Python超快速入门基础知识——Python的内置数据结构: 字符串、数组、列表、元组、集合、字典
文章目录
-
-
-
- Python内置的数据类型简介
- 1. 字符串str
- 2. 列表List
- 3. 元组tuple(戴了紧箍咒的列表, 不能修改元素)
- 4. 集合set(无序,不重复)
- 5. 字典 dict 的操作
-
-
Python内置的数据类型简介
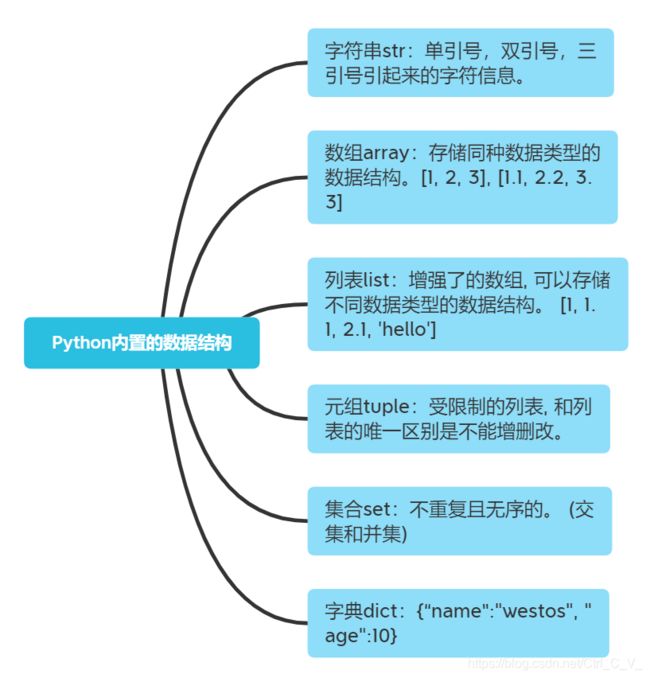
- 可变数据类型: list, set, dict
- 不可变数据类型: 数值类型,tuple, str
1. 字符串str
<创建>
- 单引号引起来:
name = 'westos' - 双引号引起来:
name = "westos" - 三引号引起来: 三引号代表字符串, 也可以作为代码的块注释
<基本特性>
- 连接(+)重复(*)
name = 'westos'
print('hello ' + name)
# 1元 + 1分 = 1元 + 0.01元 = 1.01元
print('hello' + str(1))
print("*" * 30 + '学生管理系统' + '*' * 30)
- 成员(in, not in)
s = 'hello westos'
print('westos' in s) # True
print('westos' not in s) # False
print('x' in s) # False
- 索引: 正向索引和反向索引
s = 'WESTOS'
print(s[0]) # 'W'
print(s[3]) # 'T'
print(s[-3]) # 'T'
- 切片:s[start : end : step]
s = '012345'
print(s[:3]) # s[:n]获取前n个字符
print(s[2:]) # s[n:]获取除了前n个字符的字符串信息
print(s[::-1]) # 字符串倒序
- for循环访问
s = 'westos'
count = 0
for item in s:
count += 1
print(f"第{count}个字符:{item}")
判断回文字符串
s = input('输入字符串:')
result = "回文字符串" if s == s[::-1] else "不是回文字符串"
print(s + "是" + result)
<常用方法>
- 判断类型(isdigit, isupper, islower, isalpha, isalnum)
- 转换类型:(lower, upper, title)
- 开头和结尾的判断(startswith, endswith)
- 数据清洗(strip, lstrip, rstrip, replace)
- 分割和拼接(split,
'172.25.254.100'.split("."), join) - 位置调整(center)
1.类型判断
s = 'HelloWESTOS'
print(s.isalnum()) # True
print(s.isdigit()) # Flase
print(s.isupper()) # False
2.类型的转换
print('hello'.upper()) # HELLO
print('HellO'.lower()) # hello
print('HellO WOrld'.title()) # Hello World
print('HellO WOrld'.capitalize()) # Hello world
print('HellO WOrld'.swapcase()) # hELLo woRLD
# 需求: 用户输入Y或者y都继续继续代码
# yum install httpd
choice = input('是否继续安装程序(y|Y):')
if choice.lower() == 'y':
print("正在安装程序......")
