Ekar : Explainable Knowledge Graph-based Recommendation via Deep Reinforcement Learning解析
Ekar : Explainable Knowledge Graph-based Recommendation via Deep Reinforcement Learning解析
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- Ekar : Explainable Knowledge Graph-based Recommendation via Deep Reinforcement Learning解析
- 一、前言
-
- 1. 本文的研究点:
- 2. 方法的关键点
- 二、方法介绍
-
-
- 1. 马尔科夫决策过程
- 2.策略网络
- 3. 奖励增强
- 4. 网络优化
-
一、前言
1. 本文的研究点:
- 解决知识图谱的可解释性较低的问题;
- 希望生成如图所示的一条路径,这条路径能够解释为什么推荐这个项目;
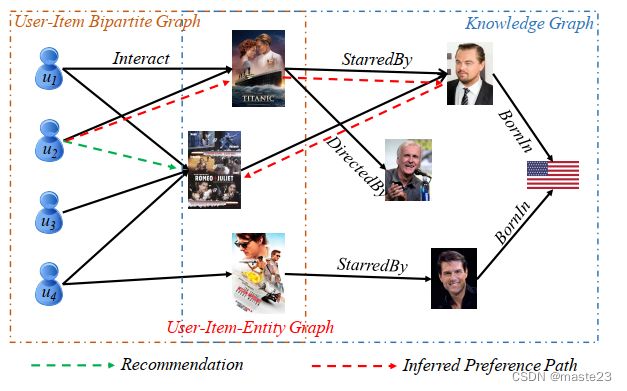
在图片中,这条路径是用户–看过–>泰坦尼克号–主演–>小李子–主演–>罗密欧和朱丽叶。
2. 方法的关键点
- 推荐Agent从目标用户开始,通过依次选择用户-项目-实体图上的行走,将其路径扩展到相关项目。在训练过程中,如果起始用户和终端实体恰巧是推荐数据中存在的一次用户与项目之间的交互,我们就给这条路径分配一个正的奖励。
- 考虑到由于巨大的探索空间,奖励在开始时可能是非常稀疏的,我们通过reward shaping[17]进一步增强奖励信号,其中软奖励函数首先使用最先进的知识图嵌入方法学习。
- 我们使用REINFORCE[29]算法来最大化 我们的推荐代理的预期奖励。
二、方法介绍
这里的介绍是按照马尔科夫决策过程进行的。
1. 马尔科夫决策过程
States : s t = ( r 0 , e 0 , r 1 , e 1 , . . . r t , e t ) ∈ S t s_t = (r_0, e_0, r_1, e_1, ... r_t, e_t) \in \mathcal{S}_t st=(r0,e0,r1,e1,...rt,et)∈St, r t ∈ R ′ r_t \in \mathcal{R}^{\prime} rt∈R′和 e t ∈ V ′ e_t\in \mathcal{V}^{\prime} et∈V′ 。初始化的状态 s 0 = ( r 0 , e 0 ) s_0 = (r_0, e_0) s0=(r0,e0)代表着开始的目标用户, r 0 r_0 r0是人工引进的边。 R ′ \mathcal{R}^{\prime} R′ 是边的集合,其中包括知识图谱中的边和用户项目交互关系, V ′ \mathcal{V}^{\prime} V′包括知识图谱中的实体和用户、项目节点。
Actions :当实体处于状态 s t s_t st,动作是当前所处实体的出节点集合,具体而言,对于状态 s t s_t st而言,实体空间是 A t = { a = ( r ′ , e ′ ) ∣ ( e t , r ′ , e ′ ) ∈ G ′ } \mathcal{A}_t=\{a=(r^{\prime}, e^{\prime}) | (e_t, r^{\prime}, e^{\prime}) \in \mathcal{G}^{\prime} \} At={a=(r′,e′)∣(et,r′,e′)∈G′}
Transition : 如果下一步的行动被设定为 a t = ( r t + 1 , e t + 1 ) a_t=(r_{t+1},e_{t+1}) at=(rt+1,et+1)则下一步的状态 s t + 1 = { r 0 , e 0 , . . . r t , e t , r t + 1 , e t + 1 } s_{t+1}=\{ r_0, e_0, ... r_t, e_t, r_{t+1}, e_{t+1} \} st+1={r0,e0,...rt,et,rt+1,et+1}。
Rewards : 给定终点状态 e T e_T eT, R T = 1 R_T=1 RT=1如果项目是用户交互过的项目,为0如果不是用户交互过的项目,为-1如果不是项目类别。

2.策略网络
基于LSTM对当前的状态进行编码:
s 0 = L S T M ( 0 , [ r 0 ; e 0 ] ) \mathbf{s}_0=LSTM(\mathbf{0}, [\mathbf{r}_0; \mathbf{e}_0]) s0=LSTM(0,[r0;e0])
s t = L S T M ( s t − 1 , [ r t ; e t ] ) \mathbf{s}_t=LSTM(\mathbf{s}_{t-1}, [\mathbf{r}_t;\mathbf{e}_t]) st=LSTM(st−1,[rt;et])
基于MLP预测每个项目的交互概率:
y t = W 2 R e L U ( W 1 s t + b 1 ) + b 2 \mathbf{y}_t = \mathbf{W}_2ReLU(\mathbf{W}_1\mathbf{s}_t+\mathbf{b}_1)+\mathbf{b}_2 yt=W2ReLU(W1st+b1)+b2
采取行为 a ′ a^{\prime} a′的概率是:
π ( a ′ ∣ s t ) = s o f t m a x ( a ′ y t ) \pi(a^{\prime}|s_t)=softmax(\mathbf{a}^{\prime}\mathbf{y}_t) π(a′∣st)=softmax(a′yt)
3. 奖励增强
R T = { 1 , if e T ∈ I and < e 0 , r ˉ , e T > ∈ G ′ , σ ( ψ ( e 0 , r ˉ , e T ) ) , if e T ∈ I and < e 0 , r ˉ , e T > ∉ G ′ , − 1 , otherwise, R_T= \begin{cases}1, & \text { if } e_T \in \mathcal{I} \text { and }
其中, σ \sigma σ是sigmoid激活函数, ψ ( e 0 , r ˉ , e T ) = − ∣ ∣ e 0 + r ˉ − e T ∣ ∣ \psi ({e_0},\bar r,{e_T}) = - ||{e_0} + \bar r - {e_T}|| ψ(e0,rˉ,eT)=−∣∣e0+rˉ−eT∣∣。
4. 网络优化
基于Reinforce方法进行优化:
J ( θ ) = E e 0 ∈ U [ E a 1 , a 2 , … , a T ∼ π θ ( a t ∣ s t ) [ R T ] ] ; J(\theta)=\mathbb{E}_{e_0 \in \mathcal{U}}\left[\mathbb{E}_{a_1, a_2, \ldots, a_T \sim \pi_\theta\left(a_t \mid s_t\right)}\left[R_T\right]\right]; J(θ)=Ee0∈U[Ea1,a2,…,aT∼πθ(at∣st)[RT]];
∇ θ J ( θ ) ≈ ∇ θ ∑ t R T log π θ ( a t ∣ s t ) \nabla_\theta J(\theta) \approx \nabla_\theta \sum_t R_T \log \pi_\theta\left(a_t \mid s_t\right) ∇θJ(θ)≈∇θt∑RTlogπθ(at∣st)