论文笔记:主干网络——SENet
Squeeze-and-Excitation Networks
SENet
文章目录
- Squeeze-and-Excitation Networks
- SENet
-
- 论文结构
- 一、摘要核心
- 二、Squeeze and Excitation
-
- ① Squeeze:Global Information Embedding
- ② Excitation:Adaptive Recalibration
- ③ SE Block流程图
- ④ SE Block嵌入方法
- 三、SE-ResNet-50
- 四、实验结果及分析
-
- Single-Crop下ImageNet-1K分类
- 五、Ablation Study 控制变量法进行实验
-
- ① 实验一:Reduction Ratio的选择
- ② 实验二:Squeeze中池化中池化选max还是average
- ③ 实验三:Excitation中,第二个FC层激活函数用sigmoid?ReLU?Tanh?
- ④ 实验四:SE Block嵌入网络的哪个阶段最合适
- ⑤ 实验五:SE Block嵌入Building Block什么位置最合适?
- 六、Role of SE Block
-
- ① 实验六:探究squeeze中的全局池化是否重要(squeeze的作用)
- ② 实验七:探究excitation输出的权重是否有意义?是否有强调有忽略?(Excitation的作用)
- 七、论文总结
-
- ① 关键点、创新点
- ② 备用参考文献知识点
- 八、研究的部分参考文献
论文结构
摘要: CNN空间维度上的特征分析有广泛研究;本文提出SE block调整通道特征;SE block获得的成绩
1. Introduction: 近期CN的研究是为了获得更好的特征表示;本文从通道维度研究更好的特征表示方法;提出SE block;SE block优点
2. Related Work: CNN经典模型罗列;网络搜索相关工作;注意力机制与门控机制相关工作
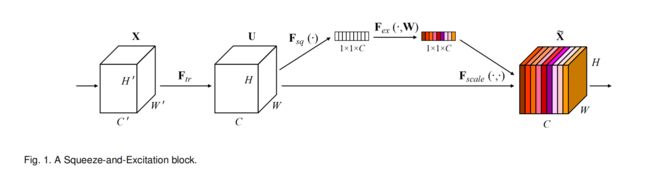
3. Squeeze-and-Excitation Blocks: SE block的内部操作
4. Model and computational Complexity: 模型复杂度计算
5. Experiments: 多个数据集上实验结果分析探讨
6. Ablation Study: 控制变量法进行一系列实验,验证最优SE block方式
