【深度学习】如何封装可维护的restiful api
这篇文章是用一个案例的形式尝试解决字段入参多了,在python这种风格的语言下如何维护的问题!
文章目录
- 前言
- 1. json 是个好东西
- 2. json 是个坏东西
- 3. json维护数据的适用范围总结
- 4.解决
-
- 4.1 基础版
- 4.2 进阶版
-
- 4.2.1 行动
- 4.2.2 精进
- 4.3 另一种选择
- 总结
前言
我们提供算法的服务,如果入参很少,比如图像识别的,input:image,camera_id, business_id, event_id 图片资源、摄像头id、业务线id、事件id ,搭建restiful api的时候可以不那么讲究,怎么写下一个人也能看懂。但是若是数理计算模型,入参很多,可能是一组参数
[ {field1: xxx,field2:xxx, field3:xxx ......}, {field1: xxx,field2:xxx, field3:xxx ......}]
还要二次处理,id列对推理计算没用, 经纬度要转成 温带、热带、寒带的温带信息。这个时候,在json_map上操作就要死人了。来一个新人接手就完蛋了,row 有 30个item, 二次处理后有50个。对应关系就得3天,没熬过去跑路了。
前任又没写注释,(50个字段我也不想写), 再加上进入不同的方法、处理不同的字段。后面来的人怎么玩,主导开发的人都hold不住了。
这篇文章是用一个案例的形式尝试解决字段入参多了,在python这种风格的语言下如何维护的问题!
1. json 是个好东西
以同步用户做统一用户为例,6个字段用json传挺好,因为key语义明确
user_list = [
{ 'username' : 'zs', 'password' : 123456, 'email' : '[email protected]', 'mobile' : 15210420000, 'gender' : '男' },
{ 'username' : 'ls', 'password' : 123456, 'email' : '[email protected]', 'mobile' : 15210420000, 'gender' : '女' } ]
后续需要增加字段encrypt_mobile, encrypt_password,也就是把手机号和密码加密一下再做交互传输或者其它业务。
这个场景下用json是没问题,字段一眼看到底,不需要走下面的流程。
2. json 是个坏东西
美好的时光总是短暂, json 不是只有好处,它的key的维护太过随意。
user_info = {
'username' : 'zs',
'password' : 123456,
'email' : '[email protected]',
'mobile' : 15210420000,
'gender' : '男'
}
# 新增(覆盖)一个key
user_info ['id'] = 1
# 读取key
id = user_info ['id']
# 删除key
del user_info['id']
以上代码或让人觉得,本来就是这样的啊,这不也挺简单么。
# 类型注解compare_field 函数使用
from typing import List,Dict
user_info = {
'username' : 'zs',
'password' : 123456,
'email' : '[email protected]',
'mobile' : 15210420000,
'gender' : '男'
}
# 某个时间要增加 encrypt_mobile 和 encrypt_password 的字段
def add_encrypt_field(user_info:json)->json:
# get from config
md5_salt = "xxx"
mobile = user_info["mobile"]
password = user_info["password"]
user_info["encrypt_mobile"] = md5(md5_salt+str(mobile))
user_info["encrypt_password"] = md5(md5_salt+str(mobile))
return user_info
# 对比用户是否为相同用户
def compare_field(user_info1:json, user_info_list[user_info]:List[Dict])->bool:
# 两个user_info的 mobile相同者为统一用户
for user_info in user_info_list:
if user_info1.get("mobile") == user_info["mobile"]:
return True
return False
