SQL语句整理三--hive
文章目录
-
-
-
- 字符串拼接:
- split函数(分割字符串):
- Hive中的replace方法:
- 行列转换:
- 创建数据库:
- 创建表:
- 添加或删除字段:
- insert into 和 insert overwrite:
- 查询语句中显示列名,不带表名:
- hive 表的类型:
-
- 1.内部表:
- 2.外部表:
- 3.分区表:
- 4.创建桶表:
- desc命令:
- 将生成的结果导入到一个文件中:
- udf时间函数用法:
- datediff,date_add和date_sub:
- 时间函数应用获取当前时间:
- mysql到hive数据类型转换:
- Hbase表映射Hive表三种方法:
-
- 1.列映射(单列):
- 2.列映射(多列):
- 3.列族映射:
- 创建日期维度表:
- show functions:
-
-
字符串拼接:
select date_format(concat('2021-08','-01'),'yyyy-MM-dd HH:mm:ss') ;
+----------------------+
| _c0 |
+----------------------+
| 2021-08-01 00:00:00 |
+----------------------+
1 row selected (2.258 seconds)
split函数(分割字符串):
语法: split(string str, string pat)
返回值: array
说明: 按照pat字符串分割str,会返回分割后的字符串数组
1.基本用法
select split('abcdef', 'c');
结果:["ab", "def"]
2.截取字符串中的某个值
select split('abcdef', 'c')[0];
结果:ab
3.特殊字符。如正则表达式中的特殊符号作为分隔符时,需做转义 (前缀加上\)
select split('ab_cd_ef', '\_')[0];
结果:ab
select split('ab?cd_ef', '\\?')[0];
结果:ab
如果是在shell中运行,则(前缀加上\\)
hive -e "select split('ab?cd_ef', '\\\\?')[0]"
注:有些特殊字符转义只需\,而有些需\\,eg.?。可能在语句翻译过程中经历经历几次转义。
参考:【Hive】split函数(分割字符串)
计算最后指定位数的字段值:
假设字段样式如下:
a,b,c,d
a,c,b
a,f,g,h,j
想要取出倒数第一位的数(结果如下):
c
c
h
实现如下:
方法一:
select split(cat_id,',')[size(split(cat_id,','))-2] from test_tmp;
方法二:
select reverse(split(reverse(cat_id),',')[1]) as cat_id from test_tmp;
注:字符串反转函数:reverse。select reverse('abcedfg'); ##返回值为gfdecba
参考(测试了sql语句有错误进行了相应的修改):hive中split后计算最后指定位数的字段值(从后往前推的索引值)
Hive中的replace方法:
参考:Hive中的replace方法
Hive本身并没有replace方法,但是提供了两个方法可以实现replace功能
1.translate例子(这个方法可用是在Hive 0.10.0):使用空字符串替换#字符
> select translate('This #is test to verify# translate #Function in Hive', '#','');
+----------------------------------------------------+--+
| _c0 |
+----------------------------------------------------+--+
| This is test to verify translate Function in Hive |
+----------------------------------------------------+--+
1 row selected (0.28 seconds)
2.regexp_replace例子:使用$符号替换^
> select regexp_replace('HA^G^FER$JY',"\\^","\\$");
+--------------+--+
| _c0 |
+--------------+--+
| HA$G$FER$JY |
+--------------+--+
1 row selected (0.208 seconds)
注:我使用的是hive 3.1.0版本,发现有replace方法啊,而且感觉更好用。
select replace('HA^G^FER$JY',"\\^","\\$");
+--------------+
| _c0 |
+--------------+
| HA^G^FER$JY |
+--------------+
select replace('HA^G^FER$JY',"^","$");
+--------------+
| _c0 |
+--------------+
| HA$G$FER$JY |
+--------------+
select regexp_replace('HA^G^FER$JY',"^","$");
Error: Error while compiling statement: FAILED: SemanticException [Error 10014]: Line 1:7 Wrong arguments '"$"': org.apache.hadoop.hive.ql.metadata.HiveException: Unable to execute method public org.apache.hadoop.io.Text org.apache.hadoop.hive.ql.udf.UDFRegExpReplace.evaluate(org.apache.hadoop.io.Text,org.apache.hadoop.io.Text,org.apache.hadoop.io.Text):Illegal group reference: group index is missing (state=42000,code=10014)
行列转换:
参考:Hive之列转行,行转列
列转行:
// 测试数据:
hive> select * from col_lie limit 10;
OK
col_lie.user_id col_lie.order_id
104399 1715131
104399 2105395
104399 1758844
104399 981085
104399 2444143
104399 1458638
104399 968412
104400 1609001
104400 2986088
104400 1795054
// 把相同user_id的order_id按照逗号转为一行:
select user_id,
concat_ws(',',collect_list(order_id)) as order_value
from col_lie
group by user_id
limit 10;
//结果(简写)
user_id order_value
104399 1715131,2105395,1758844,981085,2444143
总结:
使用函数:concat_ws(',',collect_set(column))
说明:collect_list 不去重,collect_set 去重。 column的数据类型要求是string
行转列:
// 测试数据:
hive> select * from lie_col;
OK
