Linux学习笔记
7月10号
linuxcoll
1.ls——列出目录包含的文件及子目录,输入 cd, 然后输入你想要去的工作目录的路径名。
路径名可通过两种方式来指定,一种是绝对路径,另一种是相对路径
默认不加参数的情况下,ls命令会列出当前工作目录中的文件信息,经常与cd和pwd命令搭配使用。
而带上参数后,我们则可以做更多的事情,作为最基础、最频繁使用的命令,有必要仔细了解下其常用功能。
语法格式: ls [参数] [文件]
| -a | 显示所有文件及目录 (包括以“.”开头的隐藏文件) |
| -l | 使用长格式列出文件及目录的详细信息 |
| -r | 将文件以相反次序显示(默认依英文字母次序) |
| -t | 根据最后的修改时间排序 |
| -A | 同 -a ,但不列出 “.” (当前目录) 及 “..” (父目录) |
| -S | 根据文件大小排序 |
| -R | 递归列出所有子目录 |
| -d | 查看目录的信息,而不是里面子文件的信息 |
| -i | 输出文件的inode节点信息 |
| -m | 水平列出文件,以逗号间隔 |
| -X | 按文件扩展名排序 |
| --color | 输出信息中带有着色效果 |
实例:(重点)
输出当前目录中的文件(默认不含隐藏文件):ls
输出当前目录中的文件(含隐藏文件): ls -a
输出文件的长格式,包含属性详情信息:ls -l
输出指定目录中的文件列表:ls /etc
输出文件名称及inode属性块号码:ls -i
搭配通配符一起使用,输出指定目录中所有以sd开头的文件名称:ls /dev/sd*
依据文件大小进行排序,输出指定目录中文件属性详情信息:ls -Sl /dev
2.cp——复制文件或目录(copy)
用于将一个或多个文件或目录复制到指定位置,亦常用于文件的备份工作。
-r参数用于递归操作,复制目录时若忘记加则会直接报错,
-f参数则用于当目标文件已存在时会直接覆盖不再询问,这两个参数尤为常用。
语法格式:cp [参数] 源文件 目标文件
| -f | 若目标文件已存在,则会直接覆盖原文件 |
| -i | 若目标文件已存在,则会询问是否覆盖 |
| -p | 保留源文件或目录的所有属性 |
| -r | 递归复制文件和目录 |
| -d | 当复制符号连接时,把目标文件或目录也建立为符号连接,并指向与源文件或目录连接的原始文件或目录 |
| -l | 对源文件建立硬连接,而非复制文件 |
| -s | 对源文件建立符号连接,而非复制文件 |
| -b | 覆盖已存在的文件目标前将目标文件备份 |
| -v | 详细显示cp命令执行的操作过程 |
| -a | 等价于“pdr”选项 |
实例:(重点):
在当前工作目录中,将某个文件复制一份,并定义新文件名称:cp 源文件 目标文件
在当前工作目录中,将某个目录复制一份,并定义新目录名称:cp -r 新目录名称
将某个文件复制到/etc目录中,并覆盖已有文件,不进行询问: cp -f 文件 /etc
将多个文件一同复制到/etc目录中,如已有目标文件名称则默认询问是否覆盖:
cp - i anaconda-ks.cfg ks.cfg /etc
复制某个文件时,保留其原始权限及用户归属信息:
cp -a kickstart.cfg ks.cfg
3. mkdir——创建文件和目录 (make directories)
其功能是用来创建目录文件
语法格式 : mkdir [参数] 目录
常用参数:
| -p | 递归创建多级目录 |
| -m | 建立目录的同时设置目录的权限 |
| -z | 设置安全上下文 |
| -v | 显示目录的创建过程 |
参考实例
在当前工作目录中,建立一个目录文件:mkdir dir1
在当前工作目录中,创建一个目录文件并设置700权限,不让除所有主以外任何人读、写、执行它:
mkdir -m 700 dir2
在当前工作目录中,一次性创建多个目录文件:mkdir dir3 dir4 dir n
在系统根目录中,一次性创建多个有嵌套关系的目录文件:mkdir -p /dir1/dir2/dir3/dir4/dir5
4. mv——移动或改名文件 (move)
用于对文件进行剪切和重命名
cp命令是用于文件的复制操作,文件个数是增加的,
mv则为剪切操作,也就是对文件进行移动(搬家)操作,文件位置发生变化,但总个数并无增加。
在同一个目录内对文件进行剪切的操作,实际应理解成重命名操作。
语法格式:mv [参数] 源文件 目标文件
常用参数:
| -i | 若存在同名文件,则向用户询问是否覆盖 |
| -f | 覆盖已有文件时,不进行任何提示 |
| -b | 当文件存在时,覆盖前为其创建一个备份 |
| -u | 当源文件比目标文件新,或者目标文件不存在时,才执行移动此操作 |
参考实例
在当前工作目录中,对某个文件进行剪切后粘贴(重命名)操作: mv anaconda-ks.cfg ks.cfg
将某个文件移动到/etc目录中,保留文件原始名称:mv ks.cfg /etc
将某个目录移动到/etc目录中,并定义新的目录名称:mv Documents /etc/docs
将/home目录中所有的文件都移动到当前工作目录中,遇到已存在文件则直接覆盖:
mv -f /home/* .
5.pwd——显示当前工作目录的路径(print working directory)
显示当前工作目录的路径,即显示所在位置的绝对路径。
语法格式:pwd [参数]
常用参数:
| -L | 显示逻辑路径 |
参考实例
查看当前工作目录路径:pwd
7月11号——学习记录
6.cat——在终端设备上显示文件内容(concatenate)
其功能是用于查看文件内容,在Linux系统中有很多用于查看文件内容的命令,
例如more、tail、head……等等,每个命令都有各自的特点。
cat命令适合查看内容较少的、纯文本的文件。
对于内容较多的文件,使用more。
语法格式:cat [参数] 文件
常用参数:
| -n | 显示行数(空行也编号) |
| -s | 显示行数(多个空行算一个编号) |
| -b | 显示行数(空行不编号) |
| -E | 每行结束处显示$符号 |
| -T | 将TAB字符显示为 ^I符号 |
| -v | 使用 ^ 和 M- 引用,除了 LFD 和 TAB 之外 |
| -e | 等价于”-vE”组合 |
| -t | 等价于”-vT”组合 |
| -A | 等价于 -vET组合 |
| --help | 显示帮助信息 |
| --version | 显示版本信息 |
参考实例:
查看某个文件的内容:cat 文件名
查看某个文件的内容,并显示行号:cat -n 文件名
7. echo——输出字符串或提取后的变量值
echo是用于在终端设备上输出指定字符串或变量提取后值的命令
能够给用户一些简单的提醒信息,也可以将输出的指定字符串内容同管道符一起传递给后续命令作为标准输入信息再来进行二次处理,又或者同输出重定向符一起操作,将信息直接写入到文件中。
如需提取变量值,需在变量名称前加入$符号做提取,变量名称一般均为大写形式。
语法格式:echo [参数] 字符串/变量
常用参数:
| -n | 不输出结尾的换行符 |
| -e “\a” | 发出警告音 |
| -e “\b” | 删除前面的一个字符 |
| -e “\c” | 结尾不加换行符 |
| -e “\f” | 换行,光标扔停留在原来的坐标位置 |
| -e “\n” | 换行,光标移至行首 |
| -e “\r” | 光标移至行首,但不换行 |
| -E | 禁止反斜杠转移,与-e参数功能相反 |
| —version | 查看版本信息 |
| --help | 查看帮助信息 |
参考实例:
输出指定字符串到终端设备界面(默认为电脑屏幕):echo LinuxCool
输出某个变量值内容:echo \$PATH
搭配输出重定向符一起使用,将字符串内容直接写入文件中:echo "Hello World" > Document
输出带有换行符的内容:echo -e "First\nSecond\nThird"
指定删除字符串中某些字符,随后将内容输出:echo -e "123\b456"
8.rm——删除文件或目录(remove)
其功能是用于删除文件或目录,一次可以删除多个文件,或递归删除目录及其内的所有子文件。
rm也是一个很危险的命令,使用的时候要特别当心,尤其对于新手更要格外注意,
如执行rm -rf /*命令则会清空系统中所有的文件,甚至无法恢复回来。所以我们在执行之前一定要再次确认下在哪个目录中,到底要删除什么文件,考虑好后再敲击回车,时刻保持清醒的头脑。
语法格式:rm [参数] 文件
常用参数:
| -f | 强制删除(不二次询问) |
| -i | 删除前会询问用户是否操作 |
| -r/R | 递归删除 |
| -v | 显示指令的详细执行过程 |
参考实例
删除某个文件,默认会进行二次确认,敲击y进行确认: rm 文件名
删除某个文件,强制操作不需要二次确认:rm -f 文件名
删除某个目录及其内的子文件或子目录,一并都强制删除:rm -rf 目录名
强制删除当前工作目录内的所有以.txt为后缀的文件: rm -f *.txt
(离职小妙招,谨慎!!!) 强制清空服务器系统内的所有文件:rm -rf /*
9.tail——查看文件尾部内容
功能是用于查看文件尾部内容,显示出指定文件的末尾十行,如果指定了多个文件,则会在显示的每个文件内容前面加上文件名来加以区分。
语法格式:tail [参数] 文件
| -c | 输出文件尾部的N(N为整数)个字节内容 |
-f |
持续显示文件最新追加的内容 |
-F |
与选项“-follow=name”和“--retry”连用时功能相同 |
-n |
输出文件的尾部N(N位数字)行内容 |
| --retry | 即是在tail命令启动时,文件不可访问或者文件稍后变得不可访问,都始终尝试打开文件。 |
--pid=<进程号> |
与“-f”选项连用,当指定的进程号的进程终止后,自动退出tail命令 |
--help |
显示指令的帮助信息 |
--version |
显示指令的版本信息 |
参考实例
默认显示某个文件尾部的后10行内容:tail 文件名
指定显示某个文件尾部的后5行内容: tail -n 5 文件名
指定显示某个文件尾部的后15个字节:tail -c 15 文件名
持续刷新显示某个文件尾部的后10行内容:tail -f /var/log/messages
10. grep——强大的文本搜索工具(global search regular expression and print out the line全局搜索正则表达式并打印出该行)
通常会将grep命令与正则表达式搭配使用,参数作为搜索过程中的补充或对输出结果的筛选,命令模式十分灵活。
与之容易混淆的是egrep命令和fgrep命令。如果把grep命令当作是标准搜索命令,那么egrep则是扩展搜索命令,等价于“grep -E”命令,支持扩展的正则表达式。而fgrep则是快速搜索命令,等价于“grep -F”命令,不支持正则表达式,直接按照字符串内容进行匹配。
语法格式: grep [参数] 文件
常用参数:
| -i | 忽略大小写 |
| -c | 只输出匹配行的数量 |
| -l | 只列出符合匹配的文件名,不列出具体的匹配行 |
| -n | 列出所有的匹配行,显示行号 |
| -h | 查询多文件时不显示文件名 |
| -s | 不显示不存在、没有匹配文本的错误信息 |
| -v | 显示不包含匹配文本的所有行 |
| -w | 匹配整词 |
| -x | 匹配整行 |
| -r | 递归搜索 |
| -q | 禁止输出任何结果,已退出状态表示搜索是否成功 |
| -b | 打印匹配行距文件头部的偏移量,以字节为单位 |
| -o | 与-b结合使用,打印匹配的词据文件头部的偏移量,以字节为单位 |
| -F | 匹配固定字符串的内容 |
| -E | 支持扩展的正则表达式 |
参考实例
搜索某个文件中,包含某个关键词的内容:grep root /etc/passwd
搜索某个文件中,以某个关键词开头的内容:grep ^root /etc/passwd
搜索多个文件中,包含某个关键词的内容:grep linuxprobe /etc/passwd /etc/shadow
搜索多个文件中,包含某个关键词的内容,不显示文件名称:grep -h linuxprobe /etc/passwd /etc/shadow
输出在某个文件中,包含某个关键词行的数量:grep -c root /etc/passwd /etc/shadow
搜索某个文件中,包含某个关键词位置的行号及内容:grep -n network anaconda-ks.cfg
搜索某个文件中,不包含某个关键词的内容:grep -v nologin /etc/passwd
搜索当前工作目录中,包含某个关键词内容的文件,未找到则提示:grep -l root *
搜索当前工作目录中,包含某个关键词内容的文件,未找到不提示:grep -sl root *
递归搜索,不仅搜索指定目录,还搜索其内子目录内是否有关键词文件:grep -srl root /etc
搜索某个文件中,精准匹配到某个关键词的内容(搜索词应与整行内容完全一样才会显示,有别于一般搜索):
grep -x cdrom anaconda-ks.cfg
搜索某个文件中,空行的数量:
grep -c ^$ anaconda-ks.cfg
判断某个文件中,是否包含某个关键词,通过返回状态值输出结果(0为包含,1为不包含),方便在Shell脚本中判断和调用:
grep -q linuxprobe anaconda-ks.cfg echo $? grep -q linuxcool anaconda-ks.cfg echo $?
7月12号——学习记录
11. rpm(RedHat Package Manager红帽软件包管理器)命令 – RPM软件包管理器
其功能是用于在Linux系统下对软件包进行安装、卸载、查询、验证、升级等工作。
语法格式:rpm [参数] 软件包
常用参数:
| -a | 查询所有的软件包 |
| -b或-t | 设置包装套件的完成阶段,并指定套件档的文件名称; |
| -c | 只列出组态配置文件,本参数需配合”-l”参数使用 |
| -d | 只列出文本文件,本参数需配合”-l”参数使用 |
| -e | 卸载软件包 |
| -f | 查询文件或命令属于哪个软件包 |
| -h | 安装软件包时列出标记 |
| -i | 安装软件包 |
| -l | 显示软件包的文件列表 |
| -p | 查询指定的rpm软件包 |
| -q | 查询软件包 |
| -R | 显示软件包的依赖关系 |
| -s | 显示文件状态,本参数需配合”-l”参数使用 |
| -U | 升级软件包 |
| -v | 显示命令执行过程 |
| -vv | 详细显示指令执行过程 |
参考实例
正常安装软件包:rpm -ivh cockpit-185-2.el8.x86_64.rpm
显示系统已安装过的全部RPM软件包:rpm -qa
查询某个软件的安装路径:rpm -ql cockpit
卸载某个通过RPM软件包安装的服务:rpm -evh cockpit
升级某个软件包:rpm -Uvh cockpit-185-2.el8.x86_64.rpm
12.find命令 – 根据路径和条件搜索指定文件
find命令的功能是根据给定的路径和条件查找相关文件或目录,可以使用的参数很多,并且支持正则表达式,结合管道符后能够实现更加复杂的功能,是系统管理员和普通用户日常工作必须掌握的命令之一。
find命令通常进行的是从根目录(/)开始的全盘搜索,有别于whereis、which、locate……等等的有条件或部分文件的搜索。对于服务器负载较高的情况,建议不要在高峰时期使用find命令的模糊搜索,会相对消耗较多的系统资源。
语法格式:find [路径] [参数]
常用参数:
| -name | 匹配名称 |
| -perm | 匹配权限(mode为完全匹配,-mode为包含即可) |
| -user | 匹配所有者 |
| -group | 匹配所有组 |
| -mtime -n +n | 匹配修改内容的时间(-n指n天以内,+n指n天以前) |
| -atime -n +n | 匹配访问文件的时间(-n指n天以内,+n指n天以前) |
| -ctime -n +n | 匹配修改文件权限的时间(-n指n天以内,+n指n天以前) |
| -nouser | 匹配无所有者的文件 |
| -nogroup | 匹配无所有组的文件 |
| -newer f1 !f2 | 匹配比文件f1新但比f2旧的文件 |
| -type b/d/c/p/l/f | 匹配文件类型(后面的字幕字母依次表示块设备、目录、字符设备、管道、链接文件、文本文件) |
| -size | 匹配文件的大小(+50KB为查找超过50KB的文件,而-50KB为查找小于50KB的文件) |
| -prune | 忽略某个目录 |
| -exec …… {}\; | 后面可跟用于进一步处理搜索结果的命令 |
参考实例
全盘搜索系统中所有以.conf结尾的文件: find / -name *.conf
在/etc目录中搜索所有大约1M大小的文件:find /etc -size +1M
在/home目录中搜索所有属于指定用户的文件:find /home -user linuxprobe
列出当前工作目录中的所有文件、目录以及子文件信息:find .
在/var/log目录下搜索所有指定后缀的文件,后缀不需要大小写: find /var/log -iname "*.log"
搜索当前工作目录中的所有近7天被修改过的文件:find . -mtime +7
全盘搜索系统中所有类型为目录,且权限为1777的目录文件:find / -type d -perm 1777
全盘搜索系统中所有类型为普通文件,且可以执行的文件信息:find / -type f -perm /a=x
全盘搜索系统中所有后缀为.mp4的文件,并删除所有查找到的文件:find / -name "*.mp4" -exec rm -rf {} \
13.startx(start X-windows)命令 – 初始化X-windows系统
功能是用于启动X-Windows系统。
X-Windows System也被称为X或X11,中文译为X窗口系统,
主要工作就是以图形方式显示软件窗口的系统,现在的GNOME和KDE桌面环境都是以X窗口系统为基础构建成的。
语法格式:startx [参数]
常用参数:
| — -depth <数字> | 指定颜色深度 |
| -m | 当未找到启动脚本时,启动窗口管理器 |
| -r | 当未找到启动脚本时,装入资源文件 |
| -w | 强制启动 |
| -x | 使用startup脚本启动X-windows会话 |
参考实例
以默认方式初始化启动X窗口系统:startx
指定以16位颜色深度启动X窗口系统:startx -- -depth 16
强制启动X窗口系统:startx -w
14.ps(process status)命令 – 显示进程状态
功能是用于显示当前系统的进程状态
使用ps命令可以查看到进程的所有信息,例如进程的号码、发起者、系统资源使用占比(处理器与内存)、运行状态等等。帮助我们及时的发现哪些进程出现”僵死“或”不可中断“等异常情况。
经常会与kill命令搭配使用来中断和删除不必要的服务进程,避免服务器的资源浪费。
语法格式:ps [参数]
常用参数:
| a | 显示现行终端机下的所有程序,包括其他用户的程序 |
| -A | 显示所有程序 |
| c | 显示每个程序真正的指令名称,而不包含路径 |
| -C <指令名称> | 指定执行指令的名称,并列出该指令的程序的状况 |
| -d | 显示所有程序,但不包括阶段作业管理员的程序 |
| e | 列出程序时,显示每个程序所使用的环境变量 |
| -f | 显示UID,PPIP,C与STIME栏位 |
| f | 用ASCII字符显示树状结构,表达程序间的相互关系 |
| g | 显示现行终端机下的所有程序,包括所属组的程序 |
| -G <群组识别码> | 列出属于该群组的程序的状况 |
| h | 不显示标题列 |
| -H | 显示树状结构,表示程序间的相互关系 |
| -j | 采用工作控制的格式显示程序状况 |
| -l | 采用详细的格式来显示程序状况 |
| L | 列出栏位的相关信息 |
| -m | 显示所有的执行绪 |
| n | 以数字来表示USER和WCHAN栏位 |
| -N | 显示所有的程序,除了执行ps指令终端机下的程序之外 |
| -p <程序识别码> | 指定程序识别码,并列出该程序的状况 |
| r | 只列出现行终端机正在执行中的程序 |
| -s <阶段作业> | 列出隶属该阶段作业的程序的状况 |
| s | 采用程序信号的格式显示程序状况 |
| S | 列出程序时,包括已中断的子程序资料 |
| -t <终端机编号> | 列出属于该终端机的程序的状况 |
| -T | 显示现行终端机下的所有程序 |
| u | 以用户为主的格式来显示程序状况 |
| -U <用户识别码> | 列出属于该用户的程序的状况 |
| U <用户名称> | 列出属于该用户的程序的状况 |
| v | 采用虚拟内存的格式显示程序状况 |
| -V或V | 显示版本信息 |
| -w或w | 采用宽阔的格式来显示程序状况 |
| x | 显示所有程序,不以终端机来区分 |
| X | 采用旧式的Linux i386登陆格式显示程序状况 |
| -y | 配合选项”-l”使用时,不显示F(flag)栏位,并以RSS栏位取代ADDR栏位 |
| --cols <每列字符数> | 设置每列的最大字符数 |
| --headers | 重复显示标题列 |
| --help | 在线帮助 |
| --info | 显示排错信息 |
| --lines <显示列数> | 设置显示画面的列数 |
参考实例
显示系统中全部的进程信息,含详细信息:ps aux
结合输出重定向,将当前进程信息保留备份至指定文件:ps aux > backup.txt
结合管道操作符,将当前系统运行状态中指定进程信息过滤出来:ps -ef | grep ssh
结合管道操作符,将当前系统运行状态中指定用户的进程信息过滤出来:ps -u root
结合管道操作符与sort命令,依据处理器使用量(第三列)情况降序排序:ps aux | sort -rnk 3
结合管道操作符与sort命令,依据内存使用量(第四列)情况降序排序:ps aux | sort -rnk 4
7月13号——学习记录
15.uname(Unix name)——显示系统内核信息
其功能是用于查看系统主机名、内核及硬件架构等信息。如果不加任何参数,默认仅显示系统内核名称,相当于-s参数。
语法格式:uname [参数]
常用参数:
| -a | 显示系统所有相关信息 |
| -m | 显示计算机硬件架构 |
| -n | 显示主机名称 |
| -r | 显示内核发行版本号 |
| -s | 显示内核名称 |
| -v | 显示内核版本 |
| -p | 显示主机处理器类型 |
| -o | 显示操作系统名称 |
| -i | 显示硬件平台 |
参考实例
显示系统内核名称:uname
显示系统所有相关信息(含内核名称、主机名、版本号及硬件架构):uname -a
显示系统内核版本号:uname -r
现在系统硬件架构:uname -i
16.df(Disk Free)——显示磁盘空间使用情况
其功能是用于显示系统上磁盘空间的使用量情况。
df命令显示的磁盘使用量情况含可用、已有及使用率等信息,
语法格式: df [参数] [对象磁盘/分区]
常用参数:
| -a | 显示所有系统文件 |
| -B <块大小> | 指定显示时的块大小 |
| -h | 以容易阅读的方式显示 |
| -H | 以1000字节为换算单位来显示 |
| -i | 显示索引字节信息 |
| -k | 指定块大小为1KB |
| -l | 只显示本地文件系统 |
| -t <文件系统类型> | 只显示指定类型的文件系统 |
| -T | 输出时显示文件系统类型 |
| -- -sync | 在取得磁盘使用信息前,先执行sync命令 |
参考实例
带有容量单位的显示系统全部磁盘使用量情况:df -h
带有容量单位的显示指定磁盘分区使用量情况:df -h devfs
显示系统中所有文件系统格式为xfs的磁盘分区使用量情况:df -t devfs
17.fdisk——管理磁盘分区
其功能是用于管理磁盘的分区信息
形象化:如果一套几百平米的房子内部没有墙壁,虽然看起来会很敞亮,但是各种声音、气味、物品会随意充斥在整个房子内,让人极不舒适,因此需要用墙壁按照功能进行划分,例如卧室、厕所、厨房、阳台等等。
fdisk命令可以用于对磁盘进行分区操作,用户可以根据实际情况进行合理划分,这样后期挂载和使用时会方便很多。
语法格式:fdisk [参数] [设备]
常用参数:
| -b | 指定每个分区的大小 |
| -l | 列出指定的外围设备的分区表状况 |
| -s | 将指定的分区大小输出到标准输出上,单位为区块 |
| -u | 搭配”-l”参数列表,会用分区数目取代柱面数目,来表示每个分区的起始地址 |
| -v | 显示版本信息 |
参考实例
查看当前系统的分区情况:fdisk -l
管理指定硬盘的分区: fdisk /dev/sda
18. lsblk(list block)——查看系统的磁盘使用情况
其功能是用于查看系统的磁盘使用情况
语法格式:lsblk [参数]
| -a | 显示所有设备 |
| -b | 以字节单位显示设备大小 |
| -d | 不显示 slaves 或 holders |
| -e | 排除设备 |
| -f | 显示文件系统信息 |
| -h | 显示帮助信息 |
| -i | 仅使用字符 |
| -m | 显示权限信息 |
| -l | 使用列表格式显示 |
| -n | 不显示标题 |
| -o | 输出列 |
| -P | 使用key=”value”格式显示 |
| -r | 使用原始格式显示 |
| -t | 显示拓扑结构信息 |
参考实例
显示系统中所有磁盘设备的使用情况信息:lsblk -a
显示系统中磁盘设备的归属及权限信息:lsblk -m
显示系统中所有SCSI类型的磁盘设备信息:lsblk -S
以列表格式显示磁盘设备信息,并且不显示标题:lsblk -nl
19. hdparm(hard disk parameters)——显示与设定硬盘的参数
其功能是用于显示与设定硬盘参数。
语法格式:hdparm [参数] 设备名
常用参数:
| -a | 设定读取文件时,预先存入块区的分区数 |
| -f | 将内存缓冲区的数据写入硬盘,并清空缓冲区 |
| -g | 显示硬盘的磁轨,磁头,磁区等参数 |
| -t | 评估硬盘读取效率 |
| -I | 直接读取硬盘所提供的硬件规格信息 |
| -X | 设定硬盘的传输模式 |
参考实例
显示指定硬盘的相关信息:hdparm /dev/sdb
仅显示指定硬盘的柱面、磁头和扇区数信息:hdparm -g /dev/sdb
评估指定硬盘的读取效率:hdparm -t /dev/sdb
读取指定硬盘所提供的硬件规格信息:hdparm -X /dev/sdb
7月15号
20. vgextend(volume group extend)——扩展卷组设备
其功能是用于扩展卷组设备。
LVM逻辑卷管理器技术具有灵活调整卷组与逻辑卷的特点,卷组可以在创建时规定物理卷的数量,亦可以在后期使用vgextend命令进行扩展。
语法格式:vgextend [参数] 卷组
常用参数:
| -d | 调试模式 |
| -t | 仅测试 |
参考实例
将指定的物理卷加入到卷组设备中:vgextend storage /dev/sdb
21.tftp(Trivial File Transfer Protocol简单文件传输协议)——上传及下载文件
功能是:基于TFTP协议进行的文件传输工作。
用户可以通过文字模式将文件上传至远程服务器,亦可以从服务器下载文件到本地主机。
属于轻量级的传输服务,不具备显示文件列表、断点续传等功能。
语法格式:tftp [参数] 主机
常用参数:
| connect | 连接到远程tftp服务器 |
| mode | 文件传输模式 |
| put | 上传文件 |
| get | 下载文件 |
| quit | 退出 |
| verbose | 显示详细的处理信息 |
| trace | 显示包路径 |
| status | 显示当前状态信息 |
| binary | 二进制传输模式 |
| ascii | ascii 传送模式 |
| rexmt | 设置包传输的超时时间 |
| timeout | 设置重传的超时时间 |
| help | 帮助信息 |
| ? | 帮助信息 |
参考实例
远程连接至指定服务器:tftp 192.168.10.10
下载远程指定服务器中的文件至本地工作目录 :get File1.txt
上传本地工作目录中某个文件至远程指定服务器:put File2.txt
退出登录某台远程服务器:quit
22. curl(CommandLine URL)——文件传输工具
其功能是用于在Shell终端界面中基于URL规则进行的文件传输工作。
curl是一款综合的传输工具,可以上传也可以下载,支持HTTP、HTTPS、FTP等三十余种常见协议
语法格式:curl [参数] 网址
常用参数:
| -o | 指定新的本地文件名 |
| -O | 保留远程文件的原始名 |
| -u | 通过服务端配置的用户名和密码授权访问 |
| -I | 打印HTTP响应头信息 |
| -u | 指定登录账户密码信息 |
| -A | 设置用户代理标头信息 |
| -b | 设置用户cookie信息 |
| -C | 支持断点续传 |
| -s | 静默模式,不输出任何信息 |
| -T | 上传文件 |
参考实例
获取指定网站的网页源码:curl https://www.linuxcool.com
下载指定网站中的文件:curl -O https://www.linuxprobe.com/docs/LinuxProbe.pdf
打印指定网站的HTTP响应头信息:curl -I https://www.linuxcool.com
下载指定文件服务器中的文件(用户名:linuxcool,密码:redhat):
curl -u linuxprobe:redhat ftp://www.linuxcool.com/LinuxProbe.pdf
23. fsck(filesystem check)——检查和修复文件系统
其功能是用于检查与修复文件系统,
若系统有过突然断电或磁盘异常的情况,建议使用fsck命令对文件系统进行检查与修复,以防数据丢失。
语法格式:fsck [参数] 文件系统
常用参数:
| -a | 自动修复文件系统 |
| -f | 强制检查 |
| -A | 依照/etc/fstab文件来检查全部文件系统 |
| -N | 不执行指令,仅列出实际执行会进行的动作 |
| -r | 采用互动模式,在执行修复时询问问题 |
| -R | 略过指定的文件系统不予检查 |
| -t | 指定要检查的文件系统类型 |
| -T | 执行fsck指令时,不显示标题信息 |
| -V | 显示指令执行过程 |
参考实例
检查是否的文件系统是否有损坏:fsck /dev/sdb
强制检查文件系统的损坏情况:fsck -f /dev/sdb
24. lprm(Remove jobs from the print queue)——从打印队列中移除工作
删除打印队列中的打印任务
尚未完成的打印机工作会被放在打印机贮列之中,这个命令可用来将未送到打印机的工作取消
语法格式:lprm [参数] [任务编号]
常用参数:
| -E | 与打印服务器连接时强制使用加密 |
| -P | 指定接受打印任务的目标打印机 |
| -U | 指定可选的用户名 |
参考实例
将打印机hpprint中的第102号任务移除:lprm -Phpprint 102
将第101号任务由预设打印机中移除:lprm 101
25.ftpwho——显示ftp会话信息
ftpwho命令用于显示当前所有以FTP登入的用户会话信息。
执行该命令可得知当前用FTP登入系统的用户有哪些人,以及他们正在进行的操作。
语法格式:ftpwho [参数]
常用参数:
| -h | 显示帮助信息 |
| -v | 详细模式,输出更多信息 |
参考实例
查询当前正在登录FTP 服务器的用户:ftpwho
在详细模式下,查询当前正在登录FTP 服务器的用户:ftpwho -v
显示帮助信息:ftpwho -h
7月16号
26.ssh——安全的远程连接服务器
ssh命令的功能是用于安全的远程连接服务器主机系统,作为openssh套件中的客户端连接工具,ssh命令可以让我们轻松的基于ssh加密协议进行远程主机访问,从而实现对远程服务器的管理工作。
语法格式: ssh [参数] 远程主机
常用参数:
| -1 | 强制使用ssh协议版本1 |
| -2 | 强制使用ssh协议版本2 |
| -4 | 强制使用IPv4地址 |
| -6 | 强制使用IPv6地址 |
| -A | 开启认证代理连接转发功能 |
| -a | 关闭认证代理连接转发功能 |
| -b |
使用本机指定的地址作为对位连接的源IP地址 |
| -C | 请求压缩所有数据 |
| -F<配置文件> | 指定ssh指令的配置文件,默认的配置文件为“/etc/ssh/ssh_config” |
| -f | 后台执行ssh指令 |
| -g | 允许远程主机连接本机的转发端口 |
| -i<身份文件> | 指定身份文件(即私钥文件) |
| -l<登录名> | 指定连接远程服务器的登录用户名 |
| -N | 不执行远程指令 |
| -o<选项> | 指定配置选项 |
| -p<端口> | 指定远程服务器上的端口 |
| -q | 静默模式,所有的警告和诊断信息被禁止输出 |
| -X | 开启X11转发功能 |
| -x | 关闭X11转发功能 |
| -y | 开启信任X11转发功能 |
参考实例
基于ssh协议,远程访问服务器主机系统:ssh 192.168.10.10
使用指定的用户身份登录远程服务器主机系统:ssh -l linuxprobe 192.168.10.10
登录远程服务器主机系统后执行一条命令:ssh 192.168.10.10 "free -m"
强制使用v1版本的ssh加密协议连接远程服务器主机:ssh -1 192.168.10.10
27. netstat(network statistics)——显示网络的状态
其功能是用于显示各种网络相关信息,例如网络连接状态、路由表信息、接口状态、NAT、多播成员等等。
语法格式:netstat [参数]
常用参数:
| -a | 显示所有连线中的Socket |
| -p | 显示正在使用Socket的程序识别码和程序名称 |
| -l | 仅列出在监听的服务状态 |
| -t | 显示TCP传输协议的连线状况 |
| -u | 显示UDP传输协议的连线状况 |
| -i | 显示网络界面信息表单 |
| -r | 显示路由表信息 |
| -n | 直接使用IP地址,不通过域名服务器 |
参考实例
显示系统网络状态中的所有连接信息:netstat -a
显示系统网络状态中的UDP连接信息:netstat -nu
显示系统网络状态中的UDP连接端口号使用信息:netstat -apu
显示网卡当前状态信息:netstat -i
显示网络路由表状态信息:netstat -r
找到某个服务所对应的连接信息:netstat -ap | grep ssh
28. dhclient(DHCP client)——动态获取或释放IP地址
其功能是用于动态获取或释放IP地址
使用dhclient命令前需要将网卡模式设置成DHCP自动获取,否则静态模式的网卡是不会主动向服务器获取如IP地址等网卡信息的。
语法格式:dhclient 参数 [网卡]
常用参数:
| -p | 指定dhcp客户端监听的端口号(默认端口号86) |
| -d | 总是以前台方式运行程序 |
| -q | 安静模式,不打印任何错误的提示信息 |
| -r | 释放ip地址 |
| -n | 不配置任何接口 |
| -x | 停止正在运行的DHCP客户端,而不释放当前租约,杀死现有的dhclient |
| -s | 在获取ip地址之前指定DHCP服务器 |
| -w | 即使没有找到广播接口,也继续运行 |
参考实例
通过指定网卡发起DHCP请求,获取网卡参数:dhclient ens160
释放系统中已获取的网卡参数:dhclient -r
向指定的服务器请求获取网卡参数:dhclient -s 192.168.10.10
手动停止执行dhclient服务进程:dhclient -x
29. ping——测试主机间网络的连通性
ping命令的功能是用于测试主机间网络连通性,
发送出基于ICMP传输协议的数据包,要求对方主机予以回复,若对方主机的网络功能没有问题且防火墙放行流量,则就会回复该信息,我们也就可得知对方主机系统在线并运行正常了。
不过值得我们注意的是Linux与Windows相比有一定差异,Windows系统下的ping命令会发送出去4个请求后自动结束该命令;而Linux系统则不会自动终止,需要用户手动按下组合键“Ctrl+c”才能结束,或是发起命令时加入-c参数限定发送个数。
语法格式:ping [参数] 目标主机
常用参数:
| -d | 使用Socket的SO_DEBUG功能 |
| -c | 指定发送报文的次数 |
| -i | 指定收发信息的间隔时间 |
| -I | 使用指定的网络接口送出数据包 |
| -l | 设置在送出要求信息之前,先行发出的数据包 |
| -n | 只输出数值 |
| -p | 设置填满数据包的范本样式 |
| -q | 不显示指令执行过程 |
| -R | 记录路由过程 |
| -s | 设置数据包的大小 |
| -t | 设置存活数值TTL的大小 |
| -v | 详细显示指令的执行过程 |
参考实例
测试与指定网站服务器之间的网络连通性(需手动按下“Ctrl+c”组合键结束命令):ping www.liunxcool.com
测试与指定网站服务器之间的网络连通性,发送请求包限定为4次:ping -c 4 www.linuxcool.com
测试与指定主机之间的网络连通性,发送3次请求包,每次间隔0.2秒,最长等待时间为3秒:
ping -c 3 -i 0.2 -W 3 192.168.10.10
30.ifconfig(network interfaces configuring网络接口配置)——显示或设置网络设备参数信息
其功能是用于显示或设置网络设备参数信息
语法格式:ifconfig [参数] [网卡设备]
常用参数:
| add<地址> | 设置网络设备IPv6的IP地址 |
| del<地址> | 删除网络设备IPv6的IP地址 |
| down | 关闭指定的网络设备 |
| up | 启动指定的网络设备 |
| IP地址 | 指定网络设备的IP地址 |
参考实例
显示系统的网络设备信息:ifconfig
对指定的网卡设备依次进行关闭和启动操作:fconfig ens160 down/up
对指定的网卡设备执行修改IP地址操作:ifconfig ens160 192.168.10.20 netmask 255.255.255.0
对指定的网卡设备执行修改MAC地址操作:
注意Linux系统中的MAC地址间隔符为冒号(:),而在Windows系统中间隔符为减号(-)
ifconfig ens160 hw ether 00:aa:bb:cc:dd:ee
对指定的网卡设备依次进行ARP协议关闭和开启操作:
ifconfig ens160 -arp
ifconfig ens160 arp
7月20号
31. mount——把文件系统挂载到目录
功能是用于把文件系统挂载到目录,文件系统指的是被格式化过的硬盘或分区设备,进行挂载操作后,用户便可以在挂载目录中使用硬盘资源了。
语法格式:mount [参数] [设备] [挂载点]
常用参数:
| -t | 指定挂载类型 |
| -l | 显示已加载的文件系统列表 |
| -h | 显示帮助信息并退出 |
| -V | 显示程序版本 |
| -n | 加载没有写入文件“/etc/mtab”中的文件系统 |
| -r | 将文件系统加载为只读模式 |
| -a | 加载文件“/etc/fstab”中描述的所有文件系统 |
参考实例
查看当前系统中已有的文件系统信息(可结合管道符与grep命令进行过滤):mount
挂载/etc/fstab文件中所有已定义的设备文件:mount -a
将光盘设备挂载到指定目录:mount /dev/cdrom /media/cdrom
强制以xfs文件系统挂载硬盘设备到指定目录:mount -t xfs /dev/sdb /disk
32. lspci(list PCI)——显示当前设备PCI总线设备信息
其功能是用于显示当前设备PCI总线设备信息。
语法格式:lspci [参数]
常用参数:
| -n | 以数字方式显示PCI厂商和设备代码 |
| -t | 以树状结构显示PCI设备的层次关系 |
| -b | 以总线为中心的视图 |
| -s | 仅显示指定总线插槽的设备和功能块信息 |
| -i | 指定PCI编号列表文件,不使用默认文件 |
| -m | 以机器可读方式显示PCI设备信息 |
参考实例
显示当前主机的所有PCI总线设备信息:lspci