分函数写,问题出现了, 在compare_field和add_encrypt_field的两个方法中,你咋知道入参是存在mobile和password 属性的呢? 上面一行定义了啊, 那要是在其它文件定义的呢, 那要是在其它方法要用encrpy_mobile 呢,这个时候,你就要做代码追踪看看在哪维护了呢,万一还有bug,在其它方法根据数据特征某个else分支给删了这个字段呢
3. json维护数据的适用范围总结
好,问题明确了,json对字段的维护有两大缺点:
- 太随意,
- 没有智能提示
这两个缺点在业务模块在一屏以内或者字段少,见名知意的3,5个字段的时候可以忽略。
但是你面对的入参可能是这样的:
input_params = [
{
'small_class_no':1, # 小班号
'tree_name':'杨树',
'avarage_age':2, # 平均年龄
'average_stand_height':1, # 平均高度
'stand_density_index':123, # 林分密度指数
'stand_break_area':20, # 林分断面积
'stand_volume':16, # 蓄积量
'biomass':20, # 生物量
'altitude':200, # 海拔
'slope_direction':30, # 坡向
'slope_degree':5, # 坡度
'slope_pose':"上坡", # 坡位
'soil_thickness':3, # 土壤厚度
'litter_thickness':2, # 枯落物厚度
'small_class_area':600, # 小班面积
'humus_layer_thickness':1,
'climate_zoo':"热带", # 亚热带山地丘陵、热带, 亚热带高山、暖温带、温带、寒温带
},
{
'small_class_no':2, # 小班号
'tree_name':'杨树',
'avarage_age':5, # 平均年龄
'average_stand_height':10, # 平均高度
'stand_density_index':123, # 林分密度指数
'stand_break_area':30, # 林分断面积
'stand_volume':20, # 蓄积量
'biomass':50, # 生物量
'altitude':220, # 海拔
'slope_direction':40, # 坡向
'slope_degree':15, # 坡度
'slope_pose':"下坡", # 坡位
'soil_thickness':5, # 土壤厚度
'litter_thickness':2, # 枯落物厚度
'humus_layer_thickness':10,
'small_class_area':600, # 小班面积
'climate_zoo':"热带", # 亚热带山地丘陵、热带, 亚热带高山、暖温带、温带、寒温带
}
]
入参之后需要转化一些字段:
- 平均年龄要以5年为单位分级:1代表 [0-5)年 2代表 [5-10)年…
- 海拔高度要以200m为单位分级: 1代表 [0-200) 2 代表 [200-400)…
- 坡位:1. 脊部;2.上坡;3.中坡;4.下坡;5.山谷(或山洼);6.平地 要转成枚举
- climate_zoo 要分成两个 1 亚热带山地丘陵、热带, 2 亚热带高山、暖温带、温带、寒温带
- 土壤厚度:土壤厚度:
a 亚热带山地丘陵、热带
厚 ≥80cm
中 40cm~79cm
薄 <40cm
b 亚热带高山、暖温带、温带、寒温带
厚 ≥60cm
中 30~59cm
薄 <30cm - 腐殖质层厚度:1. 薄:<2cm 2. 中:2cm~5cm 3. 厚:>5cm
- small_class_area 小班面积 >= 600 m^2 才有效
- 坡向要转成枚举:北坡:方位角 338°~22° 东北坡:方位角 23°~ 67° 东坡:方位角 68°~ 112° 东南坡:方位角 113°~157° 南坡:方位角 158°~202° 西南坡:方位角 203°~247° 西坡:方位角 248°~292° 西北坡:方位角 293°~337° 无坡向:坡度<5°的地段
后续业务有时需要原始字段,有时需要转换字段,json维护的方式就暴露无疑。
4.解决
4.1 基础版
当然你可以先设置json的数据模版,来解决第一个问题。
param_template = {
'small_class_no':"", # 小班号
"tree_name":"", # 树种名字
# 测树因子
'avarage_age':"", # 平均年龄
'average_stand_height':"", # 平均高度
'stand_density_index':"", # 林分密度指数
'stand_break_area':"", # 林分断面积
'stand_volume':"", # 蓄积量
'biomass':"", # 生物量
# 立地因子
'altitude':"", # 海拔
'slope_direction':"", # 坡向
'slope_degree':"", # 坡度
'slope_pose':"", # 坡位