7. Role of SE blocks: SE block的作用探讨
8. Conclusion
一、摘要核心
- 背景介绍:卷积神经网络的核心是卷积操作,其通过局部感受野的方式融合空间和通道维度的特征;针对空间维度的特征提取方法已被广泛研究
- 本文内容:本文针对通道维度进行研究,探索通道之间的关系,并提出SE block,它可自适应的调整通道维度上的特征
- 研究成果:SE block 课堆叠构成SENet,SENet在多个数据集上表现良好;SENet不仅可大幅度提升精度,同时仅需要增加少量的参数
- 比赛成绩
- 代码开源
二、Squeeze and Excitation
① Squeeze:Global Information Embedding
全局信息降维嵌入
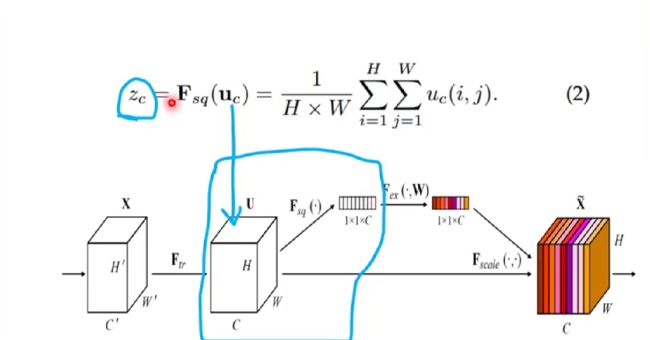
squeeze操作:采用全局池化,将空间维度H和W压缩到1×1,利用1个像素来表示一个通道,实现低维嵌入
② Excitation:Adaptive Recalibration
自适应重构
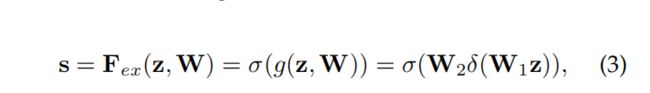
公示(3)中,第一个全连接层的激活函数是ReLU,第二个全连接层激活函数为Sigmoid
超参数reduction ratio r控制第一个全连接层神经元个数,C/r 个,进而影响SE Block的参数量。减少计算量
关于r的有对比实验,经验值为16
③ SE Block流程图
- Squeeze:压缩特征图至向量形式
- Excitation: 两个全连接层对特征向量进行映射变换
- Scale:将得到的权重向量进行逐通道乘法
C个神经元–>C/r 个神经元(第一个FC层)–>C个神经元(第二个FC层)
④ SE Block嵌入方法
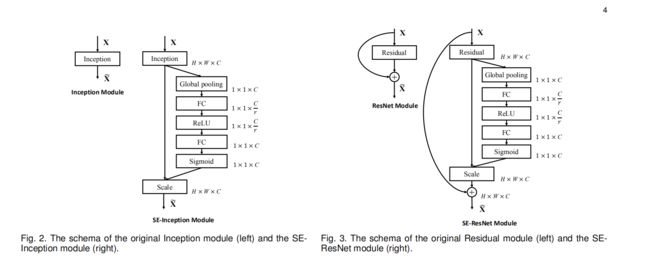
基本原则:
SE Block只“重构”特征图,不改变原来结构
三、SE-ResNet-50
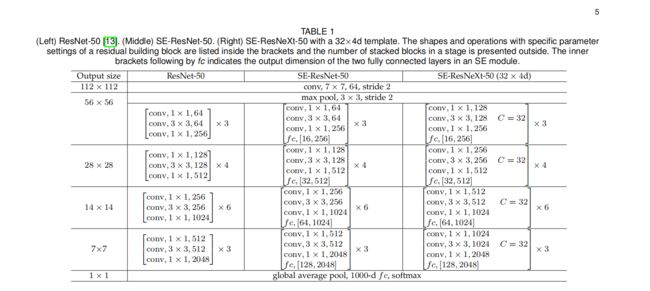
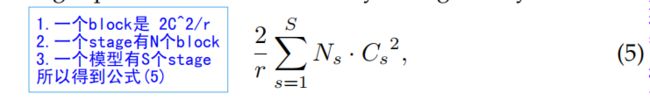
文中公式(5)描述了ResNet中嵌入SE Block所增加的参数量
r:reduction ratio r ,控制第一个全连接层神经元个数,通常为16
S:表示stage,不同stage分开计算,因为不同stage特征图通道数不一样
N_s:第S个stage有多少个building block堆叠。例如ResNet-50,N1到N4等于3,4,6,3
