(CNS复现)CLAM——Chapter_00
(CNS复现)CLAM——Chapter_00
CLAM: A Deep-Learning-based Pipeline for Data Efficient and Weakly Supervised Whole-Slide-level Analysis
文章目录
- (CNS复现)CLAM——Chapter_00
- 前言
- 一、CLAM介绍
- 环境配置
- 二、官方使用步骤
-
- Step.00 : Down_Load_DataSet
- Step.01 : WSI Segmentation and Patching
- Step.02 : Feature Extraction
- Step.03 : data split
- Step.04 : training
- Step.05 : eval
- Step.06 : Heatmap Visualization
- 总结
前言
(CNS复现)CLAM——Chapter_00
(CNS复现)CLAM——Chapter_01
(CNS复现)CLAM——Chapter_02
(CNS复现)CLAM——Chapter_03
我在前两个礼拜的一篇教程中讲过,我要开始追踪这个课题组的五篇文章。但是因为一些原因导致我心态爆炸,所以这件事情就一直耽搁着。
今天打完疫苗心态有所恢复,在这摸鱼的一个月的时间里面,我对我自己的博客定位做了很深入的思考,最终得出了今后博客的定位。我的所有博客的定位就是单细胞或者深度学习相关的CNS文献复现。
不讲废话了,直接开始
一、CLAM介绍
首先我们看一下官方介绍:
CLAM: 是一种高通量且可解释的方法,可使用幻灯片级别的标签对数据进行有效的整个幻灯片图像(WSI)分类,而无需任何ROI提取或补丁级别的注释,并且能够处理多类子类型化问题。经过训练的模型在三个不同的WSI数据集上进行了测试,可适应WSI切除和活检以及智能手机显微镜图像(显微照片)的独立测试队列。
环境配置
环境配置,什么好说的了,直接跟着官方指南走就行。
这里需要注意一点就是,topk可能按指南的Code是没办法安装的,所以我是直接下载下来后,将topk文件拖到代码目录下的
官方环境配置指南:
https://github.com/mahmoodlab/CLAM/blob/master/docs/INSTALLATION.md
还好当时没有开始写教程,刚刚发现代码新增了一部分关于可视化的内容,不过好像并不影响
如果大家看过文章的话会发现,该模型的主要用途是一种病理切片的辅助诊断系统,最终的想法是要完成一种语义分割:(如果是二分类)将病灶和非病灶区域通过模型输出的注意力得分进行可视化。
这个模型最大的难点就2个:
input的数据太大- 无法对label进行标注
文章提出了一种方法来解决这两个问题——将超大图片分割成小patch然后对patch进行聚类
因此该模型的训练阶段主要是分为4个部分:
-
切割出图形的边界,去掉大部分的背景色,
-
将大图切成小图
这两个步骤全部在create_patches_fp.py 文件中进行
- 对每一张大图进行特征提取
该步骤在extract_features_fp.py中执行
- 模型训练
该步骤在main.py中执行
对于复现的话主要分为两个部分:
- 根据官方信息跑一边
- 解读重要的数据预处理流程:关于代码的执行步骤不可能每个都讲,基本只讲我认为重要的(或者我不懂的然后查懂的,关于没查懂的也会做批注方便后续回来看),因此与其说是教程,更确确切的应该是我自己的实验记录
对于CLAM这个算法,官方给出了两个版本。分别针对不同的数据类型:
- 针对
病灶 / 非病灶的二分类任务 - 针对
多种病灶或非病灶的多分类模型
本系列主要针对二分类,多分类道理相通
二、官方使用步骤
Step.00 : Down_Load_DataSet
官方给出了 3 个数据下载源:

这里的话我是选择 cpat 数据源,一共要下载两个数据一个是 cohort.csv 文件,还有一个是 svs 文件
因为电脑带不动太大的数据,所以选择了 LSCC 和 LUAD 这两套数据
将硬盘中的数据移动到工作目录
# 多线程文件复制
import os
import shutil
import multiprocessing
target_file = ['/media/yuansh/lexar/LUAD/','/media/yuansh/lexar/LSCC/']
destination_file = ['/media/yuansh/14THHD/CLAM/DataSet/LUAD/','/media/yuansh/14THHD/CLAM/DataSet/LSCC/']
def CopyJPG(A,B):
shutil.copy(A, B) # from A to B
for file_path in (0,2):
print(file_path)
# 需要移动的目标目录
if not os.path.exists(destination_file[file_path]):
