手把手教你为神经网络编译器CINN增加One-Hot算子

在飞桨黑客松比赛的第三期,飞桨社区核心开发者李健铭参与了CINN算子开发方向的任务。
本文将由李健铭分享其开发过程,手把手教大家为神经网络编译器CINN增加One-Hot算子。

 任务介绍
任务介绍
CINN(Compiler Infrastructure for Neural Networks)是一种在不改变模型代码的条件下加速飞桨模型运行速度的深度学习编译器。不同于深度学习框架算子,深度学习编译器算子的粒度更细,算子数目也更少,因此在算子融合和自动调优方面具有更大的优势。
在对接上层框架时,编译器会将上层的框架算子进一步拆分为若干基础算子,这样做的目的一方面是为了减少算子开发的工作量,仅实现有限的基础算子便可以组合出大量的上层框架算子;另一方面便于算子融合技术在编译器中可以实现跨算子自动融合,减少最终执行时的kernel数目和访存开销,达到更好的性能;此外,结合自动调优技术使得编译器可以自动优化融合后的kernel,提升kernel性能。
我完成的是One-Hot算子的开发任务。该任务需要具备编译器的基础知识,了解神经网络的基本原理。如果你还学习过编译器框架LLVM,开发过程会更轻松。如果没学过也没关系,我们可以参照CINN中现有的基础算子,学习相关API的使用方法。这个任务的重点是理解和运用CINN IR。
 设计文档
设计文档
 算子介绍
算子介绍
One-Hot算子(在本项目中,该算子函数名为OneHot,后文将统一称为OneHot)接受5个参数,输出1个张量。算子的参数含义如下。
indices索引张量。
on_value索引位置填充的值。
off_value非索引位置填充的值。
axis填充的轴。
depth填充的长度。
算子的功能是按照张量indices表示的索引位置填充数值,生成一个新张量。在新张量中,indices索引位置上的值为on_value,其它位置上的值为off_value。算子的功能描述可能比较难理解,我们可以看一些算子计算示例。
OneHot(
indices=[0, 2, 2],
on_value=1,
off_value=0,
depth=4,
axis=0,
dtype="float32"
)代码输出
# [[1. 0. 0]
# [0. 0. 1]
# [0. 0. 1]
# [0. 0. 0]]
OneHot(
indices=[0, 2, 2],
on_value=1,
off_value=0,
depth=4,
axis=-1,
dtype="float32"
)代码输出
# [[1. 0. 0. 0.]
# [0. 0. 1. 0.]
# [0. 0. 1. 0.]] 实现方法
实现方法
CINN的结构比较复杂,我刚开始有些无从下手。为了明确任务的工作内容,我先学习了CINN已有的基础算子内容,分析算子开发的共性特征。
新增一个算子主要的工作可分为前端和后端两个部分,例如我们增加一个名为op的算子,需要完成以下的工作。
前端部分(cinn/frontend)
NetBuilder::Op函数:实现算子的前端接口。
后端部分(cinn/hlir/op/contrib)
Op函数:实现算子的compute。
InferShapeForOp函数:获取算子的结果张量的shape。
InferDtypeForOp函数:获取算子的结果张量的数据类型。
StrategyForOp函数:整合算子的compute和schedule。
注册算子:使用CINN_REGISTER_HELPER注册。
这些函数名称的后缀都是算子名称op。
在CINN中,计算(compute)与调度(schedule)是分离的。算子的compute定义了算子的计算逻辑,实现了输出张量的计算。算子的schedule定义了算子的调度逻辑,实现了算子的加速优化。这次任务我们只关注compute的开发,暂时不涉及schedule的实现。
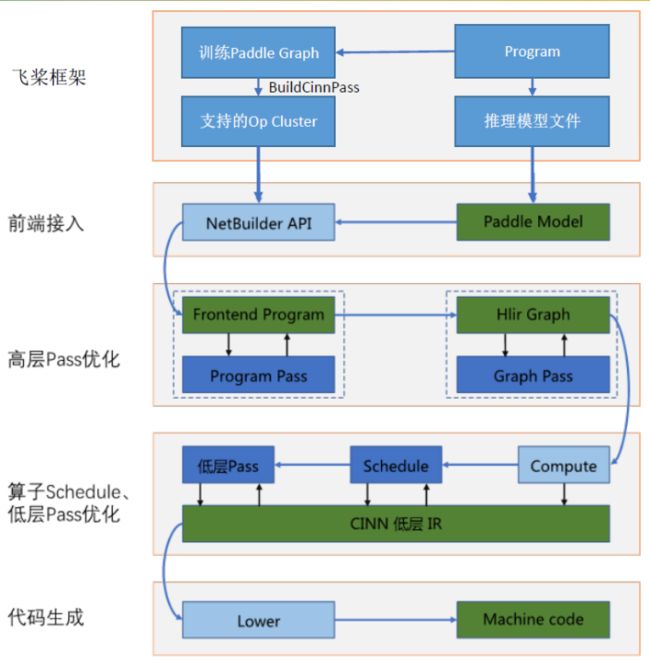
CINN的工作过程图
开发的重点是使用CINN IR构造算子的compute,其它内容可以参考CINN中已实现的算子,照葫芦画瓢。CINN IR是CINN底层进行计算表达的IR(Intermediate Representation),在框架中扮演重要角色。其中,Expr是 CINN IR的主要数据类型,它可以表示数值和计算。
下面是一些Expr的使用例子。这些例子包含了实现OneHot算子所涉及的全部CINN IR形式,目前我们了解这些就足够了。
// a+b
Expr a(1);
Expr b(1);
Expr c = a + b;
// int类型转换为float类型