C_s:第S个stage的building block中特征图有多少个通道,C1到C4等于256,512,1024,2048
ResNet-50:代入这个公式大概算出2.5million个参数

四、实验结果及分析
Single-Crop下ImageNet-1K分类
(1)在非残差连接模型上进行实验
超参设置:

实验结果:
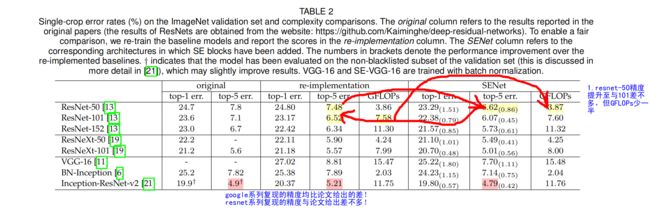
- SE-Module均带来了性能提升
- SE-ResNet-50精度与ResNet-101差不多,但是GFLOPs少一半
- SE-Module与网络深度带来的提升是互补的
- 非残差结构的模型上,同样有提升
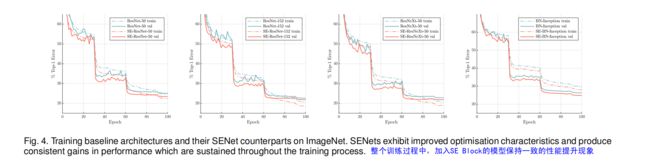
(2)轻量化模型上嵌入 SE Block,同样获得性能提升。
超参设置与以前不同


(3)更多数据集上实验
在CIFAR-10、100,places365和COCO数据集上进行实验,加入SE Module后,性能均获得提升
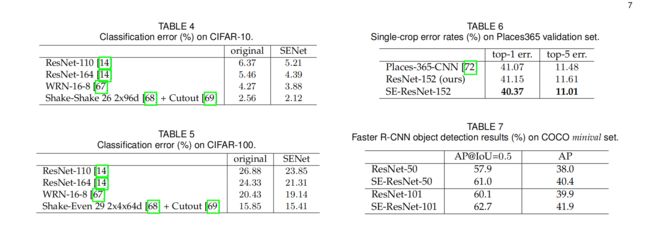
五、Ablation Study 控制变量法进行实验
① 实验一:Reduction Ratio的选择
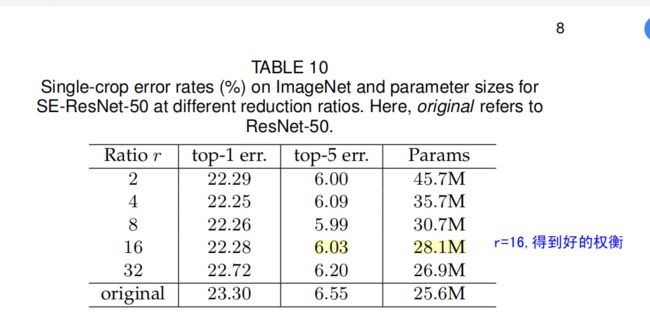
r 直接影响到SE Block的参数量和计算量。
r越大、参数越少,入6时,在精度和参数上得到比较好的平滑
② 实验二:Squeeze中池化中池化选max还是average
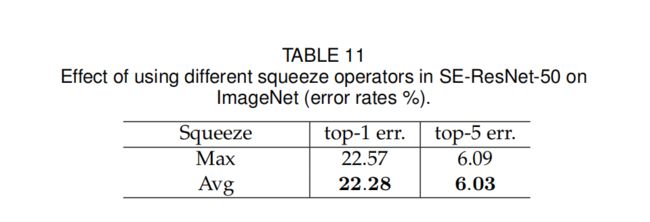
Avg比max效果更好,因此Squeeze中采用平均池化
③ 实验三:Excitation中,第二个FC层激活函数用sigmoid?ReLU?Tanh?
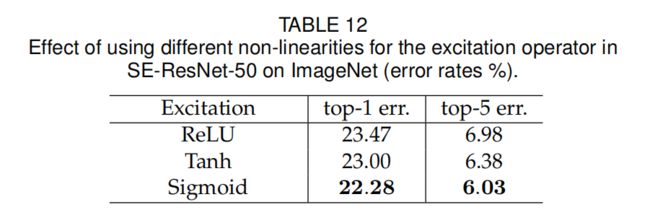
用Tanh替换Sigmoid时,性能下降,
用ReLU替换Sigmoid时,性能显著下降
在涉及尺度变换时,尝试Sigmoid激活函数
④ 实验四:SE Block嵌入网络的哪个阶段最合适
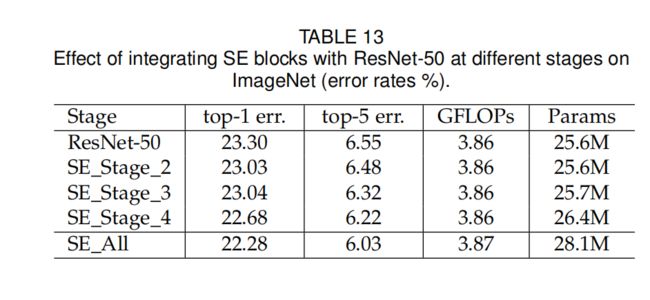
各个stage单独加入SE Block均能提升精度,
所有stage都加入SE Block,也能提升精度,
所以SE Block是普适性的模块,可嵌入网络任意位置
⑤ 实验五:SE Block嵌入Building Block什么位置最合适?