'soil_thickness':"", # 土壤厚度
'litter_thickness':"", # 枯落物厚度
'humus_layer_thickness':"", # 腐殖质层厚度
'small_class_area':"", # 小班面积
'climate_zoo':"", # 亚热带山地丘陵、热带, 亚热带高山、暖温带、温带、寒温带
# 转换过后的数据
'int_humus_layer_thickness':"", # 腐殖质层厚度
'int_slope_pose':"",
'int_soil_thickness':"",
'int_litter_thickness':"",
'int_altitude':"", # 海拔等级 200m一个等级
'int_climate_zoo':"", # 亚热带山地丘陵、热带 1 亚热带高山,暖温带,温带,寒温带 2
}
原始字段17个,一共23个,而且都是不熟悉的字段, 数据模版解决了字段维护的问题,初始化就在那里等着,只需要覆盖,不用新加。
但没解决智能提示的问题。
4.2 进阶版
任务:需找一个带智能提示的数据类型:nametuple 有名元祖
4.2.1 行动
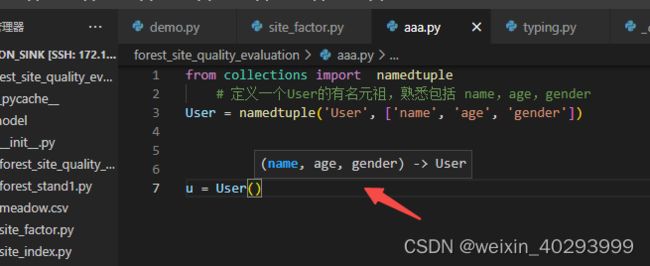
In [2]: from collections import namedtuple
# 定义一个User的有名元祖,熟悉包括 name,age,gender
...: User = namedtuple('User', ['name', 'age', 'gender'])
# 初始化
...: u = User('villa', 33, 'male')
# 这里的获取就带智能提示了,一定要自己试一下,博客文章没法演示
...: print(u.name)
...: print(u.age)
...: print(u.gender)
...: print(u)
villa
33
male
User(name='villa', age=33, gender='male')
# 也可以在适当的时候转回每个人都很喜欢的json
In [5]: u._asdict()
Out[5]: {'name': 'villa', 'age': 33, 'gender': 'male'}
修改属性要这样操作:
# 这样修改会报错
In [6]: u.age = 33
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-6-bea52c69315f> in <module>
----> 1 u.age = 33
AttributeError: can't set attribute
# 正确的修改方式
In [8]: u = u._replace(age=32)
In [9]: u
Out[9]: User(name='villa', age=32, gender='male')
正确的修改方式,还需要赋值回来,还是挺麻烦的,而且要记住age属性(不用 u. 可以智能提示发现它叫age了,嘿嘿)
u = u._replace(age=32)
我要是一般的博主,介绍有名元组到这里其实已经结束了…等等,智能提示的问题解决了,那初始化占位怎么办?
from collections import namedtuple
# 定义一个User的有名元祖,熟悉包括 name,age,gender
User = namedtuple('User', ['name', 'age', 'gender'])
u = User('villa', 33, 'male')
u
u1 = User('villa', 33)
u1
u2 = User('villa', 33, '')
In [10]: User = namedtuple('User', ['name', 'age', 'gender'])
...:
...: u = User('villa', 33, 'male')
...: u
...: u1 = User('villa', 33)
...: u1
...: u2 = User('villa', 33, '')
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in
3 u = User('villa', 33, 'male')
4 u
----> 5 u1 = User('villa', 33)
6 u1
7 u2 = User('villa', 33, '')
TypeError: __new__() missing 1 required positional argument: 'gender'
不赋值不行啊,报错了,u2是可以过的,提示一下,我们赋值不需要记住属性顺序,ide的智能提示会提示,一图胜千言。
缺点:暂时没有gender字段的信息,需要在每次初始化的时候给“”或者None (python阉割版强类型其实无所谓嘿嘿)
而且我们不能新增属性,需要在定义user有名元祖类的时候写好!
