(8) [ICML14] Towards End-to-End Speech Recognition with Recurrent Neural Networks
计划完成深度学习入门的126篇论文第八篇,多伦多大学的Alex Gravesz在End-to-End Deep RNN在Speech Recognition方向上的论文续作。
ABSTRACT&INTRODUCTION
摘要
本文提出了一种语音识别系统,该系统不需要中间语音表示,直接用文本对音频数据进行转录。该系统是基于深度双向LSTM递归神经网络结构和连接主义者的时间分类目标函数相结合的。引入了目标函数的修正,训练网络最小化任意转录损失函数的期望。这允许对单词错误率进行直接优化,即使在没有词汇或语言模型的情况下也是如此。该系统在没有先验语言信息的《华尔街日报》语料库中实现了27.3%的错误率,在只使用允许单词的词典的情况下实现了21.9%的错误率,在使用trigram语言模型的情况下实现了8.2%的错误率。将网络与基线系统相结合进一步将错误率降低到6.7%。
介绍
最近在算法和计算机硬件方面的进展使得神经网络能够以一种端到端的方式来完成以前需要大量人类专门知识的任务。例如,卷积神经网络现在可以直接将原始像素分类为高级概念,如对象类别(Krizhevsky et al., 2012)和交通标志上的消息(Ciresan et al., 2011),而不需要使用手工设计的特征提取算法。这样的网络不仅比传统方法需要更少的人力,而且通常提供更好的性能。当有大量的训练数据可用时尤其如此,所有整体优化的契合度往往大于先验知识的契合度。
而自动语音识别技术的发展则得益于神经网络的引入(Bourlard 1993;Hinton et al., 2012),网络目前只是复杂管道中的单个组件。与传统的计算机视觉技术一样,输入法的第一阶段是输入特征提取:标准技术包括melscale滤波器组(Davis;Mermelstein, 1980)(是否进一步转换成倒谱系数)和说话者正常化技术,如声道长度正常化(Lee ;玫瑰,1998)。然后训练神经网络对声数据帧进行分类,将其输出分布重新表述为隐马尔可夫模型(HMM)的发射概率。因此,用于训练网络的目标函数与真正的性能度量(序列级转录准确性)有本质上的不同。这正是端到端学习试图避免的不一致性。在实践中,这让研究人员感到沮丧,他们发现帧精度的大幅提高可以转化为微不足道的提高,甚至是转录精度的下降。另外一个问题是帧级训练目标必须从HMM确定的对齐中推断出来。这就导致了一个尴尬的迭代过程,在这个过程中,网络再训练和HMM再对齐交替进行,以生成更准确的目标。利用最大互信息等全序列训练方法直接训练hmm -神经网络杂种,使正确转录的概率最大化(Bahl et al., 1986;Jaitly等,2012)。然而,这些技术只适用于对已经在框架级别上训练过的系统进行再训练,并且需要对大量的超参数进行仔细的调优,通常比深度神经网络的调优还需要调优。
用于训练语音识别系统的转录是词汇的,而目标则呈现给网络通常是语音。因此,需要一个发音字典来从单词映射到音素序列。创建这样的字典需要大量的人力,而且通常证明对整体性能至关重要。更复杂的是,由于使用多电话上下文模型来考虑协同发音效果,因此需要状态绑定来减少另一个专家知识来源的目标类的数量。对于基于hmm的识别器来说,字母和字符等词汇状态被认为是一种处理词汇外词汇(OOV)的方法(Galescu, 2003;Bisani, 2005)。然而,它们被用来增强而不是取代语音模型。
最后,将HMM生成的声学分数与基于文本语料库的语言模型相结合。一般来说,语言模型包含大量的先验信息,对性能有很大的影响。将语言与声音分开建模也许是端到端学习中最合理的背离,因为从文本中学习语言依赖比从言语中学习更容易,而且有文化的人也会这样做,这一点是有争议的。然而,随着包含数万小时标记数据的语音语料库的出现,直接从文本中学习语言模型成为可能。
