RocketQA(百度):一种对开放域问答的向量化召回优化算法
文章目录
-
- 前言
- 正文
-
- RocketQA v1
-
- 任务描述
- 方法总览
-
- dual-encoder
- 训练
- 推理
- 具体优化方法
-
- Cross-batch Negtives
- Denoised Hard Negatives
- Data Agumentation
- 训练步骤
- 模型效果和小结
- RocketQA v2
-
- 任务描述
- 具体方法
-
- Dynamic Listwise Distillation
- Hybrid Data Augmentation
- 训练步骤
- 模型效果和小结
- PAIR
前言
本文介绍百度在2021年发表的一系列关于文档向量化召回&&排序的文章。
官方github地址。
主要有以下三篇文章:
- August 26, 2021: RocketQA v2 was accepted by EMNLP 2021. [code/model]
- May 5, 2021: PAIR was accepted by ACL 2021. [code/model]
- March 11, 2021: RocketQA v1 was accepted by NAACL 2021. [code/model]
ps:1.三篇文章给三大顶会各投了一篇,有点调皮。
2.本文很多地方会从论文的角度,用第一人称的视角来进行介绍。
正文
虽然百度给出了三篇论文的投稿时间,但个人认为RocketQA v1和v2的关系更加密切,所以按照Rocket V1、Rocket V2、PAIR的顺序进行介绍。
RocketQA v1
首先直接引用论文的abstract来对文章进行一个介绍:
在开放领域问答中,向量化段落检索已经成为一种新的检索相关段落以找到答案的范式。通常,采用dual-encoder(后文简称DE)架构来学习问题(query)和段落(passage)的向量化表示,以进行语义匹配。然而,由于1.训练和推理之间的差异;2.未标记的正样本;3.有限的训练数据等挑战。很难有效地训练DE。为了应对这些挑战,我们提出了一种称为RocketQA的优化训练方法,以改进向量化段落检索。我们在RocketQA中做出了三大技术贡献,即1.cross-batch negatives. 2.denoised hard negatives. 3.data augmentation。
ps:正样本的定义是能对query进行一定解答的文章。
这里用一幅图解释下dual-encoder和cross-encoder,这也是文本向量化&相关性的核心基础:(这里[CLS]和[SEP]需要有BERT的背景知识,大家不清楚的先看看BERT)
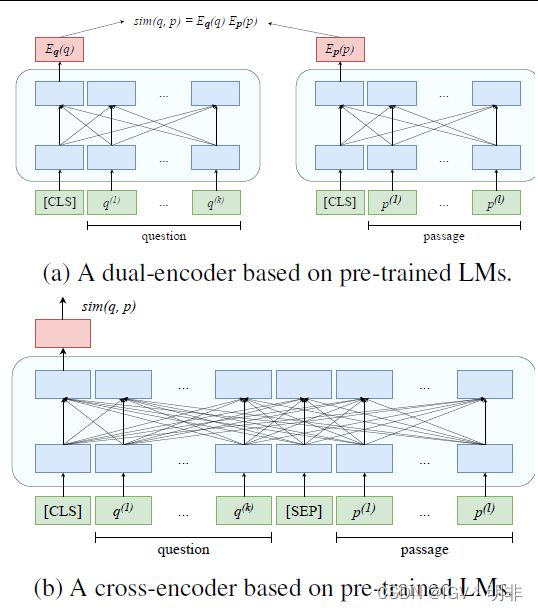
任务描述
给定一个问题,系统需要基于庞大的知识库去回答。设 C C C代表与知识库,由 N N N个文档组成,把 N N N个文档分成 M M M篇文章,记做 p 1 , p 2 , . . . , p M p_1,p_2,...,p_M p1,p2,...,pM,其中每篇文章又可以分成长度为 l l l的tokens: p i ( 1 ) , p i ( 2 ) , . . . , p i ( l ) p^{(1)}_i,p^{(2)}_i,...,p^{(l)}_i pi(1),pi(2),...,pi(l)。给定一个问题q,目标就是从 M M M篇候选集中,寻找一篇答案文章 p i p_i pi,并且从 p i p_i pi中找出具体片段 p i ( s ) , p i ( s + 1 ) , . . . , p i ( e ) p^{(s)}_i,p^{(s+1)}_i,...,p^{(e)}_i pi(s),pi(s+1),...,pi(e)来回答这个问题。
