过零检测变压器降压
With the 2020 US election around the corner, concerns about electoral interference by state actors via social media and other online means are back in the spotlight in a big way.
随着即将到来的2020年美国大选,对国家行为者通过社交媒体和其他在线手段进行选举干预的担忧再次引起人们的广泛关注。
Twitter was a major platform that Russia used to interfere with the 2016 US election, and few have doubts that Moscow, Beijing and others will turn to the platform yet again with new disinformation campaigns.
Twitter是俄罗斯过去用来干扰2016年美国大选的主要平台,很少有人怀疑莫斯科,北京和其他国家是否会通过新的虚假宣传活动再次使用该平台。
This post will outline a broad overview of of how you can build a state troll tweets detector by fine tuning a transformer model (Distilbert) with a custom dataset. This builds on my earlier project using “classic” machine learning models and a simple bag-of-words approach to detect state troll tweets.
这篇文章将概述如何通过使用自定义数据集微调转换器模型( Distilbert )来构建状态巨魔推文检测器。 这是基于我先前使用“经典”机器学习模型和简单的词袋方法检测状态巨魔推文的项目而建立的。
I’ll also compare the results from the fine tuned Distilbert model with those from a Logistic Regression and an XGBoost model, to see if a transformer model can indeed perform better in a practical use case.
我还将比较微调的Distilbert模型的结果与Logistic回归和XGBoost模型的结果,以查看在实际使用情况下转换器模型是否确实可以更好地执行。
Spoiler alert: The fine tuned transformer model performed significantly better than the Log-Reg and XGBoost models (which weren’t slouches either, to be sure), and held up much better when exposed to state troll tweets from a third country. Jump ahead to Section 4 for the results.
剧透警报:经过微调的变压器模型的性能明显优于Log-Reg和XGBoost模型(可以肯定的是,它们也不漏),并且在暴露于来自第三国的国家巨魔推文时,表现也要好得多。 跳转至第4节以获取结果。
1.地面真相,数据源,模型和回购 (1. GROUND TRUTH, DATA SOURCE, MODEL AND REPO)
First things first: How did I ascertain whose tweets are deemed the work of state influence campaigns? In this case, the ground truth is established by Twitter’s election integrity team.
首先,第一件事:如何确定谁的推文被视为国家影响运动的工作? 在这种情况下,基本事实是由Twitter的选举诚信团队确定的。
The state troll tweets used in this project are those which have been identified by Twitter and progressively released to the public since 2018. I chose six sets of state troll tweets from Twitter — three each from China and Russia — which I cleaned up, combined and downsampled to 50,000 rows.
此项目中使用的国家巨魔推文是Twitter识别并自2018年以来逐步向公众发布的那些推文。 我从Twitter上选择了六组国家巨魔推文,其中三组来自中国和俄罗斯,我进行了清理,合并并下采样至50,000行。
I created an equivalent set of 50,000 rows of real tweets by using Tweepy to scrape 175 accounts, which comprise a mixture of verified users and those which I’ve personally checked for authenticity. The resulting combined dataset of 100,000 rows of state troll-plus-real tweets was further split into the usual train-test-validation sets in the standard proportion of 70:20:10 respectively.
通过使用Tweepy抓取175个帐户,我创建了等效的50,000行真实推文集,其中包含经过验证的用户和我亲自检查过的真实性的混合物。 所得的100,000行状态巨魔加实际推文的组合数据集进一步分别以70:20:10的标准比例分为常规的火车测试验证集。
Full details are in my notebooks, and I won’t repeat them here for brevity’s sake. The full repo is available here. Fine tuning was done on a Colab Pro account, and took about five-and-a-half hours.
详细信息在我的笔记本中,为了简洁起见,在此不再赘述。 完整的仓库在这里。 在Colab Pro帐户上进行了微调,大约花费了五个半小时。
The fine tuned Distilbert model is too big for Github, but I’ve uploaded a copy to Dropbox for those who just want to experiment with the model. The six raw CSV files containing state troll tweets have to be downloaded from Twitter if you wish to create a larger training set.
对于Github而言,经过微调的Distilbert模型太大了,但是对于那些只想尝试该模型的人来说,我已经将其副本上载到了Dropbox 。 如果您想创建更大的训练集,则必须从Twitter下载包含状态巨魔推文的六个原始CSV文件。
2.数据准备 (2. DATA PREPARATION)
It ought to be pointed out that key assumptions in the data cleaning and preparation process will affect the outcomes. The assumptions are necessary to keep the scope of this project practical, but if you disagree with them, feel agree to slice a different version of the data based on your own preferred cleaning rules.
