BiSyn-GAT+: Bi-Syntax Aware Graph Attention Network for Aspect-based Sentiment Analysis 论文阅读笔记
一、作者
Shuo Liang、Wei Wei、Xian-Ling Mao、Fei Wang、Zhiyong He
Cognitive Computing and Intelligent Information Processing (CCIIP) Laboratory, School of Computer Science and Technology, Huazhong University of Science and Technology
School of Computer Science and Technology, Beijing Institute of Technology
Institute of Computig Technology, Chinese Academy of Sciences
Naval University of Engineering
二、背景
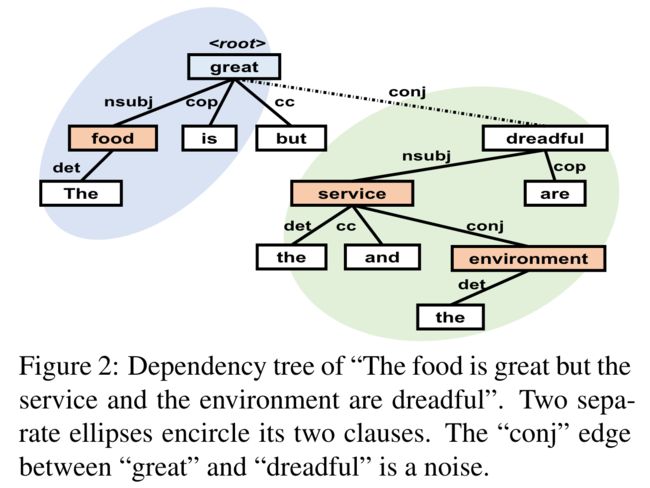
对于 ABSA 任务,现有的很多工作都侧重于通过卷积神经网络或循环神经网络,再借助于注意力机制来提取序列特征,此类方法通常基于靠近目标方面的单词更有可能与该方面的情感相关联,但有些时候这个假设并不成立。比如下面的例子,great 比 dreadful 更靠近方面词 service,这就可能会导致极性判断的错误。

为了解决此类问题,一些研究致力于通过图神经网络来利用依存句法树等非顺序信息。一般情况下,依存树会将方面术语链接到与其在语法上相关的单词上,这在一些长距离的依存问题中依然有效。但依存树结构的固有性质也可能会引入噪声,例如子句之间的不相关关系,比如下图中 great 和 dreadful 之间的 conj 关系,这些噪声会阻碍情感感知上下文的捕获。究其根本,还是依存树更关注单词之间的句法联系,而无法分析复杂的句子结构。
三、创新点
为了克服依存句法树的种种问题,作者首次将成分句法树与图神经网络结并在 ABSA 任务中加以应用并提出了 **Bi-Syntax aware Graph Attention Network(BiSyn-GAT+)**模型。
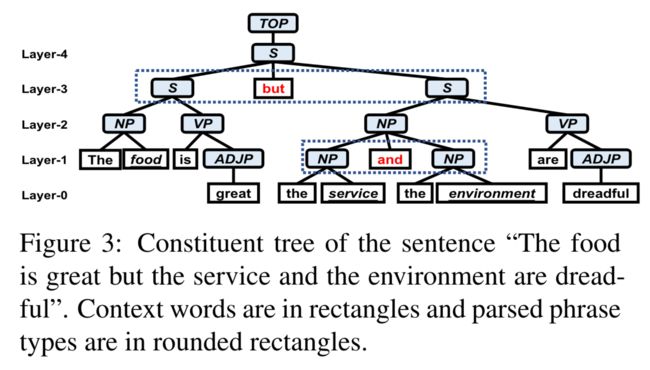
其中,成分树通常具有精确的短语分割和明显的层次结构,短语分割可以将复杂的句子划分为多个子句,层次结构可以梳理出不同方面间的联系,这些都有助于实现方面和其对应的情感词的对齐,下图就是一个很好的例子。
四、具体实现

1.上下文内模块
上下文内模块通过上下文编码器和句法编码器对每个方面的情感上下文进行了建模,并为每个方面生成了特定于方面的表示。因为此模块每次只能处理一个方面,所以该模块会被应用多次。
a.上下文编码
作者借助于 BERT 来对上下文进行编码。序列的构造格式为 [ C L S ] + { w i } + [ S E P ] + a t + [ C L S ] [\mathrm{CLS}] + \{w_i\} + [\mathrm{SEP}] + a_t + [\mathrm{CLS}] [CLS]+{wi}+[SEP]+at+[CLS],其中 { w i } \{w_i\} {wi} 为输入的句子序列, a t a_t at 为给定的目标方面。此部分得到的输出表示为 h t = { h 0 t , h 1 t , … , h n ′ t , … , h n ′ + 2 + m t ′ t } h^t = \{h_0^t, h_1^t, \dots, h_{n'}^t, \dots, h_{n'+2+m_t'}^t\} ht={h0t,h1t,…,hn′t,…,hn′+2+mt′t},其中 h i t h_i^t hit 即为每一个token 的上下文表示。为了简化后续处理,作者将多词短语组成的方面看作是一个词,因此对于 BERT 分词器拆分的短语要重新计算其上下文表示。
b.句法编码器
BERT 只能对语义信息进行编码,为了更好地利用丰富的句法信息,作者设计了句法编码器。句法编码器由多个分层的图注意力块堆叠而成,这些注意力块能在在成分树或依赖树的指导下分层编码语法信息。
c.图构造
为了显示单词间的连接,作者构造了邻接矩阵 C A \mathbf{CA} CA,它的构造规则如下:

其中 { p h u l } \{ph_u^l\} {phul} 表示成分句法树中第 l l l 层的短语集合,比如 Figure 3 中对应的 { p h 0 3 } \{ph_0^3\} {ph03} 即为 The food is great,最终的构造的结果也可以参考下面的图。
d.分层的图注意力块

HGAT 块旨在将句法信息分层编码为单词表示。一个 HGAT 块包括多个 GAT 层,每个 GAT 层利用带掩码的自注意力机制聚合邻居信息,利用全连接前馈网络将表示映射到相同的语义空间。第 l l l 层的单词 w i {w_i} wi 的最终表示 g ^ i t , l \hat{\mathbf{g}}_i^{t,l} g^it,l 定义如下,其中 W g l z \mathbf{W}_g^{lz} Wglz 即为第 l l l 层第 z z z 个注意力头对应的训练参数。
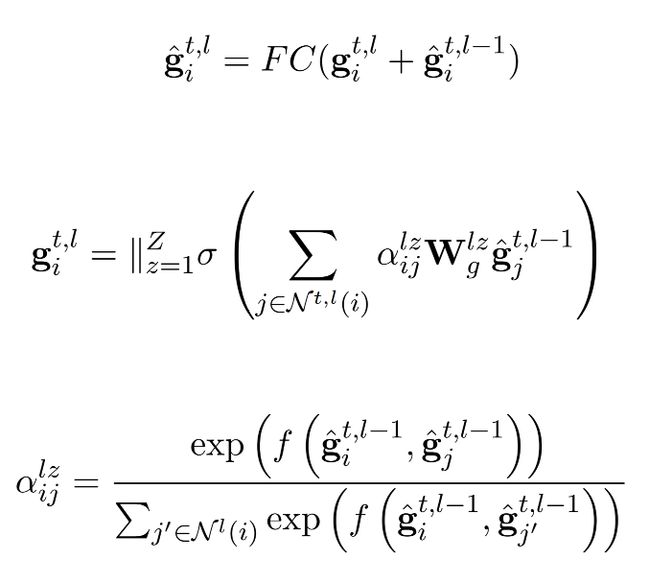
e.辅以依存信息
作者也研究了对于成分句法树和依存句法树中句法信息的融合。如果将依存句法树看作无向图,它对应的邻接矩阵 D A \mathbf{DA} DA 可以按如下定义:

作者将两者的结合定义为 F A = C A ⋅ D A \mathbf{FA} = \mathbf{CA} \cdot \mathbf{DA} FA=CA⋅DA、 F A = C A + D A \mathbf{FA} = \mathbf{CA} + \mathbf{DA} FA=CA+DA 和 F A = C A ⊕ D A \mathbf{FA} = \mathbf{CA} \oplus \mathbf{DA} FA=CA⊕DA 三种操作。
2.上下文间模块
上下文内模块忽略了多个方面之间的相互影响,因此需要借助于上下文间模块中的上下文图来对方面间的关系进行建模,进而得到每一个方面的增强表示。
a.短语分割
方面之间的联系可以通过**短语分词项(phrase segmentation terms,比如连词)**来进行衡量,作者设计了一个基于规则的映射函数 P S PS PS 来返回两个方面的短语分词项。
具体来说,对于两个给定的方面,首先获取他们在成分树中的最小公共祖先(LCA),LCA 的分支中,位于两个方面之间的分支被定义为内部分支,如果存在内部分支,那么 P S PS PS 就会返回该内部分支,如果不存在内部分支,那么就返回两个方面之间的全部单词, P S PS PS 函数的公式表示如下,其中 B r ( a i , a j ) Br(a_i, a_j) Br(ai,aj) 用于获取内部分支中的单词。

b.方面上下文图构造
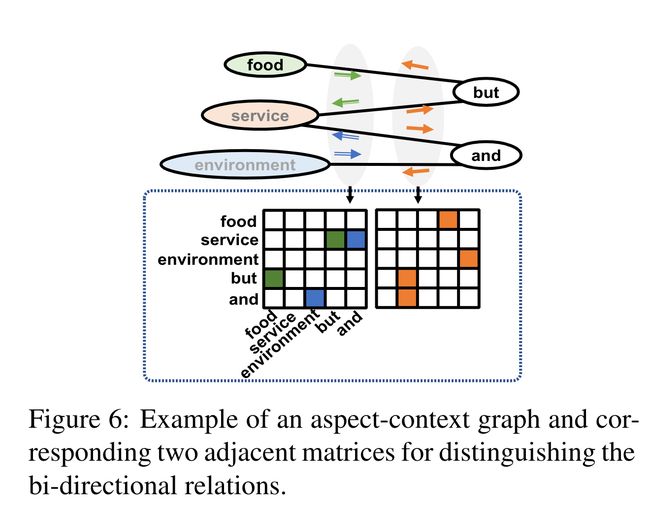
方面的相互影响会随着距离的增加而衰减,而且考虑所有方面会增加开销并且引入噪声,因此方面上下文图只需要对互为邻居的方面进行建模。
通过将邻居方面和它们对应的短语分词项进行关联即可构建方面上下文图,由于方面间的关系是双向的,因此需要两个相应的邻接矩阵,作者将第一个矩阵用于表示基数次序方面对偶数次序方面的影响,另一个与之相反。
3.模型训练
上下文内模块和上下文间模块的输出在整合后会被馈送到情感分类器中进行训练,作者的情感分类器是一个具有 softmax 激活函数的全连接层,并采用交叉熵损失函数来定义损失。