以树状结构显示当前主机的所有PCI总线设备信息:lspci -t
33. MAKEDEV——建立设备
MAKEDEV是一个脚本程序, 用于在 /dev 目录下建立设备, 通过这些设备文件可以 访问位于内核的驱动程序。
MAKEDEV 脚本创建静态的设备节点,通常位于/dev目录下。
语法格式:MAKEDEV [参数]
常用参数:
| -v | 显示出执行的每一个动作 |
| -n | 并不做真正的更新, 只是显示一下它的执行效果 |
| -d | 删除设备文件 |
参考实例
显示出执行的每一个动作: ./MAKEDEV -v update
删除设备: ./MAKEDEV -d device
34. sensors——检测服务器硬件信息
sensors命令用于检测服务器硬件信息,例如CPU电压与温度、主板、风扇转速等数据。
语法格式:sensors
参考实例
检查当前CPU处理器得电压和温度信息: sensors
35. setleds——设定键盘上方三个 LED 的状态
设置LED灯,setleds命令用来设定键盘上方三个 LED 灯的状态。在 Linux 中,每一个虚拟主控台都有独立的设定。
语法格式:setleds [参数]
常用参数:
| -F | 设定虚拟主控台的状态 |
| -D | 改变虚拟主控台的状态和预设的状态 |
| -L | 直接改变 LED 显示的状态 |
| +num/-num | 将数字键打开或关闭 |
| +caps/-caps | 把大小写键打开或关闭 |
| +scroll /-scroll | 把选项键打开或关闭 |
参考实例
控制键盘灯num灯亮和灯灭:setleds +num / -num
控制键盘的大小写键打开或关闭,键盘指示灯亮与灭:setleds +caps / -caps
控制键盘的选项键打开或关闭,键盘指示灯亮与灭: setleds +scroll / -scroll
对三灯的亮与灭的情况进行组合,分别设置为数字灯亮,大小写灯灭,选项键scroll灯灭:
setleds +num -caps -scroll
7月21号
36. zip——压缩文件
zip命令的功能是用于压缩文件,解压命令为unzip。通过zip命令可以将文件打包成.zip格式的压缩包,里面会附含文件的名称、路径、创建时间、上次修改时间等等信息,与tar命令相似。
语法格式:zip 参数 文件
常用参数:
| -q | 不显示指令执行过程 |
| -r | 递归处理,将指定目录下的所有文件和子目录一并处理 |
| -z | 替压缩文件加上注释 |
| -v | 显示指令执行过程或显示版本信息 |
| -d | 更新压缩包内文件 |
| -n<字尾字符串> | 不压缩具有特定字尾字符串的文件 |
参考实例
将指定目录及其内全部文件都打包成zip格式压缩包文件:zip -r backup1.zip /etc
将当前工作目录内所有以.cfg为后缀的文件打包:zip -r backup2.zip *.cfg
更新压缩包文件中某个文件:zip -dv backup2.zip anaconda-ks.cfg
37. unzip ——解压缩zip格式文件
unzip命令用于解压缩zip格式文件,虽然Linux系统中更多的使用tar命令进行对压缩包的管理工作,但有时也会收到同Windows系统常用的.zip和.rar格式的压缩包文件,unzip格式便派上了用场。直接使用unzip命令解压缩文件后,压缩包内原有的文件会被提取并输出保存到当前工作目录下。
语法格式:unzip [参数] 压缩包
常用参数:
| -l | 显示压缩文件内所包含的文件 |
| -v | 执行时显示详细的信息 |
| -c | 将解压缩的结果显示到屏幕上,并对字符做适当的转换 |
| -n | 解压缩时不要覆盖原有的文件 |
| -j | 不处理压缩文件中原有的目录路径 |
参考实例
将压缩包文件解压到当前工作目录中:unzip latest.zip
将压缩包文件解压到指定的目录中:unzip latest.zip -d /home
测试压缩包文件是否完整,文件有无损坏:unzip -t latest.zip
38. gzip——压缩和解压文件
gzip命令来自于英文单词gunzip的缩写,其功能是用于压缩和解压文件。gzip是一款使用广泛的压缩工具,文件经过压缩后一般会以.gz后缀结尾,与tar命令合用后即为.tar.gz后缀。
语法格式:gzip [参数] 文件
常用参数:
| -a | 使用ASCII文字模式 |
| -d | 解开压缩文件 |
| -f | 强行压缩文件 |
| -k | 保留原文件 |
| -l | 列出压缩文件的相关信息 |
| -c | 把压缩后的文件输出到标准输出设备,不去更动原始文件 |
| -r | 递归处理,将指定目录下的所有文件及子目录一并处理 |
| -q | 不显示警告信息 |
参考实例
将指定的文件进行压缩,压缩包默认会以“原文件名.gz”保存到当前工作目录下,原文件会被自动删除:gzip anaconda-ks.cfg
解压指定的压缩包文件,并显示解压过程。解压后的文件会保存在当前工作目录下,压缩包会被自动删除:gzip -dv anaconda-ks.cfg.gz
将指定的文件进行压缩,但是不删除原文件: gzip -k initial-setup-ks.cfg
显示指定文件的压缩信息:gzip -l initial-setup-ks.cfg.gz
39. zipinfo(zip information)——查看压缩文件信息
其功能是用于查看压缩文件信息。zipinfo命令可以查看zip格式压缩包内的文件列表及详细信息。
语法格式:zipinfo [参数] 压缩包
常用参数:
| -1 | 只列出文件名称 |
| -h | 只列出压缩文件名称 |
| -l | 列出原始文件的大小 |
| -m | 列出每个文件的压缩率 |
| -M | 以分页形式显示内容 |
| -s | 列出压缩文件内容 |
| -t | 列出压缩前后大小及压缩率 |
| -T | 列出每个文件的日期时间 |
| -v | 详细显示每一个文件的信息 |
| -x<范本样式> | 不列出符合条件的文件的信息 |
| -z | 将注释显示出来 |
参考实例
显示压缩包内的文件名称及简要属性信息:zipinfo file.zip
显示压缩包内的文件名称及详细属性信息:zipinfo -v file.zip
仅显示压缩包内文件大小及数目信息:zipinfo -h file.zip
仅显示压缩包内文件最后修改时间及简要属性信息:zipinfo -T file.zip
40. gunzip(Gnu unzip)——解压提取文件内容
其功能是用于解压提取文件内容。gunzip通常被用来解压那些被基于gzip格式压缩过的文件,也就是那些.gz结尾的压缩包。
语法格式:gunzip [参数] 压缩包
常用参数:
| -a | 使用ASCII文字模式 |
| -c | 把解压后的文件输出到标准输出设备 |
| -f | 强行解开压缩文件,不理会文件名称或硬连接是否存在以及该文件是否为符号连接 |
| -h | 在线帮助 |
| -l | 列出压缩文件的相关信息 |
| -L | 显示版本与版权信息 |
| -n | 解压缩时,若压缩文件内含有远来的文件名称及时间戳记,则将其忽略不予处理 |
| -N | 解压缩时,若压缩文件内含有原来的文件名称及时间戳记,则将其回存到解开的文件上 |
| -q | 不显示警告信息 |
| -r | 递归处理,将指定目录下的所有文件及子目录一并处理 |
| -S<压缩字尾字符串> | 更改压缩字尾字符串 |
| -t | 测试压缩文件是否正确无误 |
| -v | 显示指令执行过程 |
| -V | 显示版本信息 |
参考实例
解压指定的压缩包文件:gunzip Filename.gz
解压指定的压缩包文件,并输出解压过程:gunzip -v Filename.gz
测试指定的压缩包文件内容是否损坏,能够正常解压:gunzip -t Filename.gz
41. rmdir(remove directory)——删除空目录文件
其功能是用于删除空目录文件。rmdir命令仅能够删除空内容的目录文件,如需删除非空目录时,则需要使用带有-R参数的rm命令进行操作。
而rmdir命令的-p递归删除操作亦不意味着能删除目录中已有的文件,而是要求每个子目录都必须是空的。
语法格式 : rmdir [参数] 目录
常用参数:
| -p | 用递归的方式删除指定的目录路径中的所有父级目录,非空则报错 |
| -v | 显示命令的详细执行过程 |
| -- -- help | 显示命令的帮助信息 |
| -- -- version | 显示命令的版本信息 |
参考实例
删除指定的空目录:rmdir Documents
删除指定的空目录,及其内的子空目录:rmdir -p Documents
删除指定的空目录,并显示删除的过程:rmdir -v Documents
7月22号
42 ssh——管理命令运行时查询的哈希表
其功能是用于管理命令运行时查询的哈希表,
如果不加任何参数,则会默认输出路径列表的信息,这份列表会包含先前hash命令调用找到的Shell环境中命令的路径名。
语法格式: hash [参数] [目录]
常用参数:
| -d | 在哈希表中清除记录 |
| -l | 显示哈希表中的命令 |
| -p<指令> | 将具有完整路径的命令加入到哈希表中 |
| -r | 清除哈希表中的记录 |
| -t | 显示哈希表中命令的完整路径 |
参考实例
显示哈希表中的命令:hash -l
删除哈希表中的命令:hash -r
向哈希表中添加命令:hash -p /usr/sbin/adduser myadduser
在哈希表中清除记录:hash -d
43. wait——等待指令执行完毕
wait命令的功能是用于等待指令执行完毕,常被用于Shell脚本中,用于等待某个指令执行结束后返回终端,然后才会继续执行后面的指令。
例如有个服务进程PID为12345,那么此时可以用“wait 12345”来持续等待此进程的结束,一旦进程结束则会将返回值输出到终端界面。
语法格式:wait 进程号/作业号
常用参数:
| NUM 或%NUM | 进程号 或 作业号 |
参考实例
等待执行的进程结束并输出返回值:wait 12345
44. bc(binary calculator二进制计算器)——数字计算器
其功能是用于数字计算。Bash解释器仅能够进行整数计算,而不支持浮点运算,因此有时要用到bc命令进行高精度的数字计算工作。
语法格式:bc [选项]
常用参数:
| -i | 强制进入交互式模式 |
| -l | 定义使用的标准数学库 |
| -w | 定义使用的标准数学库 |
| -q | 打印正常的GNU bc环境信息 |
参考实例
计算得出指定的浮点数乘法结果:
bc
1.2345*3
3.7035
设定计算精度为小数点后3位,取浮点数除法结果:
bc
scale=3
3/8
.375
分别计算整数的平方与平方根结果:
bc
10^10
10000000000
sqrt(100)
10.000
45. history——显示与管理历史命令记录
功能是用于显示与管理历史命令记录,Linux系统默认会记录用户所执行过的所有命令,可以使用history命令查阅它们,也可以对其记录进行修改和删除操作。
语法格式: history [参数]
常用参数:
| -a | 写入命令记录 |
| -c | 清空命令记录 |
| -d | 删除指定序号的命令记录 |
| -n | 读取命令记录 |
| -r | 读取命令记录到缓冲区 |
| -s | 将指定的命令添加到缓冲区 |
| -w | 将缓冲区信息写入到历史文件 |
参考实例
显示执行过的全部命令记录:history
显示执行过的最近5条命令:history 5
将本次缓存区信息写入到历史文件中(~/.bash_history):history -w
将历史文件中的信息读入到当前缓冲区中:history -r
将本次缓冲区信息追加写入到历史文件中(~/.bash_history):history -a
清空本次缓冲区及历史文件中的信息:history -c
46. wget(web get)——下载网络文件
功能是用于从指定网址下载网络文件。
wget命令非常稳定,一般即便网络波动也不会导致下载失败,而是不断的尝试重连,直至整个文件下载完毕。
wget命令支持如HTTP、HTTPS、FTP等常见协议,可以在命令行中直接下载网络文件。
语法格式: wget [参数] 网址
常用参数:
| -V | 显示版本信息 |
| -h | 显示帮助信息 |
| -b | 启动后转入后台执行 |
| -c | 支持断点续传 |
| -O | 定义本地文件名 |
| -e <命令> | 执行指定的命令 |
| --limit-rate=<速率> | 限制下载速度 |
参考实例
下载指定的网络文件:wget https://www.linuxprobe.com/docs/LinuxProbe.pdf
下载指定的网络文件,并定义保存在本地的文件名称:wget -O Book.pdf https://www.linuxprobe.com/docs/LinuxProbe.pdf
下载指定的网络文件,限速最高每秒300k:wget --limit-rate=300k https://www.linuxprobe.com/docs/LinuxProbe.pdf
启用断点续传技术下载指定的网络文件:wget -c https://www.linuxprobe.com/docs/LinuxProbe.pdf
下载指定的网络文件,将任务放至后台执行:wget -b https://www.linuxprobe.com/docs/LinuxProbe.pdf
Linux命令行
7月24号
4.探究操作系统
ls——列出目录内容
file——确定文件类型
less——浏览文件内容
4.1——ls
这是用户最常使用的命令。可以知道目录的内容,以及各种各样重要文件和目录的属性。
1.除了当前工作的目录以外,也可以指定别的目录,ls /usr, ls /usr/local/bin, ls /usr/local
2.还可以列出多个指定的目录的内容: ls ~ /usr 将会列出用户家目录(~)和 /usr 目录的内容。
3. 还可以改变输出格式,结果以长模式输出 ls -l
4.2 选项和参数
语法: command -options arguments
大多数命令是如何工作的?
命令名经常会带有一个或多个用来更正命令行为的选项,选项后面会带有一个或多个参数。
这些参数是命令做作用的对象。
大多数命令的选项,是由一个中划线加上一个字符组成。例如: "-l"
ls -lt 有两个选项,l 选项产生长格式输出, t 选项按文件修改时间的先后来排序。
ls -lt --reverse 加上长选项,则结果会以相反的顺序输出。
-a (--all):列出所有文件以及被隐藏的文件。
-d(--directory): 列出目录
-l 结果以长格式输出
-r(--reverse):以相反的顺序显示结果
-t 按照修改时间来排序
-S 按照文件大小来排序
4.3 深入研究长格式输出
drwx------@ 28 mac staff 896 7 23 23:00 Desktop
drwx------+ 29 mac staff 928 7 23 13:52 Downloads
drwxr-xr-x 15 mac staff 480 7 10 23:18 PycharmProjects
drwx------@ 4 mac staff 128 6 24 13:26 Applications
drwxr-xr-x 2 mac staff 64 6 19 12:33 packages
drwx------@ 83 mac staff 2656 6 11 16:50 Library
drwxr-xr-x 2 mac staff 64 6 1 16:26 learnggit
drwx------+ 5 mac staff 160 5 23 17:47 Documents
-rwxr-xr-x 1 mac staff 59 5 18 21:05 hello_world
drwxr-xr-x 4 mac staff 128 5 18 20:56 bin
-rwxr-xr-x 1 mac staff 59 5 18 20:54 hello_world~
drwxr-xr-x 2 mac staff 64 5 18 20:42 sbin
-rw-r--r-- 1 mac staff 59 5 18 20:35 hello_world.txt~
drwxr-xr-x 2 mac staff 64 5 17 19:08 src
-rw-r--r-- 1 mac staff 0 5 16 17:38 fmt-info.txt
-rw-r--r-- 1 mac staff 0 5 16 17:38 fmt-code.txt
-rw-r--r-- 1 mac staff 403 5 16 17:34 fmt-info.txt~
-rw-r--r-- 1 mac staff 0 5 14 20:50 foo.txt
-rw-r--r-- 1 mac staff 124 5 14 20:45 distros.sde
-rw-r--r-- 1 mac staff 145 5 14 20:44 distros.sde~
-rw-r--r-- 1 mac staff 93 5 14 20:36 distros.sed
-rw-rw-rw- 1 mac staff 65502 5 13 19:28 ls-output.txt
-rw-r--r-- 1 mac staff 116 5 13 19:22 distros.txt看一下各个输出字段的含义:
-rw-r--r-- :文件的访问权限。从前往后介绍第一个是:文件的类型:普通文件(—)d表示目录文件,后面的三个字符使是文件所用者的访问权限,再后面的三个字符是文件所属组中成员的访问权限,最后三个字符是其他所有人的访问权限。
数字1: 文件的硬链接数目。
mac:文件所有者的用户名。
staff: 文件所属用户组的名字。
116:以字节数表示的文件大小。
05-13:上次修改文件的日期和时间。
ls-output.txt:文件名。
4.4 确定文件类型——file
file filename
4.5 用 less 浏览文件内容
用来浏览文本文件的程序。
less filename
例如要查看一个定义了系统中全部用户身份的文件: less /etc/passwd
Page UP or b 向上翻滚一页
Page Down or space 向下翻滚一页
UP Arrow 向上翻滚一行
Down Arrow 向下翻滚一行
G 移动到最后一行
1G or g 移动到开头一行
/charaters 向前查找指定的字符串
n 向前查找下一个出现的字符串,这个字符串是 之前所指定查找的
h 显示帮助屏幕
q 退出 less 程序
和less相反的是more
/ 根目录
/bin 包含系统启动和运行所必须的二进制程序。
/dev 设备目录.
/etc 包含所有系统层面的配置文件.
/etc/crontab定义自动运行的任务。
/etc/fstab,包含存储设备的列表,以及与他们相关的挂载点。
/etc/passwd包含用户帐号列表。
/home 在通常的配置环境下,系统会在/home 下,给每个用户分配 一个目录。
/lib 包含核心系统程序所使用的共享库文件
/root root 帐户的家目录
/sbin 包含“系统”二进制文件
/tmp 存储由各种程序创建的临时文件的地方
/usr 在 Linux 系统中,/usr 目录可能是最大的一个,包含普通用户所需要的所有程序和文件。
/usr/bin 包含系统安装的可执行程序
/usr/lib 包含由/usr/bin 目录中的程序所用的共享库。
/usr/local 源码编译的程序会安装在/usr/local/bin 目录下
/var 存放的是动态文件
/var/log 包含日志文件、各种系统活动的记录.
4.8 符号链接
在我们到处查看时,我们可能会看到一个目录,列出像这样的一条信息:
这是一个特殊文件,叫做符号链接(软连接)。
lrwxrwxrwx 1 root root 11 2007-08-11 07:34 libc.so.6 -> libc-2.6.so
这个符号链接指向一个叫做“libc-2.6.so”的共享库(/lib)文件。这意味着,寻找文件“libc.so.6”的 程序,实际上得到是文件“libc-2.6.so”。
4.9 硬链接
硬链接同样允许文件有 多个名字,但是硬链接以不同的方法来创建多个文件名。
5.操作文件和目录
cp——复制文件和目录
mv——移动/重命名文件和目录
mkdir——创建目录
rm——删除文件和目录
ln——创建硬链接和符号链接
5.1通配符
shell提供了特殊字符来帮助你快速指定一组文件名。这些特殊字符叫做通配符。
先介绍第一种类型——通配符:
1. *(星号):匹配任意一个字符(包括0个或一个)
2. ?(问号):不包括0个同上
3. [characters] :匹配任意一个属于字符集的字符。
[!characters]相反。
4.[[:class:]] :匹配任意一个属于指定字符集类中的字符。
第二种类型——字符类
[:alnum:]:匹配任意一个字母和数字
[:alpha:]:字母
[:digit:]:数字
[:lower:]:小写字母
[:upper:]:大写字母
第三种——通配符的例子
* :所有文件
g* :文件名以g开头的文件
b*.txt:这里有三层意思:1.以b开头的,2.中间有0个或任意多个字符,3.以.txt结尾的文件。
Data??? : 以Data开头,后面紧接着3个字符的文件。
[abc]* :文件名以 a b 或 c开头的文件。
BACKUP.[0-9][0-9][0-9]:以BACKUP开头,并紧接着3个数字的文件
[[:upper:]]* :以大写字母开头的文件。
[![:digit:]]* :不以数字开头的文件
*[[:lower:]123] : 文件名以小写字母结尾,或以 1 2 3结尾的文件
5.2 mkdir——创建目录
语法: mkdir directory...
后面的点代表参数可以重复
mkdir dir1 dir2 dir3 ——会创建三个目录 dir1 dir2 dir3
5.3 cp —— 复制文件和目录
两种使用方法:1. cp item1 item2 复制单个文件和目录 item1到文件或目录item2
2. cp item... directory 复制多个文件或目录到同一个目录下。
5.4 有用的选项(短选项和长选项)和实例
cp选项:
-a --archive(归档,档案)复制文件和目录,以及它们的属性,包括所有权和权限
-i --interactive(交互的)在重写已存在文件之前,提示用户确认
-r --recursive(递归)递归地复制目录及目录中的内容
-u --update 当把文件从一个目录复制到另一个目录时,仅复制目标目录中不存在的文件,或者是文件内容新于目标目录中已经存在的文件。
-v --verbose 显示详细的信息
cp实例:
cp file1 file2: 复制文件file1内容到文件file2。如果 file2 已经存在,file2 的内容会被 file1 的内容重写。如果 file2 不存在,则会创建 file2。
cp -i file1 file2:同上,提示用户确认。
cp file1 file2 dir1: 复制文件file1和文件file2 到目录dir1。目录dir1必须存在。
cp dir1/*dir2: 使用一个通配符,在目录dir1中的所有文件都被复制到目录dir2中。dir2必须存在。
cp -r dir1 dir2:复制目录dir1中的内容到目录dir2。如果目录dir2不存在,创建目录dir2,操作完成后,目录dir2中的内容和dir1中的一样。如果目录dir2存在,则目录dir1(和目录中的内容)将会被复制到dir2中。
5.5 mv ——移动和重命名文件
语法:mv item1 item2
把文件或目录 item1 移动或重命名为 item2或者:
mv item... directory 把一个或多个条目从一个目录移动到另一个目录中。
5.6 有用的选项和实例
mv 与 cp 共享了很多一样的选项:
mv 选项:
-i --interactive:在重写一个已经存在的文件之前,提示用户确认信息。如果 不指定这个选项,mv 命令会默认重写文件内容。
-u --update: 当把文件从一个目录移动另一个目录时,只是移动不存在的文件,或者文件内容新于目标目录相对应文件的内容。
-v --verbose :显示详细的信息
mv 实例:
mv file1 file2: 移动 file1 到 file2。如果 file2 存在,它的内容会被 file1 的 内容重写。如果 file2 不存在,则创建 file2。这两种情况下, file1 都不再存在。
mv -i file1 file2 : 除了如果 file2 存在的话,在 file2 被重写之前,用户会得到 提示信息外,这个和上面的选项一样。
mv file1 file2 dir1: 移动 file1 和 file2 到目录 dir1 中。dir1 必须已经存在。
mv dir1 dir2:如果目录 dir2 不存在,创建目录 dir2,并且移动目录 dir1 的内容到目录 dir2 中,同时删除目录 dir1。如果目录 dir2 存在,移动目录 dir1(及它的内容)到目录 dir2。
5.7 rm——删除文件和目录
rm 命令用来移除(删除)文件和目录:
rm item... item代表一个或多个文件和目录。
7月25号
5.8. 有用的选项和文档
rm选项:
-i interactive 在删除已存在的文件前,提示用户确认信息。
-r --recursive 递归删除文件,要是删除一个目录,而此目录又包含子目录,那么子目录也会被删除。
-f --force 忽视不存在的文件,不显示提示信息。
-v --verbose 显示详细的信息
rm实例:
rm file1 删除文件file1
rm -i file1 在删除文件之前,提示用户确认信息
rm -r file1 dir1 删除文件file1,目录dir1,以及目录中的内容
rm -rf file1 dir1 这个有两层含义:首先同上面的一样,其次,如果文件file1或目录dir1不存在的话,rm仍会继续执行。
注意小心使用rm。
举个例子: 如果想删除以点html结尾的所有文件,则输入 rm*.html这个是没有问题的,但是如果在*和.之间多加了一个空格,则会删除目录中的所有文件,还会提示没有找到以.html结尾的文件。
所以在使用带有通配符的rm命令时,要先检查输入的是否有错误,可以先使用ls来测试通配符,看一下要删除的文件是什么,最后返回再使用rm删除文件。
5.9 ln——创建链接
ln命令即可创建硬链接也可创建符号链接。
ln file link ——创建硬链接·
ln -s item link——创建符号链接 item可以是文件或者目录
5.10 硬链接
最初Unix创建链接的方式。
局限性:1.硬链接不能关联文件系统之外的文件。
2. 一个硬链接不能关联一个目录。
5.11 符号链接
创建符号链接是为了克服硬链接的局限性。
1.符号链接生效,是通过创建一个特殊类型的文件, 这个文件包含一个关联文件或目录的文本指针。
2.一个符号链接指向一个文件,而且这个符号链接本身与其它的符号链接几乎没有区别。
5.12 创建游戏场(实战演习)
第一:我们需要一个工作目录。在我们的家目录下创建一个叫做“playgame”的目录。
mkdir playgame在 playgame 目录下创建一对目录,分别叫做“dir1”和 “dir2”。更改我们的当前工作目录到 playgame,然后执行 mkdir 命令:
cd playgame
mkdir dir1 dir2
ls
dir1 dir2第二:复制文件
下一步,让我们输入一些数据到我们的游戏场中。我们可以通过复制一个文件来实现目的。
我们使用 cp 命令从 /etc 目录复制 passwd 文件到当前工作目录下:
cp /etc/passwd .请注意,我们使用命令末尾的一个圆点来简化当前工作目录的写法。如果我们执行 ls 命令, 可以看到我们的文件:
ls -l
total 16
drwxr-xr-x 2 mac staff 64 7 25 15:17 dir1
drwxr-xr-x 2 mac staff 64 7 25 15:17 dir2
-rw-r--r-- 1 mac staff 7868 7 25 15:18 passwd现在,仅仅是为了高兴,重复操作复制命令,使用 “-v” 选项(详细),看看它做了些什么:
cp -v /etc/passwd .
/etc/passwd -> ./passwdcp 命令再一次执行了复制操作,但是这次显示了一条简洁的信息,指明它进行了什么操作。
注意,cp 没有警告,就重写了第一次复制的文件。这是一个案例,cp 会假设你知道自己在做什 么。如果希望得到警告的话,需要加入“-i”(互动)选项:
cp -i /etc/passwd .
overwrite ./passwd? (y/n [n]) y在提示信息后输入 “y”,文件就会被重写,输入其它的字符(例如,”n”)cp 命令会保留原文件。
5.14 移动和重命名文件
现在,“passwd” 这个名字,看起来不怎么有趣,这是个游戏场,所以我们给它改个名字:
mv passwd fun
把fun文件移动到dir1文件
mv fun dir1
再把 fun 文件从 dir1 移到目录 dir2, 然后:
mv dir1/fun dir2
最后,再把 fun 文件带回到当前工作目录
mv dir2/fun .接下来,来看看移动目录的效果。首先,我们先 移动我们的数据文件到 dir1 目录:
mv fun dir1然后移动 dir1 到 dir2 目录,用 ls 来确认执行结果:
mv dir1 dir2
ls -l dir2
total 0
drwxr-xr-x 3 mac staff 96 7 25 15:34 dir1
ls -l dir2/dir1
total 16
-rw-r--r-- 1 mac staff 7868 7 25 15:20 fun注意:因为目录 dir2 已经存在,mv 命令会把 dir1 移动到 dir2 目录中。如果 dir2 不存在, mv 会把 dir1 重命名为 dir2。最后,让我们把所有的东西放回原处:
mv dir2/dir1 .
mv dir1/fun .5.15 创建硬链接
ln file link
ln fun fun-hard
ln fun dir1/fun-hard
ln fun dir2/fun-hard
所以现在,我们有四个文件 “fun” 的实例。看一下目录 playground 中的内容:
ls -l
total 32
drwxr-xr-x 3 mac staff 96 7 25 16:35 dir1
drwxr-xr-x 3 mac staff 96 7 25 16:35 dir2
-rw-r--r-- 4 mac staff 7868 7 25 15:20 fun
-rw-r--r-- 4 mac staff 7868 7 25 15:20 fun-hard注意到一件事,列表中,文件 fun 和 fun-hard 的第二个字段是 “4”,这个数字是文件 “fun” 的硬链接数目。你要记得一个文件至少有一个硬链接,因为文件名就是由链接创建的。
我们怎样知道实际上 fun 和 fun-hard 是同一个文件呢?
索引节点:索引节点与文件名字部分相关联,因此每一个硬链接都关系到一个具体的包含文件内容的索引节点。
ls 命令有一种方法,来展示(文件索引节点)的信息,在命令中加上 “-i” 选项:
ls -li
total 32
12890042027 drwxr-xr-x 3 mac staff 96 7 25 16:35 dir1
12890042028 drwxr-xr-x 3 mac staff 96 7 25 16:35 dir2
12890042045 -rw-r--r-- 4 mac staff 7868 7 25 15:20 fun
12890042045 -rw-r--r-- 4 mac staff 7868 7 25 15:20 fun-hard
5.16 创建符号链接
建立符号链接的目的是为了克服硬链接的两个缺点:
硬链接不能跨越物理设备,
硬链接不能关联目录,只能是文件。
符号链接是文件的特殊类型,它包含一个指向目标文件或目录的文本指 针。
ln -s fun fun-sym
ln -s ../fun dir1/fun-sym
ln -s ../fun dir2/fun-sym
ls -l dir1
total 16
-rw-r--r-- 4 mac staff 7868 7 25 15:20 fun-hard
lrwxr-xr-x 1 mac staff 6 7 25 16:50 fun-sym -> ../fun
第一个例子相当直接,在 ln 命令中,简单地加上 “-s” 选项就可以创建一个符号链接,而不 是一个硬链接。
记住,当我们创建一个符号链接的时候,会建立一个目标文件在哪里和符号链接有关联的文本描述.
目录 dir1 中,fun-sym 的列表说明了它是一个符号链接,通过在第一字段中的首字符 “l” 可知,并且它还指向 “../fun”,也是正确的。相对于 fun-sym 的存储位置,fun 在它的上一个目 录。
同时注意,符号链接文件的长度是 6,这是字符串 “../fun” 所包含的字符数,而不是符号 链接所指向的文件长度。
当建立符号链接时,你既可以使用绝对路径名,也可用相对路径名,使用相对路径名更令人满意,因为它允许一个 包含符号链接的目录重命名或移动,而不会破坏链接。
除了普通文件,符号链接也能关联目录:
ln -s dir1 dir1-sym
ls -l
total 32
drwxr-xr-x 4 mac staff 128 7 25 16:50 dir1
lrwxr-xr-x 1 mac staff 4 7 25 16:56 dir1-sym -> dir1
drwxr-xr-x 4 mac staff 128 7 25 16:50 dir2
-rw-r--r-- 4 mac staff 7868 7 25 15:20 fun
-rw-r--r-- 4 mac staff 7868 7 25 15:20 fun-hard
lrwxr-xr-x 1 mac staff 3 7 25 16:50 fun-sym -> fun
ls
dir1 dir1-sym dir2 fun fun-hard fun-sym
ls dir1
fun-hard fun-sym
5.17 删除文件和目录(rm)
我们将要使用它来清理一下我们的游戏场。首先,删除一个硬链接:
rm fun-hard
ls
dir1 dir1-sym dir2 fun fun-sym
ls -l
total 16
drwxr-xr-x 4 mac staff 128 7 25 16:50 dir1
lrwxr-xr-x 1 mac staff 4 7 25 16:56 dir1-sym -> dir1
drwxr-xr-x 4 mac staff 128 7 25 16:50 dir2
-rw-r--r-- 3 mac staff 7868 7 25 15:20 fun
lrwxr-xr-x 1 mac staff 3 7 25 16:50 fun-sym -> fun文件 fun-hard 消失了,文件 fun 的链接数从 4 减到 3,正如目录列表第二 字段所示。
下一步,我们会删除文件 fun,仅为了娱乐,我们会加入 “-i” 选项,看一看它的作用:
rm -i fun
remove fun? y
ls -l
total 0
drwxr-xr-x 4 mac staff 128 7 25 16:50 dir1
lrwxr-xr-x 1 mac staff 4 7 25 16:56 dir1-sym -> dir1
drwxr-xr-x 4 mac staff 128 7 25 16:50 dir2
lrwxr-xr-x 1 mac staff 3 7 25 16:50 fun-sym -> fun在提示符下输入 “y”,删除文件。让我们看一下 ls 的输出结果。注意,fun-sym 发生了什么 事? 因为它是一个符号链接,指向已经不存在的文件,链接已经坏了:
大多数 Linux 的发行版本配置 ls 显示损坏的链接。如果我们试着使用损坏的链接, 会看到以下情况:
less fun-sym
fun-sym: No such file or directory
稍微清理一下现场。删除符号链接:
rm fun-sym dir1-sym
ls -l
total 0
drwxr-xr-x 4 mac staff 128 7 25 16:50 dir1
drwxr-xr-x 4 mac staff 128 7 25 16:50 dir2对于符号链接,有一点值得记住,执行的大多数文件操作是针对链接的对象,而不是链接本 身。而 rm 命令是个特例。当你删除链接的时候,删除链接本身,而不是链接的对象。
最后,我们将删除我们的游戏场。为了完成这个工作,我们将返回到我们的家目录,然后用 rm 命令加上选项 (-r),来删除目录 playgame,和目录下的所有内容,包括子目录。
cd
rm -r playgame
cd playgame
cd: no such file or directory: playgame7月26号
第六章——使用命令
1.type ——解释一个命令名
2.which ——执行哪个可执行程序
3.man——命令手册页
4.apropos——一系列合适的命令
5.info——显示命令info
6.whatis——一个命令的简洁描述
7.alias——创建命令别名
6.1——到底什么是命令?
1.是一个可执行程序(exe):就像我们看见的位于目录下的 /usr/bin中的文件一样。
2.是一个内建的shell自身的命令(builtins):例如:cd命令就是一个shell的内部命令。
3.是一个shell函数:是一个小规模的shell脚本,混合到环境变量中。
4.是一个别名(alias):我们可以定义自己的命令,建立在其他命令之上。
6.2——识别命令
6.3——type显示命令的类型
语法:type command
type是shell的内部命令,它会显示命令的类别,给出一个特定的命令名(作为参数)。
type type
type is a shell builtin
type which
which is a shell builtin
type whatis
whatis is /usr/bin/whatis
type ls
ls is /bin/ls
type cp
cp is /bin/cp
type ls
ls is aliased to `ls --color=tty`
注意,ls 命令(在 Fedora 系统中)的检查结果,
ls 命令实际上是 ls 命令加上选项 “--color=tty” 的别名。
现在我们知道为什么 ls 的输出结果是有 颜色的!6.4——which显示一个可执行程序的位置
UNIX
which ls
/bin/ls
which type
type: shell built-in command
which cd
cd: shell built-in command
注意:这个命令只对可执行程序有效,不包括内建命令和命令别名。
当我们执行shell的内建命令时,类Unix会提示
which type
type: shell built-in command
which cd
cd: shell built-in command
像linux系统可能会得不到回应或者出现错误的信息。
linux
which cd
/usr/bin/which: no cd in
(/opt/jre1.6.0_03/bin:/usr/lib/qt-3.3/bin:/usr/kerberos/bin:/opt/jre1
.6.0_03/bin:/usr/lib/ccache:/usr/local/bin:/usr/bin:/bin:/home/me/bin)
说“命令没有找到”,真是很奇特。
rm -rf dir/*
rm -rf dir/
rm -rf dir6.5——得到命令文档
6.6——help得到shell内建命令的帮助文档
bash有一个内建的帮助命令,可供每一个shell内建命令的使用。输入”help“,接着是shell内部命令名。
[me@linuxbox ~]$ help cd
cd: cd [-L|-P] [dir]
Change ...
cd [-L|-P] [dir]
这种表示法说明,cd 命令可能有一个“-L”选项或者“-P”选项,进一步,可能有参数“dir”。6.7 --help 显示用法信息
许多可执行程序支持一个 --help 选项,这个选项是显示命令所支持的语法和选项说明。例如:
mkdir --help
mkdir: illegal option -- -
usage: mkdir [-pv] [-m mode] directory_name ...一些程序不支持 --help 选项,但不管怎样试一下。这经常会导致输出错误信息,但同时能 揭示一样的命令用法信息。
6.8 man——显示命令手册页
语法:man program(是要浏览的命令名)
例如:浏览一下 ls 命令的手册文档: man ls
手册的布局:(了解即可)