os.makedirs(destination_file[file_path])
# 文件地址,获取文件
file_id = os.listdir(target_file[file_path])
args_list = [
(target_file[file_path] + file_id[i],
destination_file[file_path] + file_id[i]) for i in range(len(file_id))
]
p = multiprocessing.Pool(32)
p.starmap(CopyJPG, args_list)
p.close() # 记得关闭
p.join()
数据源如下:
其中,
CLAM_Code是从github上下载的所有代码DataSet是刚刚下载下来的两个文件
为了加快后续的分析,我随机挑选了几个样本构成 toy_example
到该步骤,前期准备就绪开始跑流程
Step.01 : WSI Segmentation and Patching
# Step_1 get patch
# source svs文件地址
# 输出文件 save_dir
python create_patches_fp.py \
--source /media/yuansh/14THHD/CLAM/DataSet/toy_example \
--save_dir /media/yuansh/14THHD/CLAM/toy_test \
--patch_size 256 \
--seg \
--patch \
--stitch
这一步骤,一共生成4个文件,具体如下:

其中,
mask文件中储存的image代表过滤掉的前景可视化patches是将mask中被框起来的部分的分割,将超巨大的图片分割为256*256的小patch,这些小 patch 被认为是原始 image 的特在图stitches没用process_list_autogen.csv这里记录了每张 image 的处理的参数
Step.02 : Feature Extraction
在跑官方代码的时候,要先生成 CSV 文件,文件内容如下:

import os
import pandas as pd
df = pd.read_csv('/media/yuansh/14THHD/CLAM/toy_test/process_list_autogen.csv') # 这个是上一步生成的文件
ids1 = [i[:-4] for i in df.slide_id]
ids2 = [i[:-3] for i in os.listdir('toy_test/patches/')]
df['slide_id'] = ids1
ids = df['slide_id'].isin(ids2)
sum(ids)
df.loc[ids].to_csv('/media/yuansh/14THHD/CLAM/Step_2.csv',index=False)
# Step_2 get patch features
# data_h5_dir 输出文件地址
# data_slide_dir svs文件地址
# 上一步生成的csv csv_path
# feat_dir 输出文件地址
CUDA_VISIBLE_DEVICES=0 python extract_features_fp.py \
--data_h5_dir /media/yuansh/14THHD/CLAM/toy_test \
--data_slide_dir /media/yuansh/14THHD/CLAM/DataSet/toy_example \
--csv_path /media/yuansh/14THHD/CLAM/Step_2.csv \
--feat_dir /media/yuansh/14THHD/CLAM/FEATURES_DIRECTORY \
--batch_size 512 \
--slide_ext .svs
输出的文件是 /media/yuansh/14THHD/CLAM/FEATURES_DIRECTORY ,文件形式大致如下:
FEATURES_DIRECTORY/
├── h5_files
├── slide_1.h5
├── slide_2.h5
└── ...
└── pt_files
├── slide_1.pt
├── slide_2.pt
└── ...
但是,这种层级结构是不能满足后续的输入需求的。所以要新建一个名为 tumor_vs_normal_resnet_features 的文件夹,将这两个文件放入该文件夹中。最后的层级结构应该如下:
DATA_ROOT_DIR/
├──tumor_vs_normal_resnet_features/
├── h5_files
├── slide_1.h5
├── slide_2.h5
└── ...
└── pt_files
├── slide_1.pt
├── slide_2.pt
└── .. .