方法总览
dual-encoder
对于Query和passage,分别训练两个编码器 E q ( ⋅ ) E_q(·) Eq(⋅)和 E p ( ⋅ ) E_p(·) Ep(⋅)。首先对所有的文章用 E p ( ⋅ ) E_p(·) Ep(⋅)进行编码,每篇文章都编码成一个维度为d的稠密向量,并创建数据库索引。对于每个访问的query,先对其用 E q ( ⋅ ) E_q(·) Eq(⋅)编码成d维稠密向量,然后从数据库中搜索出k个和他"距离"最近的文章,我们一般用余弦相似度/归一化点乘定义"距离": s i m ( q , p ) = E q ( q ) ∗ E p ( p ) sim(q,p)=E_q(q)*E_p(p) sim(q,p)=Eq(q)∗Ep(p)
ps:我们一般选择BERT作为编码器,然后用输出层的[CLS]的向量作为query或passage的编码。
训练
训练目标的核心思想就是希望
- query和正样本passage之间的相似度越大越好
- query和负样本passage之间的相似度越小越好
所以我们采用了InfoNCE_loss损失函数,请仔细体悟这个损失函数是如何同时满足以上2个要求的:

从效果上来说,我们当然想把query对应的所有负样本passage都加入损失函数的计算中,但从算力上考虑显然是不可能的,所以只能选取m个负样本(m<
推理
1.利用FAISS库对全部passage的向量表征进行建库。
2.对输入的query用IndexFlatIP等API进行索召回和索引。
具体优化方法
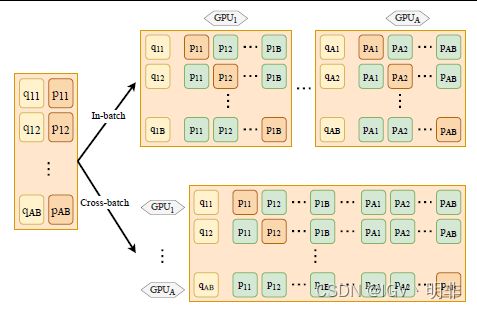
Cross-batch Negtives
首先介绍一种在训练dual-encoder时,被广泛使用的叫做in-batch negatives的方法:
假设有在一张GPU上的一个mini-batch中有个B个query及其对应的正样本passage,那对于每个query来说,剩下的B-1个passages都可以是负样本,并且不需要额外再去对负样本进行采样。B个passages都被多次重复使用,这意味着无论在内存消耗上还是算力上都是非常高效的。
基于这个思想,我们提出了cross-batch negatives的方法:
如果有多张GPU的话,那是不是可以同时把每张GPU中的mini-batch的passage都当成一个负样本,这样就极大地扩充了负样本的数量,而且也不会消耗多少额外的算力。假设有A张显卡的话,那么对于每个query来说,就有A*B-1个负样本。
最后可以通过一张图来理解这两个方法的关联:(不得不说优秀的论文的图例也是那么的优雅简洁)
Denoised Hard Negatives
就如前面所说的,负样本的数量并不是绝对,高质量的负样本也十分重要。
大多数负样本都是比较easy的(我们用easy和hard来表示这个样本是否容易学习正确),所以我们需要去挖掘一些hard的负样本。
一种最直观的想法就是选择召回的top-ranked的passages作为hard负样本。但这样的话会有一些"错误"负样本(也就是本应是正样本,但被当成了hard负样本),如果单纯靠标注员去把top-ranked中的正样本给全部挑出来是不现实的(数据量太大),所以我们需要一种更高效的方式对hard负样本进行去噪。