有时候,我们需要查看参考手册的特定章节,从而找到我们需要的信息。
man section search_term
man 5 passwd
命令运行结果会显示文件 /etc/passwd 的文件格式说明手册。6.9 apropos——显示适当的命令(把这个替换掉 man -k)
man 命令加上 “-k” 选项,和 apropos 完成一样的功能。
6.10 whatis ——显示非常简洁的命令说明
6.11 info ——显示程序info条目
输入 “info”,接着输入程序名称,启动 info。下表中的命令,当显示一个 info 页面时,用来 控制阅读器。
到目前为止,我们所讨论的大多数命令行程序,属于 GNU 项目 “coreutils” 包,所以输入:
[me@linuxbox ~]$ info coreutils6.12 README和其他程序文档
许多安装在你系统中的软件,都有自己的文档文件,这些文件位于/usr/share/doc 目录下
这 些文件大多数是以文本文件的形式存储的,可用 less 阅读器来浏览
6.13 用别名(alias)创建你自己的命令
可以把多个命令放在同一行上,命令之间用 “;” 分开。 它像这样工作:
command1; command2; command3...
例子:
cd /usr; ls; cd -
X11 bin libexec sbin standalone
X11R6 lib local share
~
首先更改目录到/usr,然后列出目录内容, 最后回到原始目录(用命令 “cd -”), 结束在开始的地方。
现在,通过 alias 命令把这一串命令 转变为一个命令。我们要做的第一件事就是为我们的新命令构想一个名字。比方说 “test”。在 使用”test” 之前,查明是否 “test” 命令名已经存在系统中,是个很不错的主意。为了查清此事, 可以使用 type 命令:
type test
test is a shell builtin
哦!“test” 名字已经被使用了。试一下”foo”:
mac@MacdeMacBook-Pro ~ % type foo
foo not found
太棒了!“foo” 还没被占用。创建命令别名:
alias foo='cd /usr; ls; cd -'
注意命令结构:
alias name='string'
mac@MacdeMacBook-Pro ~ % foo
X11 bin libexec sbin standalone
X11R6 lib local share
~
我们也可以使用 type 命令来查看我们的别名:
type foo
foo is an alias for cd /usr; ls; cd -
删除别名,使用 unalias 命令,像这样:
unalias foo
mac@MacdeMacBook-Pro ~ % foo
zsh: command not found: foo7月28号
第七章——重定向(I/O输入/输出重定向)
1.cat ——连接文件
2. sort ——排序文本行
3. uniq ——省略重复行(unique)
4. grep ——打印匹配行
5. wc ——打印文件中的换行符,字,和字节个数
6.head——输出文件第一部分(一般是指输出文件前十行)
7.tail ——输出文件最后一部分(最后十行)
8.tee ——从标准输入读取数据,并同时写到标准输出和文件
7.1 标准输入、输出和错误
输出类型:程序运行结果,即程序要完成的功能;输出的状态和错误信息,即程序进展。
7.2 标准输出重定向
使用 ”>“重定向符 后结文件名 将标准输出重定向 到除屏幕以外的 另一个文件。
例如:我们可以告诉shell 把ls 命令的运行结果输送到文件 ls-output.txt中去。
ls -l /usr/bin > ls-output.txt
这里我们创建了一个长长的目录/usr/bin列表,并且输送程序运行结果到文件ls-output.txt中。
ls -l ls-output.txt
-rw-rw-rw- 1 mac staff 60449 7 28 14:37 ls-output.txt
用less阅读器来查看这个文件,我们会看到文件ls-output.txt的确包含了ls命令的执行结果。
less ls-output.txt
现在把目录换成一个不存在的目录。
ls -l /bin/usr > ls-output.txt
ls: /bin/usr: No such file or directory
ls程序不把它的错误信息输送到标准输出。因为为我们只是重定向了标准输出,没有重定向标准错误,所以错误信息出现在屏幕上,而不是重定向文件ls-output.txt中。
ls -l ls-output.txt
-rw-rw-rw- 1 mac staff 0 7 28 14:42 ls-output.txt
这里文件长度为零,这是因为,当我们使用 > 重定向符来重定向输出结果时,目标文件总是从开头被重写。
当我们需要清空一个文件内容(或者创建一个新的空文件),可以使用:
> ls-output.txt
那么怎么样才能将重定向结果追加到文件内容后面?
使用 >> 重定向符。
ls -l /usr/bin >> ls-output.txt
ls -l ls-output.txt
-rw-rw-rw- 1 mac staff 60449 7 28 14:54 ls-output.txt
将输出结果添加到文件内容之后。
如果文件不存在,文件会被创建。
如果重复执行ls -l ls-output.txt三次,文件大小将是原先的三倍。
7.3 标准错误重定向
标准错误重定向没有专用的重定向操作符。这里参考文件描述符。
标准输入、输出和错误——在文件描述符里面代表0、1、2。
ls -l /bin/usr 2> ls-error.txt
ls -l ls-error.txt
-rw-r--r-- 1 mac staff 40 7 28 15:04 ls-error.txt
文件描述符2,紧挨着放在重定向操作符之前,来执行重定向标准错误到文件ls-error.txt。
7.4 重定向标准输出和错误到同一个文件
有两种方法来完成:
1.传统的方法,
ls -l /bin/usr > ls-output.txt 2>&1
ls -l ls-output.txt
-rw-rw-rw- 1 mac staff 40 7 28 15:11 ls-output.txt
这里完成了两个重定向,首先重定向到标准输出文件ls-output.txt,然后重定向到文件描述符2到文件描述符1
使用表示法 2>&1
注意重定向的顺序很重要。标准输出错误重定向必须总是出现在标准输出重定向之后。
第二找方法:
ls -l /bin/usr &> ls-output.txt
在这个例子里面,我们使用单单一个表示法 &> 来重定向标准输出和错误到文件 ls- output.txt。
7月29号
7.5 处理不需要的输出
/dev/null:叫做位存储桶,接受输入并且对输入不做任何处理。
ls -l /bin/usr 2> /dev/null
为了隐瞒命令错误信息7.6 标准输入重定向
到目前为止,我们还没有遇到一个命令是利用标准输入的,所以我们需要介绍一个。
7.7 cat ——连接文件
cat命令读取一个或多个文件,然后复制他们到标准输出。
cat [file]cat来显示文件而没有分页,例如:
cat ls-output.txt~
将会显示文件ls-output.txt~的内容
cat 可以用来把文件连接在一起。比如:下载了一个比较大的文件,这个文件被分离为多个部分,我们想要把这些分离的文件连接在一起,则如下:
cat movie.mpeg.0* > movie.mpeg
因为通配符总是以有序的方式展开,所以这些参数会以正确顺序安排。这和标准输入有什么关系?基本上没有什么关系。
看下面:如果我们输入不带参数的cat命令,会发生什么?
没有任何事情发生,它只坐在那里,好像挂掉一样。看起来是那样,但是它正在做他该做的事情:如果cat没有给出任何参数,它会从标准输入读入数据,又因为标准输入默认情况下连接到键盘,它正在等待着我们输入数据。
cat
7月29号天气晴,我正在学习Linux。
7月天气晴,我正在学习Linux。
下一步,输入 Ctrl-d(按住 Ctrl 键同时按下 “d”),来告诉 cat,在标准输入中,它已经到 达文件末尾(EOF):
创建一个叫做lazy_dog.txt的文件。
cat > lazy_dog.txt
The quick brown fox jumped over the lazy dog.
cat lazy_dog.txt
The quick brown fox jumped over the lazy dog.
cat 7.8 管道线
管道线使用 |(竖杠)
命令从标准输入读取数据并输送到标准输出。
command1 |command2
ls -l /usr/bin | less
7.9 过滤器
管道线经常用来对数据完成复杂的操作。有可能会把几个命令放在一起组成一个管道线。
通常,以这种方式使用的命令被称为过滤器。过滤器接受输入,以某种方式改变它,然后输出它。
ls /bin /usr/bin | sort | less
把目录 /bin 和 /usr/bin 中的可执行程序都联合在一起,再把他们排序,然后浏览执行结果。
ls 命令的输出结果由有序列表组成,各自针对一个目录。
包含sort,改变输出数据,产生一个有序列表。
7.10 uniq ——报道或忽略重复行
uniq经常和sort结合在一起使用。默认情况下,从数据列表中删除任何重复行。
uniq从标准输入或单个文件名参数接受数据有序列表。
使用uniq来删除任何重复行
ls /bin /usr/bin | sort | uniq | less
想看到重复的数据列表,让 uniq命令带上 -d选项
ls /bin /usr/bin | sort | uniq -d | less7.11 wc ——打印行数、字数和字节数
wc ls-output.txt~
1013 9320 65502 ls-output.txt~
wc 不带命令行参数,接受标准输入。
wc -l 只输出行数
wc -l ls-output.txt~
1013 ls-output.txt~
7.12 grep ——打印匹配行
grep 是个很强大的程序,用来找到文件中的匹配文件。
语法: grep pattern[file...]
例子:找到文件名包含单词 zip的所有文件
ls /bin /usr/bin | sort | uniq | grep zip
bunzip2
bzip2
bzip2recover
funzip
gunzip
gzip
unzip
unzipsfx
zip
zipcloak
zipdetails
zipdetails5.18
zipdetails5.30
zipgrep
zipinfo
zipnote
zipsplit
grep -i 忽略大小写
grep -v 只打印不匹配的行。
7.13 head/tail ——打印文件开头部分/结尾部分
head命令打印文件的前十行
tail打印文件的后十行
head -n 5 ls-output.txt~
tail -n 5 ls-output.txt~
head ls-output.txt~
tail ls-output.txt~
-n 选项来调整命令打印的行数
ls /usr/bin | tail -n 5
也可以用在管道线中
tail 有一个选项允许你实时地浏览文件。当观察日志文件的进展时,这很有用,因为他们同时再被写入。
cd /var/log
ls
tail -f /var/log/fsck_apfs.log
tail -f tail命令会继续检测这个文件,当新的内容添加到文件后,他们会立刻出现在屏幕上。
这会一直继续下去直到你输入 Ctrl-c。
7.14 tee ——从标准输入读取数据,并同时输出到标准输出和文件
ls /usr/bin | tee ls.txt | grep zip
Linux 提供了一个叫做 tee 的命令,这个命令制造了一个 “tee”,安装到我们的管道上。
在某个中间处理阶段来捕捉一个管道线的 内容时,这很有帮助。这里,我们重复执行一个先前的例子,这次包含 tee 命令,在 grep 过滤 管道线的内容之前,来捕捉整个目录列表到文件 ls.txt:7月30号
第八章 ——从shell眼中看世界
echo ——显示一行文本
8.1 (字符)展开
echo this is a test
this is a test
echo *
Applications Desktop Documents Downloads Library Movies Music Pics Pictures Public
这里列出部分输出内容
那为什么不是输出 * 呢?
shell在echo命令被执行前把 * 展开成了另外的东西(这里就是在当前工作目录下的文件名字。)
echo命令实际参数并不是 * ,而是它展开后的结果。
8.2 路径名展开
通配符所依赖的工作机制叫做路径名展开。
echo D*
Desktop Documents Downloads
echo *s
Applications Documents Downloads Movies Pics Pictures PycharmProjects Sunlogin Files packages sensors
echo [[:upper:]]*
Applications Desktop Documents Downloads Library Movies Music Pics Pictures Public PycharmProjects Sunlogin Files TEST
查看家目录之外的目录:
echo /usr/*/share
8.3 波浪线展开(~)
echo ~ 代表我们的家目录
/Users/mac
echo ~foo
8.4 算术表达式 展开
echo $((2+2))
$((expression))
算术表达式只支持整数(全部是数字,不带小数点)
算术操作符
+ 加
- 减
* 乘
/ 除
% 取余
** 取幂
echo $(((5**2) * 3))
echo five divided by two equals $((5/2))
five divided by two equals 2
echo with $((5%2)) left over
with 1 left over
8.5 花括号展开
echo front-{a,b,c}-back
front-a-back front-b-back front-c-back
花括号展开模式可能包含一个开头部分叫做报头,一个结尾部分叫做附言
花括号表达式本身可能包含一个由逗号分开的字符串列表,或者一个整数区间,或者单个的字符区间。
这种模式不能嵌入空白字符
整数区间
echo number_{1..5}
number_1 number_2 number_3 number_4 number_5
倒序排列的字母
echo {Z..A}
Z Y X W V U T S R Q P O N M L K J I H G F E D C B A
花括号可以嵌套
echo a{A{1,2},B{3,4}}b
aA1b aA2b aB3b aB4b
echo {2019..2022}-0{1..9} {2019..2022}-{10..12}
2019-01 2019-02 2019-03 2019-04 2019-05 2019-06 2019-07 2019-08 2019-09 2020-01 2020-02 2020-03 2020-04 2020-05 2020-06 2020-07 2020-08 2020-09 2021-01 2021-02 2021-03 2021-04 2021-05 2021-06 2021-07 2021-08 2021-09 2022-01 2022-02 2022-03 2022-04 2022-05 2022-06 2022-07 2022-08 2022-09 2019-10 2019-11 2019-12 2020-10 2020-11 2020-12 2021-10 2021-11 2021-12 2022-10 2022-11 2022-12
mkdir {2019..2022}-0{1..9} {2019..2022}-{10..12}
ls
8.6 参数展开
查看USER中的内容
echo $USER
mac
查看有效的变量列表
printenv | less
如果输入了一个错误的变量名,展开仍会进行,只是展开的结果是一个空字符串。
8.7 命令替换
命令替换允许我们把一个命令的输出作为一个展开模式来使用
echo $(ls)
Applications Desktop Documents Downloads Library Movies Music Pics Pictures Public
这仅展示部分输出内容
把which cp 的执行结果作为一个参数传递给ls命令,在不知道cp命令完整路径名的情况下得到他的文件属性列表。
ls -l $(which cp)
-rwxr-xr-x 1 root wheel 152672 5 10 05:30 /bin/cp
也可以使用整个管道线
file $(ls /usr/bin/* | grep zip)
/usr/bin/bunzip2: Mach-O universal binary with 2 architectures: [x86_64:Mach-O 64-bit executable x86_64
仅展示部分输出
管道线的输出结果成为file命令的参数列表。
8.8 引用
shell利用单词分隔删除掉echo命令的参数列表中多余的空格。
echo this is a test
this is a test
参数展开把$100的值替换为一个空字符串,因为1是没有定义的变量。
shell提供了一个叫做引用的机制,来有选择地禁止不需要的展开。
echo The total is $100.00
The total is .00
8.9 双引号
使用双引号,可以处理包含空格的文件。
ls -l two words.txt
ls: two: No such file or directory
ls: words.txt: No such file or directory
ls -l "two words.txt"
-rw-r--r-- 1 mac staff 710 7 30 20:01 two words.txt
使用双引号,可以阻止单词分隔,等到期望的结果。
进一步说,我们甚至可以修复破损的文件。
mv "two words.txt" two_words.txt
现在不用再使用双引号了。
在双引号中,参数展开、算术表达式展开和命令替换仍然有效。
echo "$USER $((2+2)) $(cal)"
mac 4 七月 2022
日 一 二 三 四 五 六
1 2
3 4 5 6 7 8 9
10 11 12 13 14 15 16
17 18 19 20 21 22 23
24 25 26 27 28 29 30
31
看一下单词分割是怎么工作的?
在之前的例子中,遇见过单词分隔机制是怎样来删除文本中额外空格的。
echo this is a test
this is a test默认情况下,单词分隔机制会在单词中寻找空格,制表符,和换行符,都把它们看做单词之间的界定符。这句话什么意思?意思是无引用的空格、制表符和换行符都不是文本的一部分,它们只作为分隔符使用。
这里我们加上双引号
echo "this is a test"
this is a test
可以看到,单词分隔被禁止,内嵌的空格也不会被当做界定符,会成为参数的一部分。
加上双引号,则命令行就包含一个带有一个参数的命令。
echo $(cal)
七月 2022 日 一 二 三 四 五 六 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
echo "$(cal)"
七月 2022
日 一 二 三 四 五 六
1 2
3 4 5 6 7 8 9
10 11 12 13 14 15 16
17 18 19 20 21 22 23
24 25 26 27 28 29 30
31
没有加双引号的命令替换导致命令行包含这么多参数。
而加双引号的则命令行只有一个参数,参数中包括嵌入的空格和换行符。
8.10 单引号
如果要禁止所有的展开,使用单引号。
举几个例子:看一下 无引用、双引号、单引号
echo text ~/*.txt {a,b} $(echo foo) $((2+2)) $USER
text /Users/mac/dirlist-bin.txt /Users/mac/dirlist-usr-bin.txt /Users/mac/dirlist-usr-sbin.txt /Users/mac/dirlistsbin.txt /Users/mac/distros.txt /Users/mac/file1.txt /Users/mac/file2.txt /Users/mac/fmt-code.txt /Users/mac/fmt-info.txt /Users/mac/foo.txt /Users/mac/foo1.txt /Users/mac/foot.txt /Users/mac/lazy_dog.txt /Users/mac/ls-error.txt /Users/mac/ls-output.txt /Users/mac/ls.txt /Users/mac/patchfile.txt /Users/mac/phonelist.txt /Users/mac/two_words.txt a b foo 4 mac
echo "text ~/*.txt {a,b} $(echo foo) $((2+2)) $USER"
text ~/*.txt {a,b} foo 4 mac
echo 'text ~/*.txt {a,b} $(echo foo) $((2+2)) $USER'
text ~/*.txt {a,b} $(echo foo) $((2+2)) $USER
可以看到随着引用的程度加强,越来越多的展开被禁止。
8.11 转义字符(\)
引用单个字符,在字符之前加上一个反斜杠,也就是转义字符。
经常在双引号中使用转义字符,来有选择的组织展开。
无引用
echo The balance for user $USER is: $5.00
The balance for user mac is: .00
双引号
echo "The balance for user $USER is: $5.00"
The balance for user mac is: .00
双引号+转义字符
使用转义字符来消除文件名中一个字符的特殊含义,是比较常见的。
echo "The balance for user $USER is: \$5.00"
The balance for user mac is: $5.00
在单引号中使用转义字符,则失去它的特殊含义,它被看做一个普通字符。
'The balance for user $USER is: \$5.00'
The balance for user $USER is: \$5.00例如,在文件名中可能使 用一些对于 shell 来说有特殊含义的字符。这些字符包括 “$”, ”¡‘, ” ” 等字符。在文件名中包含 特殊字符,你可以这样做:(了解)
mv bad\&filename good_filename反斜杠除了作为转义字符外,也可以构成一种表示法,来代表某种特殊字符,这些特殊字符叫做控制码。
例子:转义序列 含义
\n 换行符
\b 退格符
\r 回车符
\t 制表符
echo 命令带上 -e选项,能够解释转移序列。
sleep 10; echo -e "Time's up\a"
Time's up
sleep 10; echo -e "Time's up\r"
Time's up
sleep 10; echo -e "Time's up\n"
Time's up
sleep 10; echo -e "Time's up\t"
Time's up
sleep 10; echo -e "Time's up\b"
Time's up
使用sleep命令创建一个简单的倒数计数器(sleep是一个简单的程序,它会等待指定的秒数,
然后退出。)
7月31号
第九章——键盘高级操作技巧
1. clear ——清空屏幕
2. history ——显示历史列表内容
9.1 命令行编辑
bash使用了一个名为readline 的库,来实现命令行编辑。
9.2 移动光标
按键 : alt-a 移动光标到行首
Ctrl-e 移动光标
9.3 修改文本
9.4 剪切和粘贴文本
9.5 自动补全
输入一个命令时,按下tab键,自动补全就会发生。
ls
Applications distros.txt ls-error.txt
Desktop distros.txt~ ls-output.txt
仅列出部分命令
输入以下命令,不要按enter键:
ls l
现在按下tab键:
lazy_dog.txt link ls-output.txt ls.txt
learnggit/ ls-error.txt ls-output.txt~
ls D
Desktop/ Documents/ Downloads/
ls Do
Documents/ Downloads/
这个实例展示了路径名自动补全,这是最常用的形式。
9.6 利用历史命令
9.7 搜索历史命令
在任何时候,我们都可以浏览历史列表的内容
history | less
在自己曾经用过的命令中,找出和/usr/bin这一目录相关的。
history | grep /usr/bin
88代表的是行号
88 ls -l /usr/bin > ls-output.txt
!88
bash会把!88展开成为历史列表中88行的内容。
mac@MacdeMacBook-Pro ~ %
按下 contrl-r
bck-i-search: _
提示符改变,显示我们要正在执行反向增量搜索。
搜索过程是”反向的“,因为我们要按照从”现在“到过去某个时间段的顺序来搜索。
下一步,我们要输入要查找的文本。
ls -l /usr/bin > ls-output.txt
即刻,搜索返回我们需要的结果。我们可以按下 Enter 键来执行这个命令,或者我们可以 按下 Ctrl-j 复制这个命令到我们当前的命令行,来进一步编辑它。好了现在我们复制它,输入 Ctrl-j:
ls -l /usr/bin > ls-output.txt
9.8 历史命令展开
第十章——权限
1. id ——显示用户身份号
2. chmod ——更改文件模式
3. umask —— 设置默认的文件权限
4. su ——以另一个用户的身份来运行shell
5. sudo ——以另一个用户的身份来执行命令
6. chown ——更改文件所用者
7. chgrp——更改文件组所有权
8.passwd——更改用户密码
10.1 拥有者、组成员和其他人
id
uid=501(mac) gid=20(staff) groups=20(staff)
可以用id命令,来找到关于你自己身份的信息。
10.2 读取、写入和执行
ls -l foo.txt
-rw-r--r-- 1 mac staff 0 5 14 20:50 foo.txt
属性 文件类型
- 一个普通文件
d 一个目录
l 一个符号链接。
c 一个字符设备文件。
b 一个块设备文件。
rwx 文件所有者
rwx 文件组所有者
rwx 其他人的读、写和执行权限
r(read)读
w(write)写
x(excute)执行
文件属性 含义
-rwx-––- 普通文件,对文件所有者来说可读、可写、可执行。其他人无法访问。
-rw-––– 一个普通文件,对文件所有者来说可读可写。其他人无法访 问。
-rw-r--r-- 一个普通文件,对文件所有者来说可读可写,文件所有者的 组成员可以读该文件,其他所有人都可以读该文件。
-rwxr-xr-x 一个普通文件,对文件所有者来说可读、可写、可执行。也 可以被其他的所有人读取和执行。
-rw-rw-–- 一个普通文件,对文件所有者以及文件所有者的组成员来说 可读可写。
lrwxrwxrwx 一个符号链接,符号链接的权限都是虚拟的,真实的权限应 该以符号链接指向的文件为准。
drwxrwx-– 一个目录,文件所有者以及文件所有者的组成员可以访问该 目录,并且可以在该目录下新建、重命名、删除文件。
drwxr-x-– 一个目录,文件所有者可以访问该目录,并且可以在该目录 下新建、重命名、删除文件,文件所有者的组成员可以访问 该目录,但是不能新建、重命名、删除文件。
10.3 chmod ——更改文件模式
更改文件或目录的模式(权限),可以利用chmod命令。
注意:只有文件的所有者或者超级用户才能更改文件或目录的模式。
chmod更改文件模式的两种方法:
八进制数字表示法和符号表示法。
| Octal |
Binary |
File Mode |
| 0 | 000 | --- |
| 1 | 001 | --x |
| 2 | 010 | -w- |
| 3 | 011 | -wx |
| 4 | 100 | r-- |
| 5 | 101 | r-x |
| 6 | 110 | rw- |
| 7 | 111 | rwx |
ls -l foo.txt
-rw-r--r-- 1 mac staff 0 5 14 20:50 foo.txt
chmod 600 foo.txt
ls -l foo.txt
-rw------- 1 mac staff 0 5 14 20:50 foo.txt
文件所有者为读写权限,文件的组成员和其他人没有权限。
第二种为符号表示法。来指定文件模式。通过字符: u g o a的组合来指定要影响的对象。
| u |
”user” 的简写,意思是文件或目录的所有者。 |
| g |
用户组。 |
| o |
”others” 的简写,意思是其他所有的人。 |
| a |
”all” 的简写,是”u”, ”g” 和“o”三者的联合。 |
如果没有指定字符,则假定使用 “all”。执行的操作可能是一个“+”字符,表示加上一个 权限,一个“-”,表示删掉一个权限,或者是一个“=”,表示只有指定的权限可用,其它所有的权限被删除。
权限由“r”、“w”和“x”来指定
| u+x |
为文件所有者添加可执行权限。 |
| u-x |
删除文件所有者的可执行权限。 |
| a+x |
为文件所有者,用户组,和其他所有人添加可执行权限。等 价于 a+x。 |
| o-rw |
除了文件所有者和用户组,删除其他人的读权限和写权限。 |
| go=rw |
给文件所属的组和文件所属者/组以外的人读写权限。如果 文件所属组或其他人已经拥有执行的权限,执行权限将被移 除。 |
| u+x,go=rw |
给文件拥有者执行权限并给组和其他人读和执行的权限。 多种设定可以用逗号分开。 |
注意:这两种方法我更喜欢使用第一种八进制表示法。
10.4 借助GUI来设置文件模式
10.5 umask ——设置默认权限
umask命令控制着文件的默认权限。
umask 命令使用八进制表示法来表达从文件模式属性中删除一个位掩码。
rm -f foo.txt
less foo.txt
foo.txt: No such file or directory
umask
022
foo.txt
首先,删除文件 foo.txt,以此确定我们从新开始。下一步,运行不带参数的 umask 命令, 看一下当前的掩码值。响应的数值是 0002(0022 是另一个常用值),这个数值是掩码的八进制 表示形式。下一步,我们创建文件 foo.txt,并且保留它的权限。
ls -l foo.txt
-rw-r--r-- 1 mac staff 317 7 31 19:23 foo.txt
我们看到只有文件所用者有读和写的权限,文件的组用户和其他人只有读的权限。
这是由掩码值决定的。
首先先删除foo.txt然后运行umask命令,看一下当前的掩码值。掩码值为022,这个是八进制表示法,最后我们再重新创建一个foo.txt,并且保留他的权限。
rm foo.txt
umask 0000
> foo.txt
ls -l foo.txt
-rw-rw-rw- 1 mac staff 0 7 31 19:31 foo.txt
自己设置的掩码值,我们会看到 文件所用者,文件组用户, 其他人都具有读和写的权限。
这是怎么回事呢?
先看一下掩码的八进制形式。把掩码展开成二进制形式,然后与文件属性相比较,看看有什么区别?
| Original file mode |
-– rw- rw- rw- |
| Mask |
000 000 000 010(掩码为0002) |
| Result |
-– rw- rw- r-- |
| Original file mode |
-– rw- rw- rw- |
| Mask |
000 000 010 010(掩码为0022) |
| Result |
-– rw- r-- r-- |
大多数情况下,你不必修改掩码值,系统提供的掩码值就很好了。
8月2号
我们经常看到掩码值用三位数字来表示,但是用四位数字来表示掩码值更确切。
为什么这样说呢?因为除了读取、写入和执行权限之外,还有其他较少用到的权限设置。
一些特殊权限
虽然我们通常看到一个八进制的权限掩码用三位数字来表示,但是从技术层面上 来讲,用四位数字来表示它更确切些。为什么呢?因为除了读取、写入和执行权限 之外,还有其它较少用到的权限设置。
其中之一是 setuid 位(八进制 4000)。当应用到一个可执行文件时,它把有效 用户 ID 从真正的用户(实际运行程序的用户)设置成程序所有者的 ID。这种操作 通常会应用到一些由超级用户所拥有的程序。当一个普通用户运行一个程序,这个 程序由根用户 (root) 所有,并且设置了 setuid 位,这个程序运行时具有超级用户的 特权,这样程序就可以访问普通用户禁止访问的文件和目录。很明显,因为这会引 起安全方面的问题,所有可以设置 setuid 位的程序个数,必须控制在绝对小的范围 内。
第二个是 setgid 位(八进制 2000),这个相似于 setuid 位,把有效用户组 ID 从 真正的用户组 ID 更改为文件所有者的组 ID。如果设置了一个目录的 setgid 位,则 目录中新创建的文件具有这个目录用户组的所有权,而不是文件创建者所属用户组 的所有权。对于共享目录来说,当一个普通用户组中的成员,需要访问共享目录中 的所有文件,而不管文件所有者的主用户组时,那么设置 setgid 位很有用处。
第三个是 sticky 位(八进制 1000)。这个继承于 Unix,在 Unix 中,它可能把一 个可执行文件标志为“不可交换的”。在 Linux 中,会忽略文件的 sticky 位,但是 如果一个目录设置了 sticky 位,那么它能阻止用户删除或重命名文件,除非用户是 这个目录的所有者,或者是文件所有者,或是超级用户。这个经常用来控制访问共 享目录,比方说/tmp。
这里有一些例子,使用 chmod 命令和符号表示法,来设置这些特殊的权限。首 先,授予一个程序 setuid 权限。
chmod u+s program
下一步,授予一个目录 setgid 权限: chmod g+s dir
最后,授予一个目录 sticky 权限: chmod +t dir
当浏览 ls 命令的输出结果时,你可以确认这些特殊权限。这里有一些例子。首 先,一个程序被设置为 setuid 属性:
-rwsr-xr-x
具有 setgid 属性的目录:
drwxrwsr-x
设置了 sticky 位的目录:
drwxrwxrwt10.6 更改身份
想要得到超级用户特权,来执行一些管理任务;但是也有可能成为一个普通用户,比如说测试一个账号。有三种方式,可以拥有多重身份:
1.注销系统并以其他用户身份重新登录系统。
2.使用su命令。
3.使用sudo命令。
第一种方法了解就行了。
下面介绍su命令:
10.7 su ——以其他用户身份和组ID运行一个shell
su命令用来以另一个用户的身份来启动shell。
语法: su [-[l]] [user]
-l 选项:用户启动一个需要登录的shell。这意味着会加载此用户的shell环境,并且工作目录会更改到这个用户的家目录。
选项 -l 可以缩写为 - 这是我们经常用到的形式。
如果不指定用户,那就假定是superuser
启动superuser的shell
su -
下面让你输入密码:
如果密码输入正确,出现一个新的shell提示符,这表明这个shell具有超级用户特权
提示符的末尾字符是 # 而不是 $
并且当前工作目录是超级用户的家目录(通常是/root)。
我们可以执行超级用户所使用的命令。
当工作完成后,输入 exit 则返回原来的 shell
exit
以这样的方式使用su命令,也可以只执行单个命令,而不是启动一个新的可交互的shell:
su -c 'command'
把命令用单引号引起来很重要,因为我们不想命令在我们的shell中展开,但需要在新shell中展开。
su -c 'ls -l /root/*'
10.8 sudo ——以另一个用户身份执行命令
1. sudo 命令不要求超级用户的密码。
2.使用sudo命令时,用户使用自己的密码来认证。
例子:
sudo backup_script
sudo 命令经过配置,允许我们运行一个虚拟的备份程序,
叫做backup_script,这个程序要求超级用户权限。
su和sudo之间一个重要的区别是:sudo不会重新启动一个shell,也不会加载另一个用户的shell环境。这说明命令不必用单引号引起来。
10.9 chown ——更改文件所有者和用户组
这个命令需要超级用户权限。
语法:chown [owner] [:[group]] file...
表:chown参数实例
| 参数 |
结果 |
| bob |
把文件所有者从当前属主更改为用户 bob。 |
| bob:users |
把文件所有者改为用户 bob,文件用户组改为用户组 users。 |
| :admins |
把文件用户组改为组 admins,文件所有者不变。 |
| bob: |
文件所有者改为用户 bob,文件用户组改为用户 bob 登录 系统时所属的用户组。 |
练习题:比方说,我们有两个用户,janet 拥有超级用户访问权限,而 tony 没有。用户 janet 想要从 她的家目录复制一个文件到用户 tony 的家目录。因为用户 janet 想要 tony 能够编辑这个文件, janet 把这个文件的所有者更改为 tony:
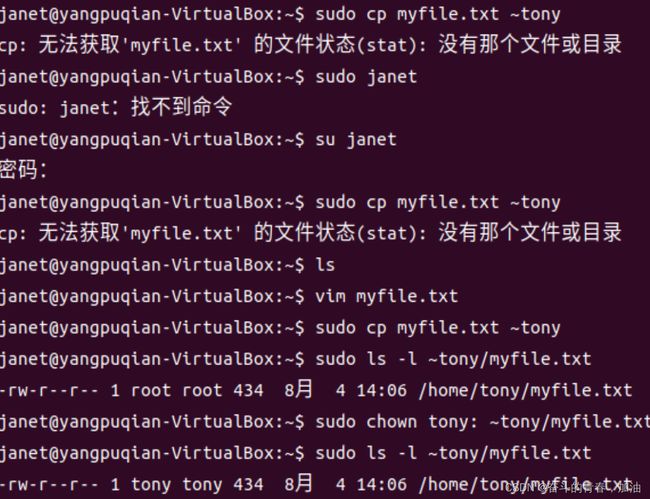
1.用户 janet 把文件从她的目录复制到 tony 的家目录。
2.janet 把文件 所有者从 root(使用 sudo 命令的原因)改到 tony。通过在第一个参数中使用末尾的 “:” 字符, janet 同时把文件用户组改为 tony 登录系统时,所属的用户组,碰巧是用户组 tony。
注意,第一次使用 sudo 命令之后,为什么(shell)没有提示 janet 输入她的密码?这是因 为,在大多数的配置中,sudo 命令会相信你几分钟,直到计时结束。
10.10 chgrp——更改用户组所有权
一般不推荐这个。使用chown就可以了。
10.11 练习使用权限
10.12 更改用户密码
使用passwd命令,来设置或更改用户的密码。
语法:passwd [user]
8月5号
第十一章 进程
现在很多操作系统都支持多任务,操作系统通过在一个执行中的程序和另一个程序之间快速切换造成了一种它同时能够做很多件事情的假象。
1.ps ——查看当前的进程
2. top ——显示任务
3. jobs ——列出活跃的任务
4. bg ——把一个任务放到后台执行
5. fg ——把一个任务放到前台执行
6. kill ——杀死进程
7. shutdown ——关机后重启系统
11.1 进程是怎样工作的
当系统启动的时候,内核先把一些它自己的活动初始化为进程,然后先运行一个叫做init的程序,
其次,在运行一系列的称为init脚本的shell脚本(位于/etc),启动所有的系统服务。
许多系统服务以守护程序的形式实现,守护进程仅在后台运行,没有任何用户接口。
内核维护每个进程的信息,以此来保持事情有序。
例如:系统分配给每个进程一个数字,这个数字叫做进程PID
11.2 查看进程——最常用的命令是ps(process status)

