pandas第二章-pandas基础--文件读取与写入、数据结构、基本函数、窗口函数
一、文件的读取与写入
文件读取
读取 csv, excel, txt 文件
常用参数: header=None 表示第一行不作为列名, index_col 表示把某一列或几列作为索引,usecols 表示读取列的集合,默认读取所有的列,parse_dates 表示需要转化为时间的列, nrows 表示读取的数据行数
df_csv = pd.read_csv('data/my_csv.csv')
df_txt = pd.read_table('data/my_table.txt')
df_excel = pd.read_excel('data/my_excel.xlsx')
#分割参数sep 以 |||| 为分割,要转义。指定引擎为 python
pd.read_table('data/my_table_special_sep.txt',
sep=' \|\|\|\| ', engine='python')
数据写入
to_csv() 或 to.excel()
把 index 设置为 False ,特别当索引没有特殊意义的时候,这样的行为能把索引在保存的时候去除。
df_csv.to_csv('data/my_csv_saved.csv', index=False)
把表格快速转换为 markdown 和 latex 语言,可以使用 to_markdown 和 to_latex 函数,此处需要安装 tabulate 包。
print(df_csv.to_markdown())
print(df_csv.to_latex())
二、基本数据结构
pandas 中具有两种基本的数据存储结构,存储一维 values 的 Series 和存储二维 values 的 DataFrame
- Series
Series 一般由四个部分组成,分别是序列的值 data 、索引 index 、存储类型 dtype 、序列的名字 name 。其中,索引也可以指定它的名字,默认为空
dtype = 'object’类型,代表了一种混合类型,
s = pd.Series(data = [100, 'a', {'dic1':5}],
index = pd.Index(['id1', 20, 'third'], name='my_idx'),
dtype = 'object',
name = 'my_name')
s
Out[23]:
my_idx
id1 100
20 a
third {'dic1': 5}
Name: my_name, dtype: object
- DataFrame
DataFrame 在 Series 的基础上增加了列索引,一个数据框可以由二维的 data 与行列索引来构造:
值 data由一维变成了二维,加了一个参数columns,给出了列名
data = [[1, 'a', 1.2], [2, 'b', 2.2], [3, 'c', 3.2]]
df = pd.DataFrame(data = data,
index = ['row_%d'%i for i in range(3)],
columns=['col_0', 'col_1', 'col_2'])
df
Out[32]:
col_0 col_1 col_2
row_0 1 a 1.2
row_1 2 b 2.2
row_2 3 c 3.2
更多的时候会采用从列索引名到数据的映射来构造数据框,同时再加上行索引
data 中给列名
df = pd.DataFrame(data = {'col_0': [1,2,3], 'col_1':list('abc'),
'col_2': [1.2, 2.2, 3.2]},
index = ['row_%d'%i for i in range(3)])
df
Out[34]:
col_0 col_1 col_2
row_0 1 a 1.2
row_1 2 b 2.2
row_2 3 c 3.2
三、常用基本函数
下面部分,df都指数据名
df = pd.read_csv('data/learn_pandas.csv')
df.head(n) 显示前n行
df.tail(n) 显示后n行
df.info() 返回表的 信息概况 ,(列名,是否空,类型)
df.describe() 返回表中 数值列对应的主要统计量 (计数,中值,均值,。。。)
df.quantile(0.75), df.count(), df.idxmax() 这三个函数,它们分别返回的是分位数、非缺失值个数、最大值对应的索引.
