不重要的token可以提前停止计算!英伟达提出自适应token的高效视觉Transformer网络A-ViT,提高模型的吞吐量!...
关注公众号,发现CV技术之美
本文分享 CVPR 2022 Oral 论文『A-ViT: Adaptive Tokens for Efficient Vision Transformer』,英伟达提出自适应token的高效视觉Transformer网络A-ViT,大大提高模型的吞吐量!
详细信息如下:

论文链接:https://arxiv.org/pdf/2112.07658.pdf
01
摘要
本文提出了一种对不同复杂度图像,自适应调整推理代价视觉Transformer(ViT)的方法——A-ViT。A-ViT通过在推理过程中自动减少网络中处理的视觉Transformer中的token数量来实现这一点。
作者为这项任务重新制定了自适应计算时间(Adaptive Computation Time ,ACT),丢弃冗余的空间token。视觉Transformer的结构特性使本文的自适应token缩减机制能够在不修改网络结构或推理硬件的情况下加快推理速度。作者证明了A-ViT不需要额外的参数或子网络,因为本文的方法基于原始网络参数学习能够自适应停止。作者进一步引入了分布先验正则化,与之前ACT方法相比,它可以稳定训练。
在图像分类任务(ImageNet1K)中,作者表明提出的A-ViT在过滤信息性空间特征和减少总体计算量方面具有很高的效率。该方法将DeiT-Tiny和DeiT-Small的吞吐量分别提高了62%和38%,准确率仅下降0.3%,大大优于现有技术。
02
Motivation
Transformer是一种流行的神经网络结构,它使用高度表达性的注意力机制计算网络输出。它们起源于自然语言处理(NLP)社区,已被证明能有效地解决NLP中的广泛问题,如机器翻译、表征学习和问答。
最近,视觉Transformer在视觉界越来越受欢迎,并已成功应用于广泛的视觉应用,如图像分类、目标检测、图像生成和语义分割。目前,最流行的范例仍然是,vision transformers通过将图像分割成一系列有序的patch来形成token,并在token之间执行计算来解决底层任务。
使用vision transformers处理图像的计算成本仍然很高,这主要是因为token之间的交互次数是二次的。因此,在数据处理集群或边缘设备上部署vision Transformer是一项具有挑战性的任务,需要大量的计算和内存资源。
本文的重点是研究如何根据输入图像的复杂度自动调整视觉Transformer中的计算。几乎所有主流的视觉Transformer在推理过程中都有一个固定的成本,该成本独立于输入。然而,预测任务的难度随着输入图像的复杂性而变化。例如,从具有同质背景的单个图像中对汽车和人类进行分类相对简单;而在复杂背景下区分不同品种的狗更具挑战性。即使在单个图像中,与背景中的patch相比,包含详细对象特征的patch也能提供更多信息。受此启发,作者开发了一个基于输入自适应调整视觉Transformer中使用的计算的框架。
神经网络的输入依赖推理问题在以前的工作中已经得到了研究。之前工作提出了自适应计算时间(ACT),将神经模块的输出表示为由halting分布定义的平均场模型。这种公式将离散halting问题放松为一个连续优化问题,使总计算的上界最小化。然而,作者表明,视觉Transformer的均匀形状和tokenization使自适应计算方法能够在现成硬件上产生直接的加速,在效率-精度权衡方面超过了先前的工作。

在本文中,作者提出了一种视觉Transformer的输入相关自适应推理机制。一种简单的方法是遵循ACT,即对剩余层中的所有token同时停止计算。作者观察到,这种方法将计算量减少了一小部分,但会造成不必要的精度损失。
为了解决这一问题,作者提出了A-ViT,这是一种空间自适应推理机制,它在不同的深度停止计算不同的token,以动态的方式仅为区分性token保留计算。与卷积特征映射中的逐点ACT不同,本文的空间暂停由高性能硬件直接支持,因为暂停的token可以有效地从底层计算中移除。此外,可以使用模型中的现有参数学习整个停止机制(halting mechanism),而无需引入任何额外参数。此外,作者还提出了一种新的方法,通过对停止概率施加分布先验来施加不同的计算预算。
根据实验观察到,计算的深度与对象语义高度相关,这表明本文的模型可以忽略不太相关的背景信息(具体可见上图中的例子)。本文提出的方法显著降低了推理成本——A-ViT将DEIT-Tiny的吞吐量提高了62%,DEIT-Small的吞吐量提高了38%,而ImageNet1K的精度仅下降了0.3%。本文的主要贡献如下:
本文介绍了一种在视觉Transformer中进行输入相关推理的方法,该方法允许在不同深度停止对不同token的计算。
作者将自适应token停止的学习建立在原始结构中现有嵌入维度的基础上,并且不需要额外的参数或计算来停止计算。
作者引入分布先验正则化来引导停止朝着稳定ACT训练的特定分布和平均token深度方向发展。
作者分析了不同图像中不同token的深度,并深入了解了视觉Transformer的注意力机制。
本文的实验表明,所提出的方法在硬件上的吞吐量提高了62%,而准确度下降很小。
03
方法
考虑一个视觉Transformer网络,该网络将图像(C、H和W分别表示通道、高度和宽度)作为输入,通过以下方式进行预测:
![]()
其中,编码网络将图像patch转换为一系列token ,K是标记的总数,E是每个token的嵌入维度,而L个中间Transformer块通过自注意力处理输入token。考虑第l层的transformer块,它通过以下方式处理l-1层出来的所有token:
![]()
其中代表所有更新的token,其中。Transformer块的内部计算流使得token的数量K可以从一层更改到另一层。当token由于停止机制而被丢弃时,这提供了计算增益。Vision transformer为整个层中的所有token使用一致的特征尺寸。这使得学习和捕获以联合方式监视所有层的全局停止机制变得很容易。与需要明确处理不同模型尺寸(例如,不同深度的通道数量)的CNN相比,这也使得Transformer的停止机制设计更容易。
为了自适应停止token,作者为每个token引入了一个与输入相关的停止分数,作为第l层token k的停止概率:
![]()
其中是一个停止模块。与ACT类似,作者强制每个token的暂停分数在范围内,并使用累积重要性在推理时深入到更深层次时停止token。为此,作者在累计停止分数超过时进行token停止:

式中,ϵ是一个小的正常数,允许在一层之后停止。为了进一步缓解相邻层之间对动态停止token的任何依赖。作者在token停止之后,将屏蔽所有剩余深度的token,方法是(1)将token值归零;(2)阻止其关注其他token,屏蔽其对的影响。作者定义来强制所有token在最后一层停止。本文的token掩蔽使训练迭代的计算成本与原始vision transformer的训练成本相似。然而,在推理时,只需在计算中删除停止的token,以测量通过停止机制获得的实际加速。
作者通过在MLP层中分配一个神经元来完成任务,将整合到现有的视觉Transformer块中。因此,可以不引入任何额外的可学习参数或停止机制的计算。更具体地说,每个token的嵌入维度E有足够的容量来适应停止学习,从而实现停止分数计算,如下所示:
![]()
其中,表示token的第e个维度,是logistic sigmoid函数。β和γ是在应用非线性之前调整嵌入的移位和缩放参数。这两个标量参数在所有token的所有层上共享。只有嵌入维度E的一个维度用于停止分数计算。从实验上看,作者观察到,简单选择(第一维度)表现良好。此外,本文的停止机制不会在两个标量参数β和γ之外引入额外的参数或子网络。
为了跟踪各层停止概率的进度,作者计算每个token的余数,如下所示:
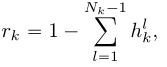
随后形成停止概率,如下所示:

给定h和r的范围,每层每个token的停止概率为。鼓励提前停止的损失为:

Vision transformers使用一个特殊的class token来生成分类预测,将其表示为。该token与其他输入token类似,在所有层中都会更新。作者应用平均场公式(先前状态的停止概率加权平均值)来形成输出token和相关任务损失,如下所示:

然后,本文的视觉Transformer可以通过最小化以下内容进行训练:
![]()
其中,表示相对于主要任务损失的比例。

上图的算法1展示了整个计算流。

上图展示了停止机制的流程。
损失函数中很重要的一项是。值越大,惩罚项越重,因此可以提前停止token。尽管对减少计算有效,但先前关于自适应计算的工作发现,训练对的选择很敏感,其值可能无法提供精确-效率权衡的细粒度控制。因此,作者在将正则化之前引入了一个分布,这样token就可以在目标深度退出。在这种情况下,对于无限数量的输入图像,作者期望token的深度在分布先验内变化。为此,作者定义了停止分数分布:

这平均了网络每一层(即,)上所有token的期望停止分数。利用这一点作为停止可能性在各层之间分布的估计,可以使用KL散度将此分布调整为预定义的先验分布。因此,将新的分布先验正则化项形式为:
![]()
其中,KL表示KL散度,表示具有引导停止层的目标停止得分分布。本文利用高斯分布的概率密度函数定义了一个钟形分布目标,该分布以预期的停止深度目标为中心。这鼓励每个token的预期停止分数之和触发N个目标的退出条件,提供了对期望的剩余计算的增强控制。
本文为自适应token计算训练网络参数的最终损失函数公式如下:
![]()
其中是一个标量系数,用于平衡分布正则化与其他损失项。
04
实验

上图显示了在通过ImageNet1K验证集,使用本文的A-ViT-T进行推理期间自适应控制的token深度。

上图(a)描绘了在验证集上学习的token的平均深度,它显示为以图像中心为中心的二维高斯分布。这与大多数ImageNet样本居中的事实一致,直观地与图像分布对齐。上图(b)显示每个图像每层所有token上平均的停止分数的方框图。停止分数在最初阶段逐渐增加,达到峰值,然后下降。

可以通过查看每个图像的自适应token的平均深度来分析网络中图像的难度。因此,在上图中,作者根据所需的计算描述了困难样本和简单样本。
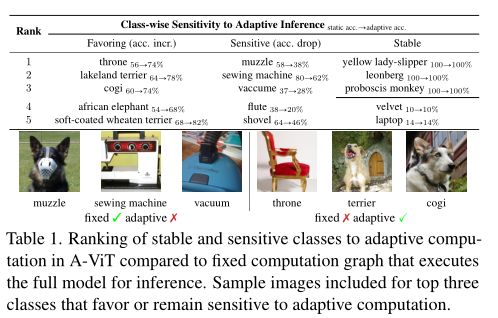
给出了一种自适应推理范式,注意这个分析了相对于完整模型的不同类别分类精度的变化。作者计算了应用自适应推理前后类验证精度的变化。作者在上表中总结了定性和定量结果。

上表给出了本文方法与研究Transformer动态推理停止机制的现有技术的比较。

为了进一步可视化对最先进的DynamicViT的改进,作者在上图中呈现了token深度的定性比较。
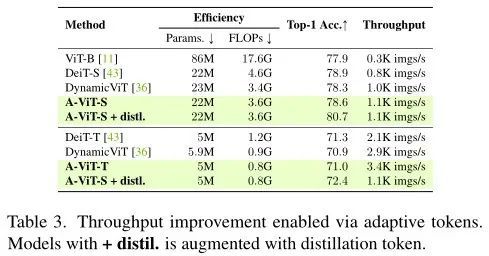
在上表中,作者比较了现有方法的GPU加速比。
05
总结
在本文中,作者提出了A-ViT来根据输入复杂性自适应调整token计算量。作者证明,该方法在硬件上提高了vision transformer的吞吐量,而无需施加额外的参数或修改transformer块,优于以前的动态方法。捕获的token重要性分布随输入图像自适应变化,与人类感知惊人地吻合,为未来提高视觉Transformer效率的工作提供了见解。
参考资料
[1]https://arxiv.org/pdf/2112.07658.pdf

END
欢迎加入「Transformer」交流群备注:TFM