应该指出的是,数据清理和准备过程中的关键假设将影响结果。 为了使该项目的范围实用,这些假设是必要的,但是如果您不同意这些假设,则可以同意根据自己的首选清除规则对数据的不同版本进行切片。
My main data cleaning rules for this project:
我对该项目的主要数据清理规则:
- Exclude non-English tweets, since the working assumption is that the target audience is English-speaking. I also wanted to prevent the model from making predictions based on language. 排除非英语推文,因为可行的假设是目标受众是说英语的人。 我还想防止模型基于语言做出预测。
- Exclude retweets. 排除转发。
- Exclude tweets which have fewer than three words after text cleaning. 排除文本清除后少于三个单词的推文。
I also kept the eventual combined dataset to 100,000 rows for practical reasons. My initial attempts to fine tune Distilbert with a 600,000 rows dataset resulted in repeated crashes of the Colab notebook and/or showed extremely long and impractical run times. A more ambitious version of this project just won’t be practical without access to more compute/hardware.
出于实际原因,我还将最终的组合数据集保留为100,000行。 我最初尝试用600,000行数据集对Distilbert进行微调,导致Colab笔记本反复崩溃和/或显示出非常长且不切实际的运行时间。 如果不访问更多的计算/硬件,该项目的更雄心勃勃的版本将不切实际。
3.使用自定义数据集微调Distilbert模型 (3. FINE TUNE THE DISTILBERT MODEL WITH CUSTOM DATASET)
For this project, I picked the distilbert-base-uncased model (smaller and more manageable) and used Hugging Face’s trainer for the task. I abandoned attempts to do a hyperparameters search after several trials which ran on for too long, and hope to return to this topic at a future date (check out the discussion here).
在这个项目中,我选择了基于Distilbert的无案例模型(更小,更易于管理),并使用Hugging Face的教练来完成任务。 在进行了太长时间的几次试验之后,我放弃了进行超参数搜索的尝试,希望以后再回到这个主题(请查看此处的讨论)。
The steps involved are fairly straightforward, as outlined in notebook2.0 of my repo. The code is mostly based on the excellent examples and documentation on Hugging Face here and here.
正如我的回购中的notebook2.0所概述的那样,涉及的步骤非常简单。 该代码主要基于此处和此处有关Hugging Face的出色示例和文档。
The immediate results of the fine tuning certainly look impressive:
微调的直接结果肯定令人印象深刻:
'eval_accuracy': 0.9158421345191773,
'eval_f1': 0.9163813100629625,
'eval_precision': 0.9098486510199605,
'eval_recall': 0.9230084557187361I ran a quick test against the validation set — 10,000 rows kept aside and which the model has not seen at all — and the excellent classification metrics barely budged:
我跑对验证集快速测试- 10,000行扔在一边和该模型还没有看到在所有-和优秀的分类指标几乎没有改变:
'eval_accuracy': 0.9179,
'eval_f1': 0.9189935865811544,
'eval_precision': 0.9178163184864012,
'eval_recall': 0.9201738786801027For a more thorough comparison and analysis, I trained two separate Logistic Regression and XGB classifier models using the same dataset used to fine tune the Distilbert model. Let’s see how they do in the same tests.
为了进行更全面的比较和分析,我使用了用于微调Distilbert模型的相同数据集训练了两个单独的Logistic回归模型和XGB分类器模型。 让我们看看它们在相同测试中的表现。
4.精细调谐的DISTILBERT VS LOG-REG VS XGB (4. FINE TUNED DISTILBERT VS LOG-REG VS XGB)
The pickled Log-Reg and XGB models are available in my repo’s “pkl” folder. My notebooks detailing their optimisation process are available here and here. I won’t go into the details here, except to highlight that both models scored above 0.8 during training and grid search. While clearly lower than the fine tuned Distilbert model’s score, I think these two models did well enough to provide for an adequate comparison.
腌制的Log-Reg和XGB模型可以在我的仓库的“ pkl”文件夹中找到。 我的笔记本详细介绍了它们的优化过程,可在此处和此处获得。 除了要强调两个模型在训练和网格搜索过程中得分均高于0.8以外,我在这里不再赘述。 虽然明显低于微调的Distilbert模型的得分,但我认为这两个模型的性能足以提供足够的比较。
The chart below shows the detailed breakdown, via confusion matrices, of how all three models performed against the validation set (10,000 rows comprising 5,061 state troll tweets and 4,939 real tweets).
