Datawhale 7月学习——李弘毅深度学习:回归
前情回顾
- 机器学习简介
1 回归模型
1.1 回归的概念及例子
回归(Regression)的意思就是找到一个函数 f u n c t i o n function function ,通过输入特征 x x x,输出一个数值 S c a l a r Scalar Scalar。
李宏毅老师在这里列举了几个回归模型的例子:
- 股市预测(Stock market forecast)
- 输入:过去10年股票的变动、新闻咨询、公司并购咨询等
- 输出:预测股市明天的平均值- 自动驾驶(Self-driving Car)
- 输入:无人车上的各个sensor的数据,例如路况、测出的车距等
- 输出:方向盘的角度- 商品推荐(Recommendation)
- 输入:商品A的特性,商品B的特性
- 输出:购买商品B的可能性- Pokemon精灵攻击力预测(Combat Power of a pokemon)
- 输入:进化前的CP值、物种(Bulbasaur)、血量(HP)、重量(Weight)、高度(Height)
- 输出:进化后的CP值
1.2 回归模型的实现
回归模型的步骤主要分为几步
- step1:模型假设,选择模型框架(模型种类)
- step2:模型评估,如何判断众多模型的好坏(损失函数)
- step3:模型优化,如何筛选最优的模型(优化求解)
对应到本次课程具体指
- step1:模型假设-线性模型
- step2:模型评估-损失函数
- step3:模型优化-梯度下降
通俗理解的话,就是在一系列的模型中,去找到一个预测结果最好(误差最小)的模型。这个寻找过程,是先确定一个模型的形式(同时确定模型参数),然后确定衡量误差的方式(模型预测结果与真实标签间的差距),在求解中,采用合适的优化方法根据误差不断调整模型的参数。
针对Pokemon精灵攻击力预测这个问题,有:
1.2.1 Step 1: 模型假设 - 线性模型
如果输入只有一个特征 x c p x_{cp} xcp ,可以假设一元线性模型
y = b + w ⋅ x c p y = b + w·x_{cp} y=b+w⋅xcp
如果输入有多个特征,例如,进化前的CP值、物种(Bulbasaur)、血量(HP)、重量(Weight)、高度(Height)等,则可以假设多元线性模型
y = b + ∑ w i x i y = b + \sum w_ix_i y=b+∑wixi
