笔记:python spark机器学习与hadoop大数据
目录
1.1机器学习的介绍
机器学习架构
1.2Spark的介绍
1.3Spark数据处理RDD、DataFrame、Spark SQl
1.4使用python开发spark机器学习与大数据应用
1.5python spark机器学习
1.6大数据定义
JAVA-JDK在Linux的下载和安装
1.1机器学习的介绍
机器学习技术不断进步, 应用相当广泛, 例如推荐引擎、 定向广告、需求预测、垃圾邮件过滤、 医学诊断、 自然语言处理、 搜索引擎、 欺诈检测、 证券分析、 视觉识别、 语音识别、 手写识别等。
机器学习架构
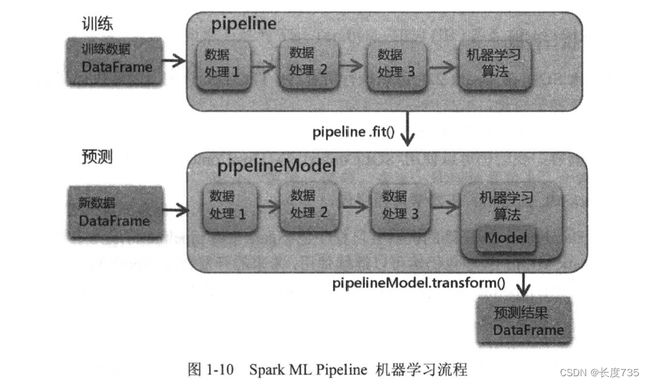
机器学习(MachineLeaming)通过算法、使用历史数据进行训练,训练完成后会产生模型。未来当有新的数据提供时,我们可以使用训练产生的模型进行预测。
机器学习训练用的数据是由Feature、Label组成的。
Feature: 数据的特征, 例如湿度、 风向、 风速、 季节、 气压。
Label: 数据的标签,也就是我们希望预测的目标,例如降雨 (0. 不会下雨、l会下雨)、 天气(1. 晴天、 2雨天、 3阴天、 4.下雪)、 气温。
机器学习可分为以下两个阶段:
1、训练阶段(Training):
训练数据是过去累积的历史数据,可能是文本文件、数据库或其他来源。经过Feature Extraction (特征提取),产生Feature(数据特征)与Label(预测目标),然后经过机器学习算法的训练后产生模型。
2、预测阶段(Predict):
新输入数据, 经过 Feature Extraction (特征提取)产生 Feature (数据特征), 使用训练完成的模型进行预测, 最后产生预测结果。
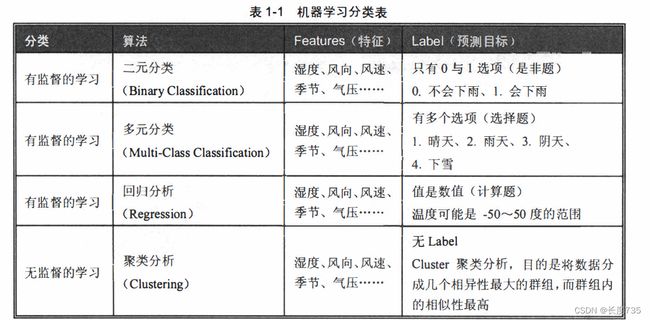
机器学习分类
有监督的学习(SupervisedLeaming), 从现有数据希望预测的答案有下列分类:
1、二元分类:
我们已知湿度、风向、风速、季节、气压等数据特征,希望预测当天是否会下雨(0. 不会下雨、1. 会下雨)。因为希望预测的目标 Label 只有 2 种选项,所以就像是非题。
2、多元分类:
我们已知湿度、风向、风速、季节、气压等数据特征,希望预测当天的天气(1. 晴天、雨天、3.阴天、4.下雪)。因为希望预测的目标Label有多个选项,所以就像选择题
3、回归分析:
已知湿度、风向、风速、季节、气压等数据特征,希望预测当天的气温。因为希望预测的目标 Label 是连续值,所以就像是计算题。
对于无监督的学习(UnsupervisedLeaming), 从现有数据我们不知道要预测的答案,所以
没有Label(预测目标)。cluster聚类分析的目的是将数据分成儿个相异性最大的群组,而群组
内的相似性最高。

机器学习程序的运行可分为下列3个阶段:数据准备阶段,训练评估阶段、预测阶段
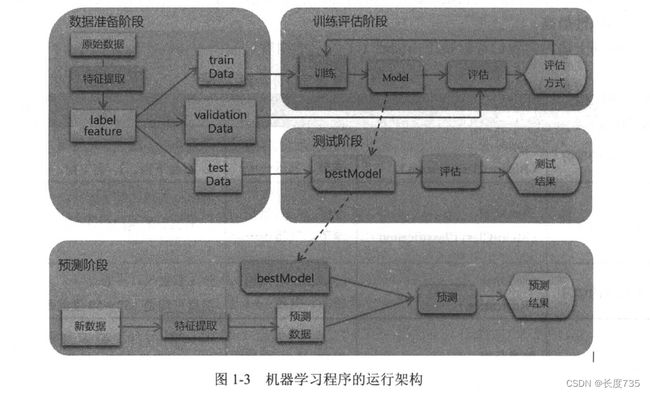
数据准备阶段
