Cross-Domain Aspect Extraction using Transformers Augmented with Knowledge Graphs 论文阅读笔记
一、作者
Phillip Howard、Arden Ma、Vasudev Lal、Ana Paula Simoes、Daniel Korat、Oren Pereg、Moshe Wasserblat、Gadi Singer
Intel Labs, Chandler, Arizona, USA
Intel Labs, Santa Clara, California, USA
Intel Labs, Hillsboro, Oregon, USA
Intel Labs, Petah Tikva, Israel
二、背景
现有的方面术语提取方法在训练数据和测试数据来自于相同的分布的单域条件下已经取得了很好的效果,但是当训练数据域和测试数据域不同时,即存在跨域的问题时,这些模型的性能便会大打折扣。
跨域问题的主要挑战在于来自于不同域的方面之间通常很少有重叠,例如消费者对笔记本电脑的评论中普遍存在的方面(如处理器、硬件等)与餐厅评论中的常见方面(如食物、开胃菜等)基本毫不相关。
三、创新点
作者着重对跨域方面术语提取进行了研究,他们引入了一种新的方法来增强预训练的 Transformer 模型,该方法借助于通过语义知识源 ConceptNet 自动构建的特定领域的知识图谱来提供目标域中潜在方面的上下文信息,进而改进域迁移。
四、具体实现
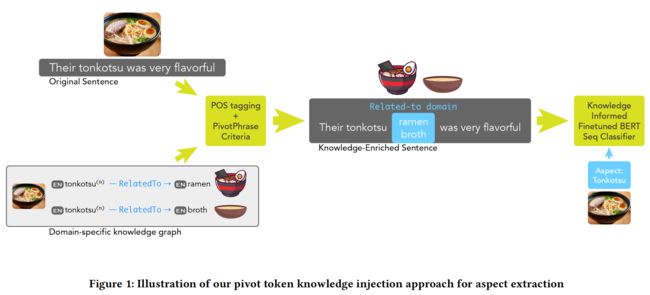
1.知识图谱准备
a.子图查询
知识子图构建的第一步是基于特定域的种子术语列表,通过对 ConceptNet 的查询构建一个原始的知识子图。
具体来说,对于每一个目标域 d d d,通过将 TF-IDF 应用于域 d d d 中所有的未标记文本并取得分最高的前 k k k 个名词短语,即可得到种子术语列表 S d = { s 1 , s 2 , … , s K } S_d = \{s_1, s_2, \dots, s_K\} Sd={s1,s2,…,sK}。然后,对 S d S_d Sd 中的每一个种子术语 s s s,查询在 ConceptNet 中通过边连接到 s s s 的所有节点,并将它们与种子术语 s s s 一起添加到特定域的子图中。最后,通过迭代查询这些附加节点进一步扩展子图,直到子图中边缘节点与种子术语的最大距离达到 h h h。
b.子图剪枝
为了增加查询子图与目标域的相关性,需要对与种子术语 s s s 的相关性得分较低的生成节点进行剪枝。