lie_col.user_id lie_col.order_value
104408 2909888,2662805,2922438,674972,2877863,190237
104407 2982655,814964,1484250,2323912,2689723,2034331,1692373,677498,156562,2862492,338128
104406 1463273,2351480,1958037,2606570,3226561,3239512,990271,1436056,2262338,2858678
104405 153023,2076625,1734614,2796812,1633995,2298856,2833641,3286778,2402946,2944051,181577,464232
104404 1815641,108556,3110738,2536910,1977293,424564
104403 253936,2917434,2345879,235401,2268252,2149562,2910478,375109,932923,1989353
104402 3373196,1908678,291757,1603657,1807247,573497,1050134,3402420
104401 814760,213922,2008045,3305934,2130994,1602245,419609,2502539,3040058,2828163,3063469
104400 1609001,2986088,1795054,429550,1812893
104399 1715131,2105395,1758844,981085,2444143,1458638,968412
Time taken: 0.065 seconds, Fetched: 10 row(s)
// 将order_value的每条记录切割为单元素:
select user_id,order_value,order_id
from lie_col
lateral view explode(split(order_value,',')) demo as order_id
limit 10;
//结果
user_id order_value order_id
104408 2909888,2662805,2922438,674972,2877863,190237 2909888
104408 2909888,2662805,2922438,674972,2877863,190237 2662805
104408 2909888,2662805,2922438,674972,2877863,190237 2922438
104408 2909888,2662805,2922438,674972,2877863,190237 674972
104408 2909888,2662805,2922438,674972,2877863,190237 2877863
104408 2909888,2662805,2922438,674972,2877863,190237 190237
104407 2982655,814964,1484250,2323912,2689723,2034331,1692373,677498,156562,2862492,338128 2982655
104407 2982655,814964,1484250,2323912,2689723,2034331,1692373,677498,156562,2862492,338128 814964
104407 2982655,814964,1484250,2323912,2689723,2034331,1692373,677498,156562,2862492,338128 1484250
104407 2982655,814964,1484250,2323912,2689723,2034331,1692373,677498,156562,2862492,338128 2323912
Time taken: 0.096 seconds, Fetched: 10 row(s)
创建数据库:
create database jiuyebu;
desc database jiuyebu;
use jiuyebu;
-- casecad 表示有表也删除
drop database yangyang casecad;
创建表:
-- 建表时判断该表是否存在
create table if not exists zb_xsgsbqy_xzq。。。
-- 创建临时表
create temporary table tmp as select * from test.test001 ;
-- 创建dept测试表
create table emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)
row format delimited fields terminated by '\t';
-- 导入测试数据
load data local inpath "/home/hadoop/emp.txt" into table emp;
-- 注释: --local表示本地
--overwrite表示覆盖(默认情况使用的是append),一般要加上overwrite 表示覆盖
-- 清空一个表
truncate table emp;
-- 删除一个表
drop table emp;
drop table if exists yesterday_tmp;
-- 重命名表名
alter table FaRen_JiChuShuJu141 rename to FaRen_JiChuShuJu;
-- 展示建表语句
show create table + 表名;
添加或删除字段:
官方文档关于Add/ReplaceColumns操作的说明
// 创建测试表
CREATE TABLE IF NOT EXISTS test (id BIGINT, name STRING);
// 插入一条数据
INSERT INTO TABLE test VALUES(2341344423,"lisi");
// 添加字段
ALTER TABLE test ADD COLUMNS(age Int) COMMENT '年龄';
注:原有数据在新增一个或多个字段后,会将新增字段的值设置为null
// 插入一条数据
INSERT INTO TABLE test VALUES(2341344422,"zhangsan",18);
// 删除字段(使用新schema替换原有的)
ALTER TABLE test REPLACE COLUMNS(id BIGINT, name STRING);
注:在删除一个或多个字段后,原始数据的原始字段的值不会随之丢失
修改字段(名称/类型/位置/注释):
CREATE TABLE test_change (a int, b int, c int);
// First change column a's name to a1.
ALTER TABLE test_change CHANGE a a1 INT;
// Next change column a1's name to a2, its data type to string, and put it after column b.
ALTER TABLE test_change CHANGE a1 a2 STRING AFTER b;
// The new table's structure is: b int, a2 string, c int.
// Then change column c's name to c1, and put it as the first column.
ALTER TABLE test_change CHANGE c c1 INT FIRST;
// The new table's structure is: c1 int, b int, a2 string.