下图通过混淆矩阵显示了所有三个模型如何针对验证集(10,000行,包括5,061个状态巨魔推文和4,939个真实推文)进行了详细细分。
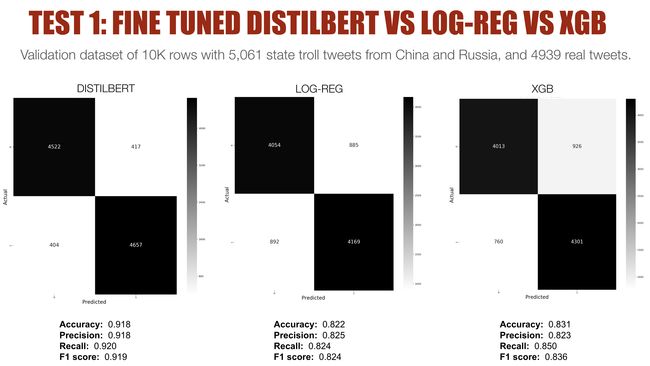
At a glance, it’s clear that the fine tuned Distilbert model (on far left) is the strongest performer, and accurately picked out more state troll and real tweets than the Log-Reg or XGB models. More significantly, the number of false positives and false negatives for the Distilbert model is about half that produced by the log-reg and XGB models.
乍一看,很明显,经过微调的Distilbert模型(最左侧)是性能最强的模型,并且与Log-Reg或XGB模型相比,可以精确地提取更多状态巨魔和实际推文。 更重要的是,Distilbert模型的假阳性和假阴性的数量大约是log-reg和XGB模型产生的数量的一半。
So while the three models’ performance metrics might seem close, the gap in their classification capabilities become very stark when seen via confusion matrices that give us a better sense of how they performed in classifying thousands of tweets.
因此,尽管这三个模型的性能指标似乎很接近,但通过混淆矩阵来看,它们的分类能力差距变得非常明显,这使我们对它们在分类成千上万条推文中的表现有了更好的了解。
4.1三种型号的附加测试 (4.1 ADDITIONAL TEST FOR THE 3 MODELS)
All three models were trained on a 50–50 split of real tweets and state troll tweets from China and Russia. In reality, we don’t know the actual proportion of real-versus-troll tweets on Twitter. More importantly, state troll tweets can come from any country and changes in tone, language and topics could significantly affect the classifier’s ability to separate real tweets from those originating from state-backed campaigns.
所有这三种模型均接受了来自中国和俄罗斯的真实推文和国家巨魔推文的50–50拆分训练。 实际上,我们不知道Twitter上的实战推文推文的实际比例。 更重要的是,州巨魔推文可以来自任何国家,而且语气,语言和主题的变化可能会严重影响分类器将真实推文与源于国家支持的活动的推文区分开的能力。
Which of the three models would hold up better if exposed to state troll tweets from a third country? To find out, I ran a new dataset — comprising 1,000 troll tweets from Iran and 993 real tweets from American users — through the three models. This new dataset was created from an earlier project I did on the same subject.
如果暴露于第三国的国家巨魔推文中,这三种模式中的哪一种会更好? 为了找出答案,我通过这三个模型运行了一个新的数据集,其中包括来自伊朗的1,000条巨魔推文和来自美国用户的993条真实推文。 这个新的数据集是根据我在同一主题上所做的一个较早的项目创建的。

As expected, all three classifiers saw their performance drop significantly when exposed to Iranian state troll tweets which they’ve not seen before.
不出所料,当接触伊朗国家巨魔推文时,这三个分类器的性能均显着下降,这是以前从未见过的。
But the fine tuned Distilbert model still held up decently, in my view. Not only did it correctly pick out more troll and real tweets compared to the Log-Reg or XGB model, the number of false negatives (troll tweets that the model thought were real tweets) was not excessively large.
但是,在我看来,微调的Distilbert模型仍然保持得不错。 与Log-Reg或XGB模型相比,它不仅可以正确地选择更多的troll和真实的tweet,而且假阴性(该模型认为是真实tweets的troll tweets)的数量也不过分。
This is particularly problematic with the Log-Reg model, which classified half (501 out of 1,000) of the troll tweets as real tweets when they were in fact the work of state-backed operators. The XGB model is slightly better in this area, but not by far, with the number of false negatives (468) significantly higher than the number of false positives.
