总结 | Prompt在NER场景的应用
每天给你送来NLP技术干货!
来自:NLP工作站
写在前面
大家好,我是刘聪NLP。
最近在做Prompt的相关内容,本人意识中一直觉得Prompt机制在序列标注任务上不是很好转换,因此,很早前,组长问我时,我夸下海口,说:“谁用prompt做NER呀”。然后,调研发现大佬们真是各显神通,是我目光短浅了。于是,决定进行一番总结,分享给大家。「有点长,大家慢慢看,记得点赞收藏转发」
部分论文已经在自己的数据上进行了实验,最后一趴会进行简要概述,并且会分析每种方法的优劣。
TemplateNER
TemplateNER,原文《Template-Based Named Entity Recognition Using BART》,是第一篇将Prompt方法应用于序列标注任务的论文,核心思想是通过N-Gram方法构建候选实体,然后将其与所有手工模板进行拼接,使用BART模型对其打分,从而预测出最终实体类别。是一篇「手工模板且无答案空间映射」的Prompt论文。
paper: https://arxiv.org/abs/2106.01760
github: https://github.com/Nealcly/templateNER模型,训练阶段如下图(c)所示,预测阶段如下图(b)所示,下面详细介绍。
任务构造
将序列标注任务转换成一个生成任务,在Encoder端输入为原始文本,Decoder端输入的是一个已填空的模板文本,输出为已填空的模板文本。待填空的内容为候选实体片段以及实体类别。候选实体片段由原始文本进行N-Gram滑窗构建,为了防止候选实体片段过多,论文中最大进行8-gram。
模板构建
模板为手工模板,主要包括正向模板和负向模板,其中,正向模板表示一个文本片段是某种实体类型,负向文本表示一个文本片段不是实体。具体模板如下表所示,我们也可以看出,最终模型效果是与手工模板息息相关的。
训练阶段
在训练阶段,正样本由实体+实体类型+正向模板构成,负样本由非实体片段+负向模板构成;由于负样本过多,因此对负样本进行随机负采样,使其与正样本的比例保持1.5:1。其学习目标为:
402 Payment Required
预测阶段
在预测阶段,将进行8-gram滑窗的所有候选实体片段与模板组合,然后使用训练好的模型进行预测,获取每个候选实体片段与模板组合的分数(可以理解为语义通顺度PPL,但是计算公式不同),分数计算如下:
402 Payment Required
其中,表示实体片段,表示第k个实体类别,T_{y_{k},x_{i:j}}表示实体片段与模板的文本。
针对,每个实体片段,选择分数最高的模板,判断是否为一个实体,哪种类型的实体。
DemonstrationNER
DemonstrationNER,原文《Good Examples Make A Faster Learner: Simple Demonstration-based Learning for Low-resource NER》,核心思想为在原始文本的基础上,拼接示例模板信息,提高原始序列标注模型的效果。是一篇「示例模板且无答案空间映射」的Prompt论文。