// Add a comment to column a1
ALTER TABLE test_change CHANGE a1 a1 INT COMMENT 'this is column a1';
insert into 和 insert overwrite:
insert into table account select id,age,name from account_tmp;
insert overwrite table account2 select id,age,name from account_tmp;
两者的区别:
- insert into 只是简单的插入,不考虑原始表的数据,直接追加到表中。
- insert overwrite 会覆盖已经存在的数据,假如原始表使用overwrite 上述的数据,先现将原始表的数据remove,再插入新数据。
查询语句中显示列名,不带表名:
在hive-site.xml配置文件里添加如下:
<property>
<name>hive.resultset.use.unique.column.namesname>
<value>falsevalue>
property>
或者:set hive.resultset.use.unique.column.names=false;
hive 表的类型:
1.内部表:
hive 的管理表也可以称为内部表: 默认表类型。
- 数据存放的MANAGED_TABLE 内部
- 默认数据存储在仓库位置目录/user/hive/warehouse/下面,每创建一个库,就是一个目录,建表就会生成文件。
- 删除表的时候,也会删除HDFS上面的文件。
create table dept1(
deptno int,
dname string,
loc string
)
row format delimited fields terminated by '\t';
-- 导入数据处理:
load data local inpath "/home/hadoop/dept.txt" into table dept1;
2.外部表:
- 数据存放的MANAGED_TABLE 内部
- 一般我们会使用location去指定存放到其他位置
- 删除表的时候,不会去删除HDFS上面的文体,只删除元数据
create table dept2(
deptno int,
dname string,
loc string
)
row format delimited fields terminated by '\t' location '/hive/dept2';
-- 导入数据处理
load data local inpath "/home/hadoop/dept.txt" into table dept2;
3.分区表:
使用业务场景:
- 时间增量数据
- 提高查询速度(核心)
- 一级分区、二级分区 partitioned by (date string,time string)
- 创建表时需要给定partitioned 处理 一般是 指定日期为string 类型。
create table emp3(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)
partitioned by (data string)
row format delimited fields terminated by '\t';
-- 导入数据的时候要加上partitioned处理。
load data local inpath "/home/hadoop/emp.txt" into table emp3 partition (date='20150515');
-- 查找可以用按 分区去查找
select * from emp3 where date='20150515';
-- 查询某个表的分区信息
show partitions emp3;
注:上传 文件到 分区表当中 没有带分区等相关信息 就需要修复分区表,可参考:hive的msck repair命令
msck repair table emp3 ;
-- 或者
alter table emp3 add partition(date='20150515');
4.创建桶表:
create table emp4(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)
clustered by(empno) into 3 buckets
row format delimited fields terminated by '\t';
-- 默认情况下load 加载时不分桶表:
-- 强制设置分桶:
set hive.enforce.bucketing = true;
-- 可以使用查询其它表加载到桶表,
-- 插入数据:
insert into emp4 select * from emp4;
-- 显示dfs下文件:路径/库/表/文件
hive> dfs -lsr /
注:hive中的桶表数量如何去设置,评估数据量,保证每个桶的数据量是block的2倍大小
desc命令:
desc 命令是为了展示hive表格的内在属性。例如列名,data_type,存储位置等信息。这个命令常常用在我们对hive表格观察之时,我们想要知道这个hive各个列名,hive表格的存储位置。
desc table + 表名;
-- 要想获得更加详细的内容,我们可以使用 desc formatted 命令。
-- 想获得表中有分区的情况:
desc formatted revr_bmbs_dmp_offline.rv_dmp_offline_tags_hist partition(dt=20210307);
-- 双分区的情况:
+----------------------+
| partition |
+----------------------+
| dt=20210309/hour=6 |
+----------------------+
desc formatted revr_bmbs_dmp_offline.rt_recmd_message partition(dt=20210309,hour=6);
将生成的结果导入到一个文件中:
beeline --outputformat=tsv2 -e "select dmp_id from huiq.heheda where partition_date='20201205'" > 20201205_rd_tmp.csv
注:hiveserver2提供了一个新的命令行工具beeline,hiveserver2 对之前的hive做了升级,功能更加强大,它增加了权限控制。Beeline和其他工具有一些不同,执行查询都是正常的SQL输入,但是如果是一些管理的命令,比如进行连接,中断,退出,执行Beeline命令需要带上“!”,不需要终止符。常用命令介绍:
1、!connect url –连接不同的Hive2服务器
2、!exit –退出shell
3、!help –显示全部命令列表
4、!verbose –显示查询追加的明细
The Beeline CLI 支持以下命令行参数:
Option
Description
--autoCommit=[true/false] ---进入一个自动提交模式:beeline --autoCommit=true
--autosave=[true/false] ---进入一个自动保存模式:beeline --autosave=true