这里列出了两个进程,进程号2253表示bash和进程号32837代表ps。
TTY是指进程的控制终端。
TIME表示进程所消耗的CPU时间数量。
看一下ps常用的两个选项
第一个:ps x (注意x开头没有 - 字符),告诉ps命令,展示所有进程,不管他们由什么终端控制。
解释一下输出的几个字段:
TTY前面有一个? 表示没有控制终端。
ps x可以看到我们所拥有的每个进程的信息。
由于系统中运行着很多进程,所以ps命令的输出结果很长,为了方便查看,将ps的输出管道到less中通常很有帮助。
STAT:是state的简写,表示进程的当前状态。
| 状态 | 含义 |
| R | 运行中 |
| S | 正在睡眠 |
| D | 不可中断睡眠 |
| T | 已停止 |
| Z | 一个死进程 |
| < | 一个高优先级进程 |
| N | 低优先级进程 |
第二个: ps aux

| 标题 | 含义 |
| USER | 用户ID,进程的所有者 |
| %CPU | 以百分比表示CPU使用率 |
| %MEM | ~内存使用率 |
| VSZ | 虚拟内存大小 |
| RSS | 进程占用的物理内存的大小 |
| START | 进程启动时间 |
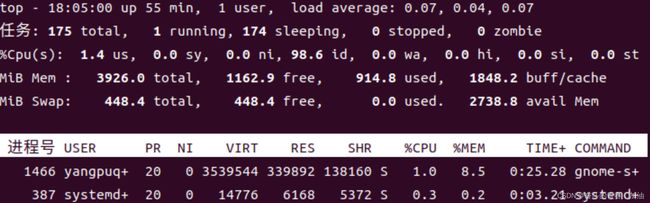
11.3 用top命令动态查看进程
为了看到更多动态信息,这里使用top命令。
top 显示的结果由两部分组成,最上面是系统概要,下面是进列表,以CPU的使用率排序。
| 行号 |
字段 |
意义 |
| 1 |
top |
程序名。 |
| 14:59:20 |
当前时间。 |
|
| up 6:30 |
这是正常运行时间。它是计算机从上次启动到现在所 运行的时间。在这个例子里,系统已经运行了六个半 小时。 |
|
| 2 users |
有两个用户登录系统。 |
|
| load average: |
加载平均值是指,等待运行的进程数目,也就是说,处 于可以运行状态并共享 CPU 的进程个数。这里展示 了三个数值,每个数值对应不同的时间段。第一个是 最后 60 秒的平均值,下一个是前 5 分钟的平均值,最 后一个是前 15 分钟的平均值。若平均值低于 1.0,则 指示计算机工作不忙碌。 |
|
| 2 | Tasks: |
总结了进程数目和这些进程的各种状态。 |
| 3 | Cpu(s): |
这一行描述了 CPU 正在进行的活动的特性。 |
| 0.7%us |
0.7% 的 CPU 被用于用户进程。这意味着进程在内核 之外。 |
|
| 1.0%sy |
1.0% 的 CPU 时间被用于系统(内核)进程。 |
|
| 0.0%ni |
0.0% 的 CPU 时间被用于”nice”(低优先级)进程。 |
|
| 98.3%id |
98.3% 的 CPU 时间是空闲的。 |
|
| 0.0%wa |
0.0% 的 CPU 时间来等待 I/O。 |
|
| 4 | Mem: | 展示物理内存的使用情况。 |
| 5 | Swap: |
展示交换分区(虚拟内存)的使用情况。 |
top有两个比较方便的命令: h q。h 显示程序的帮助命令。
q 退出top程序。
11.4 控制进程

这个xlogo程序是X窗口系统提供的示例程序,这个程序仅显示一个大小可调的包含X标志的窗口。
11.5 中断一个进程
比如我们要中断xlogo程序,使用快捷键Ctrl + c
11.6 把一个进程放置到后台(执行)
我不想终止这个xlogo程序,可以把这个程序放到后台background执行。把终端想象成有前台和后台。

我在xlogo程序之后,加上 & 字符就可以了。
执行这个命令之后,xlogo窗口出现,并且shell提示符返回,打印一些有趣的数字。
这条信息是shell特性的一部分,叫做任务控制(job control)。
通过这条信息,shell告诉我,已经启动了任务号为2,PID为33196的程序。
我在通过运行一下ps,查看一下进程就可以看到xlogo的进程。

执行一下jobs命令,可以看到这个输出列表,有一个任务,编号为2,正在运行,这个任务就是xlogo &。

11.7 进程返回到前台
对于一个在后台的进程来说,不能用任何方法来终止它的运行。
我先把在后台运行的程序把它返回到前台,用命令 fg(foreground)

fg 后面紧跟着一个百分号和一个任务序号。
然后输入 Ctrl +z 来终止xlogo程序。
11.8 停止一个程序
输入Ctrl + z就可以了。
11.9 Signals(信号)
kill 命令被用来”杀死“程序。这里有一个实例程序:
11.10 通过kill命令给进程发送信号
kill命令被用来给程序发送信号。
语法: kill [-signal] PID...
| 编号 | 名字 | 含义 |
| 1 | hup | 挂起(hangup) |
| 2 | int | 中断 |
| 9 | kill | 杀死 |
| 15 | term | 终止 |
| 18 | cont | 继续 |
| 19 | stop | 停止 |
kill -l 可以得到一个完整的信号列表。
11.11 通过killall 命令给多个进程发送信号
语法: killall [-u user] [signal] name...