原始数据(可能是文本文件、数据库或其他来源)经过数据转换,提取特征字段与标签字
段,产生机器学习所需要的格式,然后将数据以随机方式分为3部分(trainData、validationData、
testData)并返回数据,供下阶段训练评估使用。
训练评估阶段
将使用 trainData 数据进行训练, 并产生模型, 然后使用 validationData 验证模型的准确率。这个过程要重复很多次才能够找出最佳的参数组合。评估方式:二元分类使用AUC、多元分类使用 accuracy、回归分析使用 RMSE。训练评估完成后,会产生最佳模型 bestModel。
测试阶段
之前阶段产生了最佳模型 bestModel, 我们会使用另外 组数据 testData 再次测试, 以避免 overfitting 的问题。 如果训练评估阶段准确度很高, 但是测试阶段准确度很低,代表可 能有 overfitting 的问题。如果测试与训练评估阶段的结果准确度差异不大,代表无 overfitting的问题。
预测阶段
新输入数据,经过FeatureExtraction (特征提取)产生FeatureC数据特征),使用训练完成的最佳模型bestModel进行预测,最后产生预测结果。
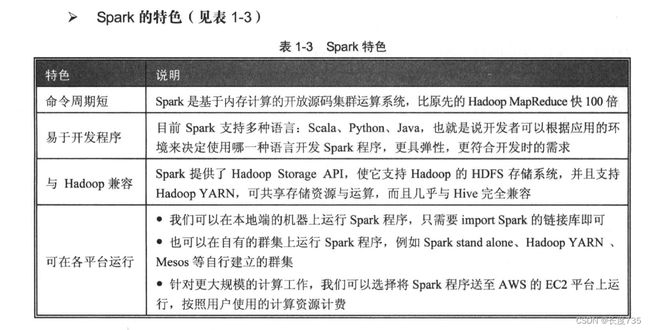
1.2Spark的介绍
ApacheSpark是开放源码的集群运算框架,由加州大学伯克利分校的AMPLab开发。Spark
是一个弹性的运算框架,适合进行Spark Streaming数据流处理、Spark SQL互动分析、MLlib
机器学习等应用,因此Spark可作为一个用途广泛的大数据运算平台。Spark 允许用户将数据
加载到cluster集群的内存中存储,并多次重复运算,非常适合用于机器学习的算法。
➢Spark RDD in-memory的计算框架
如下图所示,Spark 的核心是RDD ( Resilient Distributed Dataset)弹性分布式数据集,
是由AMPLab实验室所提出的概念,属于- -种分布式的内容。Spark主要的优势来自RDD本
身的特性,RDD能与其他系统兼容,可以导入外部存储系统的数据集,例如HDFS、HBase或
其他Hadoop数据源。

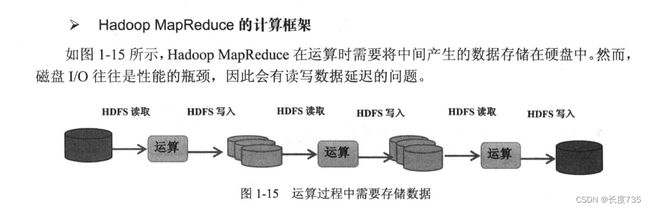
Spark 在运算时, 将中间产生的数据暂存在内存中, 因此可以加快运行速度。需要反复操
作的次数越多,所需读取的数据量越大, 就越能看出Spark 的性能。Spark 在内存中运行程序,
命令运行速度(或命令周期)比Hadoop MapReduce 的命令运行速度快100 倍, 即便是运行于
硬盘上时Spark 的速度也能快上10 倍。
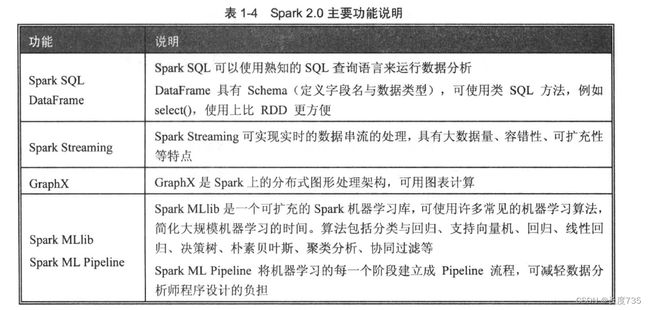
1.3Spark数据处理RDD、DataFrame、Spark SQl
Spark数据处理方式主要有3种:RDD、DataFrame、SparkSQL。
RDD、 Spark DataFrame与Spark SQL 最主要的差异在于是否定义 Schema。
