PyTorch+TensorRT!20倍推理加速!
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!
等你着陆!【GAN生成对抗网络】知识星球!
转自:新智元
众所周知,PyTorch和TensorFlow是两个非常受欢迎的深度学习框架。
12月2日,英伟达发布了最新的TensorRT 8.2版本,对10亿级参数的NLP模型进行了优化,其中就包括用于翻译和文本生成的T5和GPT-2。
而这一次,TensorRT让实时运行NLP应用程序成为可能。

Torch-TensorRT:6倍加速
TensorRT是一个高性能的深度学习推理优化器,让AI应用拥有低延迟、高吞吐量的推理能力。
新的TensorRT框架为PyTorch和TensorFlow提供了简单的API,带来强大的FP16和INT8优化功能。
只需一行代码,调用一个简单的API,模型在NVIDIA GPU上就能实现高达6倍的性能提升。

Torch-TensorRT:工作原理
Torch-TensorRT编译器的架构由三个阶段组成:
简化TorchScript模块
转换
执行
简化TorchScript模块
Torch-TensorRT可以将常见操作直接映射到TensorRT上。值得注意的是,这种过程并不影响计算图本身的功能。

解析和转换TorchScript
转换
Torch-TensorRT自动识别与TensorRT兼容的子图,并将它们翻译成TensorRT操作:
具有静态值的节点被评估并映射到常数。
描述张量计算的节点被转换为一个或多个TensorRT层。
剩下的节点留在TorchScript中,形成一个混合图,并作为标准的TorchScript模块返回。

将Torch的操作映射到TensorRT上
修改后的模块会在嵌入TensorRT引擎后返回,也就是说整个模型,包括PyTorch代码、模型权重和TensorRT引擎,都可以在一个包中进行移植。

将Conv2d层转化为TensorRT引擎,而log_sigmoid则回到TorchScript JIT中
执行
当执行编译模块时,TorchScript解释器会调用TensorRT引擎并传递所有输入。之后,TensorRT会将结果推送回解释器,整个流程和使用普通的TorchScript模块别无二致。

PyTorch和TensorRT操作的运行时执行
Torch-TensorRT:特点
对INT8的支持
Torch-TensorRT通过两种技术增强了对低精度推理的支持:
训练后量化(PTQ)
量化感知训练(QAT)
对于PTQ来说,TensorRT用目标领域的样本数据训练模型,同时跟踪FP32精度下的权重激活,以校准FP32到INT8的映射,使FP32和INT8推理之间的信息损失最小。
稀疏性
英伟达的安培架构在A100 GPU上引入了第三代张量核心,可以在网络权重中增加细粒度的稀疏性。
因此,A100在提供最大吞吐量的同时,也不会牺牲深度学习核心的矩阵乘法累积工作的准确性。
TensorRT支持在Tensor Core上执行深度学习模型的稀疏层,而Torch-TensorRT将这种稀疏支持扩展到卷积和全连接层。
举个例子
比如,用EfficientNet图像分类模型进行推理,并计算PyTorch模型和经过Torch-TensorRT优化的模型的吞吐量。
以下是在NVIDIA A100 GPU上取得的结果,batch size为1。

在NVIDIA A100 GPU上比较原生PyTorch和Torch-TensorRt的吞吐量
用TensorRT实现T5和GPT-2实时推理

Transformer架构完全改变了自然语言处理领域。近年来,许多新颖的大语言模型都建立在Transformer模块之上,比如BERT、GPT和T5。
T5和GPT-2简介
T5可以用来回答问题、做总结、翻译文本和分类文本。
T5(Text-To-Text Transfer Transformer,文本到文本转换Transformer)是谷歌创建的架构。它将所有自然语言处理(NLP)任务重新组织成统一的文本到文本格式,其中输入和输出总是文本字符串。
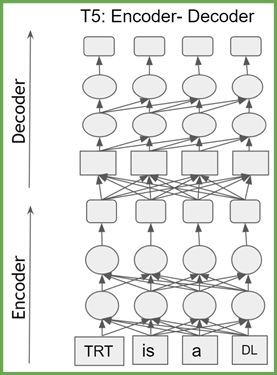
T5的架构能够将相同的模型、损失函数和超参数应用于任何自然语言处理任务,如机器翻译、文档摘要、问题回答和分类任务,如情感分析。

T5模型的灵感来自于一个NLP领域的共识,即迁移学习已经在自然语言处理中取得了最先进的结果。
迁移学习背后的原理是,在大量可用的未标记数据上经过预训练的模型,可以在较小的特定任务的已标记数据集上进行针对性的微调。事实证明,预训练-微调模型比从头开始在特定任务数据集上训练的模型具有更好的结果。

T5模型在许多下游自然语言处理任务上获得了最先进的结果。已发布的预训练T5的参数最多高达3B和11B。
虽说都是语言模型,GPT-2的长处在于生成优秀的文本。
GPT-2(Generative Pre-Trained Transformer 2)是一种自回归无监督语言模型,最初由OpenAI提出。