- x i x_i xi:就是各种特征(fetrure) x c p , x h p , x w , x h , ⋅ ⋅ ⋅ x_{cp},x_{hp},x_w,x_h,··· xcp,xhp,xw,xh,⋅⋅⋅
- w i w_i wi:各个特征的权重 w c p , w h p , w w , w h , ⋅ ⋅ w_{cp},w_{hp},w_w,w_h,·· wcp,whp,ww,wh,⋅⋅
- b b b:偏移量
确定了模型,则后续的,就是要求得最好的 w w w和 b b b,使得这个模型最优。
1.2.2 Step 2:模型评估 - 损失函数
针对单个特征 x c p x_{cp} xcp的情形

其实简单地讲,就是看函数的输出结果和真实值之间的差距,损失函数是用于量化这个差距的。
这里损失函数用的是最小二乘法的衡量方式
L ( y ^ , y ) = 1 2 ( y ^ − y ) 2 L (\hat y,y)= \dfrac {1}{2} (\hat y - y)^2 L(y^,y)=21(y^−y)2
但其实这个函数在很多问题中并不是一个很好的凸函数(在这个线性回归问题当中是凸函数),不易求得全局最优解。所以有一些其他的损失函数,比如交叉熵代价函数(cross-entropy)。
L ( y ^ , y ) = ( y log y ^ + ( 1 − y ) log ( 1 − y ^ ) ) L (\hat y,y)= (y\log {\hat y} + (1-y)\log(1-\hat y )) L(y^,y)=(ylogy^+(1−y)log(1−y^))
为了方便计算,把模型带入最小二乘法的公式
L ( f ) = ∑ n = 1 10 ( y ^ n − f ( x c p n ) ) 2 , 将 【 f ( x ) = y 】 , 【 y = b + w ⋅ x c p 】 代 入 = ∑ n = 1 10 ( y ^ n − ( b + w ⋅ x c p ) ) 2 \begin{aligned} L(f) & = \sum_{n=1}^{10}\left ( \hat{y}^n - f(x_{cp}^n) \right )^2,将【f(x) = y】, 【y= b + w·x_{cp}】代入 \\ & = \sum_{n=1}^{10}\left ( \hat{y}^n - (b + w·x_{cp}) \right )^2\\ \end{aligned} L(f)=n=1∑10(y^n−f(xcpn))2,将【f(x)=y】,【y=b+w⋅xcp】代入=n=1∑10(y^n−(b+w⋅xcp))2