这三个函数,由于操作后返回的是标量,所以又称为聚合函数,它们有一个公共参数 axis ,默认为0代表逐列聚合,如果设置为1则表示逐行聚合
使用 unique 和 nunique 可以分别得到其唯一值组成的列表和唯一值的个数
df.unique() 可得到各列所有取值组成的列表,去重后的唯一值
df.nunique() 可得到各列唯一值的个数
value_counts 可以得到唯一值和其对应出现的频数
df['School'].unique()
Out[57]:
array(['Shanghai Jiao Tong University', 'Peking University',
'Fudan University', 'Tsinghua University'], dtype=object)
df['School'].nunique()
Out[58]: 4
df['School'].value_counts()
Out[59]:
Tsinghua University 69
Shanghai Jiao Tong University 57
Fudan University 40
Peking University 34
Name: School, dtype: int64
drop_duplicates
如果想要观察多个列组合的唯一值,可以使用 drop_duplicates 。其中的关键参数是 keep ,默认值 first 表示每个组合保留第一次出现的所在行, last 表示保留最后一次出现的所在行, False 表示把所有重复组合所在的行剔除。
df_demo = df[['Gender','Transfer','Name']]
df_demo.drop_duplicates(['Gender', 'Transfer'])
Out[61]:
Gender Transfer Name
0 Female N Gaopeng Yang
1 Male N Changqiang You
12 Female NaN Peng You
21 Male NaN Xiaopeng Shen
36 Male Y Xiaojuan Qin
43 Female Y Gaoli Feng
#会显示所在行的行数
df_demo.drop_duplicates(['Gender', 'Transfer'], keep='last')
Out[62]:
Gender Transfer Name
147 Male NaN Juan You
150 Male Y Chengpeng You
169 Female Y Chengquan Qin
194 Female NaN Yanmei Qian
197 Female N Chengqiang Chu
199 Male N Chunpeng Lv
df_demo.drop_duplicates(['Name', 'Gender'],
keep=False).head() # 保留只出现过一次的性别和姓名组合
#因为删掉了,所以序列变成0,1,2,。。
Out[63]:
Gender Transfer Name
0 Female N Gaopeng Yang
1 Male N Changqiang You
2 Male N Mei Sun
4 Male N Gaojuan You
5 Female N Xiaoli Qian
duplicated 和 drop_duplicates 的功能类似,但前者返回了是否为唯一值的布尔列表,其 keep 参数与后者一致。其返回的序列,把重复元素设为 True ,否则为 False 。 drop_duplicates 等价于把 duplicated 为 True 的对应行剔除。
替换函数
replace
在 replace 中,可以通过字典构造,或者传入两个列表来进行替换
df['Gender'].replace({'Female':0, 'Male':1}).head()
df['Gender'].replace(['Female', 'Male'], [0, 1]).head()
replace 还有一种特殊的方向替换,指定 method 参数为 ffill 则为用前面一个最近的未被替换的值进行替换, bfill 则使用后面最近的未被替换的值进行替换
s = pd.Series(['a', 1, 'b', 2, 1, 1, 'a'])
s.replace([1, 2], method='ffill')
#即将,1,2值都替换掉,用该位置前面最靠近的未被替换的值替换
Out[70]:
0 a
1 a
2 b
3 b
4 b
5 b
6 a
dtype: object
s.replace([1, 2], method='bfill')
#即将,1,2值都替换掉,用该位置后面最靠近的未被替换的值替换
Out[71]:
0 a
1 b
2 b
3 a
4 a
5 a
6 a
dtype: object
s.where(条件判断) 满足条件判断的值保留,不满足则被替换
**s.mask(条件判断)**满足条件判断的值被替换,不满足则保留
逻辑替换包括了 where 和 mask ,这两个函数是完全对称的: where 函数在传入条件为 False 的对应行进行替换,而 mask 在传入条件为 True 的对应行进行替换,当不指定替换值时,替换为缺失值。
s = pd.Series([-1, 1.2345, 100, -50])
s.where(s<0) #满足则被保留,不满足被替换
Out[73]:
0 -1.0
1 NaN
2 NaN
3 -50.0
dtype: float64
s.where(s<0, 100) #不给替换值则为空值
Out[74]:
0 -1.0
1 100.0
2 100.0
3 -50.0
dtype: float64
s.mask(s<0)
Out[75]:
0 NaN
1 1.2345
2 100.0000
3 NaN
dtype: float64
s.mask(s<0, -50)
Out[76]:
0 -50.0000
1 1.2345
2 100.0000
3 -50.0000
dtype: float64
不给条件,给布尔序列也可
s_condition= pd.Series([True,False,False,True],index=s.index)