RDD 的数据未定义 Schema (也就是未定义字段名及数据类型)。 使用上必须有 Map/Reduce 的概念,需要高级的程序设计能力,但是功能也最强,能完成所有 Spark功能。
• Spark DataFrame建立时必须定义Schema(也就是定义每一个字段名与数据类型), 所以DataFrame在早期版本中也称为SchemaRDD。
• Spark SQL 是由 DataFrame 衍生出来的, 我们必须先建立 DataFrame, 然后通过登录Spark SQL temp table, 就可以使用 Spark SQL 语法了。
易使用度:Spark SQL > DataFrame > ROD
使用SparkSQL最简单,只需要使用SQL语句即可。即使是非程序设计人员,只 要懂得SQL语句也可以使用。
DataFrame API有Schema,可直接指定字段名,并且定义了很多类似SQL的方法, 例如select()、groupby()、count(),我们可以使用这些方法进行统计,比RDD更易使 用。只是使用DataFrameAPI必须具有基础程序设计能力。
在使用RDD时,必须有Map/Reduce的概念,需要高级的程序设计能力,而且没有 Schema, 只能指定数据的位置,使用起来较不方便。
1.4使用python开发spark机器学习与大数据应用
Spark支持多种语言:Scala、Python、Java、R,
Scala语言是Spark的开发语言,所以与Spark兼容性最好,执行效率也最高;但 是数据分析师使用Scala的比较少,学习门槛也比Python高。
• Java 是很常用的程序设计语言, 运用很广泛;但是使用 Java 开发 Spark 程序, 相同的功能, 写出来的语句比较冗长, 而且数据分析师也不太熟悉 Java。
R语言是数据分析中很常用的语言, 数据分析师也都很熟悉, 也很容易使用, 但是目前 Spark 的 R 语言功能比较不完整, 未来 Spark 仍会持续开发以便增加 R 语言的支持。 然而R主要是数据分析语言, 不是通用的程序设计语言, 如果还需要其他功能, 例如网站整合、 网络爬虫等, 就需要使用其他的语言。
Python是数据分析很常用的程序设计语言,程序代码简明、易学习、高生产力,同 时还是面向对象、函数式的动态语言,应用非常广泛。再加上数据分析的相关模块,例如NumPy、Matplotlib、Pandas、Scikit-leam,让Python成为数据分析的主要语 言之一。Python是通用性的程序设计语言,可以用于开发大数据相关的网站、网络 爬虫等。
1.5python spark机器学习
Python是数据分析很常用的程序设计语言,程序代码简明、易学习、高生产力,同 时还是面向对象、函数式的动态语言,应用非常广泛。再加上数据分析的相关模块,例如NumPy、Matplotlib、Pandas、Scikit-leam,让Python成为数据分析的主要语 言之一。Python是通用性的程序设计语言,可以用于开发大数据相关的网站、网络 爬虫等。