4.2.2 精进
针对4.2.1的缺点:暂时没有gender字段的信息,需要在每次初始化的时候给“”或者None
你可能会问? 我觉得也没问题啊,难道不应该这样么,在初始化的时候给默认值。
每次初始化给默认值没问题,槽点在于每次初始化你都需要手动赋值,用一次赋值一次!!!
设计理念是接收定义的复杂但不接受调用的复杂,采用4.2.1 每次调用都变得复杂
解决方案:定义复杂一些(继承nametuple,改写他的初始化函数__new__),而避免每次调用都手动负责。(为什么不是__init__, 有这个问题的同学,要查一下两者的区别,init 依赖__new__, new 更底层,以及尝试一下__init__下重写到底行不行,欢迎评论区留言, 同时也可以看下__slot__属性)
from collections import namedtuple
class Color(namedtuple("Color", ["r", "g", "b", "alpha"])):
def __new__(cls, r, g, b, alpha=None):
return super().__new__(cls, r, g, b, alpha)
>>> c = Color(r=0, g=0, b=0)
>>> c
Color(r=0, g=0, b=0, alpha=None)
通过这种修改,alpha属性就不需要每次初始化都指定了
ps: init 改完之后输出报错,报错信息也输出下
from collections import namedtuple
class Color(namedtuple("Color", ["r", "g", "b", "alpha"])):
def __init__(cls, r, g, b, alpha=None):
return super().__init__(cls, r, g, b, alpha)
c = Color(r=0, g=0, b=0)
print(c)
# -------------------------------------------------------------------
(py38_18) [jianming_ge@localhost forest_site_quality_evaluation]$ python aaa.py
Traceback (most recent call last):
File "aaa.py", line 7, in <module>
c = Color(r=0, g=0, b=0)
TypeError: __new__() missing 1 required positional argument: 'alpha'
4.3 另一种选择
4.2已经足够好了,但是我还说又臭又长的再给一个方案:类对象初始化
代码一镜到底oh yeah!版本
class SmallClassNoParams(object):
__slots__ = [
'small_class_no', # 小班号
"tree_name", # 树种名字
# 测树因子
'avarage_age', # 平均年龄
'average_stand_height', # 平均高度
'stand_density_index', # 林分密度指数
'stand_break_area', # 林分断面积
'stand_volume', # 蓄积量
'biomass', # 生物量
# 立地因子
'altitude', # 海拔
'slope_direction', # 坡向
'slope_degree', # 坡度
'slope_pose', # 坡位
'soil_thickness', # 土壤厚度
'litter_thickness', # 枯落物厚度
'humus_layer_thickness', # 腐殖质层厚度
'small_class_area', # 小班面积
'climate_zoo', # 亚热带山地丘陵、热带, 亚热带高山、暖温带、温带、寒温带
# 转换过后的数据
'int_humus_layer_thickness', # 腐殖质层厚度
'int_slope_pose',
'int_soil_thickness',
'int_litter_thickness',
'int_altitude', # 海拔等级 200m一个等级
'int_climate_zoo', # 亚热带山地丘陵、热带 1 亚热带高山,暖温带,温带,寒温带 2
]
def __init__(self, small_class_no, tree_name, avarage_age, average_stand_height, stand_density_index, stand_break_area, stand_volume, biomass,
altitude, slope_direction, slope_degree, slope_pose, soil_thickness, litter_thickness,humus_layer_thickness, small_class_area, climate_zoo,int_altitude=None,int_climate_zoo=None):
# 林班面积必须大于600 m^2
if small_class_area < 600:
raise Exception("small_class_area < 600m^2")
if climate_zoo not in ["亚热带山地丘陵","热带","亚热带高山","暖温带","温带","寒温带"]:
raise Exception("climate_zoo must be one of 亚热带山地丘陵,热带,亚热带高山,暖温带,温带,寒温带")