最终定义 损失函数 Loss function: L ( w , b ) = ∑ n = 1 10 ( y ^ n − ( b + w ⋅ x c p ) ) 2 L(w,b)= \sum_{n=1}^{10}\left ( \hat{y}^n - (b + w·x_{cp}) \right )^2 L(w,b)=∑n=110(y^n−(b+w⋅xcp))2
可以将 w w w, b b b 在二维坐标图中展示,如图所示:
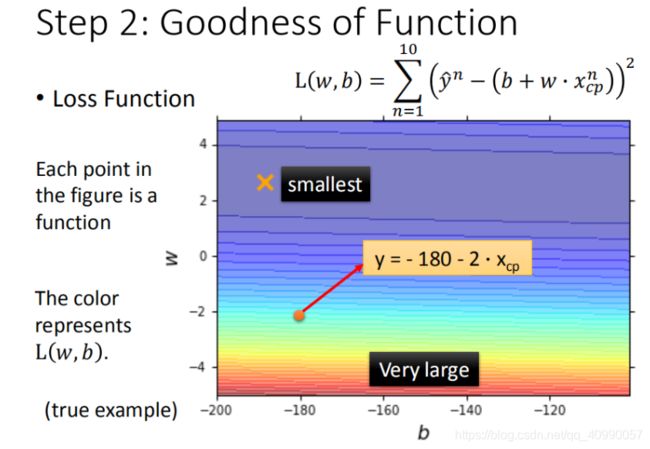
- 图中每一个点代表着一个模型对应的 w w w 和 b b b
- 颜色越深代表模型更优
1.2.3 Step 3:最佳模型-梯度下降
这一步是帮助我们筛选最优的模型,借助优化的方法逐步求得最优解,即针对这个数据 L ( w , b ) = ∑ n = 1 10 ( y ^ n − ( b + w ⋅ x c p ) ) 2 L(w,b)= \sum_{n=1}^{10}\left ( \hat{y}^n - (b + w·x_{cp}) \right )^2 L(w,b)=∑n=110(y^n−(b+w⋅xcp))2 最佳的 w w w和 b b b。
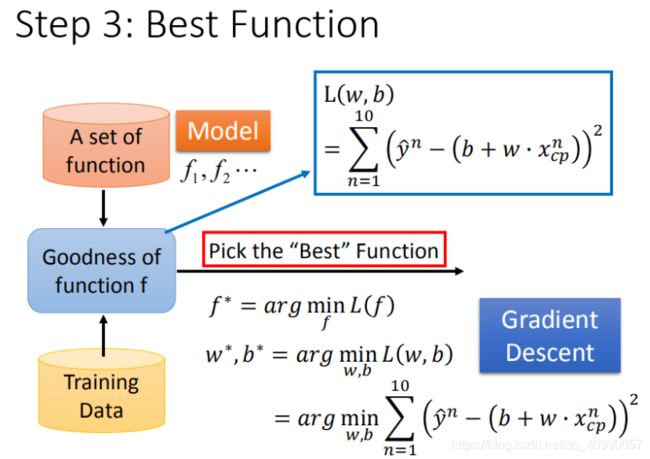
这边用的是最简单的梯度下降法。

简单的说就是求解损失函数对于参数的偏导数,然后改变参数的值,让参数的求解往最陡的地方走一步。

为了避免变化过于激烈,需要引入学习率的概念:移动的步长 η \eta η。
则梯度下降法的求解如下:
- 步骤1:随机选取一个 w 0 w^0 w0
- 步骤2:计算微分,也就是当前的斜率,根据斜率来判定移动的方向
- 步骤3:根据学习率移动
- 重复步骤2和步骤3,直到找到最低点
逐步求解如下图所示:

形象地表示如下:
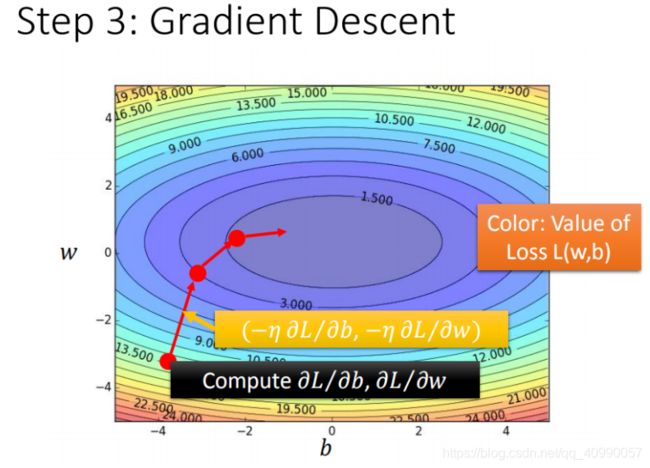
在现实中及别的问题中,梯度下降法会面临:
- 问题1:当前最优(Stuck at local minima)
- 问题2:等于0(Stuck at saddle point)
- 问题3:趋近于0(Very slow at the plateau)
这些问题需要通过调整合理的学习率,选择合理的损失函数等方法确定。