它是由transformer解码器块构建的,并在非常大的文本语料库上进行训练,以预测文本的下一个单词。

已发布的GPT-2模型中,最大的拥有1.5B参数,能够写出非常连贯的文本。
用TensorRT部署T5和GPT-2
虽然较大的神经语言模型通常会产生更好的结果,但将其部署到生产中会带来很大的挑战,尤其是对于在线应用程序,几十毫秒的额外延迟足以让用户的体验变差很多。
借助最新的TensorRT 8.2,英伟达针对大模型的实时推断这一需求,优化了T5和GPT-2。
首先,从Hugging Face模型中心下载Hugging Face PyTorch T5模型及其相关的tokenizer。
T5_VARIANT = 't5-small'
t5_model = T5ForConditionalGeneration.from_pretrained(T5_VARIANT)
tokenizer = T5Tokenizer.from_pretrained(T5_VARIANT)
config = T5Config(T5_VARIANT)接下来,将模型转换为经过优化的TensorRT执行引擎。
不过,在将T5模型转换为TensorRT引擎之前,需要将PyTorch模型转换为一种中间通用格式:ONNX。
ONNX是机器学习和深度学习模型的开放格式。它能够将深度学习和机器学习模型从不同的框架(如TensorFlow、PyTorch、MATLAB、Caffe和Keras)转换为一个统一的格式。
encoder_onnx_model_fpath = T5_VARIANT + "-encoder.onnx"
decoder_onnx_model_fpath = T5_VARIANT + "-decoder-with-lm-head.onnx"
t5_encoder = T5EncoderTorchFile(t5_model.to('cpu'), metadata)
t5_decoder = T5DecoderTorchFile(t5_model.to('cpu'), metadata)
onnx_t5_encoder = t5_encoder.as_onnx_model(
os.path.join(onnx_model_path, encoder_onnx_model_fpath), force_overwrite=False
)
onnx_t5_decoder = t5_decoder.as_onnx_model(
os.path.join(onnx_model_path, decoder_onnx_model_fpath), force_overwrite=False
)然后,将准备好的T5 ONNX编码器和解码器转换为优化的TensorRT引擎。由于TensorRT执行了许多优化,例如融合操作、消除转置操作和内核自动调整(在目标GPU架构上找到性能最佳的内核),因此这一转换过程可能需要一段时间。
t5_trt_encoder_engine = T5EncoderONNXt5_trt_encoder_engine = T5EncoderONNXFile(
os.path.join(onnx_model_path, encoder_onnx_model_fpath), metadata
).as_trt_engine(os.path.join(tensorrt_model_path, encoder_onnx_model_fpath) + ".engine")
t5_trt_decoder_engine = T5DecoderONNXFile(
os.path.join(onnx_model_path, decoder_onnx_model_fpath), metadata
).as_trt_engine(os.path.join(tensorrt_model_path, decoder_onnx_model_fpath) + ".engine")最后,就可以用T5的TensorRT引擎进行推理了。
t5_trt_encoder = T5TRTEncoder(
t5_trt_encoder_engine, metadata, tfm_config
)
t5_trt_decoder = T5TRTDecoder(
t5_trt_decoder_engine, metadata, tfm_config
)
#generate output
encoder_last_hidden_state = t5_trt_encoder(input_ids=input_ids)
outputs = t5_trt_decoder.greedy_search(
input_ids=decoder_input_ids,
encoder_hidden_states=encoder_last_hidden_state,
stopping_criteria = StoppingCriteriaList([MaxLengthCriteria(max_length)])
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))同样,对于GPT-2模型也可以按照相同的过程生成一个TensorRT引擎。优化后的TensorRT引擎可以在HuggingFace推理工作流中替代原始的PyTorch模型。
TensorRT vs PyTorch CPU、PyTorch GPU
通过将T5或GPT-2转变为TensorRT引擎,与PyTorch模型在GPU上的推断时间相比,TensorRT的延迟降低了3至6倍,与PyTorch模型在CPU上的推断时间相比,延迟更是降低了9至21倍。

T5-3B模型推断时间比较
与PyTorch模型在CPU上的推断时间相比,运行在A100 GPU上的TensorRT引擎将延迟缩小了21倍。
对NLP感兴趣的朋友,要是想加速大语言模型的推理过程,就快来试试TensorRT 8.2吧!
参考资料:
https://developer.nvidia.com/blog/nvidia-announces-tensorrt-8-2-and-integrations-with-pytorch-and-tensorflow/?ncid=so-twit-314589#cid=dl13_so-twit_en-us
https://developer.nvidia.com/blog/accelerating-inference-up-to-6x-faster-in-pytorch-with-torch-tensorrt/
https://developer.nvidia.com/blog/optimizing-t5-and-gpt-2-for-real-time-inference-with-tensorrt/
猜您喜欢:
超110篇!CVPR 2021最全GAN论文汇总梳理!
超100篇!CVPR 2020最全GAN论文梳理汇总!
拆解组新的GAN:解耦表征MixNMatch
StarGAN第2版:多域多样性图像生成
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 |《计算机视觉中的数学方法》分享
《基于深度学习的表面缺陷检测方法综述》
《零样本图像分类综述: 十年进展》
《基于深度神经网络的少样本学习综述》