本文的目标是建立一个尽可能多的语音管道被单一递归神经网络(RNN)结构所替代的系统。尽管可以直接用RNNs转录原始语音波形(Graves, 2012),也可以用受限的玻尔兹曼机器(Jaitly ;Hinton, 2011),计算成本高,性能往往不如传统的预处理。因此,我们选择光谱图作为最小预处理方案。利用深度双向LSTM网络(Graves et al., 2013)对光谱图进行处理,输出层为Connectionist Temporal Classification (CTC) output layer (Graves, 2006; Graves, 2012,第7章).该网络直接针对文本转录本进行训练:不使用语音表示(因此不使用语音词典或状态绑定)。此外,由于CTC集成了所有可能的输入输出对齐,因此不需要强制对齐来提供培训目标。双向LSTM和CTC的结合在字符级语音识别中已有应用(Eyben et al., 2009),但该工作中使用的相对较浅的架构并没有带来令人信服的结果(最佳字符错误率接近20%)。一个新的目标函数增强了基本系统,该函数训练网络直接优化单词错误率。在《华尔街日报》语音语料库上进行的实验表明,即使在没有语言模型或词典的情况下,该系统也能以合理的准确度识别单词,而且当与语言模型结合时,其性能与最先进的管道相当。
Network Architecture
给定输入序列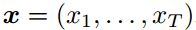 ,标准递归神经网络(RNN)计算隐藏向量序列
,标准递归神经网络(RNN)计算隐藏向量序列 ,输出向量序列
,输出向量序列 。将t = 1迭代到t,得到:
。将t = 1迭代到t,得到:
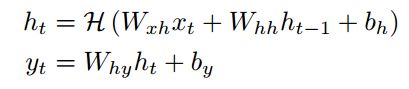
W项表示权重矩阵(如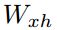 为输入隐藏权重矩阵),b项表示偏置向量,(如
为输入隐藏权重矩阵),b项表示偏置向量,(如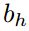 为隐藏偏置向量),
为隐藏偏置向量),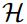 为隐藏层函数
为隐藏层函数
Long Short-Term Memory (LSTM)
![(8) [ICML14] Towards End-to-End Speech Recognition with Recurrent Neural Networks_第1张图片](http://img.e-com-net.com/image/info8/f98006ffabf9445f808c7535237ef87c.jpg)
通常是sigmoid函数的基本应用。但我们发现,Long Short-Term Memory (LSTM)架构[11]使用专门构建的内存单元memory cells来存储信息,它更善于发现和利用远程上下文。图1显示了一个LSTM内存单元。对于本文使用的LSTM版本,[14]。由以下复合函数实现:

其中σ是sigmoid函数,和我,f, o和c分别input gate, forget gate, output gate, cell activation vectors。
Bidirectional RNNs (BRNNs)
![(8) [ICML14] Towards End-to-End Speech Recognition with Recurrent Neural Networks_第2张图片](http://img.e-com-net.com/image/info8/5cb90e6fc2ab4f1b86abb324ac0f1926.jpg)
传统神经网络的一个缺点是它们只能利用以前的上下文。在语音识别中,所有的话语同时被转录,没有理由不利用未来的上下文。
双向RNNs (BRNNs) (Schuster & Paliwal, 1997)通过使用两个独立的隐藏层来处理两个方向的数据,然后将数据转发到相同的输出层。如图2所示,BRNN通过迭代后向层从t = t到1,前向层从t = 1到t,然后更新输出层来计算前向隐藏序列![]() ,后向隐藏序列
,后向隐藏序列![]() 和输出序列:
和输出序列:
![(8) [ICML14] Towards End-to-End Speech Recognition with Recurrent Neural Networks_第3张图片](http://img.e-com-net.com/image/info8/4b3114036b1342e295feedb826fb37e4.jpg)