作者首先将这个通过 ConceptNet 构建的子图结构与 Word2vec 等词嵌入技术相结合,进而将相关性得分定义为 r i , j = e i ⋅ e j ∥ e i ∥ ∥ e j ∥ r_{i, j} = \frac{\mathbf{e}_i \cdot \mathbf{e}_j}{\lVert\mathbf{e}_i\rVert \lVert\mathbf{e}_j\rVert} ri,j=∥ei∥∥ej∥ei⋅ej,其中 e i \mathbf{e}_i ei 是对于子图中给定节点 i i i 的嵌入向量。基于 r i , j r_{i, j} ri,j 作者将子图中给定路径 P = { n S , n 1 , … , n h } P = \{n_S, n_1, \dots, n_h\} P={nS,n1,…,nh} 的最小路径相关分数 P min P_{\min} Pmin 定义为 P min = min ∀ i ∈ { 1 , … , h } r i , j P_{\min} = \displaystyle\min_{\forall i \in\{1, \dots, h\}}r_{i, j} Pmin=∀i∈{1,…,h}minri,j,而满足 P min < 0.2 P_{\min} < 0.2 Pmin<0.2 的路径上的所有节点都会被剪枝,这本质上是以牺牲覆盖率为代价减少子图中的不相关节点。
c.子图扩充
对子图进行剪枝可能会影响其覆盖率,为此作者通过生成式的常识模型 COMET 来对子图进行扩充。
对于给定的头部 h h h 和关系 r r r ,COMET 可以对尾部 t t t 进行预测进而实现对三元组 ( h , r , t ) (h, r, t) (h,r,t) 的补全。为了提高 COMET 的跨域能力,对于每一个目标域 d d d,作者通过 spaCy 识别出文本中出现的所有名词和名词短语,然后在 ConceptNet 中查询包含这些名词之一的三元组,进而基于这些三元组对 COMET 进行微调。
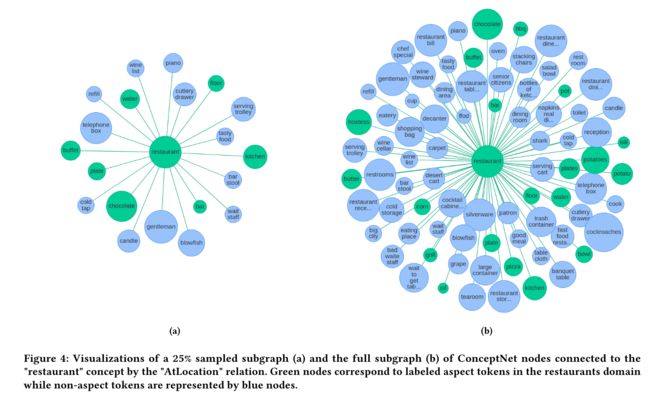
2.知识注入时机
为了确定何时注入知识,需要使用 spaCy 提取词性和依赖关系,进而识别潜在的方面 token。
因为方面一般是名词或名词短语,作者通过识别输入序列中的名词格式筛选出候选的 token 集合。然后,将此 token 集与特定域的 KG 进行比较,以确定应将哪些标记为与该领域相关联。最终,可以得到一个经过筛选的候选 token 集,它们将在下一步中被使用。
3.知识注入机制
作者提到了两种将知识注入到 Transformer 中的方法。第一种是通过在被识别为潜在方面的 token 后面插入一个 pivot token 来丰富查询。第二种是利用分离的注意力的分解来调节每个 token 在枢轴信息上的分布。
a.通过 pivot token 进行知识注入
pivot token 包括 [DOMAIN-B] 和 [DOMAIN-I],是一种特殊的 token,作者将 pivot token 插入在指定的 token 后面,用于向模型指示它前面的 token 更有可能被标记为方面。例如 It was the best pad [DOMAIN-B] thai [DOMAIN-I] I’ve ever had.。
在这一步作者通过对 Transformer 进行训练以避免插入过程的不确定性以及源域和目标域之间的依赖性。