11.12 更多和进程相关的命令
因为检测进程是一个很重要的系统管理任务,所以有许多命令与它有关。玩玩下面的几个命令。
| 命令名 | 描述 |
| pstree | 输出一个树型结构的进程列表 (processtree),这个列表展示 了进程间父/子关系。 |
| vmstat | 输出一个系统资源使用快照,包括内存,交换分区和磁盘 I/ O。为了看到连续的显示结果,则在命令名后加上更新操作 延时的时间(以秒为单位)。例如,“vmstat 5”。,按下 Ctrl-c 组合键, 终止输出。 |
| xload | 一个图形界面程序,可以画出系统负载随时间变化的图形。 |
| tload(terminal load) | terminal load 与 xload 程序相似,但是在终端中画出图形。 使用 Ctrl-c,来终止输出。 |
第十二章 shell环境
看一下这章节经常遇到的命令
1. printenv ——打印部分或所有的环境变量
2. set ——设置shell 选项
3.export ——导出环境变量,让随后执行的程序知道
4. alias ——创建命令别名
12.1 什么存储在环境变量中?
shell在环境中存储了两种基本类型的数据,分别是:环境变量和shell变量。
shell变量:是bash存放的少量数据,剩下的都是环境变量。
除了变量,shell也存储了一些可编程的数据,即别名和shell函数。
12.2 检查环境变量
可以用bash的内建命令set,或者是printenv程序来查看环境变量。
set 命令可以显示shell或环境变量,而printenv只是显示环境变量。
由于环境变量列表比较长,最好把每个命令的输出通过管道传递给less来阅读。
printenv | less
这里我只把命令写出来了,输出结果有点多,自己看看就行了。
我只把部分代码截图了。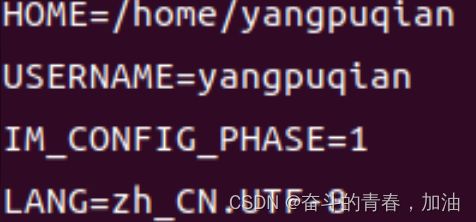
比如我们看到了一个叫做USERNAME的变量,值就是我的用户名,

注意: 当我们使用set命令时,shell变量,环境变量,和定义的shell函数都会被显示。
set | less
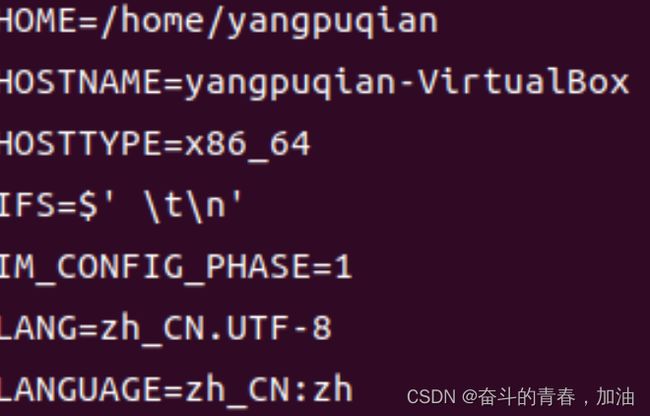

但是别名无法通过 printenv 和 set 查看。只能输入不带参数的alias来查看别名。

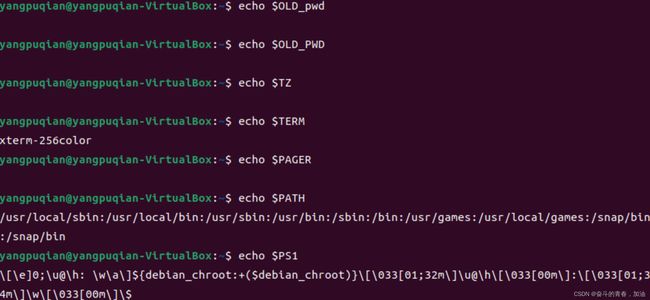
12.3 一些有趣的环境变量 (了解就行了)
e
| 变量 |
内容 |
| display | 如果你正在运行图形界面环境,那么这个变量就是你显示器 的名字。通常,它是”:0”,意思是由 X 产生的第一个显示 器。 |
| editor | 文本编辑器的名字。 |
| shell | shell 程序的名字。 |
| home | 用户家目录。 |
| lang | 定义了字符集以及语言编码方式。
|
| old_pwd | 先前的工作目录。 |
| pager | 页输出程序的名字。这经常设置为/usr/bin/less。 |
| path | 由冒号分开的目录列表,当你输入可执行程序名后,会搜索 这个目录列表。 |
| ps1 | Prompt String 1. 这个定义了你的 shell 提示符的内容。随 后我们可以看到,这个变量内容可以全面地定制。 |
| pwd | 当前工作目录。 |
| term | 终端类型名。类 Unix 的系统支持许多终端协议;这个变量 设置你的终端仿真器所用的协议。 |
| tz | 指定你所在的时区。大多数类 Unix 的系统按照协调时间时 (UTC) 来维护计算机内部的时钟,然后应用一个由这个变 量指定的偏差来显示本地时间。 |
| user | 你的用户名 |

12.4 如何建立shell环境?
当我们登录系统时,bash程序启动,会读取一系列称为启动文件的配置脚本,这些文件定义了,默认的可供所有用户共享的shell环境。
确切的启动顺序依赖于要运行的shell会话类型。
有两种shell会话类型:一个是登录shell会话(简单理解就是开机要输入用户名和密码),另一个是非登录shell会话(在GUI下启动终端)。
下面看一下登录shell会话会启动的文件。
| 文件 |
内容 |
| /etc/profile |
应用于所有用户的全局配置脚本。 |
| ̃/.bash_profile |
用户个人的启动文件。 |
| ̃/.bash_login |
如果文件 ̃/.bash_profile 没有找到,bash 会尝试读取这个 脚本。 |
| ̃/.profile |
如果文件 ̃/.bash_profile 或文件 ̃/.bash_login 都没有找 到,bash 会试图读取这个文件。 |
非登录shell会话
| 文件 |
内容 |
| /etc/bash.bashrc |
应用于所有用户的全局配置文件。 |
| ̃/.bashrc |
用户个人的启动文件。可以用来扩展或重写全局配置脚本 中的设置。 |
浏览一下你的系统,看一看系统中有哪些启动文件。记住-因为上面列出的大多数文件名 都以圆点开头(意味着它们是隐藏文件),你需要使用带 “-a” 选项的 ls 命令。ls -a

在普通用户看来,文件 ∼/.bashrc 可能是最重要的启动文件,因为它几乎总是被读取。非 登录 shell 默认会读取它,并且大多数登录 shell 的启动文件会以能读取 ∼/.bashrc 文件的方式 来书写。
12.5 一个启动文件的内容
这里我的是ubuntu,所以我要查看 less .profile文件
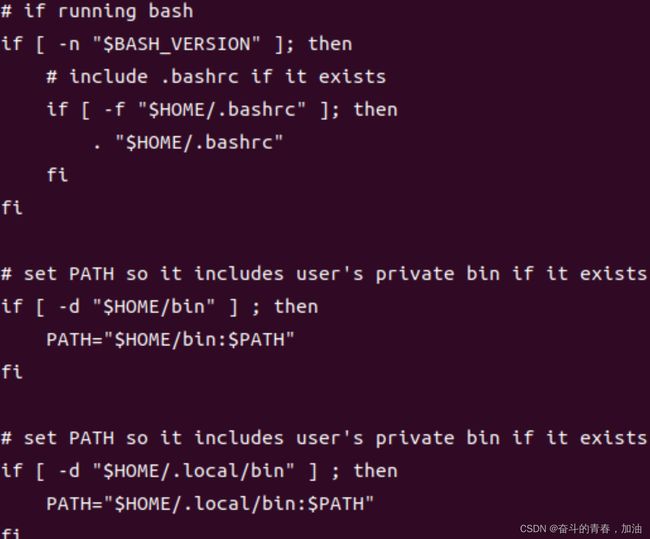
#开头的是注释,shell不会读取它们。
看一下PATH变量,修改PATH变量,添加目录 $HOME/.local/bin到目录列表的末尾。
看下面的例子: 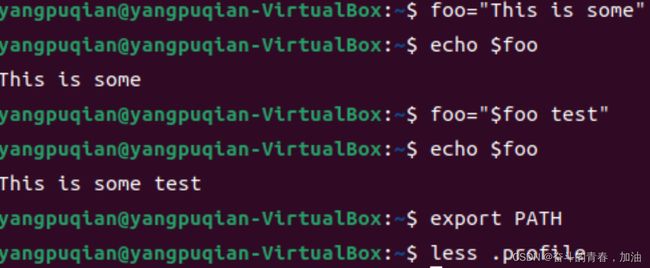
使用这种技巧,我们可以把文本附加到一个变量值的末尾。
通过添加字符串 $HOME/bin 到 PATH 变量值的末尾,则目录 $HOME/bin 就添加到了命令搜索目录列表中。这意味着当 我们想要在自己的家目录下,创建一个目录来存储我们自己的私人程序时,shell 已经给我们准 备好了。我们所要做的事就是把创建的目录叫做 bin。
注意:很多发行版默认地提供了这个 PATH 设置。一些基于 Debian 的发行版,例如 Ubuntu,在登录的时候,会检测目录 ∼/bin 是否存在,若找到目录则把它动态地加到 PATH 变量中。
export PATH
这个 export 命令告诉 shell 让这个 shell 的子进程可以使用 PATH 变量的内容。
12.6 修改shell环境
12.7 我们应该修改那个文件?
按照通常的规则,添加目录到你的 PATH 变量或者是定义额外的环境变量,要把这些更改放置 到.bash_profile 文件中,Ubuntu 使用.profile 文件。
对于其它的更改,要放到.bashrc 文件中。
12.8 文本编辑器(Vim)
12.9 使用文本编辑器
vim some_file 启动vim 编辑一个some_file的文件。
12.10 激活我们的修改
我们对于文件.bashrc 的修改不会生效,直到我们关闭终端会话,再重新启动一个新的会话,因 为.bashrc 文件只是在刚开始启动终端会话时读取。然而,我们可以强迫 bash 重新读取修改过 的.bashrc 文件,使用下面的命令
source .bashrc
运行上面命令之后,我们就应该能够看到所做修改的效果了。
第十三章 vi (vim-vi的升级版)简介
这一章我就不 写了,可以参照 vimtutor 主要是多练习,其他的没有什么难度。
第十四章——自定制shell提示符(了解)
看看就行了,没有什么知识点
第十五章——软件包管理
15.1 打包系统(主要有这两大包管理系统)
| 包管理系统 |
发行版 (部分列表) |
| Debian Style (.deb) |
Debian, Ubuntu, Xandros, Linspire |
| Red Hat Style (.rpm) |
Fedora, CentOS, Red Hat Enterprise Linux, OpenSUSE, Mandriva, PCLinuxOS |
15.2 软件包管理系统是怎样工作的?
15.3 包文件(了解)
包管理系统软件的基本单元是包文件。包文件是一个构成软件包的文件压缩集合。一个软 件包可能由大量程序以及支持这些程序的数据文件组成。
15.4 资源库(了解)
15.5 依赖性(了解)
15.6 上层和底层软件包工具
软件包管理系统通常由两种工具类型组成:底层工具用来处理这些任务,比方说安装和删除软件包文件,和上层工具,完成元数据搜索和依赖解析。
| 发行版 |
底层工具 |
上层工具 |
| Debian-Style(Ubuntu) |
dpkg |
apt-get, aptitude |
| Fedora, Red Hat Enterprise Linux, CentOS |
rpm |
yum |
15.7 常见软件包管理任务
通过命令行软件包管理工具可以完成许多操作。我们将会看一下最常用的工具。注意底 层工具也支持软件包文件的创建(暂时了解一下就行了)。
15.8 查找资源库中的软件包
使用上层工具来搜索资源库元数据,可以根据软件包的名字和说明来定位它。
| 风格 |
命令 |
| Debian |
apt-get update; apt-cache search search_string |
| Red Hat |
yum search search_string |
例如:搜索一个 yum 资源库来查找 emacs 文本编辑器,使用以下命令:
yum search emacs
应为yum是rpm的上层工具,我就不演试了。
15.9 从资源库中安装一个软件包
| 风格 |
命令 |
| Debian |
apt-get update; apt-get install package_name |
| Red Hat |
yum install package_name |
例如:从一个 apt 资源库来安装 emacs 文本编辑器:
apt-get update; apt-get install emacs 注意这个要在root里面执行命令。
那如何卸载安装好的emacs呢?
完整删除语法
1、sudo apt-get --purge remove package_name
2、sudo apt-get --purge remove virtualbox15.10 通过软件包文件来安装软件
如果从某处而不是从资源库中下载一个软件包文件,可以使用底层工具来直接安装它(没有经过依赖解析)。
| 风格 |
命令 |
| Debian |
dpkg --install package_file |
| Red Hat |
rpm -i package_file |
例如:从一个非资源库的网站下载了软件包文件 emacs-22.1-7.fc7-i386.rpm,
可以通过以下命令来安装它。
rpm -i emacs-22.1-7.fc7-i386.rpm
注意:因为这项技术使用底层的 rpm 程序来执行安装任务,
所以没有运行依赖解析。如果 rpm 程序发现缺少了一个依赖,
则会报错并退出。15.11 卸载软件
可以使用上层或者底层工具来卸载软件。下面是可用的上层工具。
| 风格 |
命令 |
| Debian |
apt-get remove package_name |
| Red Hat |
yum erase package_name |
例如:从Debian 风格的系统中卸载emacs软件包:
apt-get remove emacs15.12 经过资源库来更新软件包
最常见的软件包管理任务是保持系统中的软件包都是最新的。
上层工具仅需一步就能完成这个至关重要的任务。
| 风格 |
命令 |
| Debian |
apt-get update; apt-get upgrade |
| Red Hat |
yum update |
例如:更新安装在Debian风格系统中的软件包
apt-get update; apt-get upgrade
15.13 经过软件包文件来升级软件
只要涉及到包文件的,基本上就是从一个非资源网站上下载一个软件包的最新版本,安装最新的版本,来代替之前旧的版本。
| 风格 |
命令 |
| Debian |
dpkg --install package_file |
| Red Hat |
rpm -U package_file |
例如:把 Red Hat 系统中所安装的 emacs
的版本更新到软件包文件 emacs-22.1-7.fc7-i386.rpmz
所包含的 emacs 版本。
rpm -U emacs-22.1-7.fc7-i386.rpm注意:rpm 程序安装一个软件包和升级一个软件包所用的选项是不同的,而 dpkg 程序所用 的选项是相同的。
15.14 列出所安装的软件包
| 风格 |
命令 |
| Debian |
dpkg --list |
| Red Hat |
rpm -qa |
15.15 确定是否安装了一个软件包
| 风格 |
命令 |
| Debian |
dpkg --status package_name |
| Red Hat |
rpm -q package_name |
例如:确定是否 Debian 风格的系统中安装了这个 emacs 软件包:
dpkg --status emacs15.16 显示(查看)所安装软件包的信息
| 风格 |
命令 |
| Debian |
apt-cache show package_name |
| Red Hat |
yum info package_name |
例如:查看 Debian 风格的系统中 emacs 软件包的说明信息:
apt-cache show emacs15.17 查找安装了某个文件的软件包
| 风格 |
命令 |
| Debian |
dpkg --search file_name |
| Red Hat |
rpm -qf file_name |
第十六章 存储媒介
1. mount ——挂载一个文件系统
2. umount——卸载一个文件系统
3.fsck ——检查和修复一个文件系统
4. fdisk——分区表控制器
5. mkfs——创建文件系统
6.fdformat——格式化一张软盘
7. dd——把面向块的数据直接写入设备
8.mkisofs——创建一个iso9660的映像文件。
9. cdrecord——把数据写入光存储媒介
10. md5sum——计算MD5检验码
16.1 挂载和卸载存储设备
/etc/fstab 字段

看一下硬盘分区的六个字段的含义:
| 字段 |
内容 |
说明 |
| 1 | 设备名 |
|
| 2 | 挂载点 |
设备所连接到的文件系统树的目录。 |
| 3 | 文件系统类型 |
Linux 允许挂载许多文件系统类型。大多数本地的 Linux 文件系统是 ext3, |
| 4 | 选项 |
文件系统可以通过各种各样的选项来挂载 |
| 5 | 频率 |
一位数字 |
| 6 | 次序 |
一位数字 |
16.2 查看挂载的文件系统列表 (mount)
mount 命令被用来挂载文件系统。
简单的看看这几个命令吧,其实理解一下就行了。
1. mount
2.怎么去卸载光盘。
su - 需要超级用户来进行操作
然后用umount来卸载光盘
umount /dev/hdc
3. 创建一个新的光盘挂载点。
mkdir /mnt/cdrom
4.最后,把CD-ROW挂载到新的挂载点上(刚刚新创建的)
mount -t iso9660 /dev/hdc /mnt/cdrom
5. 利用新的挂载点来查看 CD-ROW 的内容
cd /mnt/cdrom
ls
6 卸载CD-ROW
cd umount /dev/hdc16.3 确定设备名称
一般来说,这个是比较难确定的。
我们可以先列出目录 /dev(所有的设备)的内容。
ls /devLinux 存储设备名称:
| 模式 |
设备 |
| /dev/fd* |
软盘驱动器 |
| /dev/hd* |
老系统中的 IDE(PATA) 磁盘 |
| /dev/lp* |
打印机 |
| /dev/sd* |
SCSI 磁盘 |
| /dev/sr* |
光盘(CD/DVD 读取器和烧写器) |
比如:/dev/cdrom,/dev/dvd 和/dev/floppy它们实际上就是指设备文件。
小贴士:使用这个 tail -f /var/log/messages 技巧是一个很不错的方法,可以实时观察系统 的一举一动。
启动一个实时 查看文件/var/log/messages
(你可能需要超级用户权限):
sudo tail -f /var/log/messages
最后几行会看到 sdb1是这个设备的第一分区。
Jul 23 10:07:59 linuxbox kernel: sdb: sdb1
Jul 23 10:07:59 linuxbox kernel: sd 3:0:0:0: [sdb] Attached SCSI
removable disk知道了设备名称,我们就可以挂载这个闪存驱动器了:
sudo mkdir /mnt/flash
sudo mount /dev/sdb1 /mnt/flash
df16.4 创建新的文件系统
16.5 用 fdisk 命令操作分区
使用这个工具可以在设备上编辑,删除,和创建分区。
以我们的闪存驱动器为例,首先我们必须卸载它(如果需要的话),
然后调用 fdisk 程序,如下所示
sudo umount /dev/sdb1
sudo fdisk /dev/sdb
这个程序启动后,我们 将看到以下提示:
Command (m for help):
输入 “m” 会显示程序菜单:
输入 “p” 会打印出这个设备的分区表
输入“t”,再输入新的 ID 号:
输入 “wq”退出16.6 用mkfs 命令创建一个新的文件系统
使用 mkfs(“make file system” 的简写),它能创建各种格式的文件系统。
在此设备上创建一个 ext3 文件系统,我们使用 “-t” 选项
来指定这个 “ext3” 系统类型,
随后是 我们要格式化的设备分区名称:
sudo mkfs -t ext3 /dev/sdb1
若把这个设备重新格式化为它 最初的 FAT32 文件系统,
指定 “vfat” 作为文件系统类型
sudo mkfs -t vfat /dev/sdb116.7 测试和修复文件系统 fsck(file system check)
1.每次系统启动时, 在挂载系统之前,都会按照惯例检查文件系统的完整性。这个任务由 fsck 程序(是”file system check” 的简写)完成。
2.除了检查文件系统的完整性之外,fsck 还能修复受损的文件系统,其成功度依赖于损坏的数 量。
3.在类 Unix 的文件系统中,文件恢复的部分被放置于 lost+found 目录里面,位于每个文件 系统的根目录下面。
sudo fsck /dev/sdb116.8 格式化软盘 (fdformat)
对于那些还在使用配备了软盘驱动器的计算机的用户,我们也能管理这些设备。
准备一张 可用的空白软盘要分两个步骤。
首先,对这张软盘执行低级格式化,然后创建一个文件系统。
为了完成格式化,我们使用 fdformat 程序,
同时指定软盘设备名称(通常为/dev/fd0):
sudo fdformat /dev/fd0
接下来,通过 mkfs 命令,给这个软盘创建一个 FAT 文件系统:
sudo mkfs -t msdos /dev/fd016.9 直接把数据移入/出设备(dd)
如果我们看一下磁盘驱动器,例如,我们看到它由大量的数据“块”组成,而操作系统却把这 些数据块看作目录和文件。然而,如果把磁盘驱动器简单地看成一个数据块大集合,我们就能 执行有用的任务,如克隆设备。
这个 dd 程序能执行此任务。它可以把数据块从一个地方复制到另一个地方。
它使用独特的 语法(由于历史原因),经常它被这样使用:
dd if=input_file of=output_file [bs=block_size [count=blocks]]
比方说我们有两个相同容量的 USB 闪存驱动器,
并且要精确地把第一个驱动器(中的内容) 复制给第二个。
如果连接两个设备到计算机上,
它们各自被分配到设备/dev/sdb 和 /dev/sdc 上,
这样我们就能通过下面的命令把第一个
驱动器中的所有数据复制到第二个驱动器中。
dd if=/dev/sdb of=/dev/sdc
或者,如果只有第一个驱动器被连接到计算机上,
我们可以把它的内容复制到一个普通文件
中供以后恢复或复制数据:
dd if=/dev/sdb of=flash_drive.img警告!这个 dd 命令非常强大。虽然它的名字来自于“数据定义”,有时候也把它叫做“清 除磁盘”因为用户经常会误输入 if 或 of 的规范。在按下回车键之前,要再三检查输入与输出 规范!
16.10 创建 CD-ROM映像(稍微了解知道就行了,比较难)
写入一个可记录的 CD-ROM(一个 CD-R 或者是 CD-RW)由两步组成;首先,构建一个 iso 映像文件,这就是一个 CD-ROM 的文件系统映像,第二步,把这个映像文件写入到 CD-ROM 媒介中。
16.10.1 创建一个CD-ROM的映像拷贝
如果想要制作一张现有 CD-ROM 的 iso 映像,我们可以使用 dd 命令来读取 CD-ROW 中的所 有数据块,并把它们复制到本地文件中。比如说我们有一张 Ubuntu CD,用它来制作一个 iso 文件,以后我们可以用它来制作更多的拷贝。插入这张 CD 之后,确定它的设备名称(假定是/ dev/cdrom),然后像这样来制作 iso 文件:
dd if=/dev/cdrom of=ubuntu.iso16.10.2 从文件集合中创建一个映像
创建一个包含目录内容的 iso 映像文件,我们使用 genisoimage 程序。为此,我们首先创建一 个目录,这个目录中包含了要包括到此映像中的所有文件,然后执行这个 genisoimage 命令来 创建映像文件。例如,如果我们已经创建一个叫做 ∼/cd-rom-files 的目录,然后用文件填充此 目录,再通过下面的命令来创建一个叫做 cd-rom.iso 映像文件:
genisoimage -o cd-rom.iso -R -J ~/cd-rom-files
“-R” 选项添加元数据为 Rock Ridge 扩展,
这允许使用长文件名和 POSIX 风格的文件权 限。
同样地,这个 “-J” 选项使 Joliet 扩展生效,
这样 Windows 中就支持长文件名了16.11 写入CD-ROM镜像
16.11.1 直接挂载一个ISO镜像
有一个诀窍,我们可以用它来挂载 iso 映像文件,虽然此文件仍然在我们的硬盘中,但我们当作 它已经在光盘中了。添加 “-o loop” 选项来挂载(同时带有必需的 “-t iso9660” 文件系统类型), 挂载这个映像文件就好像它是一台设备,把它连接到文件系统树上:
mkdir /mnt/iso_image
mount -t iso9660 -o loop image.iso /mnt/iso_image
上面的示例中,我们创建了一个挂载点叫做/mnt/iso_image,
然后把此映像文件 image.iso 挂载到挂载点上。
映像文件被挂载之后,可以把它当作,
就好像它是一张真正的 CD-ROM 或 者 DVD。
当不再需要此映像文件后,记得卸载它。16.11.2 清除一张可重写的CD-ROM
可重写入的 CD-RW 媒介在被重使用之前需要擦除或清空。为此,我们可以用 wodim 命令,指 定设备名称和清空的类型。此 wodim 程序提供了几种清空类型。最小(且最快)的是 “fast” 类 型:
wodim dev=/dev/cdrw blank=fast16.11.3 写入镜像
写入一个映像文件,我们再次使用 wodim 命令,指定光盘设备名称和映像文件名:
wodim dev=/dev/cdrw image.iso
wodim 命令还支持非常多的选项。常见的两个选项是,“-v” 可详细输出,
和 “- dao” 以 disk-at-once 模式写入光盘16.13 友情提示 (了解,太难了)
通常验证一下我们已经下载的 iso 映像文件的完整性很有用处。
在大多数情况下,iso 映像文 件的贡献者也会提供一个 checksum 文件 。
一个 checksum 是一个神奇的数学运算的计算结果, 这个数学计算会产生一个能表示目标文件内容的数字。如果目标文件的内容即使更改一个二进 制位,checksum 的结果将会非常不一样。生成 checksum 数字的最常见方法是使用 md5sum 程 序。当你使用 md5sum 程序的时候,它会产生一个独一无二的十六进制数字:
md5sum image.iso
34e354760f9bb7fbf85c96f6a3f94ece image.iso除了检查下载文件的完整性之外,我们也可以使用 md5sum 程序验证新写入的光学存储介 质
一个以 disk-at-once 模式写入的 CD-R,可以用下面的方式检验:
md5sum /dev/cdrom
34e354760f9bb7fbf85c96f6a3f94ece /dev/cdrom第十七章 ——网络系统
这章会用到的命令:
1. ping - 发送 ICMP ECHO_REQUEST数据包到网络主机
2. traceroute ——打印到一台网络主机的路由数据包
3. netstat ——打印网络连接,路由表、接口统计数据、伪装连接,和多路广播成员
4. ftp——因特网文件传输程序
5. wget ——非交互式网络下载器
6. ssh——OpenSSH SSH客户端(远程登录程序)
看一下几个术语:
IP 地址、主机和域名、URI。
17.1 检查和监测网络
17.1.1 ping
最基本的网络命令是ping。这个命令发送一个特殊的网络数据包,叫做ICMP ECHO_REQUEST
到一台指定的主机。
例子:看一下能不能连接到网站linuxcommand.org
ping linuxcommand.org
按下组合键 Ctrl-c,中断这个命令之后,
ping 打印出运行统计信息17.1.2 traceroute
会显示从本地到指定主机要经过的所有“跳数”的网络流量列表。
traceroute slashdot.org 
从输出结果可以看出来,连接到slashdot.org网站需要经由21个路由器。
没有标识的信息的路由器,会显示几个星号;
有标识的信息则会看到路由器的主机名、IP地址和性能数据。
17.1.3 netstat
用来检查各种各样的网络设置和统计数据。
通过此命令的许多选项,可以看到网络设置中的各种特性。