paper: https://arxiv.org/abs/2110.08454
github: https://github.com/INK-USC/fewNER模型如下图(b)所示,下面详细介绍。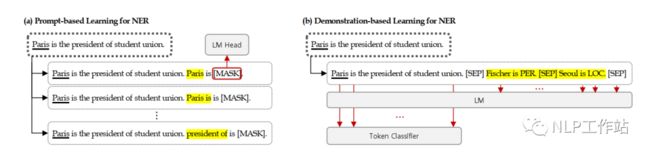
任务构造
依然是序列标注模型,仅将原始文本后面拼接示例模板,而示例模板的作用主要是提供额外信息(什么样的实体属于什么类别,与原文相似文本中哪些实体属于哪些类别等),帮助模型可以更好地识别出原始文本中的实体。
示例模板的构建
示例分为面向实体的示例和面向句子的示例,如下图所示, 面向实体的示例构造方法包括:
面向实体的示例构造方法包括:
随机法,即,随机从训练集的实体列表中,抽取若干个实体,作为示例。
统计法,即,选择在训练集中出现次数较多的实体,作为示例。
网格搜索法,即,对所有实体进行网格搜索,判断采用哪些实体作为示例时,在验证集上的效果最优。
面向句子的示例构造方法包括:
SBERT法,即,使用[CLS]向量之间的余弦值作为句子相似度分数,选择与原始句子最相似的句子作为示例。
BERTScore法,即,使用句子中每个token相似度之和作为句子相似度分数,选择与原始句子最相似的句子作为示例。
模板形式主要有三种,无上下文模板、有上下文模板和词典模板,如下图所示, 最终实验结果为实体-网格搜索法-有上下文模板效果最佳。分析句子级别不好可能是由于数据空间中句子间的相似度太低导致。
最终实验结果为实体-网格搜索法-有上下文模板效果最佳。分析句子级别不好可能是由于数据空间中句子间的相似度太低导致。
训练&预测
将示例模板拼接到原始模板后面,一起进入模型,仅针对原始文本进行标签预测与损失计算,如下:
其中,表示原始文本,表示示例模板,表示原始文本经过模型后的序列向量,表示示例模板经过模型后的序列向量。损失如下:
仅考虑原始文本部分。将需要领域迁移时,将原有模型的参数赋予新模型,进训练标签映射部分参数(linear或crf)即可。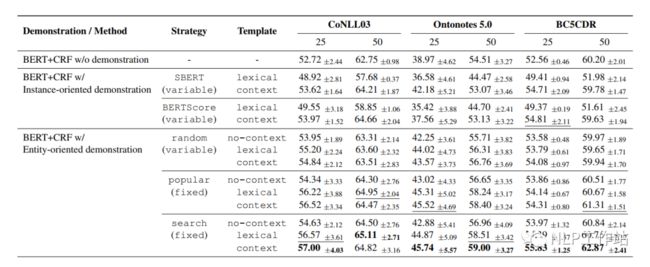
LightNER
LightNER,原文《LightNER: A Lightweight Generative Framework with Prompt-guided Attention for Low-resource NER》,核心思想为将原始序列标注任务转化为Seq2Seq的生成任务,通过在transformer的attetion机制中融入提示信息,在少量参数训练下,使模型达到较好的效果。是一篇「软模版且有答案空间映射」的Prompt论文。
paper: https://arxiv.org/abs/2109.00720
github: https://github.com/zjunlp/DeepKE/blob/main/example/ner/few-shot/README_CN.md模型如下图所示,下面详细介绍。
任务构造
将序列标注任务转换成一个生成任务,在Encoder端输入为原始文本,Decoder端逐字生成实体以及实体类型。模板信息融到Encoder和Decoder模型attention机制中,模板为soft-prompt,即一种可学习的自动模板。
基于提示引导的Attention
如上图(b)所示,分别在Encoder和Decoder中加入可训练参数,其中,为transformer的层数,,为模板长度,为隐藏节点维度,表示由key和value两项组成。
给定输入序列,,对于每一层transformer,的原始表示如下:
变化后的attention如下:
基于提示引导的Attention可以根据提示内容重新调节注意机制,使其少参数调节。并且实验发现,模板长度和提示信息融入的层数影响最终效果,当长度为10时,效果最佳。当层数为12层时,效果最佳。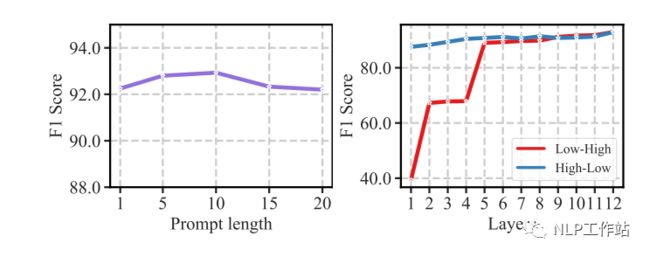
训练&预测
对于Encoder端,输入文本,获取表示;
对于Decoder端,输出不仅为实体内容还可能为实体类别,即,其每个输出内容为。
标签预测时,
402 Payment Required
402 Payment Required
其中,通过答案空间映射得来,具体为“将标签中几个词语的向量加权求和,作为标签的答案空间向量”。 消融实验发现,基于提示引导的Attention和答案空间映射对于结果的影响均较大。
消融实验发现,基于提示引导的Attention和答案空间映射对于结果的影响均较大。
EntLM
EntLM,原文《Template-free Prompt Tuning for Few-shot NER》,核心思想为将序列标注任务变成原始预训练的LM任务,仅通过答案空间映射,实现任务转化,消除下游任务与原始LM任务的Gap,提高模型效果。是一篇「无模板且有答案空间映射」的Prompt论文。
paper: https://arxiv.org/abs/2109.13532
github: https://github.com/rtmaww/EntLM/模型如下图所示,下面详细介绍。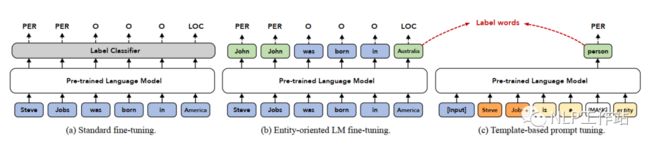
任务构造
将序列标注任务转换成一个与预训练阶段一致的LM任务,消除下游任务与预训练任务的Gap。对其输入文本进行LM预测,当token不是实体时,预测成与输入一致的token;当token是实体时,预测成实体类别下的token。而针对每个实体类别下的token的整合,即答案空间映射如何构造。
答案空间映射的构造
在特定领域下,往往未标注文本以及每个实体类别的实体列表是很好获取的,通过词表回溯构建伪标签数据
402 Payment Required
,其中, 表示实体类别, 表示文本数据。由于伪标签数据会存在很多噪音数据,因此在构建答案空间映射时,使用4种方法,对每个实体类别中的候选词语进行筛选。数据分布法,即,筛选出在语料库中,每个实体类别出现频率最高的几个词。
