知识融合之dedupe初体验
前言
最近在学习知识图谱的相关知识,看到了知识融合以及其比较流行的python库dedupe,就想着自己跑一下它的example,并进行简单的分析。
参考文章:
- 知识图谱入门 (六) 知识融合 [1]
- 知识融合之dedupe [2]
- 什么是主动学习?[3]
前者主要是介绍知识融合的大体框架和理论知识。
后者主要是介绍了python环境下dedupe的安装和跑一个简单的demo。
但[2]对于demo中的核心函数的原理基本都没做介绍,笔者自己进行更深入的了解后,发现源代码确实封装地比较难懂,之后在结合官方api进行阅读后,有了一些个人的理解,这里做一个记录。
!!!ps: 目前dedupe最新版已经发布了2.0以上版本,但笔者在使用过程中会报错,因此又只能重新安装了1.9.7的版本。所以在下面所述csv_exampile的项目中,核心api都是基于老版本来的,而当前最新的dedupe-example的git项目中的部分api和读者写的是有出入的。
概括来说, 如果你安装2.0版本的dedupe,就用最新的dedupe-example。
如果你和笔者一样安装的1.9.7版本的dedupe,在运行dedupe-examplie的demo的时候就必须使用老版的api。
正文
本次介绍的demo是dedupe-examples中的csv_example项目,这是一个芝加哥幼儿教育机构的去重项目。
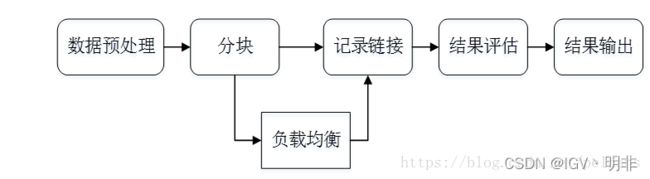
这里贴一下[1]中的框架图,方便后续讲解:
执行命令可以开始训练,并保存模型和预测结果文件。
csv_example.py
数据预处理
数据预处理很好理解,demo代码中也有所体现,这里简单贴一下
column = unidecode(column)
column = re.sub(' +', ' ', column)
column = re.sub('\n', ' ', column)
column = column.strip().strip('"').strip("'").lower().strip()
不过自己实践中肯定需要根据自身业务场景进行调整,这个不用多说。
特征选择
设置需要用到的特征(变量/属性),这个也很好理解,因为在实际业务场景中,有些特征是显然没用的,我们只需要保留(可能)有用的特征:
fields = [
{'field': 'Site name', 'type': 'String'},
{'field': 'Address', 'type': 'String'},
{'field': 'Zip', 'type': 'Exact', 'has missing': True},
{'field': 'Phone', 'type': 'String', 'has missing': True},
]
deduper = dedupe.Dedupe(fields)
'filed’是属性名。
‘type’是属性进行相似度计算时的方式,String是用编辑距离,Exact是严格相等,还有很多别的’type’
'has miss’是描述这属性在原文件中是否有缺省值。
采样
deduper.sample(data_d, sample_size=15000,blocked_proportion=0.5)
data_d表示读取原始文件后存在一个dict中,
15000指的是从中一共采样15000个pair对进行训练,
其中有0.5*15000的pair对是随机采样的,剩下的是采样的"相似对"。
然而这里的"相似对"是具体是如何生成的笔者也没看明白(水平有限,感兴趣的可以自己看源码),这里贴一下官方api的参数解释:
blocked_proportion (float) – The proportion of record pairs to be sampled from similar records, as opposed to randomly selected pairs.
至于为什么要采样“相似对”(也就是hard case,因为不相似的pair对很好判断),需要去了解下"主动学习",这里引用[3]中的一段话:
主动学习(Active Learning)的大致思路就是:通过机器学习的方法获取到那些比较“难”分类的样本数据,让人工再次确认和审核,然后将人工标注得到的数据再次使用有监督学习模型或者半监督学习模型进行训练,逐步提升模型的效果,将人工经验融入机器学习的模型中。
标注
既然是机器学习,标注自然少不了:
dedupe.consoleLabel(deduper)
笔者自己只标注了20来个pair对,根据体感来说基本都是"相似对"。
训练
标注完毕后自然就是训练了:
deduper.train()
这里训练的源码我大致看了下,虽然也封装的很深,但结合【1】的理论知识和类的命名可知,过程大致如下:
- 计算每个属性值的相似度。(这个demo一共就4个属性值)
- 给每个属性相似度赋予一个初始权重。
- 权重通过逻辑回归模型不断学习更新。
- 最终实体的相似度 r=sigmoid(w1sim1+w2sim2+w3sim3+w4sim4)
ps:wi表示第i个属性相似度的权重,simi表示第i个属性相似度。
聚类
首先解释下为什么要聚类。
因为在去重问题中,同一个"实体"可能会出现多种表现形式,我们需要把这个实体的所有表现形式都聚到同一类中,所以在最后需要进行聚类。
然而最麻烦的却是在这一步,虽然也只是一个函数的问题,但这里做的事情并不少:
clustered_dupes = deduper.match(data_d, 0.5)
这个match其实又分为三个函数:
pairs = deduper.pairs(data)
scores = deduper.scores(pairs)
clusters = deduper.cluster(scores)
一个个来看:
1.pairs(虽然源码也没看太明白)
deduper.pairs(data)
- fingerprints: Instance of dedupe.blocking.Fingerprinter class if the train() has been run, else None.
- pairs: Yield pairs of records that share common fingerprints.
从1不难推断,fingerprints(fp)是模型训练后才会产生,所以可以推断是和模型预测相关的。
再结合2来看,基本可以断定,fp就是模型的预测结果,也就是模型推断这个pair对是否是"一致"的。这点应该是没有疑问的。
不过这里还有一个问题,就是如果把所有数据两两配对让模型进行预测,当模型比较复杂而且数据量又大的话,计算复杂度太高。所以数据实现就会按某种算法进行block(即图1中的分块)。但block的源码我也没找着,只能推测是在pairs这一步的时候或者更之前就进行的block。这样就可以只在每个block中进行两两计算了。
2.scores
这个就很好理解了,每个pair对都会有个模型计算的相似度得分。
3.cluster(默认阈值为0.5)
这个源码比较简单,而且api的描述也比较详细,我放一下链接:
https://docs.dedupe.io/en/latest/API-documentation.html#dedupe.Dedupe.cluster
简单来说就是采用的层次聚类,距离度量采用“平均度量”的思想,大家感兴趣可以自己去看看。
最后再对聚类结果进行保存就完成了整个训练和预测的流程了。
评估
执行命令可进行评估:
python csv_evaluation.py
这个demo中一共有3000+的样本,笔者只标注了20条数据,最终就能得到不错的结果:

小结:
dedupe除了能做相似数据去重以外,也有很多其他的功能,感兴趣的话赶紧尝试一下。