这对Log-Reg模型尤其成问题,该模型将拖钓推文的一半(1,000个中的501个)分类为真实推文,而实际上却是由国家支持的运营商的工作。 XGB模型在此方面略胜一筹,但远没有达到,假阴性数(468)明显高于假阳性数。
This was a particularly pronounced problem with the models I trained in my earlier project, meaning classifiers trained on one particular state actor’s troll tweets were quite good at spotting new, unseen tweets from said state actor. But once troll tweets from another state operator is injected into the mix, the classifier’s performance falters significantly.
在我之前的项目中训练的模型中,这是一个特别明显的问题,这意味着在一个特定州演员的巨魔推文上训练的分类器非常善于发现该州演员新的,看不见的推文。 但是,一旦将来自其他状态操作员的巨魔推文注入到混合中,分类器的性能就会大大下降。
The fine tuned Distilbert model doesn’t overcome this problem completely, but holds up well enough to hold out hopes for a model that can “generalise” better. If you have enough computing resources to train a transformer model on a bigger dataset comprising state troll tweets from all the countries identified by Twitter to date, it stands to reason that said model might do better in the sort of tests we’ve tried in this post.
精细调整的Distilbert模型不能完全克服此问题,但可以很好地保持希望,以使模型能够更好地“普遍化”。 如果您有足够的计算资源来在更大的数据集上训练变压器模型,该数据集包含Twitter迄今所确定的所有国家/地区的国家巨魔推文,则有理由认为,该模型在我们为此进行的测试中可能会做得更好发布。
Unfortunately that’s a hypothesis I’ll have to test another time.
不幸的是,这是一个假设,我将不得不再次测试。
5.结论 (5. CONCLUSION)
Detection of state influence campaigns on Twitter involves more than just the examination of the tweet text, of course. State trolls often leave bigger tell-tale signs like the (coordinated) dates of account creation, or timing of their tweets. The increasing use of photos and memes also make the detection process trickier.
当然,在Twitter上检测国家影响力运动不仅涉及对推文的检查。 州巨魔通常会留下较大的告示牌,例如创建帐户的日期(协调)或发帖时间。 照片和模因的越来越多的使用也使检测过程更加棘手。
But spotting trends and hidden structures in their tweet text will continue to be one major area of focus. And it would appear that a fine tuned transformer model can perform significantly better in this task compared to the more popular or traditional classifiers out there.
但是,在推文中发现趋势和隐藏结构仍将是重点之一。 与目前较流行或传统的分类器相比,精调的变压器模型在此任务中的表现似乎要好得多。
There are trade-offs, of course, in terms of resources and time. The hardware needed to fine tune a transformer model on, say, a million rows of tweets, is not readily available to most users, to say nothing of whether that’s the most efficient way to tackle the task.
当然,需要在资源和时间上进行权衡。 对于大多数用户来说,在例如一百万行的推文上微调变压器模型所需的硬件并不容易获得,更不用说这是否是解决任务的最有效方法。
6.奖金部分:Web APP (6. BONUS SECTION: WEB APP)
I tried deploying the fine tuned Distilbert model as part of a simple web app but quickly found out that free hosting accounts don’t have enough disk space for pytorch installation on top of hosting the model.
我尝试将经过微调的Distilbert模型作为简单的Web应用程序的一部分进行部署,但是很快发现免费的托管帐户在托管模型之上没有足够的磁盘空间来进行pytorch安装。
But I’ve uploaded the necessary files to the repo for anyone who wants to try it out on their local machine. Just make sure to download the fine tuned model from Dropbox and move it to the “app” folder.
但是我已经将所有需要的文件上传到了仓库中,供任何想在本地计算机上试用的人使用。 只需确保从Dropbox下载经过微调的模型并将其移至“ app”文件夹即可。
As always, if you spot mistakes in this or any of my earlier posts, ping me at:
与往常一样,如果您发现此内容或我的任何较早帖子中的错误,请通过以下方式对我进行检查:
Twitter: Chua Chin Hon
Twitter:蔡展汉
LinkedIn: www.linkedin.com/in/chuachinhon
领英(LinkedIn): www.linkedin.com/in/chuachinhon
翻译自: https://towardsdatascience.com/detecting-state-backed-twitter-trolls-with-transformers-5d7825945938
过零检测变压器降压