实验表明,在四个箭头嵌入,精度差别不大
结论:SE Block很鲁棒
六、Role of SE Block
① 实验六:探究squeeze中的全局池化是否重要(squeeze的作用)
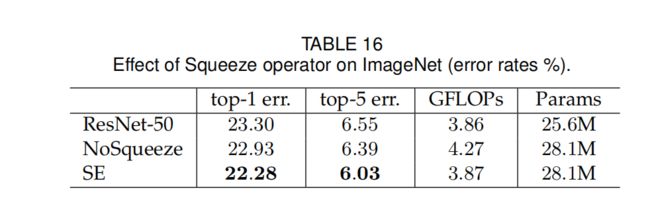
对比实验:
移除池化层,并将Excitation的FC层替换成1×1卷积来实现特征变换
1×1卷积缺乏对空间维度信息的处理(融合整合)
结论:缺乏squeeze,精度下降
② 实验七:探究excitation输出的权重是否有意义?是否有强调有忽略?(Excitation的作用)
研究方法:通过观察Excitation最终输出权重向量的分布,方差是否大,方差越大表面网络越有选择性。
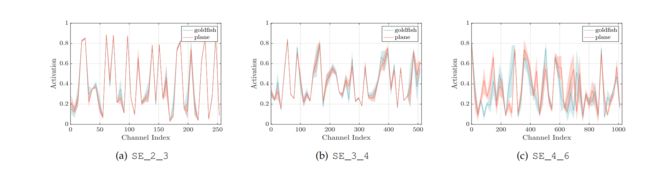
实验方法:观察各个stage最后一个block的excitation的权重分布,看看是否有高有低(有无注意力机制)
结论:在前三个stage中均表现出较大的方差,Excitation的输出的确具有特征的选择性
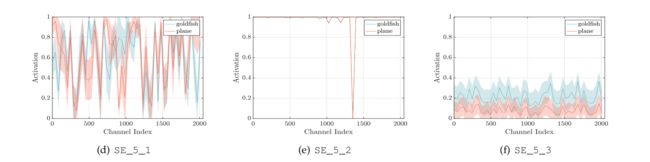
结论:最后一个stage的后两个block的方差较小,因此可以不加SE Block,以节省参数
探究类内的分布:
可以发现在最后一个stage,类内的防擦哈较大,表明网络是有选择性的
七、论文总结
① 关键点、创新点
- 提出SE模块生成通道维度的权重向量,用于特征“重构”,实现强调重要特征,忽略不重要特征,增强模型表征能力,提高模型性能。
- 设计一系列实验验证SE Block的有效性,特别是Ablation Study方法十分值得学习
② 备用参考文献知识点
-
实验结果表明,加入SE Blocks可作为模型增加深度的互补,即同时增加SE Block和网络深度,均可带来性能提升。
suggesting that the improvements induced by SE blocks may be complementary to those obtained by simply increasing the depth of the base architecture. (论文5.1的network depth) -
SE Block嵌入ResNet时,FC层不要加偏置。
We found empirically that on ResNet architectures, removing the biases of the FC layers in the excitation operation facilitates the modelling of channel dependencies(论文6的第一段) -
多个对比实验的精度没有明显差异时,可以说有很好的鲁棒性
This experiment suggests that the performance improvements
produced by SE units are fairly robust to their location, provided that they are applied prior to branch aggregation.(论文6.5的第一段)
八、研究的部分参考文献
(1)STNet 空间变换网络:(参考文献9)
提出spatial transformer,将变形的、位置偏离的图像变换到图像中间,使CNN对空间变换更鲁棒。
(2)Attention ResNet 注意力机制:(参考文献58)
特征图引出的分支 经过一系列的网络层运算,输出权重值,利用权重值与特征图进行计算,去修改原来的特征图,使模型加强关注的区域的特征值。(参考文献58)
提出一种前向Attention机制,利用Attention的网络,在原有网络的基础上新增一个分支来提取Attention,并进行单独的训练,而本文提出的模型能够就在一个前向过程中提取模型的Attention,是模型训练更简单
(3)CBAM:convolution block attention module(参考文献59)
提出两阶段的注意力机制,一个针对通道维度,一个针对空间维度。可以看出注意力机制可分不同维度进行