毕业设计记录-Pytorch学习-隐藏层特征查看与类激活热力图
文章目录
-
- 2021.12.8的记录
- 2021.12.9的记录
- 2021.12.10的记录
代码文件路径:E:\sotsugyosextsukei\VGG16\featuresvision.py
书本 P167-176
2021.12.8的记录
先看一下效果,我的可莉。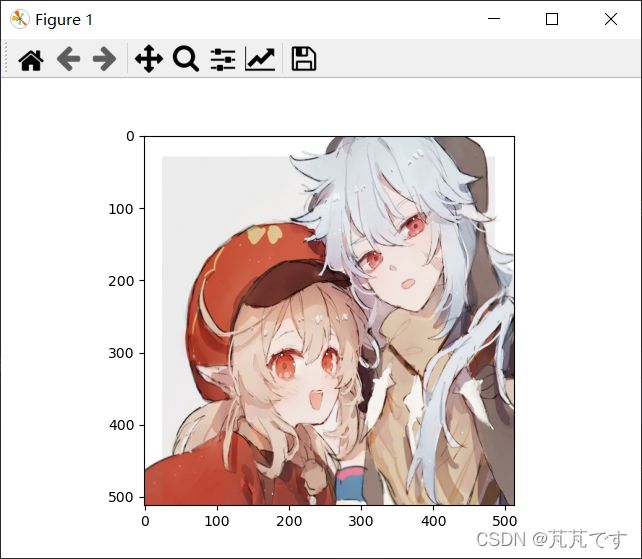

 python的钩子技术,不懂,记下了。
python的钩子技术,不懂,记下了。
需要再理解神经网络的特征提取原理和工作机制,记下了。
2021.12.9的记录
可视化代码:
activation = {}
def get_activation(name):
def hook(model, input, output):
activation[name] = output.detach()
return hook
vgg16.eval()
vgg16.features[4].register_forward_hook(get_activation("maxpool1"))
_ = vgg16(input_im)
maxpool1 = activation["maxpool1"]
print("获得特征的尺寸为:", maxpool1.shape)
plt.figure(figsize=(11, 6))
for ii in range(maxpool1.shape[1]):
plt.subplot(6, 11, ii+1)
plt.imshow(maxpool1.data.numpy()[0, ii, :, :], cmap="gray")
plt.axis("off")
plt.subplots_adjust(wspace=0.1, hspace=0.1)
plt.show()
首先定义了一个字典。关于字典:字典是一种可变容器模型,且可存储任意类型对象。
然后get_activation(name)函数中的hook函数了。
首先了解一下什么是回调函数:添加链接描述
钩子技术代码:修改自添加链接描述
import time
class LazyPerson(object):
def __init__(self, name):
self.name = name
self.watch_tv_func = None
self.have_dinner_func = None
def get_up(self):
print("%s get up at:%s" % (self.name, time.time()))
def go_to_sleep(self):
print("%s go to sleep at:%s" % (self.name, time.time()))
def register_tv_hook(self, watch_tv_func):
self.watch_tv_func = watch_tv_func
def register_dinner_hook(self, have_dinner_func):
self.have_dinner_func = have_dinner_func
def enjoy_a_lazy_day(self):
# get up
self.get_up()
time.sleep(3)
# watch tv
# check the watch_tv_func(hooked or unhooked)
# hooked
if self.watch_tv_func is not None:
self.watch_tv_func(self.name)
# unhooked
else:
print("no tv to watch")
time.sleep(3)
# have dinner
# check the have_dinner_func(hooked or unhooked)
# hooked
if self.have_dinner_func is not None:
self.have_dinner_func(self.name)
# unhooked
else:
print("nothing to eat at dinner")
time.sleep(3)
self.go_to_sleep()
def watch_daydayup(name):
print("%s : The program ---day day up--- is funny!!!" % name)
def watch_happyfamily(name):
print("%s : The program ---happy family--- is boring!!!" % name)
def eat_meat(name):
print("%s : The meat is nice!!!" % name)
def eat_hamburger(name):
print("%s : The hamburger is not so bad!!!" % name)
if __name__ == "__main__":
lazy_tom = LazyPerson("Tom")
lazy_tom.register_tv_hook(watch_daydayup)
lazy_tom.register_dinner_hook(eat_meat)
lazy_tom.enjoy_a_lazy_day()
个人理解:钩子技术貌似就是函数调用函数。为什么叫钩子呢。我的理解是他的父级的输入并没有什么限制,可以挂载任何函数,你想用啥函数的时候就钩上去。但我总感觉还是不能用这个来说服自己,什么是钩子技术。希望有高人指点。
好了再看一下这个函数,参考链接:添加链接描述
.register_forward_hook(hook)
这里要输入的参数是一个固定格式的hook函数
hook(module, input, output) -> None or modified output
hook可以修改input和output,但是不会影响forward的结果。最常用的场景是需要提取模型的某一层(不是最后一层)的输出特征,但又不希望修改其原有的模型定义文件,这时就可以利用forward_hook函数。
其中hook的内容是可以自己写的,像上文程序中利用字典获取也行,像链接文章中用列表也行。
activation[name] = output.detach()
先看一下百度百科的解释吧:
神经网络的训练有时候可能希望保持一部分的网络参数不变,只对其中一部分的参数进行调整;或者值训练部分分支网络,并不让其梯度对主网络的梯度造成影响,torch.tensor.detach()和torch.tensor.detach_()函数来切断一些分支的反向传播。本文会具体介绍这两种方法的用法和区别。
也就是说这个.detach()去掉也是没有任何问题的,并不会对output有什么改变。但是在反向传播到这一层的时候会停止更新权重。由于这里也没有进行反向传播,去掉也是没有问题的。测试一下也的确如此。
下午去办身份证遇到一个老奶奶,说卡没了没吃午饭,问我要几块钱。我没理就走了。后来想想,估计是地铁卡丢了,要几块钱坐地铁回家吧。不像是骗子,唉,想想老奶奶当时的表情心里挺不是滋味。
解释一下.register_hook()函数,是对梯度进行各种操作,需要注意的是传入的参数必须是一个函数,然后传入的函数测试下来,只能有一个参数,不然会报错。如下代码
import torch
v = torch.randn((1, 3), dtype=torch.float32, requires_grad=True)
z = v.sum()
zi = {}
def a(m):
zi["grad"] = m
def b(m):
zi["g"] = m * 2
v.register_hook(a)
v.register_hook(b)
z.backward()
print(v.grad)
print(zi["grad"])
print(zi)
输出为
tensor([[1., 1., 1.]])
tensor([[1., 1., 1.]])