b.通过分离的注意力机制进行知识注入
通过注意力机制来进行知识注入可以避免插入导致的句子序列变化,同时粒度更细。
作者通过添加新的注意力得分项对 DeBERTa 中的分离注意力机制进行了扩充。在原本的 DeBERTa 中,输入序列由内容其纳入和位置嵌入表示,而为了表示某个 token 是否是某一方面的候选方面术语,作者添加了两个嵌入向量 m + , m − ∈ R d m^+, m^- \in \mathbb{R}^d m+,m−∈Rd,并由此建立了嵌入序列 S m = m ! … m N S^m = m_!\dots m_N Sm=m!…mN。

进而,模型可以通过 Transformer 创建的 token 的内容表示和 S m S^m Sm 共同调节注意力机制,挖掘潜在位置表示的相关信息。
五、实验
作者采用了 restaurant(Pontiki et al., 2015)、laptop(Pontiki et al., 2014)和 digital devices(Wang et al., 2016)三个数据集作为实验数据集。
作者将跨域设置表示为 D = { ( , ) , ( , ) , ( , ) , ( , ) , ( , ) , ( , ) } \mathcal{D} = \{(, ), (, ), (, ), (, ), (, ), (, )\} D={(L,R),(L,D),(R,L),(R,D),(D,L),(D,R)},其中每一个元组的第一个元素是源域,第二个是目标域,模型会在源域中进行训练和微调并在目标域中进行实验。实验结果如下所示,其中 -PT 表示使用 pivot token 进行知识注入,-MA 表示通过修改后的注意方案进行知识注入。
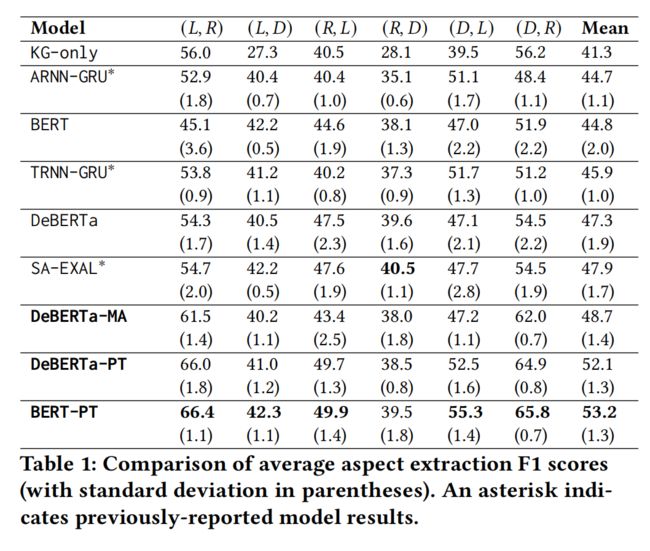
可以发现,基于 pivot token 的方法效果更好,作者认为这是由于分离的注意力机制提高了模型的复杂性,而用来识别候选方面的二元指标所提供的信息不足以抵消这样的复杂性开销。此外,尽管 DeBERTa 模型的效果优于 BERT,但实际上 BERT 对于 pivot token 的适应性更好,作者认为这是因为标记的插入会破坏 DeBERTa 中的相对位置信息,而 BERT 的绝对位置受此影响较小。
相比较之下,模型在餐厅数据集作为目标域时效果最好,这主要是因为 ConceptNet 中有关餐饮的信息最多,能够将相关方面更好地覆盖。
作者还通过调整训练过程中的知识图谱的大小以观察其影响,实验结果如下:
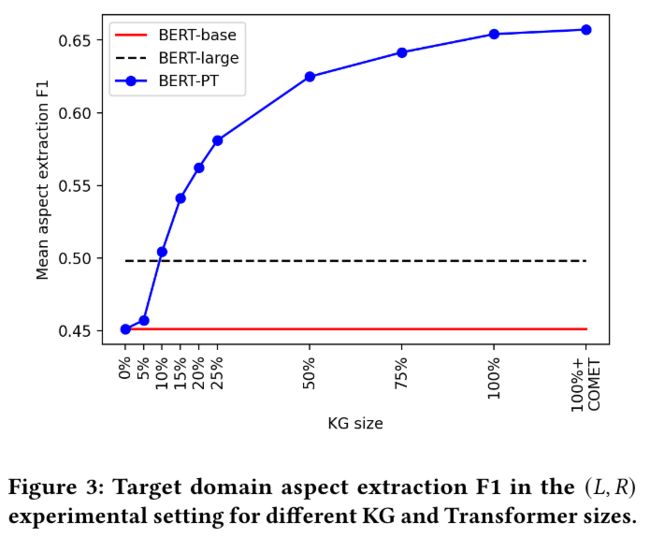
可以看到,仅仅通过扩展模型可用的外部知识量就可以提高推理时的性能,而无需重新训练 Transformer。尽管 BERT-large 的参数是 BERT-PT 的三倍多,但仅使用原始 ConceptNet 子图的 10% 作为 KG 时,BERT-PT 模型就已经优于 BERT-large。