3.字符串开头和结尾的判断
<开头判断>
# startswith
url = 'http://www.baidu.com'
if url.startswith('http'):
# 具体实现爬虫,感兴趣的话可以看request模块。
print(f'{url}是一个正确的网址,可以爬取网站的代码')
<结尾判断>
# endswith:
# 常用的场景: 判断文件的类型
filename = 'hello.png'
if filename.endswith('.png'):
print(f'{filename} 是图片文件')
elif filename.endswith('mp3'):
print(f'{filename}是音乐文件')
else:
print(f'{filename}是未知文件')
4.字符串的数据清洗
"""
数据清洗的思路:
lstrip: 删除字符串左边的空格(指广义的空格: \n, \t, ' ')
rstrip: 删除字符串右边的空格(指广义的空格: \n, \t, ' ')
strip: 删除字符串左边和右边的空格(指广义的空格: \n, \t, ' ')
replace: 替换函数, 删除中间的空格, 将空格替换为空。replace(" ", )
"""
print(" hello ".strip()) # 'hello'
print(" hello ".lstrip()) # 'hello '
print(" hello ".rstrip()) # ' hello'
print(" hel lo ".replace(" ", "")) # 'hello'
5.字符串的位置调整
# 中间对齐,一共10个字符,可指定字符补齐
print("学生管理系统".center(10)) # ' 学生管理系统 '
print("学生管理系统".center(10, "*")) # '**学生管理系统**'
print("学生管理系统".center(10, "-")) # '--学生管理系统--'
# 左对齐,右对齐
print("学生管理系统".ljust(10, "-")) # '学生管理系统----'
print("学生管理系统".rjust(10, "-")) # '----学生管理系统'
6.字符串的搜索和统计
s = "hello westos"
print(s.find("llo")) # 2
print(s.index("llo")) # 2
print(s.find("xxx")) # -1
print(s.index("xxx"))
报错:Traceback (most recent call last):
File "D:\Python Learning\day02\07_字符串的搜索和统计.py", line 6, in <module>
print(s.index("xxx"))
ValueError: substring not found
# find如果找到子串, 则返回子串开始的索引位置。 否则返回-1
# index如果找到子串,则返回子串开始的索引位置。否则报错(抛出异常).
print(s.count("xxx")) # 0
print(s.count("l")) # 2
print(s.count("o")) # 2
7.字符串的分离和拼接
ip = "172.25.254.100"
# 需求:IP地址的合法性-将ip的每一位数字拿出,判断每位数字是否在0-255之间。
print(ip.split('.')) # 将数字按'.'分开取出, '['172', '25', '254', '100']'
items = ip.split('.')
print(items)
# 拼接
# 需求: 将四个数字用'-'拼接起来
print("-".join(items)) # 用'-'连接数字, '172-25-254-100'
<实例>
# 需求: 生成100个验证码, 每个验证码由2个数字和2个字母组成。
import random
import string # 导入字符串模块
# print(string.digits)
# '0123456789'
# print(string.ascii_letters)
# 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
for i in range(100):
print("".join(random.sample(string.digits, 2)) + "".join(random.sample(string.ascii_letters, 4)))
"""
设计一个程序,用来实现帮助小学生进行算术运算练习,
它具有以下功能:
提供基本算术运算(加减乘)的题目,每道题中的操作数是随机产生的,
练习者根据显示的题目输入自己的答案,程序自动判断输入的答案是否正确
并显示出相应的信息。最后显示正确率。
1+2=?
3*6=?
"""
import random
count = 10
right_count = 0
for i in range(count):
num1 = random.randint(1, 10)
num2 = random.randint(1, 10)
symbol = random.choice(["+", "-", "*"])
result = eval(f"{num1}{symbol}{num2}")
question = f"{num1} {symbol} {num2} = ?"