{'grad': tensor([[1., 1., 1.]]), 'g': tensor([[2., 2., 2.]])}
函数a就是将梯度直接传给字典中的“grad”,而b是将梯度乘2传给“g”。至于register_hook()是怎么传的,猜测也是和上文的name一样,把梯度作为类中的一个变量传给了a或b函数中的m。
最后的类激活热力图输出
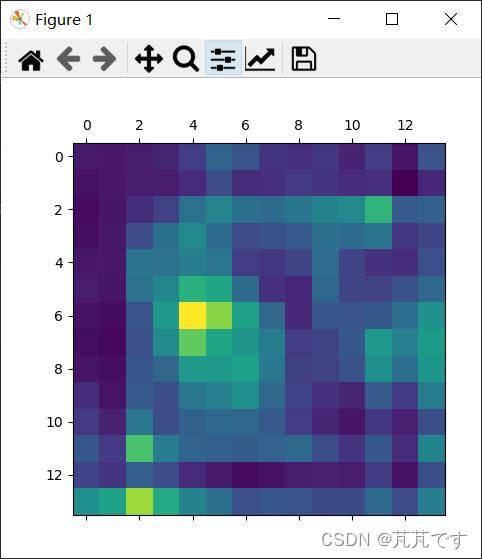
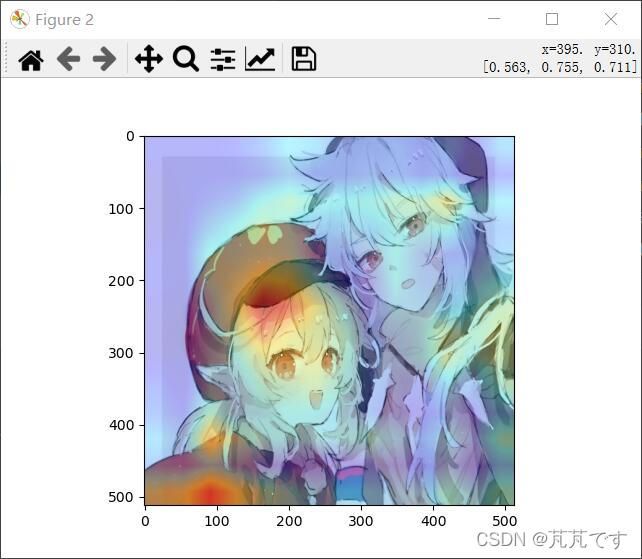 真好看。
真好看。
代码部分缺少理论知识的辅助,暂时无法知道所有在干嘛,只能理解部分。明天再看看吧。
2021.12.10的记录
先贴上参考的网址:
凭什么相信你,我的CNN模型?关于CNN模型可解释性的思考
知乎大神的链接
文章中主要介绍了CAM和Grad-CAM。
CAM:用GAP代替了整个FC层。GAP:特殊的平均池化,size和最后一层卷积输出得到的特征图size一样,也就是求整张图的平均值。随后会将得到的向量与一个同样维度的权重向量进行点乘,会得到一个标量,再将这个标量放入Sigmoid 函数中得到一个0到1的数。过程如下图:
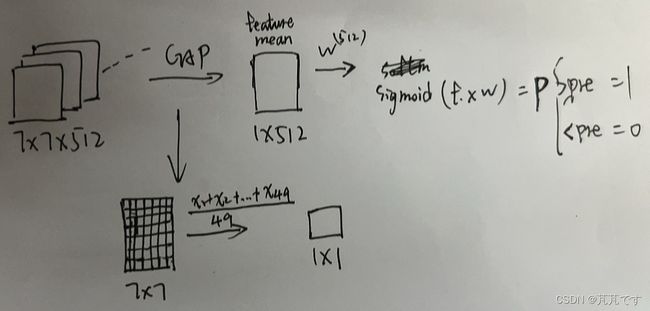
将特征图和权重对应相乘求和即可得到热力图。
CAM有个缺点就是会改变网络结构,遇到新的对象就要重新训练。
Grad-CAM:与CAM不同的是不会改变网络的结构,用梯度的全局平均来计算权重。
算得权重后,将权重和特征图进行加权求和,要注意的是,求和之后还要再加一个relu函数就可以得到热力图。(加relu的理由见第一个链接)
代码:
vggcam = MyVgg16()
vggcam.eval()
im_pre = vggcam(input_im)
softmax = nn.Softmax(dim=1)
im_pre_prob = softmax(im_pre)
# im_pre_prob.shape = 1*1000
print("im_pre_prob.shape:", im_pre_prob.shape)
"""
topk()方法用于返回输入数据中特定维度上的前k个最大的元素和索引,又大往小排
x = torch.arange(1., 6.)
pre, prelab = torch.topk(x, 3)
print(x)
print(pre, prelab)
out:
tensor([1., 2., 3., 4., 5.])