1.3 模型的提升
1.3.1 换用更复杂的模型
在上述例子中,可以选择更复杂的模型,可能可以取得更好的精度。
首先我们尝试增加模型的阶次。
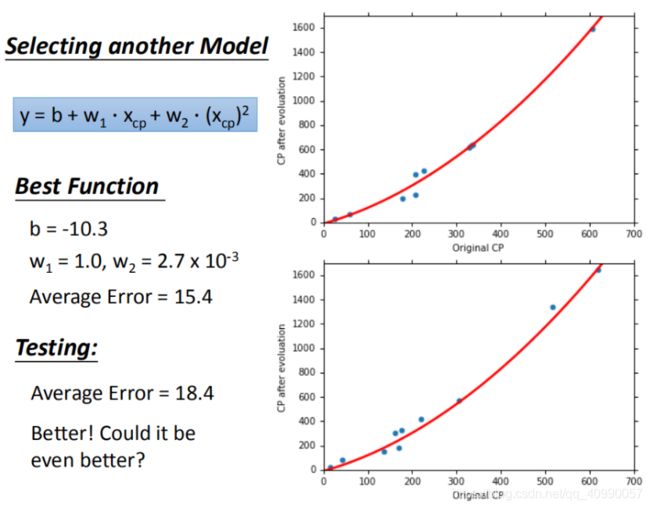
但也可能出现过拟合。

在训练集上面表现更为优秀的模型,为什么在测试集上效果反而变差了?这就是模型在训练集上过拟合的问题。
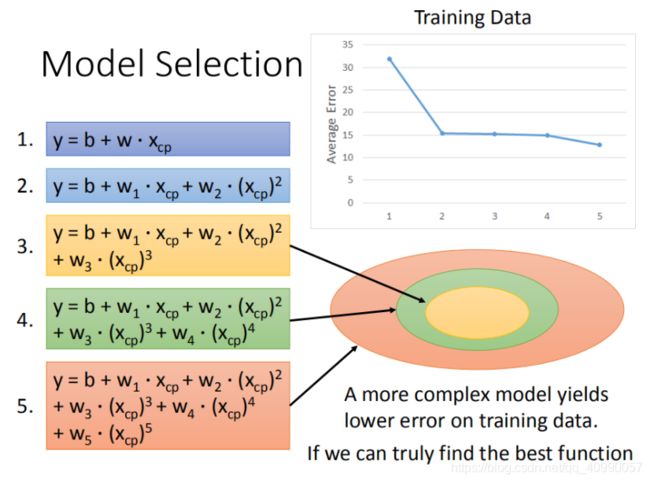
将错误率结果图形化展示,发现3次方以上的模型,已经出现了过拟合的现象:

过拟合是机器学习中经常会出现的问题,通俗地讲,过拟合就是模型过度拟合了训练集数据,而在测试集上表现很差。
一般来说,造成过拟合的原因有:
- 训练集太小
- 模型过于复杂
- 过度训练
- …
除了增加模型的阶次,还可以增加模型的变量个数,例如将对 Pokemons种类作为变量,输入模型。在此例中,Pokemon共有4类,则将 4个线性模型合并到一个线性模型中。
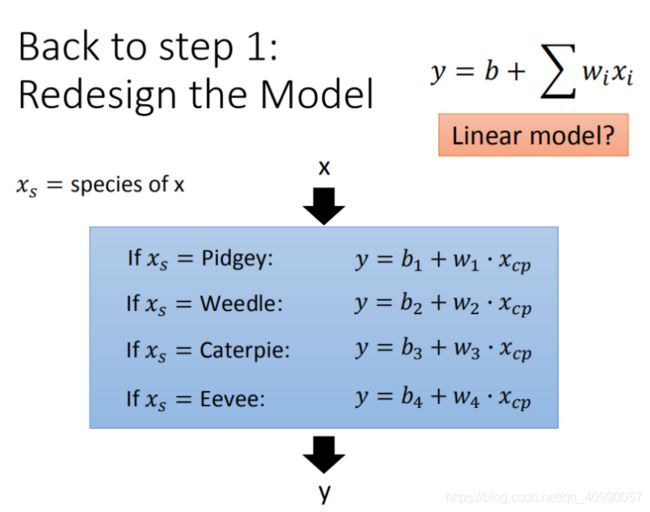
具体到某一个例子的求解上,有

效果有提升
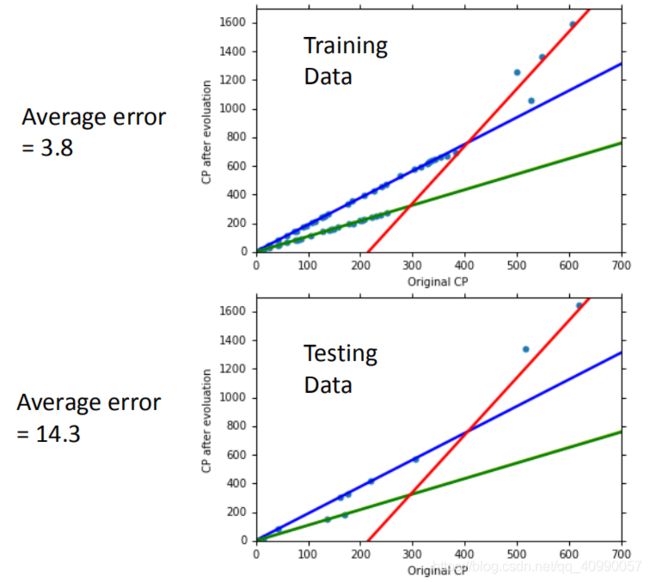
还可以将血量(HP)、重量(Weight)、高度(Height)也加入到模型中。
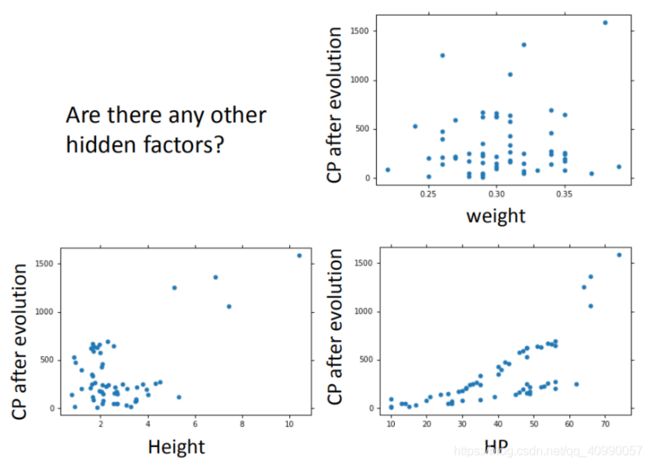
但在此例中依然会导致过拟合。
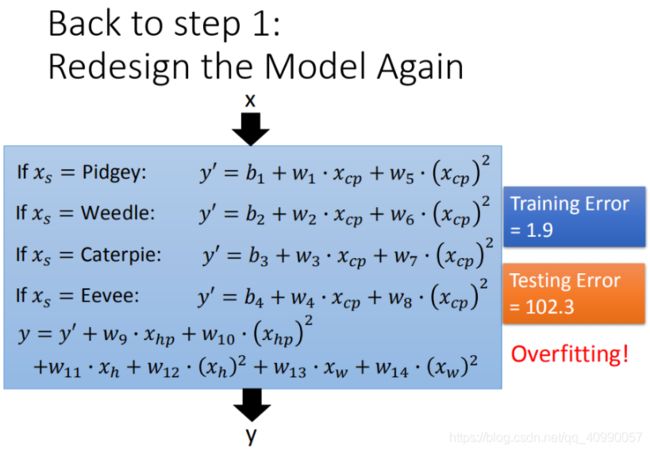
1.3.2 正则化
一种应对过拟合的方式,是在损失函数中引入正则化(Regularization)项。

在此例中引入的是L2正则化项
λ ∑ ( w i ) 2 \lambda \sum{(w_i)^2} λ∑(wi)2
这一正则化项使得 w w w参数越小的模型越受青睐。因为 w w w参数越小,说明当 x x x变化时,函数所求得的 y y y变化越小,也意味着模型更平滑,则过拟合的程度也会有所降低。
正则化项的参数 λ \lambda λ并非一味的越小越好。

从上图中我们可以看到,随着 λ \lambda λ的增大,损失函数正则化项的影响增大,模型过拟合程度下降。但当正则化项占比太大时,也会影响到损失函数的正常计算,无法求得很好的模型。
需要注意的是,由于参数 b b b与模型输入 x x x没有直接联系,故正则化项中不需要加入 b b b。
2 回归案例的计算
此部分的代码,完整版在本人的GitHub上,此处根据李宏毅机器学习2019P4适当地整理和修改。
2.1 回归案例
现在假设有10个
x_data和y_data,x和y之间的关系是y_data= b b b+ w w w*x_data。 b b b, w w w都是参数,是需要学习出来的。现在我们来练习用梯度下降找到 b b b和 w w w。
给定的x_data和y_data如下:
x_data = [338., 333., 328., 207., 226., 25., 179., 60., 208., 606.]
y_data = [640., 633., 619., 393., 428., 27., 193., 66., 226., 1591.]
x_d = np.asarray(x_data)
y_d = np.asarray(y_data)
针对上述代码中使用的np.asarray与本人常用的np.array不同,于是查找官方文档,尝试解决:What is the difference between np.asarray and np.array
根据Numpy Documnetation
np.asarray:
Returns : out: ndarray
Array interpretation of a. No copy is performed if the input is already an ndarray with matching dtype and order. If a is a subclass of ndarray, a base class ndarray is returned.
np.array:
Parameters : copybool: optional
If true (default), then the object is copied. Otherwise, a copy will only be made if array returns a copy, if obj is a nested sequence, or if a copy is needed to satisfy any of the other requirements (dtype, order, etc.).
Returns : out: ndarray
An array object satisfying the specified requirements.
可以看出它们的主要区别在于是否在生成时进行了对象拷贝。
具体到这一案例上
x_d2= np.array(x_data)
print(id(x_data))
print(id(x_d))
print(id(x_d2))
则可以得到结果
3033674123400
3033674166480
3033674167600
三者id不同,这是因为生成np.ndarray所使用的源对象本身不是np.ndarray的缘故。若:
x_d3= np.asarray(x_d2)
x_d4= np.array(x_d2)
print(id(x_d2))
print(id(x_d3))
print(id(x_d4))
则可以得到
3033674167600
3033674167600
3033674168160
可以明显地看出 np.asarray和np.array的不同,前者并未拷贝对象,而后者拷贝了对象。
具体到此例上,由于源对象不是np.ndarray,所以在此处使用np.array和np.asarray并无区别。
2.2 可视化背景等高线图的生成
教程中提供了生成可视化背景等高线图的代码,这段代码非常MATLAB。
x = np.arange(-200, -100, 1)
y = np.arange(-5, 5, 0.1)
Z = np.zeros((len(x), len(y)))
X, Y = np.meshgrid(x, y)
上述代码先生成 w w w及 b b b的绘图网格,随后进行每个网格点的残差计算。
# loss
for i in range(len(x)):
for j in range(len(y)):
b = x[i]
w = y[j]
Z[j][i] = 0 # meshgrid吐出结果:y为行,x为列
for n in range(len(x_data)):
Z[j][i] += (y_data[n] - b - w * x_data[n]) ** 2
Z[j][i] /= len(x_data)
上述这段代码是TA提供的代码,事实上这段代码非常不python,用了太多的for loops,这会使得计算效率很低。使用ipython的$$timeitmagic也可以看出其计算效率不高:
![]()
这段代码是可以改写的,可以充分利用numpy的broadcast及矩阵运算来提高运行效率。
此处先使用二维矩阵来实现这一点:
x1 = x[np.newaxis,:]
y1 = y[:,np.newaxis]
Z2 = np.zeros((len(x), len(y)))
for n in range(len(x_data)):
Z2 += (y_data[n] - x1 - y1 * x_data[n]) ** 2
Z2 /= len(x_data)
速度有了质的飞跃(提速超1000倍)。
![]()
同样地,也可以使用三维矩阵。
x1 = x[np.newaxis,:,np.newaxis]
y1 = y[:,np.newaxis,np.newaxis]
Z3 = np.zeros((len(x), len(y)))
x_data2 = x_d[np.newaxis,np.newaxis,:]#np.expand_dims(x_d[np.newaxis,:], axis=0)
