机器学习预测价格低点
Travelling is one of the most entertaining things that everybody wants to avoid city crowds. Going to another island with a unique nature brings a new perspective about new things. The Indian, one of the most entertaining cities with its uniqueness, brings a lot of wonderful islands. Based on Outlook of the Indian travel Industry, The tourism industry contributes around $98 billion in 2018 and expected to arise in the next period. This trend brings India as one of the immense potential countries because of country rich cultural and geographical diversity. These trends also bring uncertainty about the flight ticket price. It can be hard to guess the flight ticket price when we check it today compared to the other day. The tourists who want to visit a new place in India should know the ticket price in order to get the cheapest and certain ticket price with their needs. This gap brings the idea to make a prediction about the flight tickets in order to make the tourists easier to book their tickets with their needs.
旅行是每个人都想要避免的城市人群中最有趣的事情之一。 前往具有独特自然风光的另一个岛屿带来了新事物的新视角。 印度是最有趣的城市之一,其独特之处在于带来了许多美丽的岛屿。 根据印度旅游业展望,2018年旅游业贡献了约980亿美元,并有望在下一个时期出现。 由于该国丰富的文化和地域多样性,这一趋势使印度成为巨大的潜在国家之一。 这些趋势也带来了机票价格的不确定性。 当我们今天比较机票价格时,很难猜测到机票价格。 想要参观印度新地方的游客应该知道门票价格,以便根据自己的需求获得最便宜和确定的门票价格。 这种差距带来了对机票进行预测的想法,从而使游客更容易根据自己的需求预订机票。
Technology can bring a solution through the implementation of Machine learning techniques to improve the uncertainty of flight prices in the future. We will use Flight Price Dataset provided by Kaggle Flight Price. This dataset consists of 10683 records with 13 columns that explain about the flight in India by some Indian and foreign Airlines in 2019. We will analyze this dataset using Machine learning techniques in order to predict the flight ticket price based on the features provided in the columns of the dataset. We will begin the Data Science Life Cycle to process the data. Before enjoying this article, make sure the reader can understand some basics of python, machine learning techniques, hyperparameter tuning, and familiarity of pandas, seaborn, and scikit-learn. You can refer to all of my references at the end of this article.
技术可以通过实施机器学习技术带来解决方案,以改善未来航班价格的不确定性。 我们将使用Kaggle Flight Price提供的Flight Price数据集。 该数据集包括10683条记录和13列,这些列解释了一些印度和外国航空公司在2019年的印度航班。我们将使用机器学习技术分析该数据集,以便根据列中提供的功能预测机票价格数据集。 我们将开始数据科学生命周期来处理数据。 在享受本文之前,请确保读者了解python的一些基础知识,机器学习技术,超参数调整以及对熊猫,seaborn和scikit-learn的熟悉。 您可以在本文结尾处引用我的所有参考。

1.清理数据(1. Cleaning the Data)
T
Ť
Pandas, Seaborn, NumPy, and matplotlib are some of the most used libraries by Data Scientist in order to visualize and analyze the dataset. We will use these libraries such as follows :
Pandas,Seaborn,NumPy和matplotlib是数据科学家为了可视化和分析数据集而最常用的一些库。 我们将使用这些库,如下所示:

We will get the features and records by importing the dataset. We can see there are some columns such as Airline, Date_of_Journey, Source, etc.
我们将通过导入数据集来获取要素和记录。 我们可以看到其中有一些列,例如“航空公司”,“ Date_of_Journey”,“来源”等。

Based on these columns, we will try to eliminate the null values(error input) so that it can affect the prediction in our analysis. We will start by the Duration column to know the counts of each group. We will check the null values then drop the NaN values using dropna method and check whether the null values using isnull and sum method.
基于这些列,我们将尝试消除空值(错误输入),以便它可以影响分析中的预测。 我们将从“持续时间”列开始,以了解每个组的计数。 我们将检查null值,然后使用dropna方法删除NaN值,并使用notull和sum方法检查是否为null值。
2. Exploratory Data Analysis
2.探索性数据分析
Exploratory Data Analysis has been playing an important role in the success of our prediction. We will do feature engineering of some features so that it can represent the output for our model created using machine learning techniques. From the dataset shown above, we can see that column Date_of_Journey, Arrival_Time, Dep_Time, and Duration columns are a string data type, We will convert this datatype into timestamp to use this column for prediction. We will use pandas_to_datetime to convert it and get the hour and minutes of each column. You can refer to the notebook provided in Github.
探索性数据分析在我们的预测成功中一直发挥着重要作用。 我们将对某些功能进行功能工程设计,以便它可以代表使用机器学习技术创建的模型的输出。 从上面显示的数据集中,我们可以看到Date_of_Journey列,Arrival_Time列,Dep_Time列和Duration列是字符串数据类型,我们将把该数据类型转换成timestamp以便将该列用于预测。 我们将使用pandas_to_datetime进行转换,并获取每一列的小时和分钟。 您可以参考Github中提供的笔记本。

One of the most important parts of EDA is handling categorical Data. Categorical data can be divided into Nominal data (without order) by using OneHot Encoder and Ordinal Data( with Order) by using LabelEncoder to label this data. We can start by Airline column and plot the data using seaborn drawn such as follows :
EDA最重要的部分之一是处理分类数据。 可以使用OneHot编码器将分类数据分为名义数据(无顺序),而使用LabelEncoder将该数据分类为有序数据(带顺序)。 我们可以从“航空公司”列开始,然后使用seaborn绘制来绘制数据,如下所示:

We can see that the average price ticket is the same among the airlines except for Jet Airways Business due to facilities provided by the Airline. We can also see some outliers among Jet Airways Business, Jet Airways, and Multiple Carriers that affect the price of the airlines.
我们可以看到,由于航空公司提供的设施,除Jet Airways Business以外,其他航空公司的平均机票价格是相同的。 我们还可以看到Jet Airways Business,Jet Airways和Multiple Carriers之间的一些异常值会影响航空公司的价格。
We will perform the Airline column using One Hot Encoder because of nominal categorical data by using this code. We will implement the same code to the Source column and compare the Price and Source features.
由于使用此代码,因此由于名义分类数据,我们将使用“一个热编码器”执行“航空公司”列。 我们将对“源”列实施相同的代码,并比较“价格”和“源”功能。

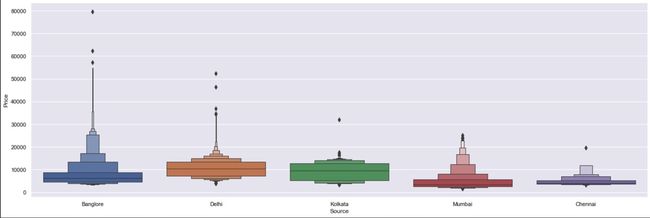
We can see that some outliers on Bangalore Source. We will implement One Hot Encoder for destination and Label Encoder for the Total_Stops encoder for Ordinal categorical data.
我们可以在Bangalore Source上看到一些离群值。 我们将为目标实现一个热编码器,为序数分类数据实现Total_Stops编码器的标签编码器。

Then we concat all the changes in the features using concat method in pandas.
然后,我们使用pandas中的concat方法来合并功能中的所有更改。
3. Test Set
3.测试仪
In our Machine Learning Process, We have already separated the training and test dataset. We will use this method in order to avoid Data Leakage. We import the data and preprocess it. We will predict the price in this analysis. Thus, we will do a feature selection to choose the best feature that has good relations with the target variable(Price).
在我们的机器学习过程中,我们已经分离了训练和测试数据集。 我们将使用此方法以避免数据泄漏。 我们导入数据并对其进行预处理。 我们将在此分析中预测价格。 因此,我们将进行特征选择,以选择与目标变量(价格)具有良好关系的最佳特征。

We will then see the correlation between independent and dependent variables using heatmap and ExtraTreesRegressor to look at which one is the better features to select.
然后,我们将使用Heatmap和ExtraTreesRegressor来查看自变量和因变量之间的相关性,以了解哪个是更好的功能。
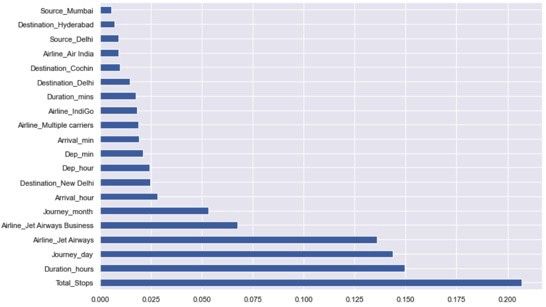
Based on the graph, We can see that the Total_Stops feature has the highest influence in predicting the price followed by Duration_hours and Journey_Day.
根据该图,我们可以看到,Total_Stops功能对预测价格的影响最大,其次是Duration_hours和Journey_Day。
4. Fitting the Model Using Random Forest
4.使用随机森林拟合模型
We will use Random Forest for this type of analysis by splitting the data using scikit-learn such as follows :
通过使用scikit-learn分割数据,我们将使用Random Forest进行这种类型的分析,如下所示:

We can see that the prediction score has exceeds 95 % for the training data and 79% for the test data. We can improve this score by implementing hyperparameter tuning that consists of RandomizedSearchCV and GridSearchCV.
我们可以看到,训练数据的预测分数已超过95%,测试数据的预测分数已超过79%。 我们可以通过实现由RandomizedSearchCV和GridSearchCV组成的超参数调整来提高此分数。
and create a random grid and use the fit method such as follows :
并创建一个随机网格并使用拟合方法,如下所示:
And then we can plot and predict the result again and we have improved the result based on our hyperparameter tuning. We have already improved our score from 79% to 81% by implementing the RandomizedSearchCV as our hyperparameter tuning. You can see the full code in the jupyter notebook uploaded in this Github link.
然后我们可以再次绘制和预测结果,并且基于超参数调整对结果进行了改进。 通过将RandomizedSearchCV用作超参数调整,我们已经将分数从79%提高到81%。 您可以在此Github链接中上传的jupyter笔记本中看到完整的代码。
Reference :
参考:
Machine Learning Concepts (Supervised Learning, Unsupervised Learning, Hyperparameter tuning, Classification, Regression, etc)
机器学习概念(监督学习,无监督学习,超参数调整,分类,回归等)
翻译自: https://medium.com/@naiborhujosua/predicting-airfare-price-using-machine-learning-techniques-bf3a13ad07d1
机器学习预测价格低点