将BRNNs与LSTM相结合,得到了双向的结果LSTM (Graves & Schmidhuber, 2005),它可以在两个输入方向上访问远程上下文。
混合系统最近成功的一个关键因素是使用了深度架构,这种架构能够逐步构建更高级别的声学数据表示。通过将多个RNN隐藏层叠加在一起,一个层的输出序列构成下一个层的输入序列,就可以创建深层RNN,如图3所示。假设使用相同的隐藏层函数,对于堆栈中的所有N层,从N = 1到N,从t = 1到,迭代计算隐藏向量序列![]() :
:
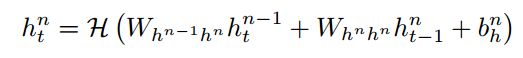
![]() 时,输出
时,输出![]() 是:
是:
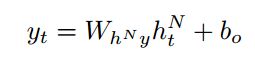
通过将每个隐藏序列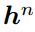 替换为正向序列和反向序列
替换为正向序列和反向序列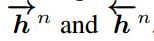 。如果将LSTM用于隐藏层,则得到了深层的双向LSTM,即本文使用的主要架构。据我们所知,这是第一次将深度LSTM应用到语音识别中,我们发现它比单层LSTM有了很大的改进。
。如果将LSTM用于隐藏层,则得到了深层的双向LSTM,即本文使用的主要架构。据我们所知,这是第一次将深度LSTM应用到语音识别中,我们发现它比单层LSTM有了很大的改进。
Connectionist Temporal Classification —— CTC
神经网络(无论是前馈还是递归)通常被训练成语音识别中的帧级分类器。这就要求每一帧都有一个单独的训练目标,这就需要HMM来确定音频和转录序列之间的对齐。然而,只有训练了分类器,对齐才可靠,这导致了分割和识别之间的循环依赖关系(在密切相关的手写识别领域被称为Sayre s paradox)。此外,对齐与大多数语音识别任务无关,只有单词级别的转录才重要。Connectionist Temporal Classification (CTC) (Graves, 2012)是一种目标函数,它允许训练RNN执行序列转录任务,而不需要输入序列和目标序列之间进行任何事先的比对。
输出层为每个转录标签(字符、音素、音符等)包含一个单元,加上一个额外的单元,称为“空白”,对应于零排放。给定长度为T的输入序列x,输出向量yt用softmax函数进行归一化,然后解释为在T时刻用索引k发出标签(或空白)的概率:

其中![]() 是yt的元素k。CTC是长度空序列和标号索引的T序列。对a的概率
是yt的元素k。CTC是长度空序列和标号索引的T序列。对a的概率![]() 是各时个步发中概率的乘积:
是各时个步发中概率的乘积:

对于一个给定的转录序列,有尽可能多的可能的排列,就像有不同的方法用空格分隔标签一样。例如(用于表示空格)对齐(a; -; b; c; -; -)
(-; -; a; -; b; c)两者都对应转换(a; b; c)。当相同的标签以一种对齐方式连续出现在时间步长上时,则删除重复:因此((a; b; b; b; c; c)
和(a; -; b; -; c; c)也对应于(a; b; c)。用B表示一个算子,先去掉重复的标签,然后去掉对齐中的空格,观察输出转换y的总概率等于对应的对齐的概率之和,我们可以写成:
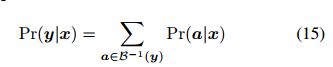
这种在可能的对齐上的集成使得网络可以使用未分割的数据进行训练。直觉告诉我们,因为我们不知道一个特定转录中的标签会在哪里出现,我们把它们可能出现的所有地方加起来。Eq.(15)可以通过动态规划算法进行有效的评估和区分(Graves et al., 2006)。给定目标转录y,就可以训练该网络使CTC的目标功能最小化:
![]()
Expected Transcription Loss