--color=[true/false] ---显示用到的颜色:beeline --color=true
--delimiterForDSV= DELIMITER ---分隔值输出格式的分隔符。默认是“|”字符。
--fastConnect=[true/false] ---在连接时,跳过组建表等对象:beeline --fastConnect=false
--force=[true/false] ---是否强制运行脚本:beeline--force=true
--headerInterval=ROWS ---输出的表间隔格式,默认是100: beeline --headerInterval=50
--help ---帮助 beeline --help
--hiveconf property=value ---设置属性值,以防被hive.conf.restricted.list重置:beeline --hiveconf prop1=value1
--hivevar name=value ---设置变量名:beeline --hivevar var1=value1
--incremental=[true/false] ---输出增量
--isolation=LEVEL ---设置事务隔离级别:beeline --isolation=TRANSACTION_SERIALIZABLE
--maxColumnWidth=MAXCOLWIDTH ---设置字符串列的最大宽度:beeline --maxColumnWidth=25
--maxWidth=MAXWIDTH ---设置截断数据的最大宽度:beeline --maxWidth=150
--nullemptystring=[true/false] ---打印空字符串:beeline --nullemptystring=false
--numberFormat=[pattern] ---数字使用DecimalFormat:beeline --numberFormat="#,###,##0.00"
--outputformat=[table/vertical/csv/tsv/dsv/csv2/tsv2] ---输出格式:beeline --outputformat=tsv (默认为talbe)
--showHeader=[true/false] ---显示查询结果的列名:beeline --showHeader=false
--showNestedErrs=[true/false] ---显示嵌套错误:beeline --showNestedErrs=true
--showWarnings=[true/false] ---显示警告:beeline --showWarnings=true
--silent=[true/false] ---减少显示的信息量:beeline --silent=true
--truncateTable=[true/false] ---是否在客户端截断表的列
--verbose=[true/false] ---显示详细错误信息和调试信息:beeline --verbose=true
-d class> ---使用一个驱动类:beeline -d driver_class
-e ---使用一个查询语句:beeline -e "query_string"
-f ---加载一个文件:beeline -f filepath 多个文件用-e file1 -e file2
-n ---加载一个用户名:beeline -n valid_user
-p ---加载一个密码:beeline -p valid_password
-u ---加载一个JDBC连接字符串:beeline -u db_URL
udf时间函数用法:
参考:hive中的udf时间函数用法
-
from_unixtime函数用法为将时间戳转换为时间格式
语法:from_unixtime(bigint unixtime, [string format])返回值为string
例如:hive>select from_unixtime(1326988805,'yyyyMMddHH');
结果:2012011916 -
UNIX时间戳函数:
unix_timestamp
语法:unix_timestamp()返回值为bigint
例如1:hive> select unix_timestamp();
结果:1629111510
例如2:select unix_timestamp('2011-12-07 13:01:03');
结果:1323262863
例如3:select unix_timestamp('20111207 13:01:03', 'yyyyMMdd HH:mm:ss');
结果:1323262863 -
日期时间转日期函数:
to_date
语法:to_date(string timestamp)返回值为string
例如:hive>select to_date('2011-12-08 10:03:01');
结果:2011-12-08 -
日期转年函数:
year
语法:year(string date)返回值为int
例如:hive>select year('2011-12-08 10:03:01');
结果:2011 -
日期转月函数:
month
语法:month (string date)返回值为int
例如:hive>select month('2011-08-08');
结果:8 -
日期转天函数:
day
语法:day (string date)返回值为int
例如1:hive>select day('2011-12-08 10:03:01');
结果:8
例如2:hive>select day('2011-12-24');
结果:24 -
日期转小时函数:
hour
语法:hour (string date)返回值为int
例如:hive>select hour('2011-12-08 10:03:01');
结果:10 -
日期转分钟函数:
minute
语法:minute (string date)返回值为int
例如:hive>select minute('2011-12-08 10:03:01');
结果:3 -
日期转秒函数:
second
语法:second (string date)返回值为int
例如:hive>select second('2011-12-08 10:03:01');
结果:1 -
日期转周函数:
weekofyear
语法:weekofyear (string date)返回值为int
例如:hive>select weekofyear('2011-12-08 10:03:01');
结果:49
datediff,date_add和date_sub:
1、日期比较函数:datediff语法:datediff(string enddate,string startdate)
返回值:int
说明:返回结束日期减去开始日期的天数。
例如:
hive> select datediff('2019-10-13','2019-10-03');
OK
10
月数时间差:select months_between('1997-02-28', '1996-1-30'); --12.93548387
其他方式:先转换为时间戳格式再求时间差
# 将两个字段转换为为毫秒类型时间戳,相减,再转换为2019-06-23 00:00:00 这种形式并取两位小数点,如果时间差单位为天的话则除以3600*24 如果时间差单位是小时的话则除以3600
示例:时间格式为2019-06-23 00:00:00
计算天数时间差:
select round(((unix_timestamp('2019-06-23 00:00:00') - unix_timestamp('2019-06-22 00:00:00') ) / (3600*24)),2); --1.0
计算小时时间差:
select round(((unix_timestamp('2019-06-23 00:00:00') - unix_timestamp('2019-06-22 00:00:00') ) / (3600)),2); --24.0
计算分钟时间差:
select round(((unix_timestamp('2019-06-23 00:00:00') - unix_timestamp('2019-06-22 00:00:00') ) / 60),2); --1440.0
计算秒时间差:
select round((unix_timestamp('2019-06-23 00:00:00') - unix_timestamp('2019-06-22 00:00:00') ),2); --86400
2、日期增加函数:date_add语法:date_add(string startdate, intdays)
返回值:String
说明:返回开始日期startdate增加days天后的日期
例如:
hive> select date_add('2019-10-13',10);
OK
2019-10-23
3、日期减少函数:date_sub语法: date_sub (string startdate,int days)
返回值:String
说明:返回开始日期startdate减少days天后的日期
例如:
hive> select date_sub('2019-10-13',10);
OK
2019-10-03
时间函数应用获取当前时间:
参考:hive时间函数应用获取当前时间
1. 获取当前时间:yyyy-MM-dd HH:mm:ss.S
select current_timestamp;
结果1:2021-08-17 14:11:43.61
结果2:2021-08-17 14:11:43.499
select date_format(current_timestamp,'yyyy-MM-dd HH:mm:ss') ;
结果:2021-08-17 14:11:43
select substr(current_timestamp(),1,19);
结果:2021-08-17 14:11:43
注:网上还有一种写法是select from_unixtime(unix_timestamp(),"yyyy-MM-dd HH:mm:ss");但我的结果却和上面的相差8小时,在hive版本2.1.1的时候结果正常,但到3.1.0的时候就会相差8小时。并且在3.1.0版本查询时有显示“unix_timestamp(void) is deprecated.Use current_timestamp instead.”。参考:https://blog.csdn.net/tototuzuoquan/article/details/113518186
2. 获取当前时间:yyyy-mm-dd
SELECT CURRENT_DATE;
结果:2021-08-17
3. 获取当月第一天时间:yyyy-mm-dd
select date_sub(current_date,dayofmonth(current_date)-1);
结果:2021-08-01
4. 获取下个月第一天时间:yyyy-mm-dd
select add_months(date_sub(current_date,dayofmonth(current_date)-1),1);
结果:2021-09-01
5. 获取当月第几天:yyyy-mm-dd
select dayofmonth(current_date);
结果:17
6. 获取当前日期所在月月末日期:yyyy-mm-dd
select last_day(current_date);
结果:2021-08-31
7. 获取当前日期本周一:yyyy-mm-dd
select date_sub(next_day(CURRENT_DATE,'MO'),7);
结果:2021-08-16
8. 获取当前日期上周一:yyyy-mm-dd
select date_sub(next_day(CURRENT_DATE,'MO'),14);
结果:2021-08-09
9. 获取当前日期上周日:yyyy-mm-dd
select date_sub(next_day(CURRENT_DATE,'MO'),8);
结果:2021-08-15
10. 获取当前日期本周二:yyyy-mm-dd(获取其他周几调整最后参数)
select date_sub(next_day(CURRENT_DATE,'MO'),6);
结果:2021-08-17
11. 获取当前日期上周二:yyyy-mm-dd(获取其他周几调整最后参数)
select date_sub(next_day(CURRENT_DATE,'MO'),13) ;
结果:2021-08-10
12. 获取当前时间的前/后几个月时间:yyyy-mm-dd(调整最后参数)
select add_months(CURRENT_DATE,-3);
结果:2021-05-17
13. 获取上季度初日期=(quarter方法hive不支持需通过其他方式)
select add_months(concat(year(CURRENT_DATE),'-',substr(concat('0',floor((month(CURRENT_DATE)+2)/3)*3+1),-2),'-01'),-6);
结果:2021-04-01
14. 获取本季度初日期=(quarter方法hive不支持需通过其他方式)
select add_months(concat(year(CURRENT_DATE),'-',substr(concat('0',floor((month(CURRENT_DATE)+2)/3)*3+1),-2),'-01'),-3);
结果:2021-07-01
15. 取上个季度同今天时间
select add_months(CURRENT_DATE,-3);
结果:2021-05-17
16. 去年本季度开始时间
select add_months(concat(year(CURRENT_DATE),'-',substr(concat('0',floor((month(CURRENT_DATE)+2)/3)*3+1),-2),'-01'),-15);
结果:2020-07-01
17. 去年本季度结束时间
select add_months(CURRENT_DATE,-12);
结果:2020-08-17
mysql到hive数据类型转换:
mysql和hive中的数据类型存在差异,在mysql集成数据到hive中这样的场景下,我们希望在hive中的数据是贴源的,所以在hive中希望创建和mysql结构一致的表。mysql到hive数据类型映射参考如下:
| mysql数据类型 | hive数据类型 | |
|---|---|---|
| 整型 | bigint | BIGINT |
| 整型 | int | BIGINT |
| 整型 | smalint | BIGINT |
| 整型 | tinyint | BIGINT |
| 浮点型 | decimal | DECIMAL |
| 浮点型 | double | DOUBLE |
| 浮点型 | float | DOUBLE |