print(question)
user_answer = int(input("Answer:"))
if user_answer == result:
print("Right")
right_count += 1
else:
print("Error")
print("Right percent: %.2f%%" %(right_count/count*100))
2. 列表List
<创建>
li1 = [1, 2, 3, 4]
print(li1, type(li1))
li2 = [1, 2.4, True, 2e+5, [1, 2, 3]]
print(li2, type(li2))
<基本特性>
1.连接操作符和重复操作符
print([1, 2] + [2, 3]) # [1, 2, 2, 3]
print([1, 2] * 3) # [1, 2, 1, 2, 1, 2]
2.成员操作符(in, not in)
print(1 in [1, 2, 3]) # True
"""
布尔类型:
True: 1
False:0
"""
print(1 in ["a", False, [1, 2]]) # False
3.索引
li = [1, 2, 3, [1, 'b', 3]]
print(li[0]) # 1
print(li[-1]) # [1, 'b', 3]
print(li[-1][0]) # 1
print(li[3][-1]) # 3
4.切片
li = ['172', '25', '254', '100']
print(li[:2])
print(li[1:])
print(li[::-1])
#需求: 已知['172', '25', '254', '100'], 输出: "100-254-25"
li = ['172', '25', '254', '100']
print("-".join(li[1:][::-1]))
5.for循环
names = ["粉丝", '粉条', '粉带']
for name in names:
print(f"西部开源猫大佬的姓名是:{name}")
<常用方法>
1.增加
1-1). 追加
li = [1, 2, 3]
li.append(4)
print(li) # [1, 2, 3, 4]
1-2). 在列表开头添加
li = [1, 2, 3]
li.insert(0, 'cat')
print(li) # ['cat', 1, 2, 3]
在索引2前面添加元素cat
li = [1, 2, 3]
li.insert(2, 'cat')
print(li) # [1, 2, 'cat', 3]
1-3). 一次追加多个元素
li = [1, 2, 3] # 添加4, 5, 6
li.extend([4, 5, 6])
print(li) # [1, 2, 3, 4, 5, 6]
2.修改: 通过索引和切片重新赋值的方式。
li = [1, 2, 3]
li[0] = 'cat'
li[-1] = 'westos'
print(li) # ['cat', 2, 'westos']
li = [1, 2, 3]
li[:2] = ['cat', 'westos']
print(li) # ['cat', 'westos', 3]
3.查看: 通过索引和切片查看元素。 查看索引值和出现次数。
li = [1, 2, 3, 1, 1, 3]
print(li.count(1)) # 3
print(li.index(3)) # 2
4.删除
4-1). 根据索引删除
li = [1, 2, 3]
#将pop方法的结果存储到delete_num变量中。
delete_num = li.pop(-1)
print(li) # [1, 2]
print("删除的元素是:", delete_num) # 删除的元素是: 3
4-2). 根据value值删除
li = [1, 2, 3]
li.remove(1)
print(li) # [2, 3]
4-3). 全部清空
li = [1, 2, 3]
li.clear()
print(li) # []
5.其他操作
li = [18, 6, 99, 56]
li.reverse() # 类似于li[::-1]
print(li) # [56, 99, 6, 18]
#sort排序默认由小到大。 如果想由大到小排序,设置reverse=True
li.sort(reverse=True)
print(li) # [99, 56, 18, 6]
li1 = li.copy()
print(id(li), id(li1)) # 2208521303104 2208521297856
print(li, li1) # [99, 56, 18, 6] [99, 56, 18, 6]
3. 元组tuple(戴了紧箍咒的列表, 不能修改元素)
1.元组的创建
t1 = () # 空元组
print(t1, type(t1))
t2 = (1,) # 重要(易错点):元组只有一个元素时一定要加逗号
print(t2, type(t2))
t3 = (1, 1.2, True, [1, 2, 3])
print(t3, type(t3))
2.特性
print((1, 2, 3) + (3,))
print((1, 2, 3) * 2)
print(1 in (1, 2, 3))
t = (1, 2, 3)
print(t[0])
print(t[-1])
print(t[:2])
print(t[1:])
print(t[::-1])
3.常用方法: 元组是不可变数据类型(不能增删改)
# 查看: 通过索引和切片查看元素。 查看索引值和出现次数。
t = (1, 2, 3, 1, 1, 3)
print(t.count(1)) # 3
print(t.index(3)) # 2
命名元组的操作:
tuple = ("westos", 18, "西安")
print(tuple[0], tuple[1], tuple[2])
# 从collections模块中导入namedtuple工具。
from collections import namedtuple
# 1. 创建命名元组对象User
User = namedtuple('User', ('name', 'age', 'city'))
# 2. 给命名元组传值
user1 = User("westos", 18, "西安")
# 3. 打印命名元组
print(user1)
# 4. 获取命名元组指定的信息
print(user1.name)
print(user1.age)
print(user1.city)
is和==的区别:
"""