在上述实例中,我们看到我们的测试系统有两个网络接口。第一个,叫做 eth0,是以太网接 口,和第二个,叫做 lo,是内部回环网络接口,它是一个虚拟接口。
当执行日常网络诊断时,要查看的重要信息是每个网络接口第四行开头出现的单词“UP”, 说明这个网络接口已经生效,还要查看第二行中 inet addr 字段出现的有效 IP 地址。对于使用 DHCP(动态主机配置协议dynamic host config protocol)的系统,在这个字段中的一个有效 IP 地址则证明了 DHCP 工作正常。 
使用这个“-r”选项会显示内核的网络路由表.
解释一下输出的结果:
10.0.2.0 IP地址以零结尾的是指网络,而不是独立主机,所以这个目的地意味着局域网中的任何一台主机。
Gateway:是网关的名字或IP地址,用它来连接2当前的主机和目的地网络。若这个字段显示一个星号,则表明不需要网关。
default :指的是发往任何表上没有列出的目的地网络的流量。
17.2 网络中传输文件
17.2.1 ftp(文件传输协议)
使用 ftp 程序下载一个Ubuntu系统映像文件
1. ftp fileserver 唤醒 ftp 程序,让它连接到 FTP 服务器,file- server。
2. Name (fileserver:me): anonymous 登录名
3. ftp > cd pub/cd\_images/Ubuntu-8.04 跳转到远端系统中
4. ftp> ls 列出远端系统中的目录。
5. ftp> lcd Desktop 跳转到本地系统中的 ̃/Desktop 目录下
6. ftp> get ubuntu-8.04-desktop-i386.iso 告诉远端系统传送文件到本地
7. ftp> bye 退出远端服务器
在“ftp>”提示符下,输入“help”,会显示所支持命令的列表17.2.2 lftp ——更好的 ftp(了解)
ftp 并不是唯一的命令行形式的 FTP 客户端。实际上,还有很多,其中比较好(也更流行的) 是 lftp 程序。
17.2.3 wget
另一个流行的用来下载文件的命令行程序是 wget。若想从网络和 FTP 网站两者上都能下载 数据,wget 是很有用处的。不只能下载单个文件,多个文件,甚至整个网站都能下载。
比如:下载linuxcommand.org网站的首页

17.3 与远程主机安全通信
17.3.1 ssh(secure shell 安全的shell)
SSH 解决了这两个基本的和远端主机安全交流的问题。
首先,它要认证远端主机是否为它所知道的那台主机(这样就 阻止了所谓的“中间人”的攻击),
其次,它加密了本地与远程主机之间所有的通讯信息。
SSH 由两部分组成。SSH 服务端运行在远端主机上,在端口 22 上监听收到的外部连接,而 SSH 客户端用在本地系统中,用来和远端服务器通信。
大多数 Linux 发行版自带一个提供 SSH 功能的软件包,叫做 OpenSSH。
Ubuntu则只提供客户端。为了能让系统接受远端的连接,它必须安装 OpenSSH-server 软件 包,配置,运行它,并且(如果系统正在运行,或者系统在防火墙之后)它必须允许在 TCP 端 口 22 上接收网络连接。
17.3.2 scp(secure cp) 和 sftp(secure ftp)
18. 查找文件
用来在系统之后查找文件的工具(两个):
locate ——通过名字来查找文件
find ——在一个目录层次结构中搜索文件
用来处理搜索到的文件列表:
xargs——从标准输入生成和执行命令。
还有两个命令是协助的:
touch ——更改文件的时间
stat —— 显示文件或文件系统的状态
18.1 locate ——查找文件的简单方法
会执行一次快速的路径名数据库搜索,并且输出每个与给定子字符串相匹配的路径名。
比如:我们想要找到所有名字以“zip”开头的程序。假设包含的程序目录以“bin/”结尾。

locate 命令将会搜索它的路径名数据库,输出任一个包含字符串"bin/zip" 的路径名。
如果搜索要求没有这么简单,locate 可以结合其它工具,比如说 grep 命令,来设计更加有趣的搜索:
18.2 find ——查找文件的复杂方式
locate 程序只能依据文件名来查找文件,而 find 程序能基于各种各样的属性搜索一个给定目录 (以及它的子目录),来查找文件
在它的最简单的使用方式中,find 命令接收一个或多个目录名来执行搜索。例如,输出我们
的家目录的路径名列表
1.find ~
2.find ~ | wc -l18.2.1 Tests
比如说我们想在我们的搜索中得到目录列表。我们可以添加以下测试条件:
1.find ~ -type d | wc -l
添加测试条件-type d 限制了只搜索目录
2.find ~ -type f | wc -l
测试条件来限定搜索 普通文件:
find 命令支持的常见文件类型测试条件:
| 文件类型 |
描述 |
| b | 块 |
| c | 字符 |
| d | 目录 |
| l | 符号链接 |
| f | 普通文件 |
查找所有文件名匹配通配符模式“*.JPG”和文件大小大于 1M 的普通文件:
find ~ -type f -name "*.JPG" -size +1M | wc -l直接运行 man find 看里面的tests就行了。
18.2.2 操作符
find结合操作符来进行操作
例子:查找权限不是 0600 的文件和权限不是 0700 的目录。
find ~ \( -type f -not -perm 0600 \) -or \( -type d -not -perm 0700 \)
( expression 1 ) -or ( expression 2 )
这里为什么用 -or 来代替 -and呢?
我们想要知道它是具有错误权限的文件还是有错误权限的目录。
它不可能同时符合这两个条件。
( file with bad perms ) -or ( directory with bad perms )起初我一看这个感觉挺复杂的,剖析一下:
| 操作符 |
描述 |
| -and | 如果操作符两边的测试条件都是真,则匹配 |
| -or | 若操作符两边的任一个测试条件为真,则匹配 |
| -not | 若操作符后面的测试条件是假,则匹配 |
| () | 把测试条件和操作符组合起来形成更大的表达式 |
测试具有“不正确”权限的文件表达式为:
-type f -and -not -perms 0600
对于目录,表达式为:
-type d -and -not -perms 0700
find ~ ( -type f -not -perms 0600 ) -or ( -type d -not -perms 0700 )
然而,因为圆括号对于 shell 有特殊含义,我们必须转义它们,来阻止 shell 解释它们。
在 圆括号字符之前加上一个反斜杠字符来转义它们。expr1 -operator expr2
在所有情况下,总会执行表达式 expr1;
然而操作符将决定是否执行表达式 expr2。
| expr1 的结果 |
操作符 |
expr2 is... |
| true | -and | 总要执行 |
| false | -and | 从不执行 |
| true | -or | 从不执行 |
| false | -or | 总要执行 |
我们知道如果表达式 expr1 的结果为假,表达式 expr1 -and expr2 不能为真,所以没有必要执行 expr2。
如果我们 有表达式 expr1 -or expr2,并且表达式 expr1 的结果为真,那么就没有必要执行 expr2,因为 我们已经知道表达式 expr1 -or expr2 为真。
18.3 预定义的操作
| 操作 |
描述 |
| -delete |
删除当前匹配的文件。 |
| -ls |
对匹配的文件执行等同的 ls -dils 命令 |
| |
把匹配文件的全路径名输送到标准输出 |
| -quit |
一旦找到一个匹配,退出。 |
find ~
find ~ -print
来删除扩展名为“.BAK”(这 通常用来指定备份文件)的文件,我们可以使用这个命令:
find ~ -type f -name '*.BAK' -delete
用户家目录(和它的子目录)下的每个文件中搜索以.BAK 结尾的文件 名。当找到后,就删除它们。
警告:当使用 -delete 操作时,不用说,你应该格外小心。
每次都应该首先用 -print 操作代 替 -delete
find ~ -type f -name '*.BAK' -print 或者下面的
find ~ -type f -and -name '*.BAK' -and -print
测试一下命令,来确认搜索结果。| 测试/行为 |
只有... 的时候,才被执行 |
| |
只有 -type f and -name ’*.BAK’ 为真的时候 |
| -name ‘*.BAK’ |
只有 -type f 为真的时候 |
| -type f |
总是被执行,因为它是与 -and 关系中的第一个测试/行为。 |
如果我们重新安排测试和行为之间的顺序,让 -print 行为是第一个,
那么这个命令执行起来会截然不同:
find ~ -print -and -type f -and -name '*.BAK'
这个版本的命令会打印出每个文件(-print 行为总是为真),
然后测试文件类型和指定的文 件扩展名。18.4 用户定义的行为
语法:传统方式是通过-exec行为。
-exec command {} ;
command 就是指一个命令的名字,{} 是当前路径名的符号表示,分号是必要的分 隔符表明命令的结束。
花括号和分号对于 shell 有特殊含义,所以它们必须被引起来或被转义。
通过使用 -ok 行为来代替 -exec,在执行每 个指定的命令之前,会提示用户:输入y
find ~ -type f -name 'foo*' -ok ls -l '{}' ';'
"ls -l /Users/mac/foo.test"? y
-rw-r--r-- 1 mac staff 0 4 28 17:36 /Users/mac/foo.test
"ls -l /Users/mac/foo.txt~"? y
-rw-r--r-- 1 mac staff 12 5 12 19:22 /Users/mac/foo.txt~
在这个例子里面,我们搜索以字符串“foo”开头的文件名,
并且对每个匹配的文件执行 ls -l 命令。使用 -ok 行为,
会在 ls 命令执行之前提示用户。18.5 提高效率
我们可能更愿意把所有的搜索结果结合起来,再运行一个命令的实例。例如,与其像这样执行 命令:
ls -l file1
ls -l file2
我们更喜欢这样执行命令:
ls -l file1 file2这样就导致命令只被执行一次而不是多次。
有两种方法可以这样做。传统方式是使用外部 命令 xargs,另一种方法是,使用 find 命令自己的一个新功能。我们看第二种方法。
find ~ -type f -name 'foo*' -exec ls -l '{}' ';'
find ~ -type f -name 'foo*' -exec ls -l '{}' +
通过把末尾的分号改为加号,就激活了 find 命令的一个功能,
把搜索结果结合为一个参数 列表,然后用于所期望的命令的一次执行。
虽然我们得到一样的结果,但是系统只需要执行一次 ls 命令。18.5.1 xargs
它从标准输入接受输入,并把输入转换为一个特定命 令的参数列表 。
find ~ -type f -name 'foo*' -print | xargs ls -l
这里我们看到 find 命令的输出被管道到 xargs 命令,
之后,xargs 会为 ls 命令构建参数列 表,然后执行 ls 命令。18.6 返回操练场
到实际使用 find 命令的时候了。我们将会创建一个操练场,来实践一些我们所学到的知识。
mkdir -p playground/dir-{00{1..9},0{10..99},100}
touch playground/dir-{00{1..9},0{10..99},100}/file-{A..Z}
只用这两行,我们就创建了一个包含一百个子目录,每个子目录 中包含了 26 个空文件的操练场
touch 命令通常被用来设置或更新文件的访问,更改,和修改时间。
然而,如果一个文 件名参数是一个不存在的文件,则会创建一个空文件。
find playground -type f -name 'file-A'
find playground -type f -name 'file-A' | wc -l
下一步,让我们看一下基于文件的修改时间来查找文件
首先我们将创建一个参考文件,我们将与其比较修 改时间:
touch playground/timestamp
这个创建了一个空文件,名为 timestamp,并且把它的修改时间设置为当前时间
stat,是一款加大马力的 ls 命令版本。
这个 stat 命令会展 示系统对某个文件及其属性所知道的所有信息:
stat playground/timestamp
如果我们再次 touch 这个文件,然后用 stat 命令检测它,
我们会发现所有文件的时间已经 更新了。
touch playground/timestamp
stat playground/timestamp下一步,让我们使用 find 命令来更新一些操练场中的文件:
find playground -type f -name 'file-B' -exec touch '{}' ';'
这会更新操练场中所有名为 file-B 的文件
接下来我们会使用 find 命令通过把所有文件与 参考文件 timestamp 做比较,
来找到已更新的文件:
find playground -type f -newer playground/timestamp
搜索结果包含所有一百个文件 file-B 的实例。因为我们在更新了文件 timestamp 之后
touch 了操练场中名为 file-B 的所有文件,
所以现在它们“新于”timestamp 文件,
因此能被用 -newer 测试条件找到。
最后,让我们回到之前那个错误权限的例子中,把它应用于操练场里:
find playground \( -type f -not -perm 0600 \) -or \( -type d -not -perm 0700 \)
我们可以给这个命令添加行为,对实战场中的文件和目录应用新的权限。
find playground \( -type f -not -perm 0600 -exec chmod 0600 '{}' ';' \)
-or \( -type d -not -perm 0711 -exec chmod 0700 '{}' ';' \)第十九章 —— 归档和备份
这一章用到的命令为:
1. gzip ——压缩或者展开文件
2. bzip2 ——块排序文件压缩器
归档排序:
3. tar ——磁带打包工具
4. zip ——打包和压缩文件
还有文件同步程序:
rsync——同步远端文件和目录
19.1 压缩文件
数据压缩就是一个删除冗余数据的过程。
有损压缩:执行压缩操作时会删除数据,允许更大的压缩。文件被还原时,与原文件不相匹配;它是一个近似值。
无损压缩:保留了原始文件的所有数据。当还原一个压缩文件时,还原的文件与原文件一模一样。
19.1.1 gzip(扩展名.gz)
用来压缩一个或多个文件。
例子:1. 创建一个名为foo.txt 的文本文件,其内容包含一个目录的列表清单。
2. 然后运行gzip 会把原始文件替换为一个叫做foo.txt.gz的压缩文件。
3. 在foo.*文件列表中,我们看到原始文件已经被压缩文件替代了,并且可以看出压缩后的文件是没有压缩后的文件的五分之一。
4. 最后 运行 gunzip来解压缩文件。
就可以看到压缩文件已经被还原文件替代了,同时也保留了相同的权限和时间戳。

当然了,可以使用 man gzip来查看gzip的许多选项。
返回之前的例子:
1.用压缩文件来代替文件foo.txt,压缩文件名为foo.txt.gz。
2. 接着我们测试了压缩文件的完整性,使用了-t 和-v选项。
3 . 最后我们在解压文件foo.txt.gz。
gzip foo.txt
gzip -tv foo.txt.gz
foo.txt.gz: OK
gzip -d foo.txt.gzls -l /etc | gzip > foo.txt.gz
这个命令创建了一个目录列表的压缩文件。
gunzip foo.txt.gz——这个gunzip程序,会解压gzip文件,没有必要指定它,可以不执行
这个命令
gunzip -c foo.txt.gz | less
为了浏览一下压缩文件的内容,直接执行上面的命令就行。
对应于gzip还有一个程序,是zcat, 它就等同于 gunzip -c。
zcat foo.txt.gz | less19.1.2 bzip2 (扩展名为 .bz2)
它与 gzip 程序相似,区别就是使用了不同的算法,舍弃了压缩速度,实现了更高的压缩级别。
其实工作原理都一样,由bzip2压缩的文件,扩展名为 .bz2来表示。
ls -l /etc > foo.txt
ls -l foo.txt
bzip2 foo.txt
ls -l foo.txt.bz2
bunzip2 foo.txt.bz219.2 归档文件
与文件压缩结合一块使用的文件管理任务是归档。
归档就是收集许多文件,并把它们捆绑成一个大文件的过程。归档经常作为系统备份的一部分来使用。
当把旧数据从一个系统移到某种类型的长期存储设备中时,也会用到归档程序。
19.2.1 tar(tape achive)磁带存档
tar 程序是用来归档文件的经典工具。
这个是比较常见的,像 .tar 或者 .tgz 的文件。它们代表 普通的一些 tar包和被gzip程序压缩过的tar包。
语法格式: tar mode[options] pathname...
这里的mode指的就是操作模式(写一部分看看了解一下)
| 模式 |
说明 |
| c |
为文件和/或目录列表创建归档文件。 |
| x |
抽取归档文件。 |
| r |
追加具体的路径到归档文件的末尾。 |
| t |
列出归档文件的内容。 |
如果想具体了解 可以使用 man tar。
tar包是如何工作的:
首先,让我们重新创建之前我们用过的操练场:
mkdir -p playground/dir-{00{1..9},0{10..99},100}
touch playground/dir-{00{1..9},0{10..99},100}/file-{A..Z}
下一步,让我们创建整个操练场的 tar 包:
tar cf playground.tar playground
这个命令创建了一个名为 playground.tar 的 tar 包,
其包含整个 playground 目录层次结果。
要想列出归档文件的内容,我们可以这样做:
tar tf playground.tar
为了得到更详细的列表信息,我们可以添加选项 v:
tar tvf playground.tar
抽取 tar 包 playground 到一个新位置。我们先创建一个名为 foo 的新目录,
更改目 录,然后抽取 tar 包中的文件。
mkdir foo
cd foo
tar xf ../playground.tar
ls
tar 命令另一个有趣的行为是它处理归档文件路径名的方式。
默认情况下,路径名是相对的, 而不是绝对路径。
当以相对路径创建归档文件的时候,tar 命令会简单地删除路径名开头的斜 杠(这个其实不是语法错误,直接忽略掉就好了)。为了说明问题,我们将会重新创建我们的归档文件,但是这次指定用绝对路径创建:
cd
tar cf playground2.tar ~/playground
记住,当按下回车键后,∼/playground 会展开成 /home/me/playground,
所以我们将会得 到一个绝对路径名。
cd foo
tar xf ../playground2.tar
ls
ls home
ls home/yangpuqian
这里我们看到当我们抽取第二个归档文件时,它重新创建了 home/me/playground 目录,
相 对于我们当前的工作目录,∼/foo,而不是相对于 root 目录,作为带有绝对路径名的案例。
这 看起来似乎是一种奇怪的工作方式,但事实上这种方式很有用,因为这样就允许我们抽取文件 到任意位置,
而不是强制地把抽取的文件放置到原始目录下。
加上 verbose(v)选项,重做这 个练习,将会展现更加详细的信息。19.2.2 zip ——既是压缩工具,也是一个打包工具
zip在windows系统中比较常见,在Linux/Unix中可能最常见的是gzip和bzip2。
在 zip 命令最基本的使用中,可以这样唤醒 zip 命令:
zip options zipfile file...
例如,制作一个 playground 的 zip 版本的文件包,这样做:
zip -r playground.zip playground使用 unzip 程序,来直接抽取一个 zip 文件的内容。
cd foo
unzip ../playground.zip
对于 zip 命令(与 tar 命令相反)要注意一点,就是如果指定了一个已经存在的文件包,
其 被更新而不是被替代。这意味着会保留此文件包,但是会添加新文件,
同时替换匹配的文件。 可以列出文件或者有选择地从一个 zip 文件包中抽取文件,
只要给 unzip 命令指定文件名.
[me@linuxbox ~]$ unzip -l playground.zip playground/dir-87/file-Z
Archive: ../playground.zip
Length Date Time Name
0 10-05-08 09:25 playground/dir-87/file-Z
0 1 file
[me@linuxbox ~]$ cd foo
[me@linuxbox foo]$ unzip ./playground.zip playground/dir-87/file-Z
Archive: ../playground.zip
replace playground/dir-87/file-Z? [y]es, [n]o, [A]ll, [N]one,
[r]ename: y
extracting(抽取): playground/dir-87/file-Z
使用-l 选项,导致 unzip 命令只是列出文件包中的内容而没有抽取文件
通过-@ 选 项,有可能把一系列的文件名管道到 zip 命令。
[me@linuxbox foo]$ cd
[me@linuxbox ~]$ find playground -name "file-A" | zip -@ file-A.zip
这里我们使用 find 命令产生一系列与“file-A”相匹配的文件列表,
并且把此列表管道到 zip 命令,然后创建包含所选文件的文件包 file-A.zip。
然而,zip 命令可以接受标准输入,所以它可以被用来压缩其它程序的输出:
ls -l /etc/ | zip ls-etc.zip -
在这个例子里,我们把 ls 命令的输出管道到 zip 命令。像 tar 命令,
zip 命令把末尾的横杠 解释为“使用标准输入作为输入文件。”
这个 unzip 程序允许它的输出发送到标准输出,当指定了-p 选项之后
unzip -p ls-etc.zip | less19.3 同步文件和目录 rsync
维护系统备份的常见策略是保持一个或多个目录与另一个本地系统(通常是某种可移动的存储 设备)或者远端系统中的目录(或多个目录)同步。
例如有一个正在开发的网站的 本地备份,需要时不时的与远端网络服务器中的文件备份保持同步。在类 Unix 系统的世界里, 能完成此任务且备受人们喜爱的工具是 rsync。
这个程序能同步本地与远端的目录,通过使用 rsync 远端更新协议,此协议允许 rsync 快速地检测两个目录的差异,执行最小量的复制来达 到目录间的同步。比起其它种类的复制程序,这就使 rsync 命令非常快速和高效。
rsync 被这样唤醒:
rsync options source destination
这里 source 和 destination 是下列选项之一:
一个本地文件或目录
一个远端文件或目录,以 [user@]host:path 的形式存在
一个远端 rsync 服务器,由 rsync://[user@]host[:port]/path 指定
注意 source 和 destination 两者之一必须是本地文件。rsync 不支持远端到远端的复制让我们试着对一些本地文件使用 rsync 命令。首先,清空我们的 foo 目录:
rm -rf foo/*
下一步,我们将同步 playground 目录和它在 foo 目录中相对应的副本
rsync -av playground foo
我们包括了-a 选项(递归和保护文件属性)和-v 选项(冗余输出),
来在 foo 目录中制作一 个 playground 目录的镜像。
当这个命令执行的时候,我们将会看到一系列的文件和目录被复 制。
如果我们再次运行这个命令,我们将会看到不同的结果:
rsync -av playgound foo
注意到没有文件列表。
这是因为 rsync 程序检测到在目录 ∼/playground 和 ∼/foo/ playground
之间不存在差异,因此它不需要复制任何数据。
如果我们在 playground 目录中修改一个文件,
然后再次运行 rsync 命令:
touch playground/dir-099/file-Z
rsync -av playground foo
我们看到 rsync 命令检测到更改,并且只是复制了更新的文件19.3.1 在网路间使用rsync命令
总结:这一章的难点:240页那一部分, 19.3最后结尾那一部分, 19.3.1,
第二十章 ——正则表达式
20.1 grep(global regular expression print)
本质上,grep程序会在文本文件中查找一个指定的正则表达式,并把匹配行输出到标准输出。
位于目录 /usr/bin 中,文件名中包含子字符串“zip”的所有文件。
ls /usr/bin | grep zip
grep 程序以这样的方式来接受选项和参数:
grep [options] regex [file...]
regex 是指一个正则表达式grep 选项列表——man grep
为了更好的探究 grep 程序,让我们创建一些文本文件来搜寻:
我们能够对我们的文件列表执行简单的搜索,像这样:
 如果我们只是对包含匹配项的文件列表,而不是对匹配项本身感兴 趣的话,我们可以指定-l 选项:
如果我们只是对包含匹配项的文件列表,而不是对匹配项本身感兴 趣的话,我们可以指定-l 选项:

相反地,如果我们只想查看不包含匹配项的文件列表,我们可以这样操作:

20.2 元字符和原义字符 (Metacharacters And Literals)
原义字符: 字符串“bzip”中的所有字符。它们匹配本身。
元字符:用来指定更复杂的匹配项。
正则表达式元字符由以下字符组成:
^$.[]{}-?*+()|\一共12个字符
20.3 任何字符
我们将要查看的第一个元字符是圆点字符,其被用来匹配任意字符。 这里只是列举了几个。
注意点:1.没有找到这个 zip 程序。正则表达式中包含的圆点字符把所要求的匹配 项的长度增加到四个字符,并且因为字符串“zip”只包含三个字符,所以这个 zip 程序不匹配。
2.文件列表中有一些文件的扩展名是.zip,则它们也会成为匹配项,因为文件扩 展名中的圆点符号也会被看作是“任意字符”。
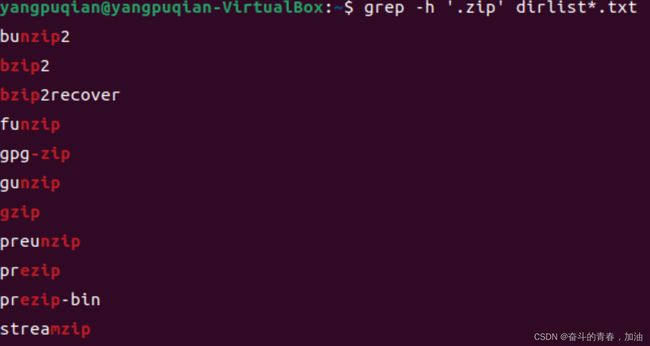
20.4 锚点
在正则表达式中,插入符号和美元符号被看作是锚点。这意味着正则表达式只有在文本行的开
头或末尾被找到时,才算发生一次匹配。
grep -h '^zip' dirlist*.txt
grep -h 'zip$' dirlist*.txt
grep -h '^zip$' dirlist*.txt
文件列表中搜索行首、行尾以及行首和行尾同时包含字符串“zip”的匹配行。
注意正则表达式‘ˆ$’(行首和行尾之间没有字符)会匹配空行.20.5 中括号表达式和字符类
使用中括号表达式,我们也能够 从一个指定的字符集合中匹配单个字符。通过中括号表达式,我们能够指定一个待匹配字符集 合。
grep -h '[bg]zip' dirlist*.txt
匹配包含字符串“bzip”或者“gzip”的任意行。20.6 否定(^注意是放在中括号里面)
grep -h '[^bg]zip' dirlist*.txt
通过激活否定操作,我们得到一个文件列表,它们的文件名都包含字符串“zip”,
并且“zip” 的前一个字符是除了“b”和“g”之外的任意字符。20.7 传统的字符区域
在我们的列表中找到每个以大写字母开头的文件:
grep -h '^[ABCDEFGHIJKLMNOPQRSTUVWXZY]' dirlist*.txt
但是输入所有字母非常令人烦恼, 所以有另外一种方式:
grep -h '^[A-Z]' dirlist*.txt
比如下面这个表达式就匹配了所有以字母和数字开头的文件名:
grep -h '^[A-Za-z0-9]' dirlist*.txt
考虑一下这两个例子:
grep -h '[A-Z]' dirlist*.txt 这会匹配包含一个大写字母的文件名
grep -h '[-AZ]' dirlist*.txt
上面的表达式会匹配包含一个连字符,或一个大写字母“A”,或一个大写字母“Z”的文件 名。20.8 POSIX字符集 
echo $LANG
针对不同地区选择合适的字符集。
ls /usr/sbin/[[:upper:]]*看一下POSIX字符集:
| 字符集 |
说明 |
| [:alnum:] |
字母数字字符 |
| [:word:] |
与 [:alnum:] 相同, 但增加了下划线字符。 |
| [:alpha:] |
字母字符 |
| [:blank:] |
包含空格和 tab 字符 |
| [:cntrl:] |
ASCII 的控制码 |
| [:digit:] |
数字 0 到 9 |
| [:graph:] |
可视字符 |
| [:lower:] |
小写字母 |
| [:punct:] |
标点符号字符 |
| [:print:] |
可打印的字符 |
| [:space:] |
空白字符,包括空格、tab、回车、换行、vertical tab 和 form feed. 在 ASCII 中,等价于:[ \t\r\n\v\f] |
| [:upper:] |
大写字母。 |
| [:xdigit:] |
用来表示十六进制数字的字符。在 ASCII 中,等价于: [0-9A-Fa-f] |
使用 locale 命令,来查看 locale 的设置。
locale20.9 POSIX基本正则表达式与POSIX扩展正则表达式
POSIX 把正则表达式的实现分成了两类: 基本正则表达式(BRE)和扩展的正则表达式(ERE)
BRE 和 ERE 之间有什么区别呢?
这是关于元字符的问题。BRE 可以辨别以下元字符:其它的所有字符被认为是文本字符。
^$.[]*再此基础之上ERE 添加了以下元字符 :
(){}?+|在 BRE 中,字符“(”,“)”,“{”,和“}”用反斜杠转义后, 被看作是元字符, 相反在 ERE 中,在任意元字符之前加上反斜杠会导致其被看作是一个文本字符。
20.10 交替 (类似于中括号)
我们将要讨论的扩展表达式的第一个特性叫做 alternation(交替),从一系列表达 式之间选择匹配项的实用程序。
首先,让我们试一个普通的字符串匹配:
echo "AAA" | grep AAA
echo "BBB" | grep AAA
当出现一 个匹配项时,我们看到它会打印出来;当没有匹配项时,我们看到没有输出结果。
现在我们将添加 alternation,以竖杠线元字符为标记:
echo "AAA" | grep -E 'AAA|BBB'
echo "BBB" | grep -E 'AAA|BBB'
echo "CCC" | grep -E 'AAA|BBB'
正则表达式’AAA|BBB’,这意味着“匹配字符串 AAA 或者是字符串 BBB
注意因为这是一个扩展的特性,我们给 grep 命令
(虽然我们能以 egrep 程序来代替)添加了-E 选项,
并且我们把这个正则表达式用单引号引起来,
为的是阻止 shell 把竖杠线元字符解释为 一个 pipe 操作符.
Alternation 并不局限于两种选择:
echo "AAA" | grep -E 'AAA|BBB|CCC'grep -Eh '^(bz|gz|zip)' dirlist*.txt
这个表达式将会在我们的列表中匹配以“bz”,或“gz”,或“zip”开头的文件名
grep -Eh '^bz|gz|zip' dirlist*.txt
会变成匹配任意以“bz”开头,或包含“gz”,或包含“zip”的文件名。20.11 限定符
20.11.1 ? 匹配零个或一个元素
限定符意味着,实际上,“使前面的元素可有可无。”
比方说我们想要查看一个电话号码的真实性,如果它匹配下面两种格式的任意一种,我们就认为这个电话号码是真实的:
(nnn) nnn-nnnn
nnn nnn-nnnn
^\(?[0-9][0-9][0-9] \)? [0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]$
在圆括号之后加上一个问号,来表示它们将被匹配零次或一次
通常圆括号都是元字符(在 ERE 中),所以我们在圆括号之前加上了反斜杠,使它们 成为文本字符。
echo "(555) 123-4567" | grep -E '^\(?[0-9][0-9][0-9]\)? [0-9][0-9][0-9]-[0-9] [0-9][0-9][0-9]$'
echo "555 123-4567" | grep -E '^\(?[0-9][0-9][0-9]\)? [0-9][0-9][0-9]-[0-9] [0-9][0-9][0-9]$'
$ echo "AAA 123-4567" | grep -E '^\(?[0-9][0-9][0-9]\)? [0-9][0-9][0-9]-[0-9] [0-9][0-9][0-9]$'
20.12 * 匹配零个或多个元素
例子:
比方说我们想要知道是否一个字符串是一句话;也就是说,字符串 开始于一个大写字母,然后包含任意多个大写和小写的字母和空格,最后以句号收尾
为了匹 配这个(非常粗略的)语句的定义,我们能够使用一个像这样的正则表达式:
[[:upper:]][[:upper:][:lower:] ]*.
这个表达式由三个元素组成:一个包含 [:upper:] 字符集的中括号表达式,一个包含 [:upper:] 和 [:lower:] 两个字符集以及一个空格的中括号表达式,和一个被反斜杠字符转义过的圆点。
第 二个元素末尾带有一个 * 元字符,所以在开头的大写字母之后,
可能会跟随着任意数目的大写 和小写字母和空格,并且匹配:
echo "This works." | grep -E '[[:upper:]][[:upper:][:lower:] ]*\.'
echo "This Works." | grep -E '[[:upper:]][[:upper:][:lower:] ]*\.'
echo "this does not" | grep -E '[[:upper:]][[:upper:][:lower:] ]*\.'
这个表达式匹配前两个测试语句,但不匹配第三个,因为第三个句子缺少开头的大写字母和 末尾的句号。20.12.1 + 匹配一个或多个元素
+ 和 * 相似,除了它要求前面的元素至少出现一次匹配。
这个正则表达式只匹配那些由一个或多个字母字符组构成的文本行,字母字符之间由单个空格分开:
^([[:alpha:]]+ ?)+$
echo "This that" | grep -E '^([[:alpha:]]+ ?)+$'
echo "a b c" | grep -E '^([[:alpha:]]+ ?)+$'
echo "a b 9" | grep -E '^([[:alpha:]]+ ?)+$'
echo "abc d" | grep -E '^([[:alpha:]]+ ?)+$'
我们看到这个正则表达式不匹配“a b 9”这一行,因为它包含了一个非字母的字符;
它也不 匹配“abc d”,因为在字符“c”和“d”之间不止一个空格。20.12.2 { } 匹配特定个数的元素
{ 和 } 元字符都被用来表达要求匹配的最小和最大数目。
| 限定符 |
意思 |
| n |
匹配前面的元素,如果它确切地出现了 n 次。(x=n) |
| n,m |
匹配前面的元素,如果它至少出现了 n 次,但是不多于 m 次。 |
| n, |
匹配前面的元素,如果它出现了 n 次或多于 n 次。 |
| ,m |
匹配前面的元素,如果它出现的次数不多于 m 次。 |
^\(?[0-9][0-9][0-9]\)? [0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]$
简化为
^\(?[0-9]{3}\)? [0-9]{3}-[0-9]{4}$
echo "(555) 123-4567" | grep -E '^\(?[0-9]{3}\)? [0-9]{3}-[0-9]{4}$'
echo "555 123-4567" | grep -E '^\(?[0-9]{3}\)? [0-9]{3}-[0-9]{4}$'
echo "5555 123-4567" | grep -E '^\(?[0-9]{3}\)? [0-9]{3}-[0-9]{4}$'20.13 让正则表达式工作起来
20.13.1 通过grep命令来验证一个电话薄(了解一下就行了)
for i in {1..10}; do echo "($ {RANDOM: 0:3}) $ {RANDOM: 0:3}- $ {RANDOM: 0:4}"
>> phonelist.txt; done
cat phonelist.txt
grep -Ev '^\([0-9]{3}\) [0-9]{3}-[0-9]{4}$' phonelist.txt20.13.2 用find查找丑陋的文件名
find 命令支持一个基于正则表达式的测试。
find 命令要求路径名精确地匹配这个正则表达式。
例子:在下面的 例子里面,我们将使用带有一个正则表达式的 find 命令,来查找每个路径名,其包含的任意字符都不是以下字符集中的一员。
[-\_./0-9a-zA-Z]
find . -regex '.*[^-\_./0-9a-zA-Z].*'
由于要精确地匹配整个路径名,所以我们在表达式的两端使用了.*,来匹配零个或多个字 符。
在表达式中间,我们使用了否定的中括号表达式,其包含了我们一系列可接受的路径名字 符。20.13.3 用locate 查找文件
locate 程序支持基本的(--regexp 选项)和扩展的(--regex 选项)正则表达式。通过 locate
命令,我们能够执行许多与先前操作 dirlist 文件时相同的操作:
locate --regex 'bin/(bz|gz|zip)'通过使用 alternation,我们搜索包含 bin/bz,bin/gz,或/bin/zip 字符串的路径名。
20.13.4 在less和vim中查找文本 (了解)
less 和 vim 两者享有相同的文本查找方法。按下/按键,然后输入正则表达式,来执行搜索任 务。如果我们使用 less 程序来浏览我们的 phonelist.txt 文件:
less phonelist.txt
(232) 298-2265
(624) 381-1078
(540) 126-1980
(874) 163-2885
(286) 254-2860
(292) 108-518
(129) 44-1379
(458) 273-1642
(686) 299-8268
(198) 307-2440
~
/^\([0-9]{3}\) [0-9]{3}-[0-9]{4}$
(232) 298-2265
(624) 381-1078
(540) 126-1980
(874) 163-2885
(286) 254-2860
(292) 108-518
(129) 44-1379
(458) 273-1642
(686) 299-8268
(198) 307-2440
~
(END)另一方面,vim 支持基本的正则表达式,所以我们用于搜索的表达式看起来像这样:
/([0-9]\{3\}) [0-9]\{3\}-[0-9]\{4\}
依赖于系统中 vim 的特殊配置,匹配项将会被高亮。如若不是,试试这个命令模式:
:hlsearch
来激活搜索高亮功能。第二十一章 ——文本处理
这一章用到的命令:
1. cat —— 连接文件并且打印到标准输出
2. sort ——给文本行排序
3. uniq (忽略,省略)——报告或忽略重复行
3. cut ——从每行中删除文本区域
4. paste(粘贴)—— 合并文件文本行
5. join —— 基于某个共享字段来联合两个文件的文本行
6. comm —— 逐行比较两个有序的文件
7. diff —— 逐行比较文件
8. patch(补丁)—— 给原始文件打补丁
9. tr —— 翻译或删除字符
10. sed —— 用于筛选和转换文本的流编辑器
11. aspell——交互式拼写检查器
21.1 文本应用程序
21.1.1 文档(了解)
21.1.2 网页(了解)
21.1.3 电子邮件(了解)
21.1.4 打印输出(了解)
21.1.5 源码程序(了解)
21.2 回顾一些老朋友
21.2.1 cat (连接文件并打印到标准输出)
创建一个测试文件,用 cat 程序作为一个简单的文字处理器。键入 cat 命令(随后指定了用于重定向输出的文件),然后输入我们的文本,最后按下 Enter 键来结束 这一行,然后按下组合键 Ctrl-d,来指示 cat 程序,我们已经到达文件末尾了。
文本行的开头和末尾分别键入了一个 tab 字符以及一些空格。
cat > foo.txt下一步,我们将使用带有-A 选项的 cat 命令来显示这个文本:
cat -A foo.txt
^IThe quick brown fox jumped over the lazy dog. $cat 程序也包含用来修改文本的选项。最著名的两个选项是-n,其给文本行添加行号和-s, 禁止输出多个空白行,多余的空白行被删除。 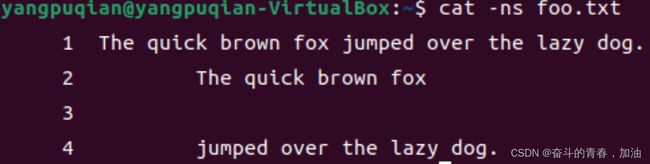
21.2.2 sort (给文本行排序)
sort和cat用法相似,sort对标准输入的内容,或命令行中指定的一个或多个文件进行排序,然后把排序结果发送到标准输出。
sort > foo.txt
cat foo.txtsort能接受命令行中的多个文件作为参数,所以有可能把多个文件合并成一个有序的文件。
sort file1.txt file2.txt file3.txt > final_sorted_list.txt还有一些 sort的命令 man sort来查看就行。
看一下 -n选项:用来做数值排序。
du 命令可以确定最大的磁盘空间用户。du命令列出的输出结果按照路径名来排序。
du -s /usr/share/* | head 限制为前 10 行
显示 10 个最大的空间消费者:
du -s /usr/share/* | sort -nr | head
-nr 选项,我们产生了一个反向的数值排序,最大数值排列在第一位。
这种排序起作用是因为数值出现在每行的开头如果我们想要基于文件行中的某个数值排序,又会 怎样呢?
例如,命令 ls -l 的输出结果:
ls -l /usr/bin | head
使用 sort 程序来完成 此任务:
ls -l /usr/bin | sort -nr -k 5 | head
-rwxr-xr-x 1 root root 8234216 2008-04-07 17:42 inkscape
第五个字段是文件 大小
指定 -k 5,让 sort 程序使用第五字段作为排序的关键值。
思考题(难度还行):
包含从 2006 年到 2008 年三款流行的 Linux 发行版的发行历 史,来做一系列实验。文件中的每一行都有三个字段:发行版的名称,版本号,和 MM/DD/ YYYY 格式的发行日期:
SUSE 10.2 12/07/2006
Fedora 10 11/25/2008
SUSE 11.04 06/19/2008
Ubuntu 8.04 04/24/2008
Fedora 8 11/08/2007
SUSE 10.3 10/04/2007
使用一个文本编辑器(可能是 vim),我们将输入这些数据,并把产生的文件命名为 distros.txt。
下一步,我们将试着对这个文件进行排序,并观察输出结果:
sort distros.txt
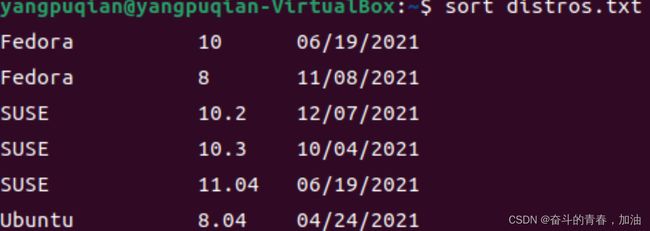 问题出现在 Fedora 的版本号上。因为在字符集中“1”出现在“5”之前, 版本号“10”在最顶端,然而版本号“9”却掉到底端。
问题出现在 Fedora 的版本号上。因为在字符集中“1”出现在“5”之前, 版本号“10”在最顶端,然而版本号“9”却掉到底端。
为了解决这个问题,我们必须依赖多个键值来排序。
对第一个字段执行字母排序, 然后对第三个字段执行数值排序。sort 程序允许多个 -k 选项的实例,所以可以指定多个排序 关键值。
多键值排序的语法:
sort --key=1,1 --key=2n distros.txt
为了清晰,我们使用了选项的长格式,但是 -k 1,1 -k 2n 格式是等价的。
-k 1,1:始于并且结束于第一个字段
-k 2n:第二个字段 是排序的键值,并且按照数值排序。
b(忽略开头的空格),n(数 值排序),r(逆向排序)

列表中第三个字段包含的日期格式不利于排序,幸运地是,sort 程序提供了一种方式。
sort -k 3.7nbr -k 3.4nbr -k 3.1nbr distros.txt
-k 3.7:其始于第三个字段中的第七个字符,对应于年的开头。
-k 3.1 和 -k 3.4 来分离日期中的月和日。
我们也添加 了 n 和 r 选项来实现一个逆向的数值排序。
这个 b 选项用来删除日期字段中开头的空格。一些文件不会使用 tabs 和空格做为字段界定符;例如,这个 /etc/passwd 文件:
head /etc/passwd
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/bin/sh
bin:x:2:2:bin:/bin:/bin/sh
sys:x:3:3:sys:/dev:/bin/sh
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/bin/sh
man:x:6:12:man:/var/cache/man:/bin/sh
lp:x:7:7:lp:/var/spool/lpd:/bin/sh
mail:x:8:8:mail:/var/mail:/bin/sh
news:x:9:9:news:/var/spool/news:/bin/sh
文件的字段之间通过冒号分隔开,所以我们怎样使用一个 key 字段来排序这个文件?
sort 程序提供了一个 -t 选项来定义分隔符。按照第七个字段(帐户的默认 shell)来排序此 passwd 文件,我们可以这样做:
sort -t ':' -k 7 /etc/passwd | head
通过指定冒号字符做为字段分隔符,我们能按照第七个字段来排序。21.2.3 uniq
uniq是一个轻量级程序与sort程序相比。会删除重复的行,把结果发送到标准输出。经常与sort程序一起使用,来清理重复的行。
建一个文本文件,来实验一下:
cat > foo.txt
a
b
c
a
b
c
对文本文件执行 uniq 命令:
uniq foo.txt
a
b
c
a
b
c
输出结果与原始文件没有差异;重复行没有被删除。实际上,
uniq 程序能完成任务,其输入必须是排好序的数据,
sort foo.txt | uniq
a
b
c
这是因为 uniq 只会删除相邻的重复行
sort foo.txt | uniq -c
man uniq 查看一些uniq的命令选项。21.3 切片和切块
21.3.1 cut(从每行中删除文本区域)
从文本行中抽取文本,输出到标准输出。
它能够接受多个文件参数或者标准输入。cut 程序抽取文本的方式相当不灵活。
cut 命令最好用来从其它程 序产生的文件中抽取文本,而不是从人们直接输入的文本中抽取。
cut 的选项:常用的两个
-c char_list 从文本行中抽取由 char_list 定义的文本
-f field_list 从文本行中抽取一个或多个由 field_list 定义的字段
-d delim_char 当指定-f 选项之后,使用 delim_char 做为字段分隔符
使用带有 -A 选项的 cat 命令
cat -A distros.txt
使用 -f 选项来抽取一个字段
cut -f 3 distros.txt
因为 distros 文件是由 tab 分隔开的,最好用 cut 来抽取字段而不是字符
cut -f 3 distros.txt | cut -c 7-10
通过对我们的列表再次运行 cut 命令,我们能够抽取从位置 7 到 10 的字符
当操作字段的时候,有可能指定不同的字段分隔符,而不是 tab 字符。
这里我们将会从/ etc/passwd 文件中抽取第一个字段:
cut -d ':' -f 1 /etc/passwd | head
使用-d 选项,我们能够指定冒号做为字段分隔符。
21.3.2 paste (合并文件文本行)
这个和cut相反,它会添加一个或多个文本列到文件中,而不是从文件中抽取文本列。
它通过读取多个文件,然后把每个文件中的字段整合成单个文本流,输入到标准输出。
从我们之前使用 sort 的工作中,首先我们将产生一个按照日期排序的发行版列表,并把结 果存储在一个叫做 distros-by-date.txt 的文件中:
sort -k 3.7nbr -k 3.1nbr -k 3.4nbr distros.txt > distros-by-date.txt
下一步,我们将会使用 cut 命令从文件中抽取前两个字段(发行版名字和版本号),
并把结 果存储到一个名为 distro-versions.txt 的文件中:
cut -f 1,2 distros-by-date.txt > distros-versions.txt
head distros-versions.txt
最后的准备步骤是抽取发行日期,并把它们存储到一个名为 distro-dates.txt 文件中:
cut -f 3 distros-by-date.txt > distros-dates.txt
head distros-dates.txt
现在我们拥有了我们所需要的文本了。为了完成这个过程,使用 paste 命令来把日期列放到 发行版名字和版本号的前面,这样就创建了一个年代列表。通过使用 paste 命令,然后按照期 望的顺序来安排它的参数,就能很容易完成这个任务。
paste distros-dates.txt distros-versions.txt21.3.3 join(联合两个文件的文本行)
其实这个join和关系型数据库连接两个数据库表原理差不多。也是通过关键的键来连接。
比如:有一个表叫做客户表字段有:客户号,客户的名字,客户的姓
另一个表订单表字段有:订单号,客户号,数量,订购的货品。
我们就可以通过客户号把这两个表连接起来。
为了说明join程序的原理,要先创建两个文件,这两个文件同时包含一对共享键值,然后还有相同的字段——日期。两个文件分别为发行日期和发行版名称。
1.cut -f 1,1 distros-by-date.txt > distros-names.txt
paste distros-dates.txt distros-names.txt > distros-key-names.txt
head distros-key-names.txt
2. 第二个文件包含发行日期和版本号:
cut -f 2,2 distros-by-date.txt > distros-vernums.txt
paste distros-dates.txt distros-vernums.txt > distros-key-vernums.txt
head distros-key-vernums.txt
现在我们有两个具有共享键值,有必要指出,为了使 join 命 令能正常工作,
所有文件必须按照关键数据域排序。
join distros-key-names.txt distros-key-vernums.txt | head
21.4 比较文本
通常比较文本文件的版本很有帮助。比如,需要拿现有的配置文件与先前的版本作比较,来诊断一个系统错误或一些代码版本出现的报错。
21.4.1 comm(逐行比较两个有序的文件)
比较两个文本文件,并且会显示每个文件特有的文本行和共有的文本行。
cat > file1.txt
a
b
c
d
cat > file2.txt
b
c
d
e
comm file1.txt file2.txt
a
b
c
d
ecomm 支持 -n 形式的选项,这里 n 代表 1,2 或 3。这些选项使用的时候,指定了要隐藏的列
comm -12 file1.txt file2.txt
b
c
d21.4.2 diff (逐行比较文件)
diff 程序被用来监测文件之间的差异。它比较复杂,支持许多输出格式,并且一次能处理许多文本文件。diff的一个常见用例是创建diff文件或者补丁,它会被其他程序使用,例如:patch程序,来把文件从一个版本装换为另一个版本。
diff file1.txt file2.txt
1d0
e
diff 程序的默认输出风格:对两个文件之间差异的简短描述| 改变 |
说明 |
| r1ar2 |
把第二个文件中位置 r2 处的文件行添加到第一个文件中的 r1 处。 |
| r1cr2 |
用第二个文件中位置 r2 处的文本行更改(替代)位置 r1 处 的文本行。 |
| r1dr2 |
删除第一个文件中位置 r1 处的文本行,这些文本行将会出 现在第二个文件中位置 r2 处。 |
diff 的格式:1. 上下文模式
2. 统一模式
1. 上下文模式: 带上 -c 选项
diff -c file1.txt file2.txt 这个输出结果以两个文件名和它们的时间戳开头。第一个文件用星号做标记,第二个文件 用短横线做标记。
这个输出结果以两个文件名和它们的时间戳开头。第一个文件用星号做标记,第二个文件 用短横线做标记。
*** 1,4 *** 其表示第一个文件中从第一行到第四行的文本行
--- 1,4 --- 这表示第二个文件中从第一行到第四行的文本行。
| 指示符 |
意思 |
| blank |
上下文显示行。它并不表示两个文件之间的差异。 |
| - |
删除行。这一行将会出现在第一个文件中,而不是第二个文 件内。 |
| + |
添加行。这一行将会出现在第二个文件内,而不是第一个文 件中。 |
| ! |
更改行。将会显示某个文本行的两个版本,每个版本会出现 在更改组的各自部分。 |
这个统一模式相似于上下文模式,但是更加简洁。通过 -u 选项来指定它 ,上下文模式和统一模式之间最显著的差异就是重复上下文的消除,这就使得统一模式的输 出结果要比上下文模式的输出结果简短。
字符串 @@ -1,4 +1,4 @@表示了在更改组中描述的第一 个文件中的文本行和第二个文件中的文本行。这行字符串之后就是文本行本身,与三行默认的 上下文
 21.4.3 patch(给原文件打补丁)
21.4.3 patch(给原文件打补丁)
把更改应用到文本文件中。它接收从diff程序的输出,并且通常被用来把较老的文件版本转变为较新的文件版本。
使用diff/patch组合提供了两个重大优点。
1. 一个 diff 文件非常小,与整个源码树的大小相比较而言。
2. 一个 diff 文件简洁地显示了所做的修改,从而允许程序补丁的审阅者能快速地评估它。
当然,diff/patch 能工作于任何文本文件,不仅仅是源码文件。它同样适用于配置文件或任 意其它文本。
准备一个 diff 文件供 patch 程序使用,建议这样使 用 diff 命令:
diff -Naur old_file new_file > diff_file
patch < diff_file
我们将使用测试文件来说明:
diff -Naur file1.txt file2.txt > patchfile.txt
patch < patchfile.txt
输出 patching file file1.txt
cat file1.txt
b
c
d
e
建了一个名为 patchfile.txt 的 diff 文件,然后使用 patch 程序,来 应用这个补丁。
一旦应用了补丁,我们能看到,现在 file1.txt 与 file2.txt 文件 相匹配了。
21.5 运行时编辑
21.5.1 tr
用来更改字符。基于字符的查找和替换操作。
换字是一种把字符从一个字母转换为另一个字母的过程。例如:把小写字母转换成大写字母就是换字——通过tr命令来执行这样的替换。
echo "lowercase letters" | tr a-z A-Ztr 命令操作标准输入,并把结果输出到标准输出。
tr 命令接受两个参数:要 被转换的字符集以及相对应的转换后的字符集。字符集可以用三种方式来表示 :
1. 一个枚举列表。例如,ABCDEFGHIJKLMNOPQRSTUVWXYZ
2. 一个字符域。例如,A-Z 。
3. POSIX 字符类。例如,[:upper:]
echo "lowercase letters" | tr [:lower:] A
AAAAAAAAA AAAAAAAtr 也可以完成另一个技巧。使用-s 选项,tr 命令能“挤压”(删除)重复的字符实例:
echo "aaabbbccc" | tr -s ab
abccc
注意重复的字符必须 是相邻的。如果它们不相邻:那么挤压会没有效果。
echo "abcabcabc" | tr -s ab
abcabcabc
21.5.2 sed(stream editor流编辑器)
对文本流,即一系列指定的文件或标准输入进行编辑。
sed 的工作方式是要不给出单个编辑命令(在命令行中)要不就是包含多个命令的脚 本文件名,然后它就执行这些命令.
echo "front" | sed 's/front/back/'
back在这个例子中,我们使用 echo 命令产生了一个单词的文本流,然后把它管道给 sed 命令。我们也能够把这个命令认为 是相似于 vi 中的“替换”(查找和替代)命令。把front替换为back。
这个替换命令由字母 s 来代表,其后跟着 查找和替代字符串,斜杠字符做为分隔符。
sed 将会接受紧随命令之后的任意字符做为分隔符。我们可以按照这种方式来执行 相同的命令:
cho "front" | sed 's_front_back_'
back
通过紧跟命令之后使用下划线字符,则它变成界定符sed 中的大多数命令之前都会带有一个地址,其指定了输入流中要被编辑的文本行。如果省 略了地址,然后会对输入流的每一行执行编辑命令。最简单的地址形式是一个行号。我们能够 添加一个地址到我们例子中:
echo "front" | sed '1s/front/back/'
back给我们的命令添加地址 1,就导致只对仅有一行文本的输入流的第一行执行替换操作。如果 我们指定另一个数字:
echo "front" | sed '2s/front/back/'
front
我们看到没有执行这个编辑命令,因为我们的输入流没有第二行。
地址可以用许多方式来 表达。这里是最常用的:sed的地址表示法:
| 地址 |
说明 |
| n |
行号,n 是一个正整数。 |
| $ |
最后一行。 |
| /regexp/ |
所有匹配一个 POSIX 基本正则表达式的文本行。注意正则 表达式通过斜杠字符界定。 |
| addr1,addr2 |
从 addr1 到 addr2 范围内的文本行,包含地址 addr2 在内。 |
| first ̃step |
匹配由数字 first 代表的文本行,然后随后的每个在 step 间 隔处的文本行。例如 1 ̃2 是指每个位于奇数行号的文本行, 5 ̃5 则指第五行和之后每五行位置的文本行。 |
| addr1,+n |
匹配地址 addr1 和随后的 n 个文本行。 |
| addr! |
匹配所有的文本行,除了 addr 之外, |
sed -n '1,5p' distros.txt
开始于第一行,直到第五行,
p 命令,其就是简单地把匹配的文本行打印出来正则表达式:
sed -n '/SUSE/p' distros.txt最后,我们将试着否定上面的操作,通过给这个地址添加一个感叹号
sed -n '/SUSE/!p' distros.txt输出了文件中所有的文本行,除了那些匹配这个正则表达式的文 本行。
sed基本的编辑命令:
| 命令 |
说明 |
| = |
输出当前的行号。 |
| a | 在当前行之后追加文本。 |
| d | 删除当前行。 |
| i | 在当前行之前插入文本。 |
| p | 打印当前行。 |
| q | 退出 sed,不再处理更多的文本行。如果不指定-n 选项,输 出当前行。 |
| Q | 退出 sed,不再处理更多的文本行。 |
| s/ regexp/ replace- ment/ |
只要找到一个 regexp 匹配项,就替换为 replacement 的内 容。 |
| y/set1/set2 |
执行字符转写操作,通过把 set1 中的字符转变为相对应的 set2 中的字符。注意不同于 tr 程序,sed 要求两个字符集合 具有相同的长度。 |
到目前为止,这个 s 命令是最常使用的编辑命令。
文件中的日期格式是 MM/DD/YYYY,但如果格式是 YYYY-MM-DD 会更好一些。
sed 's/\([0-9]\{2\}\)\/\([0-9]\{2\}\)\/\([0-9]\{4\}\)$/\3-\1-\2/' distros.txt
让我们看一下怎样来构建它。首先,我们知道此命令有这样一个基本的结构:
sed 's/regexp/replacement/' distros.txt
因为日期是 MM/DD/YYYY 格 式,并且出现在文本行的末尾,我们可以使用这样的表达式:
[0-9]{2}/[0-9]{2}/[0-9]{4}$
创建这个子表达式,我们简单地把它们用圆括号括起来,像这样
([0-9]{2})/([0-9]{2})/([0-9]{4})$
现在我们有了三个子表达式。第一个表达式包含月份,第二个包含某月中的某天,以及第三 个包含年份。
现在我们就可以构建 replacement ,如下所示:
\3-\1-\2
此表达式给出了年份,一个短划线,月份,一个短划线,和某天。现在我们的命令看起来像下面这样:
sed 's/([0-9]{2})/([0-9]{2})/([0-9]{4})$/\3-\1-\2/' distros.txt
最后通过反斜杠来解决字符的问题。一个最重要的可选标志是 g 标 志,其指示 sed 对某个文本行全范围地执行查找和替代操作,不仅仅是对第一个实例,这是默 认行为。这里有个例子:
echo "aaabbbccc" | sed 's/b/B/'
aaaBbbccc
echo "aaabbbccc" | sed 's/b/B/g'
aaaBBBcccP304-306自己看就行了,主要是编写sed脚本,我已经编写好了,在Linux中。
21.5.3 aspell ——交互式的拼写检查器会把自己写错的单词检查出来然后修改掉
语法: aspell check 文件名
作为一个实际例子,让我们创建一个简单的文本文件, 叫做 foo.txt,包含一些故意的拼写错误:
cat > foo.txt
The quick brown fox jimped over the laxy dog.
下一步我们将使用 aspell 来检查文件:
aspell check foo.txt
aspell 会认为 HTML 标志的内容是拼写错误。
通过包含-H(HTML)检查模式选项,
这个 问题能够解决,像这样:
aspell -H check foo.txt
这个 HTML 标志被忽略了,并且只会检查文件中非标志部分的内容。
在这种模式下, HTML 标志的内容被忽略了,不会进行拼写检查。
然而,ALT 标志的内容,会被检查。
详细内容查看 aspell 命令手册。22. 格式化输出
这一张将要用到的命令:
1. nl ——添加行号
2. fold ——限制文件列宽
3. fmt —— 一个简单的文本格式转换器
4. pr ——让文本为打印做好准备
5. printf——格式化数据并打印出来
6. groff —— 一个文件格式系统
22.1 简单的格式化工具
22.1.1 nl ——添加行号
nl foo.txt | head
nl 相当于 cat -n:
像 cat,nl 既能接受多个文件作为命令行参数,也能接受标准输入。22.1.2 fold ——限制文件行宽
折叠是将文本的行限制到特定的宽的过程。
echo "The quick brown fox jumped over the lazy dog." | fold -w 12这里我们看到了 fold 的行为。这个用 echo 命令发送的文本用 -w 选项分解成块。在这个例 子中,我们设定了行宽为 12 个字符。
22.1.3 fmt ——一个简单的文本格式器
fmt 程序同样折叠文本,外加很多功能。它接受文本或标准输入并且在文本流上格式化段落。 它主要是填充和连接文本行,同时保留空白符和缩进。
fmt -w 50 fmt-info.txt | head
fmt -c 50 fmt-info.txt | head默认情况下,输出会保留空行,单词之间的空格,和缩进;持续输入的具有不同缩进的文本 行不会连接在一起;tab 字符在输入时会展开,输出时复原。
通过添加 -c 选项,现在我们得到了所期望的结果。
cat > fmt-code.txt
fmt -w 50 -p '# ' fmt-code.txt注意相邻的注释行被合并了,空行和非注释行被保留了。
22.1.4 pr ——格式化打印文本
pr 程序用来把文本分页 。当打印文本的时候,经常希望用几个空行在输出的页面的顶部或底部 添加空白。此外,这些空行能够用来插入到每个页面的页眉或页脚。
pr -l 15 -w 65 distros.txt在上面的例子中,我们用 -l 选项(页长)和 -w 选项(页宽)定义了宽 65 列,长 15 行的一 个“页面”。
22.1.5 printf ——格式化数据并打印出来
printf “format” arguments
printf "I formatted the string: %s\n" foo
I formatted the string: foo格式字符串可能包含文字文本(如“我格式化了这个字符串:”“I formatted the string:”), 转义序列(例如\n,换行符)和以%字符开头的序列,这被称为转换规范。在上面的例子中,转 换规范%s 用于格式化字符串“foo”并将其输出在命令行中。我们再来看一遍:
printf "I formatted '%s' as a string.\n" foo
I formatted 'foo' as a string.我们可以看到,在命令行输出中,转换规范%s 被字符串“foo”所替代。s 转换用于格式化 字符串数据。
| 组件 |
描述 |
| d |
将数字格式化为带符号的十进制整数 |
| f | 格式化并输出浮点数 |
| o | 将整数格式化为八进制数 |
| s | 将字符串格式化 |
| x | 将整数格式化为十六进制数,必要时使用小写 a-f |
| X | 与 x 相同,但变为大写 |
| % | 打印% 符号 (比如,指定“%%”) |
printf "%d, %f, %o, %s, %x, %X\n" 380 380 380 380 380 380
380, 380.000000, 574, 380, 17c, 17C完整的转换规范包含以下 内容:
%[flags][width][.precision]conversion_specification| 组件 |
描述 |
| flags |
有 5 种不同的标志: # –使用“备用格式”输出。这取决于 数据类型。对于 o(八进制数)转换,输出以 0 为前缀. 对于 x 和 X(十六进制数)转换,输出分别以 0x 或 0X 为前缀。 0–(零) 用零填充输出。这意味着该字段将填充前导零,比 如“000380”。 ‘’–(空格) 在正数前空一格。 |
| width |
指定最小字段宽度的数。 |
| .precision |
对于浮点数,指定小数点后的精度位数。对于字符串转换, 指定要输出的字符数。 |
| 自变量 |
格式 |
结果 |
备注 |
| 380 |
”%d” |
380 |
简单格式化 整数。 |
| 380 | ”%#x” |
0x17c |
使用“替代 格式”标志 将整数格式 化为十六进 制数。 |
| 380 | ”%05d” |
00380 |
用前导零(padding)格式 化 整 数且最小字段 宽度为五个 字符。 |
| 380 | ”%05.5f” |
380.00000 |
使用前导零 和五位小数 位精度格式 化数字为浮 点数。由于 指定的最小 字段宽度(5) 小于格式化 后数字的实 际宽度,因 此前导零这 一命令实际 上没有起到 作用。 |
| 380 | ”%010.5f” |
0380.00000 |
将最小字段 宽度增加到 10,前导零 现在变得可 见。 |
| 380 | ”%+d” |
+380 |
使用+标 志标记正 数。 |
| 380 | ”%-d” |
380 |
使用-标志 左对齐 |
| abcdefghijk |
”%5s” |
abcedfghijk |
用最小字段 宽度格式化 字符串。 |
| abcdefghijk |
”%d” |
abcde |
对字符串应 用精度,它 被从中截 断。 |
printf "%s\t%s\t%s\n" str1 str2 str3
str1 str2 str3printf "Line: %05d %15.3f Result: %+15d\n" 1071
3.14156295 32589
Line: 01071 3.142 Result: +32589通过插入\t(tab 的转义序列),我们实现了所需的效果。接下来,我们让一些数字的格式变 得整齐:
printf "Line: %05d %15.3f Result: %+15d\n" 1071 3.14156295 32589这显示了最小字符宽度对字符间距的影响。或者,让我们看看如何格式化一个小网页:
printf"\n\t\n\t\t%s \n\t\n\t\n\t\t%s
\n\t\n\n" "Page Title" "Page Content"
22.2 Document Formatting Systems
22.3 文件格式系统
22.3.1 groff ——一个文件格式系统
23. 打印
这一章用到的命令:
1. pr——转换需要打印的文本文件
2. lpr——打印文件
3. lp——打印文件
4. a2ps——为PostScript打印机格式化文件
5. lpstat——显示打印机状态信息
6. lpq——显示打印机队列状态
7.lprm——取消打印任务
8. cancel——取消打印任务
23.1 打印简史
23.1.1 早期的打印
23.1.2 基于字符的打印机
zcat /usr/share/man/man1/ls.1.gz | nroff -man | cat -A | head
ˆH(ctrl-H)字符是用于打印粗体效果的退格符。同样,我们还可以看到用于打印下划线效 果的 [退格/下划线] 序列。