| 二进制 | binary | BINARY |
| 二进制 | varbinary | BINARY |
| 字符 | char | STRING |
| 字符 | varchar | STRING |
| 字符 | mediumtext | STRING |
| 字符 | text | STRING |
| 字符 | longtext | STRING |
| 时间 | datetime | STRING |
| 时间 | time | STRING |
| 时间 | timestamp | STRING |
| 时间 | date | DATE |
| json | json | MAP |
参考:mysql到hive数据类型转换、Hive之数据类型
Hbase表映射Hive表三种方法:
官方文档:https://cwiki.apache.org/confluence/display/Hive/HBaseIntegration
| Hbase表 | Hive表 | 映射方法 |
|---|---|---|
| index1 | hbase_table1 | 列映射(单列) |
| index1 | hbase_table2 | 列映射(多列) |
| index1 | hbase_table3 | 列族映射 |
index1表结构:

逻辑关系:
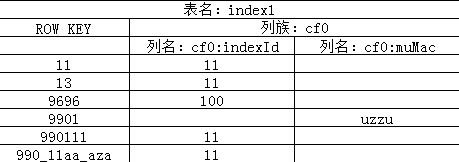
注:如果hbase不存在相应的表则hive创建映射表时hbase中也会自动创建相应的表。
1.列映射(单列):
Hive建表语句:
CREATE EXTERNAL TABLE hbase_table_1(key string, value string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES("hbase.columns.mapping" = "cf0:indexId")
TBLPROPERTIES("hbase.table.name" = "index1", "hbase.mapred.output.outputtable" = "index1");
在Hive库中创建一个hbase_table_1表,列名为key、value
映射Hbase库中的index1表的cf0:indexId列
key、value为hive表的列名可修改
string为该字段的字符类型可修改
hive库中的表:
hive> show tables;
OK
hbase_table_1
Time taken: 0.03 seconds, Fetched: 1 row(s)
hive> select * from hbase_table_1;
11 11
13 11
9696 100
990111 11
990_11aa_aza 11
Time taken: 1.266 seconds, Fetched: 5 row(s)
-- 第一列为rowkey的值
-- 第二列为cf0:indexId的值
-- 没有展示cf0:muMac的值
2.列映射(多列):
Hive建表语句:
CREATE EXTERNAL TABLE hbase_table_2(key int, indexId string, muMac string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = "cf0:indexId,cf0:muMac")
TBLPROPERTIES("hbase.table.name" = "index1", "hbase.mapred.output.outputtable" = "index1");
在Hive库中创建一个hbase_table_2表,列名为key、indexId、muMac
映射Hbase库中的index1表的cf0:indexId与cf0:muMac列
key、indexId、muMac为hive表的列名可修改
string为该字段的字符类型可修改
hive库中的表:
hive> show tables;
OK
hbase_table_1
hbase_table_2
Time taken: 0.02 seconds, Fetched: 2 row(s)
hive> select * from hbase_table_2;
OK
11 11 NULL
13 11 NULL
9696 100 NULL
9901 NULL uzzu
990111 11 NULL
NULL 11 NULL
Time taken: 0.144 seconds, Fetched: 6 row(s)
-- 第一列为rowkey的值
-- 第二列为cf0:indexId的值
-- 第三列为cf0:muMac的值
3.列族映射:
Hive建表语句:
CREATE EXTERNAL TABLE hbase_table_3(value map<string,string>,row_key string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = "cf0:,:key")
TBLPROPERTIES("hbase.table.name" = "index1", "hbase.mapred.output.outputtable" = "index1");
在Hive库中创建一个hbase_table_3表,列名为value map、row_key
映射Hbase库中的index1表的cf0:列名
key、indexId、muMac为hive表的列名可修改
string为该字段的字符类型可修改
hive库中的表:
hive> show tables;
OK
hbase_table_1
hbase_table_2
hbase_table_3
Time taken: 0.922 seconds, Fetched: 3 row(s)
hive> select * from hbase_table_3;
{"indexId":"11"} 11
{"indexId":"11"} 13
{"indexId":"100"} 9696
{"muMac":"uzzu"} 9901
{"indexId":"11"} 990111
{"indexId":"11"} 990_11aa_aza
Time taken: 1.469 seconds, Fetched: 6 row(s)
-- 第一列为键值对
-- 第二列为rowkey的值
参考:Hbase表映射Hive表三种方法
注意1:其中key是必须加的,否则会报错:
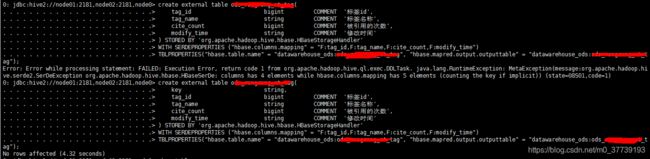
注意2:在ods层做完hbase表映射之后,编写hql语句想在dwd层使用hbase的映射表生成相应的表却报错:Caused by: org.apache.zookeeper.KeeperException$ConnectionLossException: KeeperErrorCode = ConnectionLoss for /hbase/meta-region-server

一开始跑偏的解决思路:在 hive-site 中添加 zookeeper.znode.parent 参数后重启hive
注:不同的环境,此默认值不一样,CDH是/hbase,HDP是/hbase-unsecure。
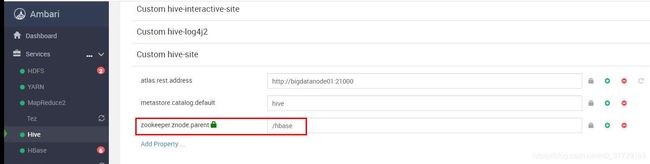