python语言:
==: 类型和值是否相等
is: 类型和值是否相等, 内存地址是否相等
"""
print(1 == '1') # False
li = [1, 2, 3]
li1 = li.copy()
print(li == li1) # True
# 查看内存地址
print(id(li), id(li1))
print(li is li1) # False
<实例>
"""
编写一个云主机管理系统:
- 添加云主机(IP, hostname,IDC)
- 搜索云主机(顺序查找)
- 删除云主机
- 查看所有的云主机信息
"""
from collections import namedtuple
menu = """
云主机管理系统
1). 添加云主机
2). 搜索云主机(IP搜索)
3). 删除云主机
4). 云主机列表
5). 退出系统
请输入你的选择: """
# 思考1. 所有的云主机信息如何存储?选择哪种数据类型存储呢? 选择列表
# 思考2: 每个云主机信息该如何存储?IP, hostname,IDC 选择命名元组
hosts = []
Host = namedtuple('Host', ('ip', 'hostname', 'idc'))
while True:
choice = input(menu)
if choice == '1':
print('添加云主机'.center(50, '*'))
ip = input("ip:")
hostname = input("hostname:")
idc = input('idc(eg:ali,huawei..):')
host1 = Host(ip, hostname, idc)
hosts.append(host1)
print(f"添加{idc}的云主机成功.IP地址为{ip}")
elif choice == '2':
print('搜索云主机'.center(50, '*'))
# 今天的作业: for循环(for...else),判断, break
elif choice == '3':
print('删除云主机'.center(50, '*'))
# 今天的作业:(选做)
elif choice == '4':
print('云主机列表'.center(50, '*'))
print("IP\t\t\thostname\tidc")
count = 0
for host in hosts:
count += 1
print(f'{host.ip}\t{host.hostname}\t{host.idc}')
print('云主机总个数为', count)
elif choice == '5':
print("系统正在退出,欢迎下次使用......")
exit()
else:
print("请输入正确的选项")
地址引用和深浅拷贝
1.值的引用
n1 = [1, 2, 3]
n2 = n1
n1.append(4)
print(n2) # 1, 2, 3, 4
2.拷贝:浅拷贝和深拷贝
2-1). 浅拷贝
n1 = [1, 2, 3]
n2 = n1.copy() # n1.copy和n1[:]都可以实现拷贝。
print(id(n1), id(n2))
n1.append(4)
print(n2)
2-2). 为什么需要深拷贝?
# 如果列表的元素包含可变数据类型, 一定要使用深拷贝。
"""
可变数据类型(可增删改的): list
不可变数据类型:数值,str, tuple, namedtuple
"""
n1 = [1, 2, [1, 2]]
n2 = n1.copy()
# n1和 n2的内存地址:的确拷贝了
print(id(n1), id(n2))
# n1[-1]和 n2[-1]的内存地址:
print(id(n1[-1]), id(n2[-1]))
n1[-1].append(4) # n1 = [1, 2, [1, 2, 4]]
print(n2)
深拷贝和浅拷贝最根本的区别在于是否真正获取一个对象的复制实体,而不是引用。
假设B复制了A,修改A的时候,看B是否发生变化:
如果B跟着也变了,说明是浅拷贝,拿人手短!(修改堆内存中的同一个值)
如果B没有改变,说明是深拷贝,自食其力!(修改堆内存中的不同的值)
2-3). 如何让实现深拷贝? copy.depcopy
import copy
n1 = [1, 2, [1, 2]]
n2 = copy.deepcopy(n1)
# n1和n2的内存地址:的确拷贝了
print(id(n1), id(n2))
# n1[-1]和n2[-1]的内存地址:
print(id(n1[-1]), id(n2[-1]))
n1[-1].append(4) # n1 = [1, 2, [1, 2, 4]]
print(n2)
4. 集合set(无序,不重复)
1.集合的创建
s = {1, 2, 3, 1, 2, 3} # {1, 2, 3}
print(s, type(s))
# 注意点1: 集合的元素必须时不可变数据类型。
# s = {1, 2, 3, [1, 2, 3]}
# print(s, type(s))
# 注意点2:空集合不能使用{}, 而要使用set()
# s = {}
# print(s, type(s))
s = set()
print(s, type(s))
2.集合的特性:
# 不支持+,*, index, slice(因为集合无序不重复的)
# 支持in和not in
print(1 in {1, 2, 3, 4})
3.集合的常用操作
3-1). 增加
# add: 添加单个元素
# update: 添加多个元素
s = {1, 2, 3}
s.add(100)
print(s)
s = {1, 2, 3}
s.update({4, 5, 6})
print(s)
3-2). 删除
# remove: 如果元素存在,删除,否则报错
# discard: 如果元素存在,删除,否则do nothing
# pop: 随机
# 删除元素,集合为空则报错
s = {1, 2, 3}
s.remove(3)
print(s)
s = {1, 2, 3}
s.discard(100)
print(s)
s = {1, 66, 2,99, 78, 3}
s.pop()
print(s)
3-3). 查看
# 差集: s1 - s2
# 交集: s1 & s2
# 对称差分: s1 ^ s2
# 并集: s1 | s2
s1 = {1, 2, 3}
s2 = {1, 2}
print(s1 - s2) # {3}
print(s1 & s2) # {1, 2}
s1 = {1, 2, 3}
s2 = {1, 2, 4}