语言模型输出法,即,将数据输入到语言模型中,统计每个类别中词汇在语言模型输出概率的总和,选择概率最高的几个词。
数据分布&语言模型输出法,即将数据分布法和语言模型输出法相结合,将每个实体类别中的某一词的词频*该词模型输出概率作为该词得分,选择分数最高的几个词。
虚拟标签法,即,使用向量代替实体类别中的词语,相当于类别「原型」,向量获取办法为将上述某一种方法获取的高频词,输入到语言模型中,获取每个词语的向量,然后进行加和取平均,获取类别向量。
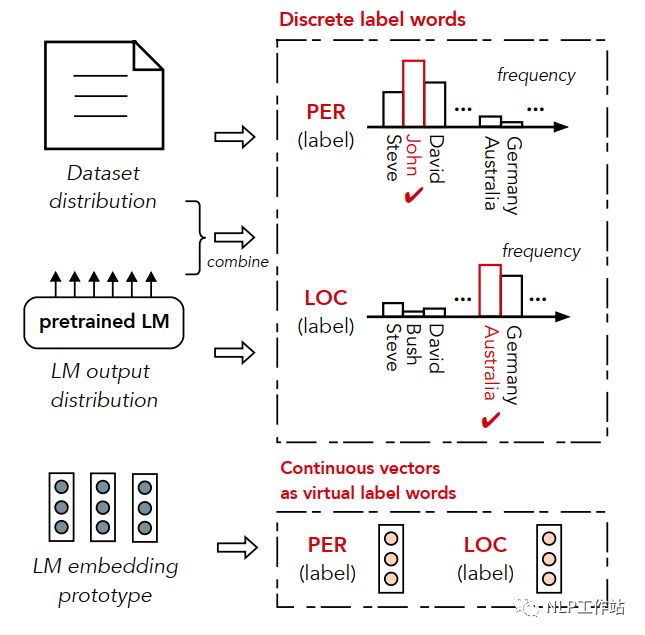 由于一些高频词可能出现在多个实体类别中,造成标签混乱,因此采用阈值过滤方法去除冲突词语,即(某个类别中的词语出现的次数/词语在所有类别中出现的次数)必须大于规定的阈值,才将该词语作为该实体类别的标签词语。
由于一些高频词可能出现在多个实体类别中,造成标签混乱,因此采用阈值过滤方法去除冲突词语,即(某个类别中的词语出现的次数/词语在所有类别中出现的次数)必须大于规定的阈值,才将该词语作为该实体类别的标签词语。 实验发现,绝大多少情况下,数据分布&语言模型输出法获取高频词,再使用虚拟标签法获取类别「原型」的方法最好。
实验发现,绝大多少情况下,数据分布&语言模型输出法获取高频词,再使用虚拟标签法获取类别「原型」的方法最好。
训练&预测
模型训练阶段采用LM任务的损失函数,如下:
其中,,为预训练过程中LM层参数。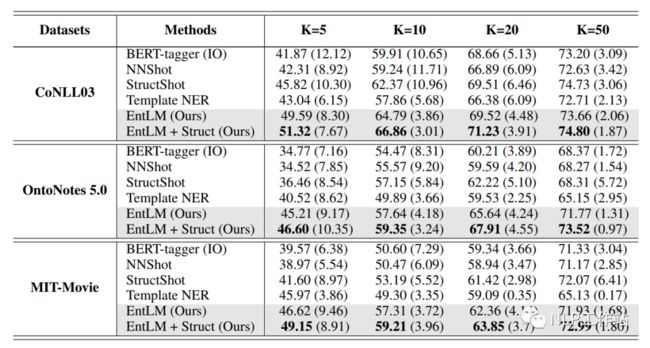
UIE
UIE,原文《Unified Structure Generation for Universal Information Extraction》,核心思想为将序列标注任务转化为Seq2Seq的生成任务,将手工提示模板与原始文本进行结合,通知模型待抽取的内容,再通过特定的抽取格式,进行逐字解码生成,提高模型效果。是一篇「手工模板且无答案空间映射」的Prompt论文。不过UIE适用于所有信息抽取任务,不限于NER任务,但后面主要以NER任务为例,进行阐述。
paper: https://arxiv.org/abs/2203.12277
github: https://github.com/universal-ie/UIE模型如下图所示,下面详细介绍。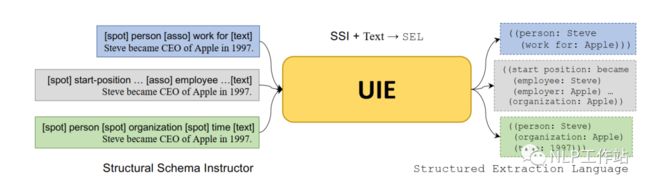 值得注意的是,UIE这篇论文与百度Paddle提到到UIE框架并不一个东西(看过源码的人都知道,不要混淆)。百度Paddle提到到UIE框架本质是一个基于提示的MRC模型,将提示模板作为query,文本作为document,使用Span抽取提示对应的内容片段。
值得注意的是,UIE这篇论文与百度Paddle提到到UIE框架并不一个东西(看过源码的人都知道,不要混淆)。百度Paddle提到到UIE框架本质是一个基于提示的MRC模型,将提示模板作为query,文本作为document,使用Span抽取提示对应的内容片段。
任务构造