最终解决方法:在 hive-site 中添加 hbase.zookeeper.quorum 参数后重启hive。参考:解决HBase整合Hive时一直连接地址为localhost2181的zookeeper的问题
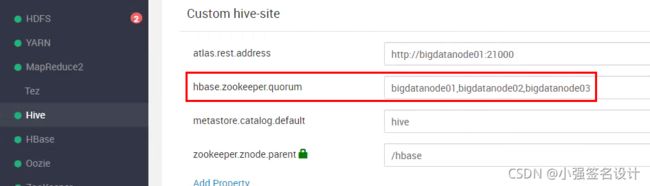
问题剖析:目前公司有两套集群,测试环境为三台服务器,zookeeper的server在这三台机器上都有安装,并且同样的场景执行相同的SQL语句并没有出现该问题。正式环境有10台服务器,zookeeper的server也装在了其中三台服务器中,而且在正式环境中执行同一语句有时候可以成功有时候却报上面截图的那个错误很是奇怪,后来查看yarn的日志发现当最后在装有zookeeper server的机器上就可以成功,而在其他七台机器上会失败而且日志中会报拒绝连接Session 0x0 for server null, unexpected error, closing socket connection and attempting reconnect java.net.ConnectException: Connection refused,而且看日志发现当在其他7台机器上会去连本地的zookeeper最终导致任务失败,于是我就想能不能让他们都连装有zookeeper server的三台机器上呐,最终搜索发现在hive中配置hbase.zookeeper.quorum可以解决该问题。
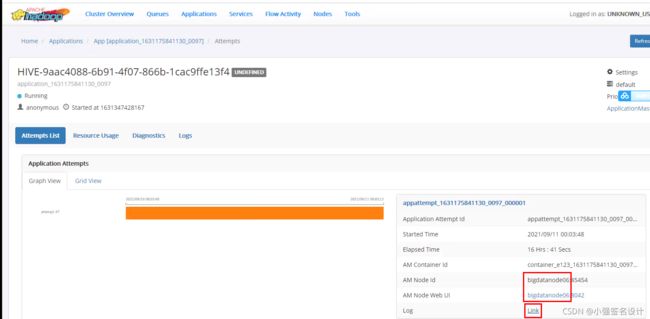

修改参数后的日志截图:

创建日期维度表:
在Hive数仓中创建一张时间跨度为2004-01-01到2021-08-31的时间维度表:
SELECT
row_number() over(order by `date`) as id,
date_ds,
`date` day,
substr(`date`, 0, 7) month,
substr(`date`, 0, 4) year
FROM (
SELECT
`date`,
regexp_replace(`date`, '-', '') as date_ds
FROM (
SELECT date_add(`start_date`,pos) AS `date`
from (
SELECT '2004-01-01' `start_date`
) t
lateral view posexplode(split(repeat(", ", 6452), ",")) tf AS pos,val -- 6452为时间跨度
) dates
) dates_expanded;
优化:
参考:使用Hive SQL创建日期维度表
注意:这篇文章中的theMonday再计算CAST((day(theMonday) - 1) / 7 + 1 AS BIGINT) as week_of_month的逻辑不对,比如2004年1月1号、2号、3号取本周一29号再算的话是本月的第5个周,而实际是本月的第1个周。
| 列 | 类型 | Comment | 计算逻辑(用于需求沟通) |
|---|---|---|---|
| date | string | 标准日期格式 | 2020-01-01 |
| date_ds | string | ds日期格式 | 20200101 |
| year | string | 年份 | 2020 |
| month | string | 月份 | 01 |
| day | string | 日期 | 01 |
| day_of_week | bigint | 星期几【1-7】 | |
| week_of_year | bigint | 本年度第几周 | 1. 以本年度第一个周一开始计算 2. 本年度前几日如属于上一年度的最后一周,则与上一年度最后一周的序号相同 |
| week_of_month | bigint | 本月第几周 | 与weekOfYear类似 |
SELECT
`date`,
date_ds,
year,
month,
day,
day_of_week,
weekofyear(`date`) as week_of_year,
from_unixtime(unix_timestamp(`date`, 'yyyy-MM-dd'), 'W') as week_of_month
FROM (
SELECT
`date`,
regexp_replace(`date`, '-', '') as date_ds,
year(`date`) as year,
month(`date`) as month,
day(`date`) as day,
-- 版本支持date_format,可以使用: date_format(`date`, 'u') as day_of_week
from_unixtime(unix_timestamp(`date`, 'yyyy-MM-dd'), 'u') as day_of_week
FROM (
SELECT date_add(`start_date`,pos) AS `date`
from (
SELECT '2004-01-01' `start_date`
) t
lateral view posexplode(split(repeat(', ', 10), ',')) tf AS pos,val -- 10为时间跨度
) dates
) dates_expanded
SORT BY `date`
;

注:我是用的hive版本为Apache Hive (version 3.1.0.3.1.4.0-315)
show functions:
hive的UDF还是很强大的,可以多show functions,学习了解各种hive function。
# 我这里hive的版本是3.1.0
hive> show functions;
+------------------------------+
| tab_name |
+------------------------------+
| ! |
| != |
| $sum0 |
| % |
| & |
| * |
| + |
| - |
| / |
| < |
| <= |
| <=> |
| <> |
| = |
| == |
| > |
| >= |
| ^ |
| abs |
| acos |
| add_months |
| aes_decrypt |
| aes_encrypt |
| and |
| array |
| array_contains |
| ascii |
| asin |
| assert_true |
| assert_true_oom |
| atan |
| avg |
| base64 |
| between |
| bin |
| bloom_filter |
| bround |
| bucket_number |
| cardinality_violation |
| case |
| cbrt |
| ceil |
| ceiling |
| char_length |
| character_length |
| chr |
| coalesce |
| collect_list |
| collect_set |
| compute_stats |
| concat |
| concat_ws |
| context_ngrams |
| conv |
| corr |
| cos |
| count |
| covar_pop |
| covar_samp |
| crc32 |
| create_union |
| cume_dist |
| current_authorizer |