self.int_climate_zoo = Soil_Type.SUBTROPICAL_MOUNTAIN_HILL_AND_TROPICAL.value if "亚热带山地丘陵、热带".find(row["climate_zoo"]) >=0 else Soil_Type.SUBTROPICAL_MOUNTAIN_WARM_TEMPERATE_TEMPERATE_COLD_TEMPERATE_ZONE.value
self.int_soil_thickness = get_soil_thickness_level(soil_thickness,self.int_climate_zoo).value
self.humus_layer_thickness = humus_layer_thickness
self.int_humus_layer_thickness = get_humus_thickness_level(humus_layer_thickness)
int_slope_pose = map_slope_pose.get(slope_pose)
if not int_slope_pose:
raise Exception("slope_pose must be one of 1. 脊部;2.上坡;3.中坡;4.下坡;5.山谷(或山洼);6.平地")
self.int_litter_thickness = get_litter_thickness_level(litter_thickness)
self.int_slope_pose = int_slope_pose
self.small_class_no = small_class_no
self.tree_name = tree_name
self.avarage_age = avarage_age
self.average_stand_height = average_stand_height
self.stand_density_index = stand_density_index
self.stand_break_area = stand_break_area
self.stand_volume = stand_volume
self.biomass = biomass
self.altitude = altitude
self.slope_direction = slope_direction
self.slope_degree = slope_degree
self.slope_pose = slope_pose
self.soil_thickness = soil_thickness
self.litter_thickness = litter_thickness
self.small_class_area = small_class_area
self.climate_zoo = climate_zoo
self.int_altitude = math.ceil(altitude/200)
def to_json(self):
a = {}
for field in self.__slots__:
a.__setitem__(field,getattr(self,field))
return a
使用
import json
handle_params = []
# step 1: 验证参数并转换成有名元祖
for row in input_params:
## 完成初始化的时候同时验证参数了, **row是什么意思自行百度
a = SmallClassNoParams(**row)
## 我是存的json,村对象也可以,主要是为了转成pandas,为后续并行计算打基础
handle_params.append(a.to_json())
X = pd.DataFrame(handle_params,columns=['avarage_age','average_stand_height','stand_density_index','stand_break_area','stand_break_area','stand_volume','altitude','slope_direction','int_humus_layer_thickness','int_slope_pose','int_soil_thickness','int_litter_thickness','int_altitude','int_climate_zoo',])
print(X)
# X = np.array([[1, 2], [1, 4], [1, 0],
# [4, 2], [4, 4], [4, 0]])
clustering = AgglomerativeClustering(2).fit(X)
print(clustering.labels_)
优点:
- **slot**属性用来定义哪些属性应该暴露出来
- 在初始化的同时做参数转化维护,而且只在init里面做参数转化,预期是获取到参数对象后,你的参数一定是对的,报错是计算业务出错了!!!
- to_json 方法用来将对象转成json,哪些属性能转出来取决于1.的定义
- to_json的方法用到了getattr(对象,属性名)内置方法,这是我第一次把它用到生产中,之前我肤浅的认为,这是脱了裤子放屁,对象.属性名的方式不香么
- 其实我还用__getitem__魔术方法实现过,不过死循环了,列出来你可以想一下为啥读属性的时候会死循环
- __setitem__也是魔术方法,你可以自己练习一下,看看他的调用时机
- 我知道在sqlalchemy或者flask中有个column属性也能实现,但偷个懒不查了。
这样以来,就分层了,等等~我实现的这个参数对象类不就是restiful 框架的参数验证层么!
总结
其实以上代码若一直用list[json]的维护方式,2个小时可以实现,但这篇文章的方法,我实现了超过5个小时,有了思路,不一定能改对,再真正落地思考的同时,会报错,有助于理解魔术方法在什么场景下适合。啰⑦⑧嗦,各位见笑!