将序列标注任务转换成一个生成任务,在Encoder端输入为提示模板+原始文本,Decoder端逐字生成结构化内容。以T5为基础,采用预训练技术,学习从文本到结构化生成。
手工模板
在编码端,通过待抽取schema(实体类别、关系等)构造Prompt模板,称为SSI,同于控制生成内容。模板样式如下图所示,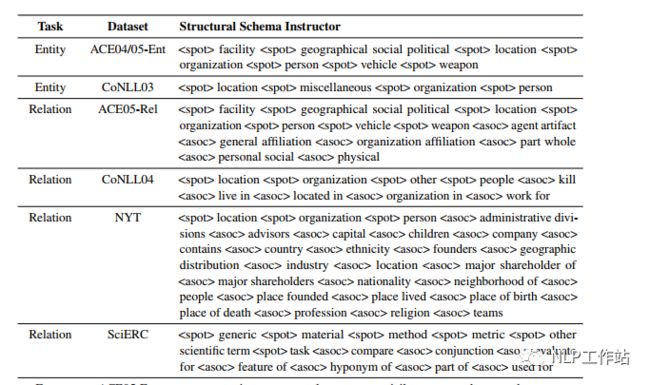 在解码端,设计了特定的抽取结构,称为SEL,而这种特殊的结构,也可以算作模板的一种吧,可以使解码时,按照统一要求进行表示。抽取结构样式如下图所示,
在解码端,设计了特定的抽取结构,称为SEL,而这种特殊的结构,也可以算作模板的一种吧,可以使解码时,按照统一要求进行表示。抽取结构样式如下图所示,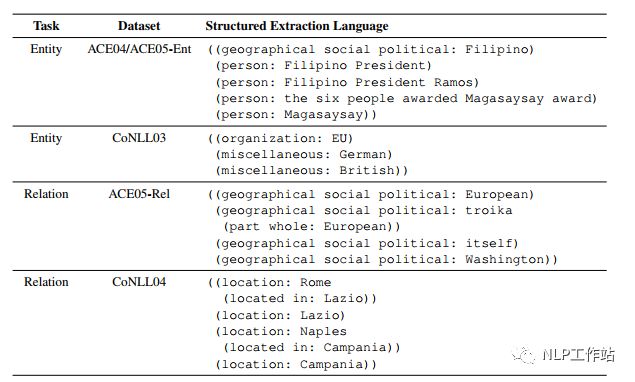 只需关注Entity部分即可。
只需关注Entity部分即可。
训练&测试
对于Encoder端,输入文本以及SSI内容,获取表示为:
对于Decoder端,逐字生成,如下:
由于训练数据中,待生成部分的数据格式均按照SEL格式构造,因此生成内容也会遵循其结构。
而模型重点是如何构造预训练数据,在预训练过程中,数据来自Wikidata、Wikipedia和ConceptNet。并且构造的数据格式包含三种,分别为、和。
,是通过Wikidata和Wikipedia构建的text-to-struct平行语料。
,是仅包含结构化形式的数据。
,是无结构化的纯文本数据。
在预训练过程中,三种语料对应不同的训练损失,训练的网络结构也不一样。训练整个Encoder-Decoder网络结构,仅训练Decoder网络结构,进训练Encoder网络结构,最终的损失是三者的加和。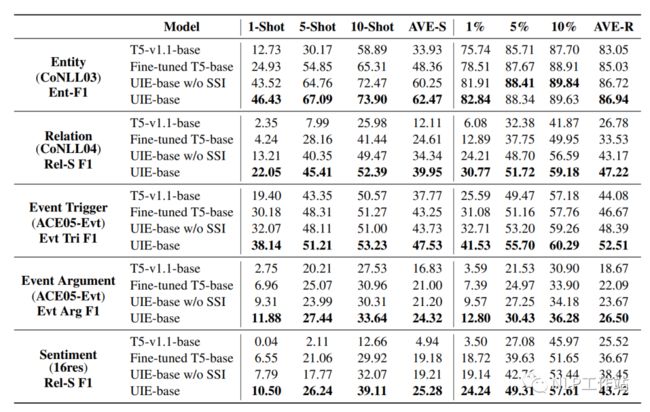
总结
本人在自己的中文数据集上,测试了TemplateNER、LightNER和EntLM的效果,惊奇的发现当数据量增加到50-shot时,「BERT-CRF」的效果是最好的(别整哪些没用的,加点数据啥都解决了,这也是令我比较沮丧的点。也许、可能、大概、兴许、或许是数据集或者代码复现(code下载错误?)的问题,无能狂怒!!!)。
当5-shot和10-shot时,EntLM方法的效果较好,但是跟答案空间映射真的是强相关,必须要找到很好的标签词才能获取较好的效果。而TemplateNER方法测试时间太久了,在工业上根本无法落地。
就像之前我对prompt的评价一样,我从来不否认Promot的价值,只是它并没有达到我的预期。是世人皆醉我独醒,还是世人皆醒我独醉,路还要走,任务还要做,加油!!!
最近文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
一种全新易用的基于Word-Word关系的NER统一模型,刷新了14种数据集并达到新SoTA
阿里+北大 | 在梯度上做简单mask竟有如此的神奇效果
ACL'22 | 快手+中科院提出一种数据增强方法:Text Smoothing,非常简单且有效尤其在数据不足的情况下