1.6大数据定义
大数据 (Big data) 又称为巨量资料、 巨量数据或海量数据。 一般来说,大数据的特性可归类为 3V: Volume、 Variety 和 Velocity。
Volume (大量数据)
• 累积庞大的数据:因特网、 企业 IT、物联网、 社区、 短信、 电话、 网络搜索、 在线交易等,随时都在快速累积庞大的数据。
• 数据量等级:数据量很容易达到 TB(Terabyte, 1024 GB) 甚至 PB(Petabyte, 1024 TB) 或 EB (Exabyte , l 024 PB) 的等级。
Variety (多样性)
大数据的数据类型非常多样化, 可分为非结构化信息和结构化信息。
• 非结构化信息:文字、 图片、 图像、 视频、 音乐、 地理位置信息、 个人化信息——如社区、 交友数据等。
• 结构化信息: 数据库、 数据仓库等。
Velocity (时效性)
• 数据的传输流动:随着带宽越来越大、 设备越来越多, 每秒产生的数据流越来越大。
• 组织必须能实时处理大量的信息:时间太久就会失去数据的价值, 所以数据必须能 在最短时间内得出分析结果。

JAVA-JDK在Linux的下载和安装
在终端输入,查看当前安装的java版本
java --version

使用apt-get安装jdk
sudo apt-get install default-jdk
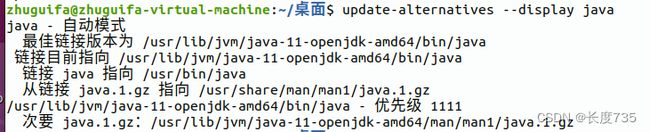
查看java安装的位置
update-alternatives --display java
设置SSH无密码登录
安装SSH
sudo apt-get install ssh
安装rsync
sudo apt-get install rsync
产生SSH key(密钥)进行后续验证
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
查看产生的密钥文件
ll ~/.ssh
将产生的key放置到许可证文件中
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
这个重定向符号">>"会将命令运行后产生的标准输出 (stdout) 重定向附加在该文件之后。
(1) 如果文件不存在, 就会先创建一个新文件,然后把标准输出 (stdout) 的内容存储在
这个文件中。
(2) 如果文件已经存在, 就会将标准输出 (stdout) 的数据附加至文件内容的后面, 而不
会覆盖原来文件的内容。
下载安装Hadoop
浏览器打开下面的网址
Index of /dist/hadoop/common
在终端输入下载2.6.4版本的hadoop
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.6.4/hadoop-2.6.4.tar.gz
下载完之后解压缩
sudo tar -zxvf hadoop-2.6.4.tar.gz.1

将默认的安装目录移动到/usr/local/hadoop
注:图片均来自书本截图,这只是一篇笔记