Step.03 : data split
与步骤2相同,步骤三执行前要先生成 CSV 文件,文件内容如下:
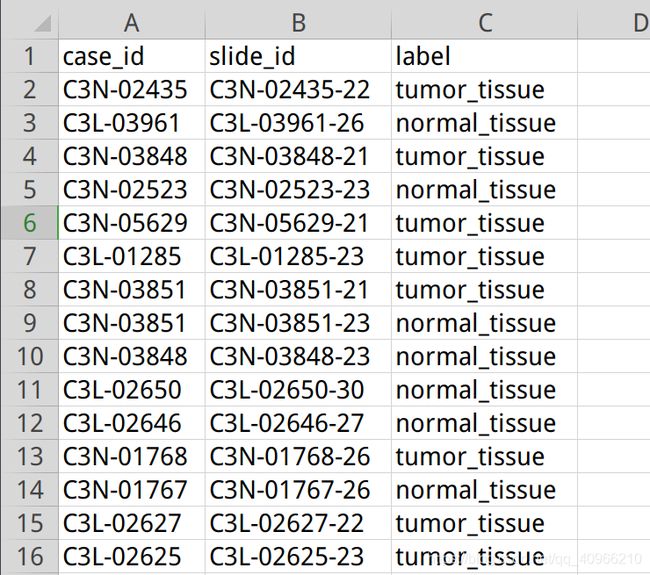
其中第一列为case_id,这个要使用之前下载的cohort.csv文件获取,生成Step.03所需要的csv文件代码如下:
import os
import pandas as pd
df = pd.read_csv('/media/yuansh/14THHD/CLAM/DataSet/cohort.csv')
df = df[['Case_ID','Slide_ID','Specimen_Type']]
ids1 = [i for i in df.Slide_ID]
ids2 = [i[:-3] for i in os.listdir('toy_test/patches/')]
ids = df['Slide_ID'].isin(ids2)
sum(ids)
df = df.loc[ids]
df.columns = ['case_id','slide_id','label']
df.to_csv('/media/yuansh/14THHD/CLAM/Step_3.csv',index=False)
在跑代码的时候我们需要打开 create_splits_seq.py 文件,并找到如下位置修改:
找到csv_path 修改为自己的csv即可
if args.task == 'task_1_tumor_vs_normal':
args.n_classes=2
dataset = Generic_WSI_Classification_Dataset(csv_path = '/media/yuansh/14THHD/CLAM/Step_3.csv',
shuffle = False,
seed = args.seed,
print_info = True,
label_dict = {'normal_tissue':0, 'tumor_tissue':1},
patient_strat=True,
ignore=[])
python create_splits_seq.py \
--task task_1_tumor_vs_normal \
--seed 1 \
--label_frac 0.75 \
--k 10
执行这一步骤后,会在工作目录下生成 splits 文件,该文件中储存所有的输出对象
Step.04 : training
同样,打开 main.py 文件,找到并做如下修改
if args.task == 'task_1_tumor_vs_normal':
args.n_classes=2
dataset = Generic_MIL_Dataset(csv_path = '/media/yuansh/14THHD/CLAM/Step_3.csv',
data_dir= os.path.join(args.data_root_dir, 'tumor_vs_normal_resnet_features'),
shuffle = False,
seed = args.seed,
print_info = True,
label_dict = {'normal_tissue':0, 'tumor_tissue':1},
patient_strat=False,label_col = 'label',
ignore=[])
CUDA_VISIBLE_DEVICES=0 python main.py \
--drop_out \
--early_stopping \
--lr 2e-4 \
--k 10 \
--label_frac 0.75 \
--exp_code task_1_tumor_vs_normal_CLAM_50 \
--weighted_sample \
--bag_loss ce \
--inst_loss svm \
--task task_1_tumor_vs_normal \
--model_type clam_sb \
--log_data \
--data_root_dir /media/yuansh/14THHD/CLAM/FEATURES_DIRECTORY
Step.05 : eval
这个步骤和 train 是完全一样的
CUDA_VISIBLE_DEVICES=0 python eval.py \
--drop_out \
--k 10 \
--models_exp_code task_1_tumor_vs_normal_CLAM_50_s1 \
--save_exp_code task_1_tumor_vs_normal_CLAM_50_s1_cv \
--task task_1_tumor_vs_normal \
--model_type clam_sb \
--results_dir results \
--data_root_dir /media/yuansh/14THHD/CLAM/FEATURES_DIRECTORY
Step.06 : Heatmap Visualization
在执行这个步骤的时候要对配置文件和模型参数做一下修改,具体修改如下:
打开 / heatmaps /configs/config_template.yaml 文件,找到如下几个位置并做修改即可
# 这个csv文件只有两列,第一列是要处理的数据的slide_id以及所对应的label
process_list: heatmap_demo_dataset.csv
# 图片处理参数,这个就是第一步输出的文件扣掉前三列,然后取出第一行即可
preset: presets/bwh_biopsy.csv
# 根据自己的实际情况修改
label_dict:
LUAD: 0
LSCC: 1
# 把train输出的参数结果放入该文件夹中,并把需要可视化的文件放入该文件夹同级的 slides 文件夹下
ckpt_path: heatmaps/demo/ckpts/s_9_checkpoint.pt
然后运行即可
CUDA_VISIBLE_DEVICES=0 python create_heatmaps.py --config config_template.yaml
最终可视化结果如图:


总结
官方基本流程运行完毕,这一篇是复现细节的必要途径。接下来的几篇主要针对Step1-4展开深度的解析,主要是为了让我自己清楚他怎么做的数据处理,和思考他为什么这么做。
如果我的博客您经过深度思考后仍然看不懂,可以根据以下方式联系我:
Best Regards,
Yuan.SH
---------------------------------------
School of Basic Medical Sciences,
Fujian Medical University,
Fuzhou, Fujian, China.
please contact with me via the following ways:
(a) e-mail :yuansh3354@163.com