23.1.3 图形化打印机
23.2 在Linux下打印
当前 Linux 系统采用两套软件配合显示和管理打印。第一,CUPS(Common Unix Printing
System,一般 Unix 打印系统),用于提供打印驱动和打印任务管理;第二,Ghostscript,一种PostScript 解析器,作为 RIP 使用。
23.3 为打印准备文件
作为命令行用户,尽管打印各种格式的文本都能实现,不过打印最多的,还是文本。
23.3.1 pr —转换需要打印的文本文件
| 选项 |
描述 |
| +first[:last] |
输出从 first 到 last(默认为最后)范围内的页面。 |
| -columns |
根据 columns 指定的列数排版页面内容。 |
| -a |
默认多列输出为垂直,用 -a (across) 可使其水平输出。 |
| -d |
双空格输出。 |
| -D format |
用 format 指定的格式修改页眉中显示的日期,日期命令中 format 字符串的描述详见参考手册。 |
| -f |
改用换页替换默认的回车来分割页面。 |
| -h header |
在页眉中部用 header 参数替换打印文件的名字。 |
| -l length |
设置页长为 length,默认为 66 行(每英寸 6 行的美国信 纸)。 |
| -n |
输出行号。 |
| -o offset |
创建一个宽 offset 字符的左页边。 |
| -w width |
设置页宽为 width,默认为 72 字符。 |
我们通常用管道配合 pr 命令来做筛选。下面的例子中我们会列出目录 /usr/bin 并用 pr 将其格式化为 3 列输出的标题页:
ls /usr/bin | pr -3 -w 65 | head
23.4 将打印任务送至打印机
CUPS 打印体系支持两种曾用于类 Unix 系统的打印方式。一种,叫 Berkeley 或 LPD(用于 Unix 的 Berkeley 软件发行版),使用 lpr 程序;另一种,叫 SysV(源自 System V 版本的 Unix), 使用 lp 程序。这两个程序的功能大致相同。具体使用哪个完全根据个人喜好。
23.4.1 lpr —打印文件(Berkeley 风格)
lpr程序可以用来把文件传送给打印机。由于它能接收标准输入,所以能用管道来协同工作。
例如,要打印多列目录列表的结果:
ls /usr/bin | pr -3 | lpr报告会送到系统默认的打印机,如果要送到别的打印机,可以使用 -P 参数
lpr -P printer_nameprinter_name 表示这台打印机的名称。若要查看系统已知的打印机列表:
lpstat -alpr 的一些常用选项:
| 选项 |
描述 |
| -# number |
设定打印份数为 number。 |
| -p |
使每页页眉标题中带有日期、时间、工作名称和页码。这 种所谓的“美化打印”选项可用于打印文本文件。 |
| -P printer | 指定输出打印机的名称。未指定则使用系统默认打印机。 |
| -r | 打印后删除文件。对程序产生的临时打印文件较为有用。 |
23.4.2 lp— 打印文件(System V 风格)
和 lpr 一样,lp 可以接收文件或标准输入为打印内容。与 lpr 不同的是 lp 支持不同的选项(略 为复杂)。

再次打印我们的目录列表,这次我们设置 12 CPI、8 LPI 和一个半英寸的左边距。注意这
里我必须调整 pr 选项来适应新的页面大小:
ls /usr/bin | pr -4 -w 90 -l 88 | lp -o page-left=36 -o cpi=12 -o lpi=8这条命令用小于默认的格式产生了一个四列的列表。增加 CPI 可以让我们在页面上打印更 多列。
23.4.3 另一种选择: a2ps
a2ps 程序很有趣。单从名字上看,这是个格式转换程序,但它的功能不止于此。程序名字的本 意为 ASCII to PostScript,它是用来为 PostScript 打印机准备要打印的文本文件的 。
但它实际的功能却是打印。它的默认输出不是标准输出,而是系统的默认打印机。程序的 默认行为被称为“漂亮的打印机”,这意味着它可以改善输出的外观。我们能用程序在桌面上创 建一个 PostScript 文件:
ls /usr/bin | pr -3 -t | a2ps -o ~/Desktop/ls.ps -L 66这里我们用带 -t 参数(忽略页眉和页脚)的 pr 命令过滤数据流,然后用 a2ps 指定一个输 出文件(-o 参数),并设定每页 66 行(-L 参数)来匹配 pr 的输出分页。


23.5 监视和控制打印任务
23.5.1 lpstat—显示打印系统状态
lpstat 程序可用于确定系统中打印机的名字和有效性。
例如,我们系统中有一台实体打印机
(名叫 printer)和一台 PDF 虚拟打印机(名叫 PDF),我们可以像这样查看打印机状态:
lpstat -a接着,我们可以查看打印系统更具体的配置信息:
lpstat -s 
23.5.2 lpq — 显示打印机队列状态
如果我们不指定打印机(用 -P 参数),就会显示系统默认打印机。如果给打印机添加一项 任务再查看队列,我们就会看到下列结果:
ls *.txt | pr -3 | lp
lpq23.5.3 lprm和cancel—取消打印任务
CUPS 提供两个程序来从打印队列中终止并移除打印任务。一个是 Berkeley 风格的(lprm), 另一个是 System V 的(cancel)。
我们可以像这样终止并移除任务:
cancel 603
lpq24 编译程序
为什么要编译软件呢?有两个原因:
1. 可用性
2. 及时性
make - 维护程序的工具
24.1 什么是编译?
编译就是把源码翻译成计算机处理 器的语言的过程。
24.1.1 所有的程序都是可编译的吗?
不是。比如 shell 脚本就不需要编译。它们直接执行。这些程序是 用所谓的脚本或解释型语言编写的。近年来,这些语言变得越来越流行,包括 Perl、Python、 PHP、Ruby 和许多其它语言。
24.2 编译一个 C 语言
在编译之前,然而我们需要一些工具,像编译器、链接器以及 make。在 Linux 环境中,普遍使用的 C 编译器叫做 gcc(GNU C 编译器)。大多数 Linux 系统发行版默认不安装 gcc。我们可以这样查看该编译器是 否存在:
which gcc
/usr/bin/gcc
输出结果表明安装了 gcc 编译器。24.2.1 得到源码
25 ——编写第一个Shell脚本
25.1 什么是Shell脚本 ?
最简单的解释,一个shell脚本就是一个包含一系列命令的文件。
shell读取这个文件,然后执行文件中的所有命令。
shell不仅是一个功能强大的命令行接口,也是一个脚本语言解释器。
大多数能够在命令行中完成的任务也能够用脚本来实现,反之也是可以的。
shell也提供了一些通常在编写程序时才使用的功能。
25.2 怎样编写一个shell脚本
1. 编写一个脚本,shell脚本就是普通的文件。我们需要一个文本编辑器来书写它们。
2. 使脚本文件可执行。
3. 把脚本放置到shell能够找到的地方。
25.3 脚本文件格式
#!/bin/bash
# This is our first script.
echo 'Hello World!' # This is a comment too
此脚本文件保存为 hello_world
echo 'Hello World!' # This is a comment too25.4 可执行权限
ls -l hello_world
chmod 755 hello_world
ls -l hello_world对于脚本文件,有两个常见的权限设置;权限为 755 的脚本,则每个人都能执行,和权限为 700 的脚本,只有文件所有者能够执行。注意为了能够执行脚本,脚本必须是可读的。
25.5 脚本文件位置
当设置了脚本权限之后,我们就能执行我们的脚本了:
./hello_world
为了能够运行此脚本,我们必须指定脚本文件明确的路径。如果我们没有那样做,我们会得 到这样的提示:
hello_world
bash: hello_world: command not foundecho $PATH
/home/me/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:
/bin:/usr/games
注意列表中的第一个目录/home/me/bin创建了一个 bin 目录,并把我们的脚本放在这个目录下,那么这个脚本就 应该像其它程序一样开始工作了:
mkdir bin
mv hello_world bin
hello_world
Hello World!如果这个 PATH 变量不包含这个目录,我们能够轻松地添加它,通过在我们的.bashrc 文件 中包含下面这一行文本:
export PATH=~/bin:"$PATH"当做了这个修改之后,它会在每个新的终端会话中生效。为了把这个修改应用到当前的终 端会话中,我们必须让 shell 重新读取这个.bashrc 文件.
. .bashrc25.5.1 脚本文件的好去处
这个 ∼/bin 目录是存放为个人所用脚本的好地方。
如果我们编写了一个脚本,系统中的每个用 户都可以使用它,那么这个脚本的传统位置是 /usr/local/bin。
系统管理员使用的脚本经常放 到 /usr/local/sbin 目录下。
大多数情况下,本地支持的软件,不管是脚本还是编译过的程序, 都应该放到 /usr/local 目录下,而不是在 /bin 或 /usr/bin 目录下。
25.6 更多的格式技巧
脚本书写的关键目标之一是为了易于维护;也就是说,一个脚本可以轻松地被作者或其它用户修改,使它适应变化的需求。使脚本容易阅读和理解是一种方便维护的方法。
25.6.1 长选项名称
我们学过的许多命令都以长短两种选项名称为特征。例如,这个 ls 命令有许多选项既可以用短形式也可以用长形式来表示。例如:
ls -ad 短
ls --all --directory 长
这两个是相等的。
个人更推荐短格式,当然长格式也是可以的。
25.6.2 缩进和行继续符
当使用长命令的时候,通过把命令在几个文本行中展开,可以提高命令的可读性。在第十八章
中,我们看到了一个特别长的 find 命令实例:
find playground \( -type f -not -perm 0600 -exec
chmod0600‘{}’ ‘;’\)-or\(-typed-not-perm0711-exec chmod
0711 ‘{}’ ‘;’ \)显然,这个命令有点儿难理解,当第一眼看到它的时候。在脚本中,这个命令可能会比较容 易理解,如果这样书写它:
find playground \
\( \
-type f \
-not -perm 0600 \
-exec chmod 0600 ‘{}’ ‘;’ \
\) \
-or \
\( \
-type d \
-not -perm 0711 \
-exec chmod 0711 ‘{}’ ‘;’ \
\)26 ——启动一个项目
目的:为了了解怎样使用各种各样的shell功能来创建程序,更重要的是,创建好程序。
编写的程序是一个报告生成器。它会显示系统的各种统计数据和它的状态,并将产生HTML格式的报告,所以我们能通过网络浏览器,比如说火狐浏览器,来查看这个报告。
通常,创建程序要经过一系列阶段,每个阶段会添加新的特性和功能。我们程序的第一个阶段将会产生一个非常小的HTML网页,其不包含系统信息。随后我们会添加这些信息。
26.1 第一阶段:最小的文档
首先我们需要知道的事是一个规则的 HTML 文档的格式。它看起来像这样:

如果我们将这些内容输入到文本编辑器中,并把文件保存为 foo.html,然后我们就能在 Firefox 中使用下面的 URL 来查看文件内容:
file:///home/username/foo.html
username:自己的用户名yangpuqian程序的第一个阶段将这个 HTML 文件输出到标准输出。我们可以编写一个程序,相当容易 地完成这个任务。启动我们的文本编辑器,然后创建一个名为 ∼/bin/sys_info_page 的新文件:
vim ~/bin/sys_info_page随后输入下面的程序:

保存文件之后,我们将让它成为可执行文 件,再尝试运行它:
chmod 755 ~/bin/sys_info_page
sys_info_page当程序运行的时候,我们应该看到 HTML 文本在屏幕上显示出来,因为脚本中的 echo 命令会将输出发送到标准输出。我们再次运行这个程序,把程序的输出重定向到文件 sys_info_page.html 中,从而我们可以通过网络浏览器来查看输出结果:
sys_info_page > sys_info_page.html
firefox sys_info_page.html实际上,我们可以把所有的 echo 命令结合成一个 echo 命令,当然这样能更容易地添加更多的文本行到程序的输出中。那么,把我们的程序修改 为:

一个带引号的字符串可能包含换行符,因此可以包含多个文本行。Shell 会持续读取文本直 到它遇到右引号。它在命令行中也是这样工作的:

开头的“>”字符是包含在 PS2shell 变量中的 shell 提示符。每当我们在 shell 中键入多行 语句的时候,这个提示符就会出现。现在这个功能有点儿晦涩,但随后,当我们介绍多行编程 语句时,它会派上大用场。
26.2 第二阶段:添加一点儿数据
现在我们的程序能生成一个最小的文档,让我们给报告添加些数据吧。为此,我们将做以下修
改:

我们增加了一个网页标题,并且在报告正文部分加了一个标题。
26.3 变量和常量
然而,我们的脚本存在一个问题。请注意字符串“System Information Report”是怎样被重复 使用的?对于这个微小的脚本而言,它不是一个问题,但是让我们设想一下,我们的脚本非常 冗长,并且我们有许多这个字符串的实例。如果我们想要更换一个标题,我们必须对脚本中的 许多地方做修改,这会是很大的工作量。如果我们能整理一下脚本,让这个字符串只出现一次 而不是多次,会怎样呢?这样会使今后的脚本维护工作更加轻松。我们可以这样做:

通过创建一个名为 title 的变量,并把“System Information Report”字符串赋值给它,我 们就可以利用参数展开功能,把这个字符串放到文件中的多个位置。
那么,我们怎样来创建一个变量呢?很简单,我们只管使用它。当 shell 碰到一个变量的时 候,它会自动地创建它。这不同于许多编程语言,它们中的变量在使用之前,必须显式的声明 或是定义。关于这个问题,shell 要求非常宽松,这可能会导致一些问题。例如,考虑一下在命 令行中发生的这种情形:
[me@linuxbox ~]$ foo="yes"
[me@linuxbox ~]$ echo $foo
yes
[me@linuxbox ~]$ echo $fool
[me@linuxbox ~]$首先我们把“yes”赋给变量 foo,然后用 echo 命令来显示变量值。接下来,我们显示拼写 错误的变量名“fool”的变量值,然后得到一个空值。这是因为当 shell 遇到 fool 的时候, 它很 高兴地创建了变量 fool 并且赋给 fool 一个空的默认值。因此,我们必须小心谨慎地拼写!同样 理解实例中究竟发生了什么事情也很重要。从我们以前学习 shell 执行展开操作,我们知道这 个命令:
echo $foo
echo yes
echo $fool
展开为:
echo这个空变量展开值为空!对于需要参数的命令来说,这会引起混乱。下面是一个例子:
[me@linuxbox ~]$ foo=foo.txt
[me@linuxbox ~]$ foo1=foo1.txt
[me@linuxbox ~]$ cp $foo $fool
cp: missing destination file operand after `foo.txt'
Try `cp --help' for more information.我们给两个变量赋值,foo 和 foo1。然后我们执行 cp 操作,但是拼写错了第二个参数的名 字。参数展开之后,这个 cp 命令只接受到一个参数,虽然它需要两个。
有一些关于变量名的规则:
1. 变量名可由字母数字字符(字母和数字)和下划线字符组成。
2. 变量名的第一个字符必须是一个字母或一个下划线。
3. 变量名中不允许出现空格和标点符号。
单词“variable”意味着可变的值,并且在许多应用程序当中,都是以这种方式来使用变量 的。然而,我们应用程序中的变量,title,被用作一个常量。常量有一个名字且包含一个值,在 这方面就像是变量。不同之处是常量的值是不能改变的。在执行几何运算的应用程序中,我们 可以把 PI 定义为一个常量,并把 3.1415 赋值给它,用它来代替数字字面值。shell 不能辨别变 量和常量;它们大多数情况下是为了方便程序员。一个常用惯例是指定大写字母来表示常量, 小写字母表示真正的变量。我们将修改我们的脚本来遵从这个惯例:

我们亦借此机会,通过在标题中添加 shell 变量名 HOSTNAME,让标题变得活泼有趣些。 这个变量名是这台机器的网络名称。
26.3.1 给变量和常量赋值
这里是我们真正开始使用参数扩展知识的地方。正如我们所知道的,这样给变量赋值:
variable=value这里的 variable 是变量的名字,value 是一个字符串。不同于一些其它的编程语言,shell 不 会在乎变量值的类型;它把它们都看作是字符串。
在参数展开过程中,变量名可能被花括号“{}”包围着。由于变量名周围的上下文,其变得 不明确的情况下,这会很有帮助。这里,我们试图把一个文件名从 myfile 改为 myfile1,使用 一个变量:
[me@linuxbox ~]$ filename="myfile"
[me@linuxbox ~]$ touch $filename
[me@linuxbox ~]$ mv $filename $filename1
mv: missing destination file operand after `myfile'
Try `mv --help' for more information.这种尝试失败了,因为 shell 把 mv 命令的第二个参数解释为一个新的(并且空的)变量。 通过这种方法可以解决这个问题:
[me@linuxbox ~]$ mv $filename ${filename}1通过添加花括号,shell 不再把末尾的 1 解释为变量名的一部分。
我们将利用这个机会来添加一些数据到我们的报告中,即创建包括的日期和时间,以及创建 者的用户名:

26.4 Here Documents
我们已经知道了两种不同的文本输出方法,两种方法都使用了 echo 命令。还有第三种方法,叫 做 here document 或者 here script。一个 here document 是另外一种 I/O 重定向形式,我们在 脚本文件中嵌入正文文本,然后把它发送给一个命令的标准输入。它这样工作:
command << token
text
token这里的 command 是一个可以接受标准输入的命令名,token 是一个用来指示嵌入文本结束 的字符串。我们将修改我们的脚本,来使用一个 here document:

取代 echo 命令,现在我们的脚本使用 cat 命令和一个 here document。这个字符串 _EOF_ (意思是“文件结尾”,一个常见用法)被选作为 token,并标志着嵌入文本的结尾。注意这个
token 必须在一行中单独出现,并且文本行中没有末尾的空格。
那么使用一个 here document 的优点是什么呢?它很大程度上和 echo 一样,除了默认情况
下,here documents 中的单引号和双引号会失去它们在 shell 中的特殊含义。这里有一个命令 中的例子:
[me@linuxbox ~]$ foo="some text"
[me@linuxbox ~]$ cat << _EOF_
> $foo
> "$foo"
> '$foo'
> \$foo
> _EOF_
some text
"some text"
'some text'
$foo正如我们所见到的,shell 根本没有注意到引号。它把它们看作是普通的字符。这就允许我 们在一个 here document 中可以随意的嵌入引号。对于我们的报告程序来说,这将是非常方便 的。
Here documents 可以和任意能接受标准输入的命令一块使用。在这个例子中,我们使用了 一个 here document 将一系列的命令传递到这个 ftp 程序中,为的是从一个远端 FTP 服务器 中得到一个文件:

如果我们把重定向操作符从“<<”改为“<<-”,shell 会忽略在此 here document 中开头 的 tab 字符。这就能缩进一个 here document,从而提高脚本的可读性:
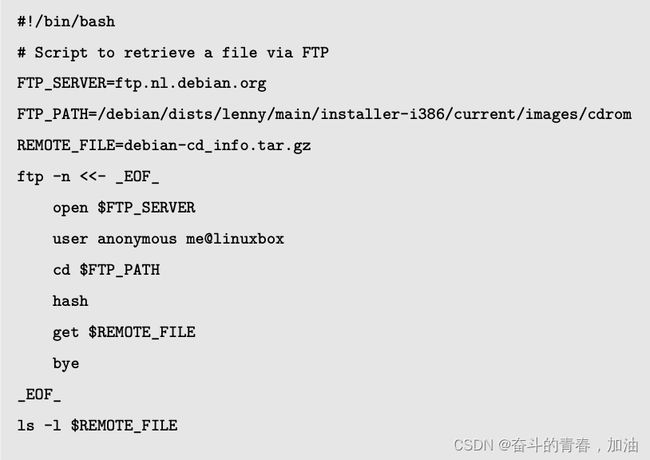
27 自顶向下设计
这种先确定上层步骤,然后再逐步细化这些步骤的过程被称为自顶向下设计。
这种技巧允 许我们把庞大而复杂的任务分割为许多小而简单的任务。自顶向下设计是一种常见的程序设计 方法,尤其适合 shell 编程。
27.1 Shell 函数
目前我们的脚本执行以下步骤来产生这个 HTML 文档:
• 打开网页
• 打开网页标头
• 设置网页标题
• 关闭网页标头
• 打开网页主体部分
• 输出网页标头
• 输出时间戳
• 关闭网页主体
• 关闭网页
为了下一阶段的开发,我们将在步骤 7 和 8 之间添加一些额外的任务。这些将包括:
-
系统正常运行时间和负载。这是自上次关机或重启之后系统的运行时间,以及在几个时间间隔内当前运行在处理中的平均任务量。
-
磁盘空间。系统中存储设备的总使用量。
-
家目录空间。每个用户所使用的存储空间使用量。
如果对于每一个任务,我们都有相应的命令,那么通过命令替换,我们就能很容易地把它们 添加到我们的脚本中: