帮助。为了构建这样的资源,我们使用现有的TempRel提取系统自动处理了来自NYT的大型语料库,其中包含超过100万个文档,并获得了TEMporal关系概率知识库(TEMPROB)。TEMPROB很好地展示了这些先验知识的能力,并且它已经展示了其在基准数据集TBDense上改进现有TempRel提取系统的能力。本文报告的资源和系统都可以公开获得12,我们希望它可以促进对与时间有关的任务的更多调查。