Expr d = Cast::Make(common::Str2Type("float32"), a);
// 判断a与b是否相等
Expr e = EQ::Make(a, b)
// ?:三元表达式
Expr f = Select::Make(e, a, b)CINN IR的完整定义可查看链接
https://github.com/PaddlePaddle/CINN/pull/775
飞桨专家们也提供了算子开发的视频讲解
https://aistudio.baidu.com/aistudio/course/introduce/26351?directly=1&shared=1
注:课节10:深度学习编译器算子应用与开发介绍,推荐学习一下。
 代码开发
代码开发
在开始代码开发之前,我们需要先阅读CINN项目贡献指南 。文中介绍了开发环境和PR提交过程。搭建好开发环境,就可以开始编写代码了。
CINN项目贡献指南
https://github.com/PaddlePaddle/CINN/pull/810
新增OneHot算子需要完成以下的工作。
前端部分(cinn/frontend)
实现NetBuilder::OneHot函数
后端部分(cinn/hlir/op/contrib)
实现OneHot函数
实现InferShapeForOneHot函数
实现InferDtypeForOneHot函数
实现StrategyForOneHot函数
注册算子
我们先开发算子的后端,再开发算子的前端。
 算子后端
算子后端
InferDtypeForOneHot
InferDtypeForOneHot函数的实现比较简单,只要从算子的输入参数列表中获得dtype。
if (attrs.find("dtype") != attrs.end()) {
dtype = absl::get(attrs.at("dtype"));
} InferShapeForOneHot
InferShapeForOneHot函数的作用是计算输出张量的shape。
生成输出张量的过程是一个升维的过程,如果输入张量的shape是 (a, b),参数axis是0,则输出张量的shape为 (depth, a, b)。
在函数实现中,我们将depth插入输入张量的shape的axis轴,得到新的shape。
for (int i = 0; i < ndim + 1; ++i) {
if (i == true_axis) {
new_shape.push_back(depth);
} else {
new_shape.push_back(in_shape[indices_index++]);
}
}OneHot
OneHot函数内需要实现算子的compute,函数的主要内容是参数检查,计算输出张量的shape,以及使用CINN IR构造compute。
对于新张量X的每个多维索引iter,将iter的axis轴删除得到另一个索引indices_indices。输入张量indices在索引indices_indices处的值,指定了新张量X在索引iter处的整个axis轴的值。
如果indices[indices_indices]与iter[axis]相等,那么X[iter]的值取on_value,否则取off_value。按照这个思路,我们就能构造出compute。
Tensor res = lang::Compute(
new_shape,
[=](const std::vector& iter) {
std::vector indices_indices;
for (size_t i = 0; i < iter.size(); i++) {
if (static_cast(i) == true_axis) {
continue;
}
indices_indices.push_back(iter[i]);
}
Expr idx = iter[true_axis];
Expr elem = ir::Cast::Make(idx.type(), indices(indices_indices));
return ir::Select::Make(ir::EQ::Make(elem, idx), on_value_cast, off_value_cast);
},
common::UniqName(output_name)); StrategyForOneHot
StrategyForOneHot函数整合算子的compute和schedule。这里schedule的内容与其它算子的保持相同即可。
std::shared_ptr StrategyForOneHot( … ){
...