CTC目标函数使序列转录完全正确的日志概率最大化。因此,不正确转录的相对概率被忽略,这意味着它们都是同样糟糕的。然而,在大多数情况下,转录性能是通过一种更微妙的方式来评估的。例如,在语音识别中,标准度量是单词错误率(word error rate, WER),定义为真实单词序列与转录器发出的最可能单词序列之间的编辑距离。因此,我们更倾向于高应答的转录比低应答的更有可能。为了减少目标函数和测试标准之间的差距,本节提出了一种方法,允许训练RNN来优化定义在输出转录(如WER)之上的任意损失函数的期望值。网络结构和输出激活解释为在特定时间步长发出标签(或空白)的概率,与CTC相同。给定输入序列x, CTC定义的转录序列y上的Pr(yjx)分布,以及实值转录损失函数L(x;,预期转录损失L(x)定义为:

一般来说,我们无法准确地计算出这个期望,我们将使用蒙特卡罗抽样来近似L和它的梯度。将式(15)代入式(17)可得:
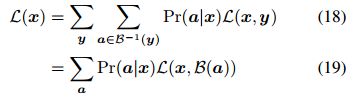
由式(14)可知,从![]() 中独立选取样本可以从
中独立选取样本可以从![]() 中提取样本;在每个时间步长,并将结果串联起来,这样就可以直接估计损失
中提取样本;在每个时间步长,并将结果串联起来,这样就可以直接估计损失
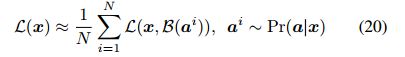
为了对L对网络输出进行微分,首先从式(13)中观察到:
![]()
从式子19应用![]() :
:
![(8) [ICML14] Towards End-to-End Speech Recognition with Recurrent Neural Networks_第4张图片](http://img.e-com-net.com/image/info8/c047f36c7df84115a6b7e20eddc1e899.jpg)
这个期望也可以近似于MonteCarlo抽样。由于输出概率是独立的,![]() 的无偏样本ai可以转化为
的无偏样本ai可以转化为![]() 的无偏样本ai;令
的无偏样本ai;令![]() ,则每一个ai都可以为每一个
,则每一个ai都可以为每一个![]() 如下:
如下:

重用对齐样本的优点(相对于为每个k选择单独t)是由于损失方差造成的噪声在很大程度上被抵消了,只有改变单个标签造成的损失的差异才被添加到梯度中。正如在梯度文献和其他地方广泛讨论的那样(Peters & Schaal)在随机梯度估计优化时,噪声的最小化是至关重要的。公关![]() 导数通过softmax函数得到:
导数通过softmax函数得到:
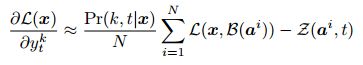

因此,给定![]() 对
对![]() 的导数等于
的导数等于![]() 时的损失与
时的损失与![]() 。这意味着网络只接收一个错误项,用于更改更改损失的对齐方式。例如,如果损失函数是词错误率和采样校准收益率字符转录WTRD错误率梯度将鼓励输出改变第二个输出标签啊,抑制输出更改其他两个单词和其他地方接近零。为了使抽样过程有效,必须有一个合理的概率来选择其变体受到不同损失的对齐。从随机初始化的网络中提取的绝大多数比对结果将给出完全错误的转录,因此通过修改单个输出来改变损失的可能性很小。因此,我们建议使用期望损失最小化来重新培训已经使用CTC进行培训的网络,而不是从一开始就应用它。采样校准很便宜,因此在这个过程中唯一重要的计算成本是重新计算校准变量的损失。然而,对于许多丢失函数(包括字错误率),只需重新计算与对齐更改相对应的那部分丢失,就可以对其进行优化。在我们的实验中,每个序列的5个样本给出了足够低的方差梯度估计值来进行有效的训练。注意,为了计算单词错误率,必须使用一个endof-word标签作为分隔符。
。这意味着网络只接收一个错误项,用于更改更改损失的对齐方式。例如,如果损失函数是词错误率和采样校准收益率字符转录WTRD错误率梯度将鼓励输出改变第二个输出标签啊,抑制输出更改其他两个单词和其他地方接近零。为了使抽样过程有效,必须有一个合理的概率来选择其变体受到不同损失的对齐。从随机初始化的网络中提取的绝大多数比对结果将给出完全错误的转录,因此通过修改单个输出来改变损失的可能性很小。因此,我们建议使用期望损失最小化来重新培训已经使用CTC进行培训的网络,而不是从一开始就应用它。采样校准很便宜,因此在这个过程中唯一重要的计算成本是重新计算校准变量的损失。然而,对于许多丢失函数(包括字错误率),只需重新计算与对齐更改相对应的那部分丢失,就可以对其进行优化。在我们的实验中,每个序列的5个样本给出了足够低的方差梯度估计值来进行有效的训练。注意,为了计算单词错误率,必须使用一个endof-word标签作为分隔符。