y_data2 = y_d[np.newaxis,np.newaxis,:]
Z3 = np.mean((y_data2 - x1 - y1 * x_data2) ** 2,axis = 2)
速度相较原来也有很大提升,但有趣的是,相较二维反而变慢了。
![]()
可以画出如下的等高线图
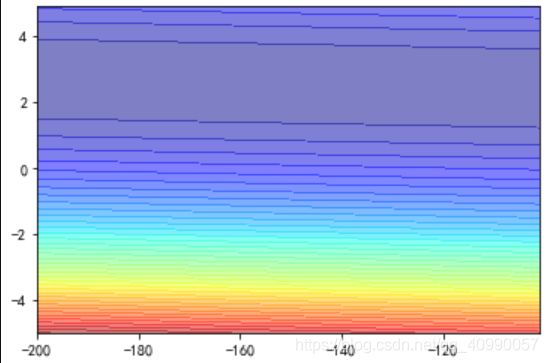
2.3 回归模型的建立
可以定义回归模型函数
def train(b, w, lr, iteration):
b_history = []
w_history = []
loss_history = []
for i in range(iteration):
b_history.append(b)
w_history.append(w)
m = len(x_d)
y_hat = w * x_d + b
loss = np.dot(y_d - y_hat, y_d - y_hat) / m
grad_b = -2.0 * np.sum(y_d - y_hat) / m
grad_w = -2.0 * np.dot(y_d - y_hat, x_d) / m
# update param
b -= lr * grad_b
w -= lr * grad_w
loss_history.append(loss)
return b_history, w_history, loss_history
及结果绘图函数
def draw(b_history, w_history, loss_history):
plt.figure(figsize = (8,6))
plt.contourf(x, y, Z, 50, alpha=0.5, cmap=plt.get_cmap('jet')) # 填充等高线
plt.plot([-188.4], [2.67], 'x', ms=12, mew=3, color="orange")
plt.plot(b_history, w_history, 'o-', ms=3, lw=1.5, color='black')
plt.xlim(-200, -100)
plt.ylim(-5, 5)
plt.xlabel(r'$b$')
plt.ylabel(r'$w$')
plt.title("线性回归")
plt.figure(figsize = (8,6))
plt.plot(range(iteration), np.log(loss_history))
plt.xlabel(r'$iteration$')
plt.ylabel(r'$loss(log10)$')
plt.title("损失函数")
x_predict = np.arange(0,650,1)
y_predict = b_history[-1] + w_history[-1] * x_predict
plt.figure(figsize = (8,6))
plt.plot(x_d, y_d, "o")
plt.plot(x_predict, y_predict)
plt.xlabel(r'$x$')