s.mask(s_condition, -50)
Out[78]:
0 -50.0000
1 1.2345
2 100.0000
3 -50.0000
dtype: float64
数值替换
round, abs, clip 方法,它们分别表示按照给定精度四舍五入、取绝对值和截断
clip函数:限制一个array的上下界
给定一个范围[min, max],数组中值不在这个范围内的,会被限定为这个范围的边界。如给定范围[0, 1],数组中元素值小于0的,值会变为0,数组中元素值大于1的,要被更改为1
s = pd.Series([-1, 1.2345, 100, -50])
s.round(2)
Out[80]:
0 -1.00
1 1.23
2 100.00
3 -50.00
dtype: float64
s.abs()
Out[81]:
0 1.0000
1 1.2345
2 100.0000
3 50.0000
dtype: float64
s.clip(0, 2) # 前两个数分别表示上下截断边界
#数值中小于0的数改为0,大于2的数改为2
Out[82]:
0 0.0000
1 1.2345
2 2.0000
3 0.0000
dtype: float64
排序函数
排序共有两种方式,其一为值排序,其二为索引排序,对应的函数是 sort_values 和 sort_index
df.sort_values(‘排序列名’) 默认ascending=True 为升序
df_demo.sort_values('Height').head()
df_demo.sort_values('Height', ascending=False).head()
多列排序
比如在体重相同的情况下,对身高进行排序,并且保持身高降序排列,体重升序排列
df_demo.sort_values(['Weight','Height'],ascending=[True,False]).head()
索引排序的用法和值排序完全一致,只不过元素的值在索引中,此时需要指定索引层的名字或者层号,用参数 level 表示。另外,需要注意的是字符串的排列顺序由字母顺序决定。
df_demo.sort_index(level=['Grade','Name'],ascending=[True,False]).head()
#level列即按排序列,字符列按字母顺序
mad 函数返回的是一个序列中偏离该序列均值的绝对值大小的均值,例如序列1,3,7,10中,均值为5.25,每一个元素偏离的绝对值为4.25,2.25,1.75,4.75,这个偏离序列的均值为3.25。
df.mad()
df.apply(lambda x:(x-x.mean()).abs().mean()) #这一行实习了同df.mad()一样的结构
apply 的自由度很高,但这是以性能为代价的。一般而言,使用 pandas 的内置函数处理和 apply 来处理同一个任务,其速度会相差较多,因此只有在确实存在自定义需求的情境下才考虑使用 apply 。
四、窗口函数
pandas 中有3类窗口,分别是滑动窗口 rolling 、扩张窗口 expanding 以及指数加权窗口 ewm
1.滑动窗口
要使用滑窗函数,就必须先要对一个序列使用 .rolling 得到滑窗对象,其最重要的参数为窗口大小 window
rolling函数移动的窗口的意思
DataFrame.rolling(window, min_periods=None, freq=None, center=False, win_type=None, on=None, axis=0, closed=None)
参数:
1) window:表示时间窗的大小
2)min_periods:最少需要有值的观测点的数量,对于int类型,默认与window相等
import pandas as pd
# 导入 pandas
index = pd.date_range('2022-01-01',periods=6)
#创建日期序列
data = pd.DataFrame(np.arange(len(index)),index=index,columns=['test'])
#创建简单的pd.DataFrame
print(data)
#打印data
data['sum'] = data.test.rolling(3).sum()
#移动3个值,进行求和
data['mean'] = data.test.rolling(3).mean()
#移动3个值,进行求平均数
data['mean1'] = data.test.rolling(3,min_periods=2).mean()
print(data)
结果:
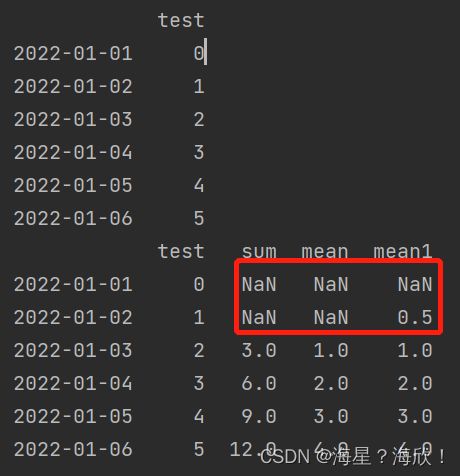
sum列和mean列分别为三个连续值(从当前值向前推两个,共计三个值)的求和/求平均值
rolling.count()计算非空观察数
rolling. sum()值的总和
rolling. mean()平均值
rolling. median()计算中值
rolling. min()得到最小值
rolling. max()得到最大值
rolling. std()求贝塞尔修正样本标准差
rolling. var()求无偏方差
rolling. skew()样本偏度
rolling. kurt()样本峰度
rolling. quantile()样本分位数(参数值为百分比)
rolling. apply()这个自己可以定义函数来灵活运用。
rolling. cov()无偏协方差在数据处理中用于衡量两个变量的总体误差。
rolling. corr()相关系数, 它是研究变量之间线性相关程度的量
shift, diff, pct_change 是一组类滑窗函数,它们的公共参数为 periods=n ,默认为1,分别表示取向前第 n 个元素的值、与向前第 n 个元素做差(与 Numpy 中不同,后者表示 n 阶差分)、与向前第 n 个元素相比计算增长率。这里的 n 可以为负,表示反方向的类似操作
s = pd.Series([1,3,6,10,15])
s.shift(2)
Out[105]:
0 NaN
1 NaN
2 1.0
3 3.0
4 6.0