这里我们想到去训练一个cross-encoder模型作为"裁判"去过滤掉top-ranked的passages中的false negatives。在很多论文中已经验证过,cross-encoder结构比dual-encoder结构的效果更好,因为它能通过深层次交互来捕捉到语义相似度。cross-encoder的缺点也很明显,在服务的推理中,计算效率太低。
最后再梳理一下挖掘hard负样本的整个流程:首先分别训练一个dual-encoder和cross-encoder。然后对每个query,用dual-encoder召回top-ranked的passages,接着选择那些cross-encoder以高置信度判定为负样本的passages作为新的dual-encoder模型训练的hard负样本。
Data Agumentation
第三个策略主要是想解决训练数据不足的问题。
既然cross-encoder这么强力,那么我们也可以用它来对未标注的样本进行打标。
具体来说,对于一批新的未标注的query,在passage集合不变的情况下,我们可以用训练好的cross-encoder对其标签进行预测。为了保证自动标注数据的质量,我们可以只选择预测结果置信度较高的正样本和负样本。最后这些正负样本就可以作为数据增强得到的数据去训练dual-encoder模型。
训练步骤
介绍完这三个方法,下一步就是需要说明三个方法的一个配合使用。简单来说这几部是串行地进行的:
- 用cross-batch的方法在原始数据集 D L D_L DL上训练一个v0版的dual-encoder—— M D ( 0 ) M^{(0)}_D MD(0)。
- 在数据集 D L D_L DL上训练一个cross-encoder—— M C M_C MC。注意这里的负样本采样方式,首先用 M D ( 0 ) M^{(0)}_D MD(0)召回top-k的passages,并把其中的正样本给排除掉,然后从中随机选取n个作为负样本。这种采样方式是为了让cross-encoder去适应dual-encoder的召回数据分布(大家可以仔细领悟下)。
- 基于1和2训练的dual-encoder M D ( 0 ) M^{(0)}_D MD(0)和cross-encoder M C M_C MC,对每个query进行hard负样本采样,并加入dual-encoder的训练中(只选择那些cross-encoder判定置信度高的负样本作为dual-encoder训练的hard负样本),得到新的dual-encoder M D ( 1 ) M^{(1)}_D MD(1)
- 基于2和3得到的dual-encoder M D ( 1 ) M^{(1)}_D MD(1)和cross-encoder M C M_C MC,构造一批自动打标的训练数据 D U D_U DU,基于 D U D_U DU和 D L D_L DL训练一个最终的dual-encoder M D ( 2 ) M^{(2)}_D MD(2)
注意:1.cross-batch negative策略是贯穿所有训练dual-encoder步骤的。2.cross-encoder在第三步和第四步中的目的和作用是不同的。

模型效果和小结
在两个常见的QA任务上,和之前主流模型的一些效果对比:

本文主要是在讨论如何针对QA类的召回问题,训练一个优秀的dual-encoder,通过把一系列并不复杂的思想和方法进行组合,得到了一个优美的最终方案,这也符合百度论文的一贯作风。
RocketQA v2
我个人愚见,v2虽然也有很多创新,但比起v1对文本向量化召回做出的统一性贡献来说,还是差一些,所以对v2的介绍会相对不那么详细,大家感兴趣的可以自行阅读原文。
任务描述
RocketQA v1的重点主要还是在dual-encoder(文档向量化召回)上。但RocketQA v2考虑同时对dual-encoder和cross-encoder进行训练,并且这俩模型效果在训练过程中会互相影响。