print(s1 ^ s2) # {3, 4}, {1, 2, 3, 4} - {1, 2} = {3,4}
print(s1 | s2) # {1, 2, 3, 4}
print(s1.issubset(s2)) # False
print(s1.isdisjoint(s2)) # False
4.拓展: frozenset不可变的集合
s = frozenset({1, 2, 3})
print(s, type(s))
词频统计
"""
技能需求:
1. 文件操作
2. 字符串的分割操作
3. 字典操作
功能需求:词频统计
1. 读取song.txt文件 with open(filename) as f: content=f.read()
2. 分析文件中的每一个单词,统计每个单词出现的次数。{"hello":2, "python":1, "java":1}
- 分析文件中的每一个单词
content = "hello python hello java"
words = content.split()
- 统计每个单词出现的次数- {"hello":2, "python":1, "java":1}
# words = ['hello', 'python', 'hello', 'java']
"""
# with open('doc/song.txt') as f:
# words = f.read().split()
# from collections import Counter
# counter = Counter(words)
# result = counter.most_common(5)
# print(result)
nums = (i ** 2 for i in range(1, 3))
print(next(nums))
生成随机数并排倒序
import random
n = int(input("输入n:"))
s = set()
for i in range(n):
s.add(random.randint(1, 1000))
print(sorted(s, reverse=True))
5. 字典 dict 的操作
1.字典的创建dict
# key-value对或者键值对
d = {"name": "westos", "age": 18, "city": "西安"}
print(d, type(d))
d = {}
print(d, type(d))
2.字典的特性
# 不支持+,*, index, slice(因为集合无序不重复的)
# 支持in和not in
d = {"name": "westos", "age": 18, "city": "西安"}
print('name' in d) # True, 判断是否为所有key值得成员
print("westos" in d) # False
3.字典的常用方法
3-1). 查看
"""
查看所有: keys, values, items
查看局部: d[key], d.get(key), d.get(key, default-value)
"""
d = {"name": "westos", "age": 18, "city": "西安"}
print(d.keys()) # 查看字典所有的key值
print(d.values()) # 查看字典所有的value值
print(d.items()) # 查看字典所有的key-value值(item元素)
print(d['name']) # 查看key为name对应的value值
# print(d['province']) # 查看key对应的vlaue值,如果不存在会报错。
print(d.get('province')) # 查看key对应的vlaue值, 如果存在则返回,如果不在在则返回None.
print(d.get('province', "陕西")) # 查看key对应的vlaue值, 如果存在则返回,如果不在在则返回默认值.
3-2). 增加和修改
d = {"name": "westos", "age": 18}
d['city'] = "西安" # key不存在就添加
print(d)
d['city'] = "北京" # key存在则修改value值
print(d)
d = {"name": "westos", "age": 18}
d.setdefault('city', "西安") # key不存在就添加
print(d)
d.setdefault('city', "北京") # key存在,则do nothing
print(d)
3-3). 删除
d = {"name": "westos", "age": 18}
d.pop('name')
print(d)
d = {"name": "westos", "age": 18}
del d['name']
print(d)
4.遍历字典(for)
d = {"name": "westos", "age": 18, "city": "西安"}
# 默认情况下,字典只会遍历key值
for item in d:
print(item)
# 如果遍历字典的key和value呢?(特别特别重要)
for key, value in d.items(): # [('name', 'westos'), ('age', 18), ('city', '西安')]
print(f"key={key}, value={value}")
字典的拓展:defaultdict
from collections import defaultdict
# 默认字典,设置默认value
d = defaultdict(int)
d['views'] += 1
d['transfer'] += 1
print(d) # defaultdict(, {'views': 1, 'transfer': 1})
d = defaultdict(list)
d['allow_users'].append('westos')
d['deny_users'].extend(['user1', 'user2'])
print(d) # defaultdict(, {'allow_users': ['westos'], 'deny_users': ['user1', 'user2']})
d = defaultdict(set)
d['love_movies'].add("黑客帝国")
d['dislike_movies'].update({'前任3', '电影xxxx'})
print(d) # defaultdict(, {'love_movies': {'黑客帝国'}, 'dislike_movies': {'前任3', '电影xxxx'}})