//compute
framework::CINNCompute one_hot_compute([=](lang::Args args, lang::RetValue* ret) {
//调用OneHot
ir::Tensor out = OneHot(indices, on_value, off_value, depth, axis, common::Str2Type(dtype), tensor_name);
...
});
//schedule
framework::CINNSchedule one_hot_schedule([=](lang::Args args, lang::RetValue* ret) {
//与其它算子相同
...
});
//整合算子的 compute 和 schedule
auto strategy = std::make_shared();
strategy->AddImpl(one_hot_compute, one_hot_schedule, "strategy.one_hot.x86", 1);
return strategy;
} 算子注册
使用CINN_REGISTER_HELPER宏注册算子,设置好算子的参数数量、参数名称和相关的函数名等。
CINN_REGISTER_HELPER(one_hot_ops) {
CINN_REGISTER_OP(one_hot)
.describe(
"Returns a one-hot tensor where the locations repsented by indices take value `on_value`, "
"other locations take value `off_value`.")
.set_num_inputs(3)
.set_num_outputs(1)
.set_attr("CINNStrategy", cinn::hlir::op::StrategyForOneHot)
.set_attr("infershape", MakeOpFunction(cinn::hlir::op::InferShapeForOneHot))
.set_attr("inferdtype", MakeOpFunction(cinn::hlir::op::InferDtypeForOneHot))
.set_support_level(4);
return true;
}
} 最后在cinn/hlir/op/use_ops.h中注册算子,后端的内容就完成了。
CINN_USE_REGISTER(one_hot_ops) 算子前端
算子前端
前端的工作比较简单,主要是在NetBuilder中实现OneHot的前端接口,函数实现有固定的形式。
Variable NetBuilder::OneHot( … ) {
return CustomInstr("one_hot", {indices, on_value, off_value}, {{"depth", depth}, {"axis", axis}, {"dtype", dtype}}).front();
} 算子单测
算子单测
完成新算子的代码开发后,必须编写新算子的单测。算子的前端和后端均需要测试。在前端,我们测试算子的计算结果的正确性。在后端,我们测试算子代码生成的结果的正确性。单测的内容比较模式化,我们可以模仿其它算子的单测进行编写,
详细代码可查看PR
https://github.com/PaddlePaddle/CINN/pull/963/files#diff-e6ba4389af270c6638b14468d8fce5a3b2d001a397c433de4935f94b64922bb4
编译完成后,使用ctest指令运行单测。
ctest -R one_hot_test
ctest -R net_builder_test在开发过程中,我们也可以通过运行单测来打印一些数据,辅助算子代码的调试。
 总结
总结
CINN的基础算子开发的关键是使用CINN IR构造compute,框架中现有的算子都是很好的学习材料。
深度学习编译器是近年来新兴的开发方向,涉及许多新颖而有趣的知识。如果你对新领域技术有好奇心,想看看业界大牛新的工作和成果,欢迎参与CINN开源项目。

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~