tensor([5., 4., 3.]) tensor([4, 3, 2])
"""
prob, prelab = torch.topk(im_pre_prob, 5)
print(prob, prelab)
print("prob1.shape:", prob.shape)
print("prelab1.shape:", prelab.shape)
# .flatten()返回一个一维数组
prob = prob.data.numpy().flatten() # 这里的作用是降维
prelab = prelab.numpy().flatten() # 这里的作用是降维
print(prob, prelab)
print("prob2.shape:", prob.shape)
print("prelab2.shape:", prelab.shape)
# 反向传播链式求导
im_pre[:, prelab[0]].backward()
"""
这里并没有对所有1000个激活值都进行求导,而是':, prelab[0]'。
把prelab[0]改成999也是可以的,而且也更符合Grad-CAM的算法。
"""
# 获得模型的梯度
gradients = vggcam.get_activations_gradient() # gradients.shape = torch.Size([1, 512, 14, 14])
# 计算梯度相应通道的均值
mean_gradients = torch.mean(gradients, dim=[0, 2, 3]) # mean_gradients.shape = torch.Size([512])
"""
# 注意:这里的gradients求完平均之后维度发生了改变。
# mean_gradients也就是Grad-CAM中的权重了。
"""
# 获得图像在相应卷积层输出的卷积特征
activations = vggcam.get_activations(input_im).detach() # activations.shape = torch.Size([1, 512, 14, 14])
# 每个通道乘以相应的梯度均值,对应Grad-CAM中的相乘求和。Σ(weight*feature)
for i in range(len(mean_gradients)):
activations[:, i, :, :] *= mean_gradients[i]
# 计算所有通道的均值输出得到热力图
heatmap = torch.mean(activations, dim=1).squeeze() # heatmap.shape = torch.Size([14, 14])
"""
这里的操作相当于将512张特征图分别乘以对应的权重然后加起来做了个平均
最后得到了一张图。
Grad-CAM中的说法虽然是512(这里有512)处理后的图进行叠加,但在程序中,
你不可能把512张图的像素点都加起来就完事了,我们的像素点的范围是0-255,
所以要做个平均。当然也可以用其他的方法,但平均可以很好保存512张图的综合特征?
维度变化:
activations(1, 512, 14, 14)求平均值后activations(1, 512, 14, 14),
.squeeze()之后heatmap(14, 14)
"""
# 使用relu函数作用于热力图
heatmap = F.relu(heatmap)
# 对热力图进行标准化
heatmap /= torch.max(heatmap)
heatmap = heatmap.numpy()
# 可视化热力图
plt.matshow(heatmap)
打印输出
im_pre_prob.shape: torch.Size([1, 1000])
tensor([[8.7331e-01, 1.1931e-01, 7.2762e-03, 9.7360e-05, 1.7178e-06]],
grad_fn=<TopkBackward0>) tensor([[386, 101, 385, 51, 48]])
prob1.shape: torch.Size([1, 5])
prelab1.shape: torch.Size([1, 5])
[8.7330627e-01 1.1931463e-01 7.2761849e-03 9.7359698e-05 1.7177526e-06] [386 101 385 51 48]
prob2.shape: (5,)
prelab2.shape: (5,)
将热力图和原图叠加
代码:
img = cv2.imread(imgdir)
heatmap = cv2.resize(heatmap, (img.shape[1], img.shape[0]))
heatmap = np.uint8(255 * heatmap)
heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)
Grad_cam_img = heatmap * 0.4 + img
Grad_cam_img = Grad_cam_img / Grad_cam_img.max()
b, g, r = cv2.split(Grad_cam_img)
Grad_cam_img = cv2.merge([r, g, b])
plt.figure()
plt.imshow(Grad_cam_img)
plt.show()

 看来网络更关注大象的牙齿和脸部。ok,类热力图部分就此完结。虽然还只是皮毛,网上还有大佬做过动态显示,我以后应该也可以的吧。
看来网络更关注大象的牙齿和脸部。ok,类热力图部分就此完结。虽然还只是皮毛,网上还有大佬做过动态显示,我以后应该也可以的吧。