plt.ylabel(r'$y$')
plt.title("拟合结果")
接下来分别对三组参数进行试验。
- 学习率0.000001
b=-120
w=-4
lr = 0.000001
iteration = 140000
经过14000次计算后
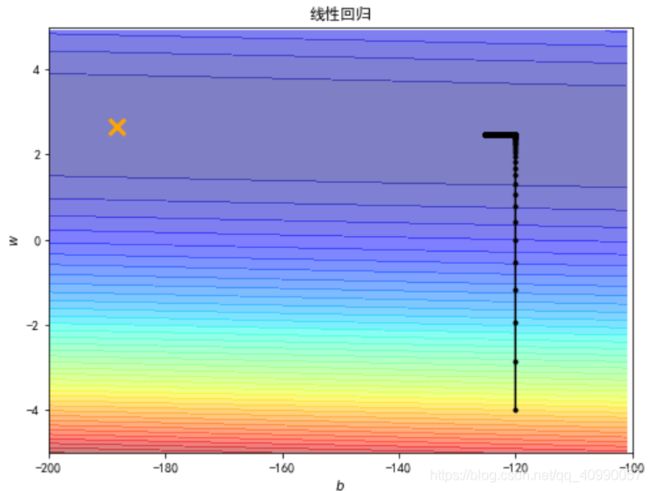
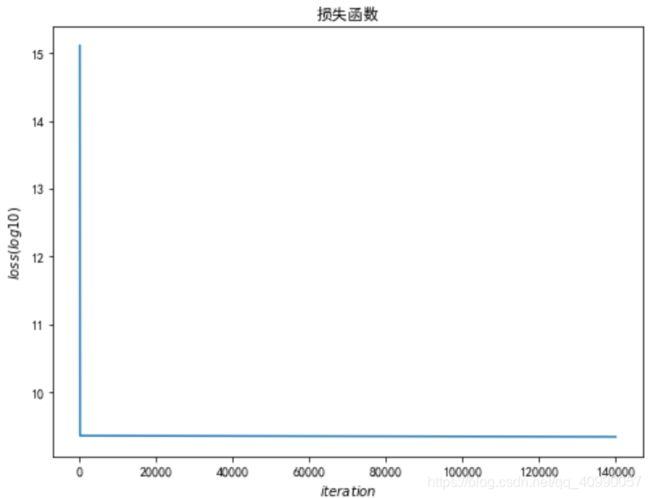

并未求得最优解
- 学习率0.00001(增大十倍)
b=-120
w=-4
lr = 0.00001
iteration = 140000
经过14000次计算后
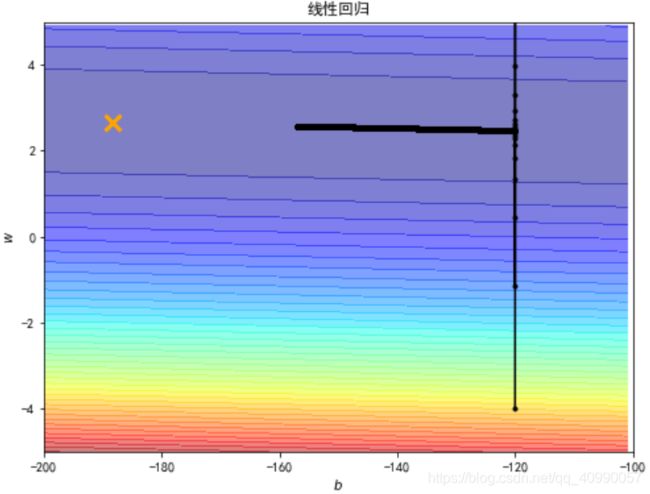


更接近最优解了,但出现了一定程度的振荡。
- 学习率0.0001(再增大十倍)
b=-120
w=-4
lr = 0.0001
iteration = 140000
经过14000次计算后

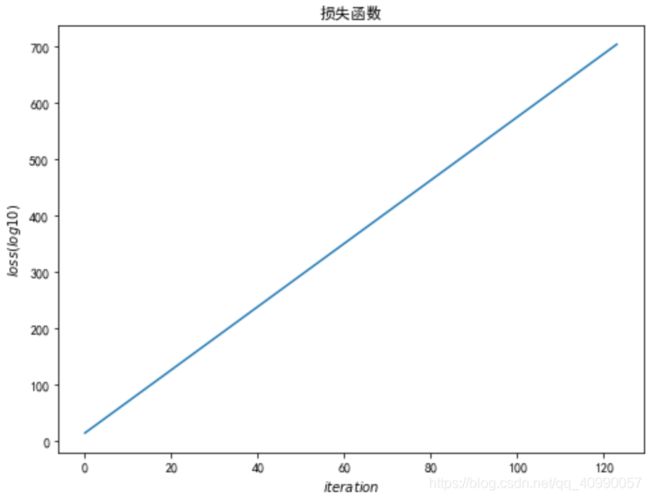
振荡相当明显。
由此可以看出,并不是一味增加学习率就可以达到快速学到结果的目的。
2.4 学习率的优化
TA提供了一种动态计算学习率的方法(Adagrad)。
Adagrad是一种基于梯度的优化算法:它将学习速率与参数相适应,对频繁参数的罕见更新和较小更新执行更大的更新。因此,它非常适合处理稀疏数据。
# linear regression
b = -120
w = -4
lr = 1
iteration = 100000
b_history = []
w_history = []
loss_history = []
lr_b=0
lr_w=0
for i in range(iteration):
b_history.append(b)
w_history.append(w)
m = len(x_d)
y_hat = w * x_d + b
loss = np.dot(y_d - y_hat, y_d - y_hat) / m
b_grad = -np.sum(2.0 * (y_d - b - w * x_d) * 1.0)
w_grad = -np.sum(2.0 * (y_d - b - w * x_d) * x_d)
lr_b = lr_b + b_grad ** 2
lr_w = lr_w + w_grad ** 2
# update param
b -= lr / np.sqrt(lr_b) * b_grad
w -= lr / np.sqrt(lr_w) * w_grad
loss_history.append(loss)
draw(b_history, w_history, loss_history)
笔记中的代码有误,且未利用矩阵运算,此处进行了修改和优化。
可以在100000次内求得最优解。
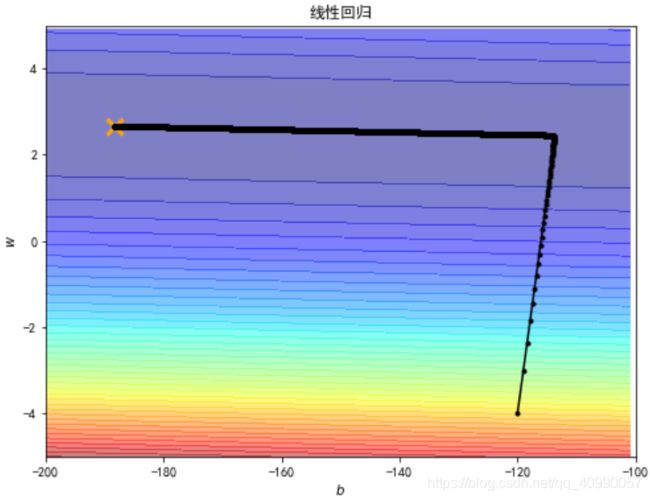


参考阅读
- 李宏毅机器学习笔记(LeeML-Notes)
- 李宏毅机器学习课程视频
- 什么是 L1/L2 正则化 (Regularization)
- Adagrad优化器