具体方法
Dynamic Listwise Distillation
因为cross-encoder有更强的能力,所以从reranker中进行知识蒸馏并传导给retriver已经是一种常见的做法了。但在以往的策略中,我们往往对re-ranker和retriever是分别训练的,这就无法使两个模型在训练中互相优化提升。
所以我们设计了一个统一的listwise训练方法,能够同时训练re-ranker和retriever,并且动态地更新re-ranker和retriever的参数。
具体来说,给定一个query,以及其对应的passages候选集合: P q = { p q , i } 0 < i < m P_q=\{p_{q,i}\}_{0

我们的主要思想就是自适应地去减少retriever和re-ranker之间的分布差异,使得它俩能够在训练中互相提升。
为了达到这个效果,我们选择最小化 s ~ d e ( q , p ) {\tilde s_{de}(q,p)} s~de(q,p)和 s ~ c e ( q , p ) {\tilde s_{ce}(q,p)} s~ce(q,p)之间的KL散度:

同时,我们还需要对cross-encoder进行进一步的训练,采用的依然是InfoNCE_loss的结构,其中N是训练实例的数量:
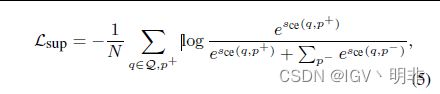
我们把两个损失函数结合起来就得到了最终的损失函数:
L f i n a l = L K L + L s u p L_{final} = L_{KL} + L_{sup} Lfinal=LKL+Lsup
最后再梳理一下整个流程,首先优化re-ranker,然后根据re-ranker的预测结果,作为一个"软标签"去训练retriever:
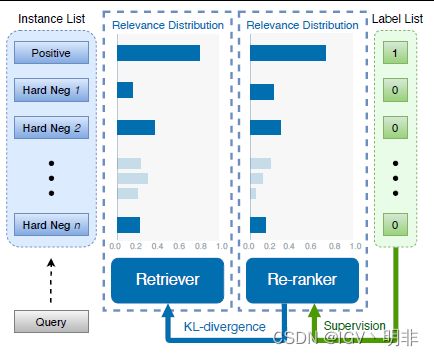
Hybrid Data Augmentation
为了更好地发挥 dynamic listwise distillation的作用,我们需要在制定一个生成候选文档列表 P q P_q Pq的方法:Hybrid Data Augmentation,如下图所示
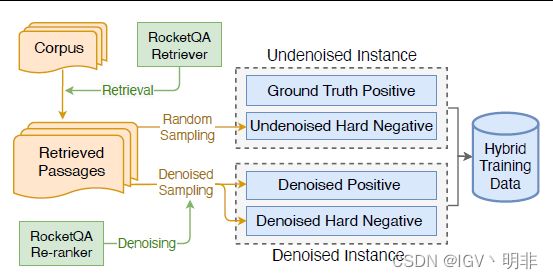
我们同时使用了无噪和去噪的数据来生成data,二者都需要先用RocketQA从语料中来召回top-n的文档,然后分别进行如下操作:
- 对于无噪音的数据,我们从top-n文档中除正样本的数据里随机采样作为无噪音的hard负样本,正样本就是标注的正例。
- 对于有噪音的数据,我们用RocketQA的Re-ranker过滤掉top-n文档中低置信度的正样本和负样本,剩下的就作为去噪的正、负样本数据来使用。
训练步骤
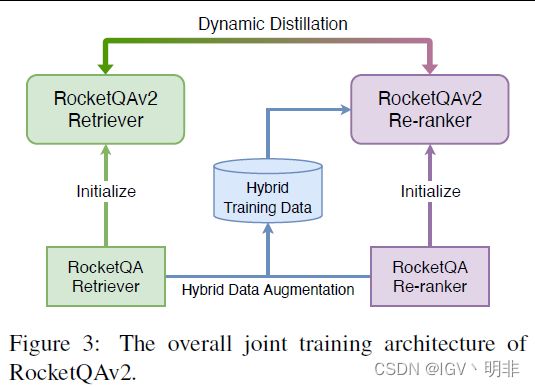
首先从训练好的RocketQA v1的dual-encoder和cross-encoder中,初始化了一组retriever和re-ranker;然后用这组retriever和re-ranker通过hybrid data augmentation方法生成训练数据;最后用dynamic listwise distillation方法同时对retriever和re-ranker进行优化训练。
模型效果和小结

可以看到RocketQA v2和v1相比还是有一定的提升。
本文主要的创新点还是在retriever和re-ranker的联合训练上,二者自适应地互相影响,最终达到一个平衡的点上。
PAIR
未末待续…