Decoding
解码一个CTC网络(即为给定输入序列x找到最可能的输出转录y,可以通过在每个时间步上选取单个最可能的输出。并返回相应的转录来进行第一次近似:
![]()
使用beam search算法可以实现更精确的解码,这也使得集成语言模型成为可能。该算法类似于基于hmm系统的解码方法,但由于对网络输出的解释发生了变化,因此略有不同。在混合系统中,网络输出被解释为状态占用的后验概率,然后与语言模型和HMM提供的转换概率相结合。对于CTC,网络输出本身表示转换概率(在HMM中,标签激活是转换到不同状态的概率,空白激活是保持当前状态的概率)。在连续的时间步上去除重复的标签排放使情况更加复杂,这就需要区分以空白结束的对齐和以标签结束的对齐。
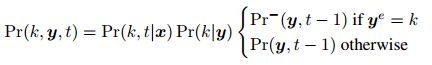
![(8) [ICML14] Towards End-to-End Speech Recognition with Recurrent Neural Networks_第5张图片](http://img.e-com-net.com/image/info8/7f8c039dae884869a4d3366c72fad19e.jpg)
要将单词级语言模型转换为标签级语言模型,首先要注意,任何标签序列y都可以表示为连接y = (w + p),其中w是y中字典单词最长的完整序列,p是剩下的单词前缀。w和p可能都是空的。然后我们可以写:
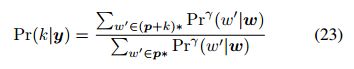
Experiments
在81小时的训练集中,字母组合、双字母组合和三字母组合的错误率分别为8.9%、2%和1.4%,而反字母组合(排名300)的错误率分别为45.5%和33%。使用更大的N-best列表(最多N=1000)并没有产生显著的性能改进,从中我们得出结论,该列表足够大,可以近似于RNN的真正解码性能。另外还进行了一项实验,以测量RNN和DNN相结合的效果。将81小时组rn - wer训练后的候选分数与DNN声学模型分数进行混合,并对候选进行重新排序。语言模型权值为11,RNN评分权值为1,DNN权值为1,获得最佳结果。表1中的结果表明,在完全训练集上,当没有语言模型时,字符级别RNN的性能优于基线模型。RNN经过重新训练以最小化单词错误率(标记为RNN- wer以将其与原始的RNN- ctc网络区分开来),在这种情况下表现得尤为出色。这可能是由于两个因素:首先,RNN能够学习更强大的声学模型,因为它可以访问更多的声学上下文;其次,从训练文本中学习隐式语言模型。然而,基线系统在LM增强时超过了RNN:在这种情况下,RNN s隐式LM可能通过干扰显式模型来对抗基线系统。尽管如此,考虑到如此多的先验信息(音频预处理、发音字典、状态、强制对齐)被编码到基线系统中,差异还是很小。不出意料的是,随着LM变得更占优势,RNN-CTC和RNN-WER之间的差距也缩小了。基线系统仅从14小时的训练集逐步改进到81小时的训练集,而RNN错误率则大幅下降。一种可能的解释是,14个小时的转录语音不足以让RNN学会如何拼写足够的单词来进行准确的转录,而足以学会识别音素。组合模型的性能比单独的RNN或基线要好得多。在基线上超过1%的绝对改善远远大于模型平均通常所看到的微小改善;这可能是由于两种系统之间存在较大的差异。
![(8) [ICML14] Towards End-to-End Speech Recognition with Recurrent Neural Networks_第6张图片](http://img.e-com-net.com/image/info8/89792b5a91db4e5bb35f7079f0d060fd.jpg)
![(8) [ICML14] Towards End-to-End Speech Recognition with Recurrent Neural Networks_第7张图片](http://img.e-com-net.com/image/info8/708ed437f7334bb28747164d9dd314ec.jpg)