dtype: float64
s.diff(3)
Out[106]:
0 NaN
1 NaN
2 NaN
3 9.0 #10-1
4 12.0 #15-3
dtype: float64
s.pct_change()
Out[107]:
0 NaN
1 2.000000 #(3-1)/1
2 1.000000 #(6-3)/3
3 0.666667 #(10-6)/6
4 0.500000
dtype: float64
s.shift(-1)
Out[108]:
0 3.0
1 6.0
2 10.0
3 15.0
4 NaN
dtype: float64
s.diff(-2)
Out[109]:
0 -5.0
1 -7.0
2 -9.0
3 NaN
4 NaN
dtype: float64
将shift, diff, pct_change视作类滑窗函数的原因是,它们的功能可以用窗口大小为 n+1 的 rolling 方法等价代替
s.rolling(3).apply(lambda x:list(x)[0]) # 等同s.shift(2)
Out[110]:
0 NaN
1 NaN
2 1.0
3 3.0
4 6.0
dtype: float64
s.rolling(4).apply(lambda x:list(x)[-1]-list(x)[0]) # 等同s.diff(3)
Out[111]:
0 NaN
1 NaN
2 NaN
3 9.0
4 12.0
dtype: float64
def my_pct(x):
L = list(x)
return L[-1]/L[0]-1
#定义增长率函数my_pct
s.rolling(2).apply(my_pct) #等同 s.pct_change()
Out[113]:
0 NaN
1 2.000000
2 1.000000
3 0.666667
4 0.500000
dtype: float64
2. 扩张窗口
扩张窗口又称累计窗口,可以理解为一个动态长度的窗口,其窗口的大小就是从序列开始处到具体操作的对应位置,其使用的聚合函数会作用于这些逐步扩张的窗口上。具体地说,设序列为a1, a2, a3, a4,则其每个位置对应的窗口即[a1]、[a1, a2]、[a1, a2, a3]、[a1, a2, a3, a4]
s = pd.Series([1, 3, 6, 10])
print(s.expanding().sum())
print(s.expanding().mean())
输出:
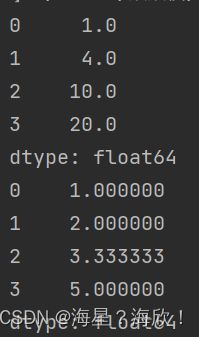
五、练习
第一题
1.
df[[‘列1’,‘列2’]].sum(1) 即对每行的几组列求和
df = pd.read_csv('data/pokemon.csv')
(df[['HP', 'Attack', 'Defense', 'Sp. Atk', 'Sp. Def', 'Speed'
]].sum(1)!=df['Total']).mean()
2.a 求第一属性的种类数量和前三多数量对应的种类
多个列组合的唯一值:drop_duplicates
dp_dup = df.drop_duplicates('#', keep='first')
dp_dup['Type 1'].nunique()
Out[32]: 18
dp_dup['Type 1'].value_counts().index[:3]
Out[33]: Index(['Water', 'Normal', 'Grass'], dtype='object')
2.b 求第一属性和第二属性的组合种类
attr_dup = dp_dup.drop_duplicates(['Type 1', 'Type 2'])
attr_dup.shape[0]
Out[35]: 143
3.c 求尚未出现过的属性组合
先求出所有种可能,然后排除掉已经出现的 set(L_full).difference(set(L_part))
L_full = [i+' '+j if i!=j else i for i in df['Type 1'
].unique() for j in df['Type 1'].unique()]
L_part = [i+' '+j if not isinstance(j, float) else i for i, j in zip(
df['Type 1'], df['Type 2'])]
res = set(L_full).difference(set(L_part))
len(res) # 太多,不打印了
Out[39]: 170
3.a 取出物攻,超过120的替换为 high ,不足50的替换为 low ,否则设为 mid
用mask,多用几次
df['Attack'].mask(df['Attack']>120, 'high'
).mask(df['Attack']<50, 'low').mask((50<=df['Attack']
)&(df['Attack']<=120), 'mid').head()
3.b 取出第一属性,分别用 replace 和 apply 替换所有字母为大写
#用replace与upper 进行替换为大写
#replace({i :str.upper(i) for i in df['']
df['Type 1'].replace({i:str.upper(i) for i in df['Type 1'].unique()}).head()
#用apply(lambda x:str.upper(x))
df['Type 1'].apply(lambda x:str.upper(x)).head()
3.C 求每个妖怪六项能力的离差,即所有能力中偏离中位数最大的值,添加到 df 并从大到小排序
离差:(x-x.median()).abs()
df['Deviation'] = df[['HP', 'Attack', 'Defense', 'Sp. Atk',
'Sp. Def', 'Speed']].apply(lambda x:np.max(
(x-x.median()).abs()), 1)
df.sort_values('Deviation', ascending=False).head()
第二题