| current_database |
| current_date |
| current_groups |
| current_timestamp |
| current_user |
| date_add |
| date_format |
| date_sub |
| datediff |
| day |
| dayofmonth |
| dayofweek |
| decode |
| degrees |
| dense_rank |
| div |
| e |
| elt |
| encode |
| enforce_constraint |
| exp |
| explode |
| extract_union |
| factorial |
| field |
| find_in_set |
| first_value |
| floor |
| floor_day |
| floor_hour |
| floor_minute |
| floor_month |
| floor_quarter |
| floor_second |
| floor_week |
| floor_year |
| format_number |
+------------------------------+
| tab_name |
+------------------------------+
| from_unixtime |
| from_utc_timestamp |
| get_json_object |
| get_splits |
| greatest |
| grouping |
| hash |
| hex |
| histogram_numeric |
| hour |
| if |
| in |
| in_bloom_filter |
| in_file |
| index |
| initcap |
| inline |
| instr |
| internal_interval |
| isfalse |
| isnotfalse |
| isnotnull |
| isnottrue |
| isnull |
| istrue |
| java_method |
| json_tuple |
| lag |
| last_day |
| last_value |
| lcase |
| lead |
| least |
| length |
| levenshtein |
| like |
| likeall |
| likeany |
| ln |
| locate |
| log |
| log10 |
| log2 |
| logged_in_user |
| lower |
| lpad |
| ltrim |
| map |
| map_keys |
| map_values |
| mask |
| mask_first_n |
| mask_hash |
| mask_last_n |
| mask_show_first_n |
| mask_show_last_n |
| matchpath |
| max |
| md5 |
| min |
| minute |
| mod |
| month |
| months_between |
| murmur_hash |
| named_struct |
| negative |
| next_day |
| ngrams |
| noop |
| noopstreaming |
| noopwithmap |
| noopwithmapstreaming |
| not |
| ntile |
| nullif |
| nvl |
| octet_length |
| or |
| parse_url |
| parse_url_tuple |
| percent_rank |
| percentile |
| percentile_approx |
| pi |
| pmod |
| posexplode |
| positive |
| pow |
| power |
| printf |
| quarter |
| radians |
| rand |
| rank |
| reflect |
| reflect2 |
| regexp |
| regexp_extract |
| regexp_replace |
+------------------------------+
| tab_name |
+------------------------------+
| regr_avgx |
| regr_avgy |
| regr_count |
| regr_intercept |
| regr_r2 |
| regr_slope |
| regr_sxx |
| regr_sxy |
| regr_syy |
| repeat |
| replace |
| replicate_rows |
| restrict_information_schema |
| reverse |
| rlike |
| round |
| row_number |
| rpad |
| rtrim |
| second |
| sentences |
| sha |
| sha1 |
| sha2 |
| shiftleft |
| shiftright |
| shiftrightunsigned |
| sign |
| sin |
| size |
| sort_array |
| sort_array_by |
| soundex |
| space |
| split |
| sq_count_check |
| sqrt |
| stack |
| std |
| stddev |
| stddev_pop |
| stddev_samp |
| str_to_map |
| struct |
| substr |
| substring |
| substring_index |
| sum |
| surrogate_key |
| tan |
| to_date |
| to_epoch_milli |
| to_unix_timestamp |
| to_utc_timestamp |
| translate |
| trim |
| trunc |
| tumbling_window |
| ucase |
| udftoboolean |
| udftobyte |
| udftodouble |
| udftofloat |
| udftointeger |
| udftolong |
| udftoshort |
| unbase64 |
| unhex |
| unix_timestamp |
| upper |
| uuid |
| var_pop |
| var_samp |
| variance |
| version |
| weekofyear |
| when |
| width_bucket |
| windowingtablefunction |
| xpath |
| xpath_boolean |
| xpath_double |
| xpath_float |
| xpath_int |
| xpath_long |
| xpath_number |
| xpath_short |
| xpath_string |
| year |
| | |
| ~ |
+------------------------------+
291 rows selected (0.056 seconds)