《机器学习实战》chap1 机器学习概览
《机器学习实战》chap1 机器学习概览
Chap1 The Machine Learning Landscape
这本书第三版也已经出版了:https://github.com/ageron/handson-ml3
-
Hands-on Machine Learning with Scikit-Learn,Keras & TensorFlow
-
引入
- 很早的应用:光学字符识别(OCR, Optical Character Recognition)
- 20世纪90年代:垃圾邮件过滤器 the spam filter
- … Now 数不清的机器学习应用
现在开始培养自己看英文原版的习惯
结合着看…
文章目录
- 《机器学习实战》chap1 机器学习概览
- 1.1 What is Machine Learning
- 1.2 Why Use Machine Learning?
- 1.3 Types of Machine Learning Systems
-
- 1.3.1 Supervised/Unsupervised Learning
-
- Supervised Learning
- Unsupervised learning
- Semisupervised learning
- Reinforcement learning
- 1.3.2 Batch and Online Learning
-
- Batch learning
- Online learning
- 1.3.3 Instance-Based Versus Model-Based Learning
-
- Instance-based learning
- Model-based learning
- 1.4 Main Challenges of Machine Learning
-
- Insuffcient Quantity of Training Data
- Nonrepresentative Training Data
- Poor-Quality Data
- Irrelevant Features
- Overfitting the Training Data
- Underfitting the Training Data
- 1.5 Testing and Validating
- Exercises
- 参考
Examples of Applications 举得一些例子没有记笔记
1.1 What is Machine Learning
-
definition
- a slightly more general definition:
- [Machine Learning is the] field of study that gives computers the ability to learn without being explicitly programmed. —Arthur Samuel, 1959
- 机器学习是一个研究领域,让计算机无须进行明确编程就具备学 习能力。
- a more engineering-oriented one:
- A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E. —Tom Mitchell, 1997
- 一个计算机程序利用经验E来学习任务T,性能是P,如果针对任务T的性能P随着经验E不断增长,则称为机器学习
- a slightly more general definition:
-
For example, your spam filter is a Machine Learning program that can learn to flag spam given examples of spam emails (e.g., flagged by users) and examples of regular (nonspam, also called “ham”) emails.
- 你的垃圾邮件过滤器是一个机器学习程序,它可以根据垃圾邮件的例子(例如,被用户标记的垃圾邮件)和普通的例子(非垃圾邮件,也称为 “ham”)邮件的例子学习如何标记出垃圾邮件。
-
The examples that the system uses to learn(系统用来进行学习的样例) are called the training set(训练集). Each training example is called a training instance (or sample)(训练实例,训练样本). In this case, the task T is to flag spam for new emails(标记垃圾邮件), the experience E is the training data(训练数据),
- the performance measure P needs to be defined; for example, you can use the ratio of correctly classified emails.
(比如可以把P定义为 可以正确分类邮件的比例)
- This particular performance measure is called accuracy(准确率) and it is often used in classification tasks(分类任务).
1.2 Why Use Machine Learning?
-
作者还是用垃圾邮件的例子,感觉讲的很棒
-
Machine Learning is great for:
- Problems for which existing solutions require a lot of hand-tuning or long lists of rules: one Machine Learning algorithm can often simplify code and perform better.
- Complex problems for which there is no good solution at all using a traditional approach: the best Machine Learning techniques can find a solution.
- Fluctuating(波动的) environments: a Machine Learning system can adapt to new data.
- Getting insights about complex problems and large amounts of data
-
积累一个我觉得文中很好的表达,下面这个shine
Another area where Machine Learning shines is for problems that either are too complex for traditional approaches or have no known algorithm.
-
Machine Learning is about making machines get better at some task by learning from data, instead of having to explicitly code rules.
1.3 Types of Machine Learning Systems
哈哈哈最近发现state-of-the-art这个词用的挺多的
There are so many different types of Machine Learning systems that it is useful to classify them in broad categories based on: (据以下标准进行大致分类)
-
Whether or not they are trained with human supervision (supervised, unsuper‐ vised, semisupervised, and Reinforcement Learning)
-
Whether or not they can learn incrementally on the fly (online versus batch learning)
是否可以动态地进行增量学习 (在线学习和批量学习)
-
Whether they work by simply comparing new data points to known data points, or instead detect patterns in the training data and build a predictive model, much like scientists do (instance-based versus model-based learning)
These criteria are not exclusive; you can combine them in any way you like. For example, a state-of-the-art spam filter may learn on the fly using a deep neural net‐ work model trained using examples of spam and ham; this makes it an online, model-based, supervised learning system.
1.3.1 Supervised/Unsupervised Learning
-
be classified according to the amount and type of supervision they get during training.
-
four major categories: supervised learning, unsupervised learning, semisupervised learning, and Reinforcement Learning.
Supervised Learning
-
typical supervised learning tasks
-
classification
- 还是以spam filter为例:A labeled training set 中, trained with many example emails with their class (spam or ham)

-
regression
Fun fact: this odd-sounding name is a statistics term introduced by Francis Galton while he was studying the fact that the children of tall people tend to be shorter than their parents. Since children were shorter, he called this regression to the mean. This name was then applied to the methods he used to analyze correlations between variables.
- predict a target numeric value, such as the price of a car, given a set of features (mileage, age, brand, etc.) called predictors.
- To train the system, you need to give it many examples of cars, including both their predictors and their labels (i.e., their prices).

-
-
Some of the most important supervised learning algorithms (covered in this book):
Some regression algorithms can be used for classification as well, and vice versa. For example, Logistic Regression is commonly used for classification.
- k-Nearest Neighbors
- Linear Regression
- Logistic Regression
- Support Vector Machines (SVMs)
- Decision Trees and Random Forests
- Neural networks
Unsupervised learning
-
The training data is unlabeled. The system tries to learn without a teacher
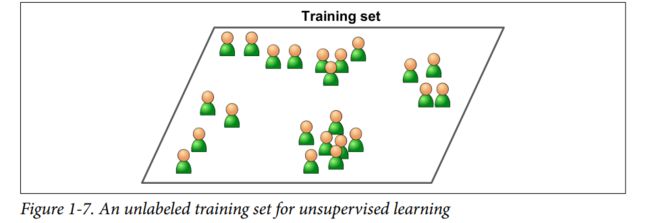
以下为典型task和对应的一些重要算法
-
Clustering
- K-Means
- DBSCAN
- Hierarchical Cluster Analysis (HCA) 分层聚类分析
-
Anomaly detection and novelty detection 异常检测和新颖性检测
Anomaly detection:it learns to recognize them and when it sees a new instance it can tell whether it looks like a normal one or whether it is likely an anomaly
Novelty detection: 和前者类似,the difference is that novelty detection algorithms expect to see only normal data during training, while anomaly detection algorithms are usually more tolerant, they can often perform well even with a small percentage of outliers in the training set.
- One-class SVM 单类SVM
- Isolation Forest
-
Visualization and dimensionality reduction 可视化和降维
visualization:you feed them a lot of complex and unlabeled data, and they output a 2D or 3D rep‐ resentation of your data that can easily be plotted
dimensionality reduction:the goal is to simplify the data without losing too much information
It is often a good idea to try to reduce the dimension of your train‐ ing data using a dimensionality reduction algorithm before you feed it to another Machine Learning algorithm (such as a super‐ vised learning algorithm). It will run much faster, the data will take up less disk and memory space, and in some cases it may also per‐ form better
- Principal Component Analysis (PCA)
- Kernel PCA 核主成分分析
- Locally-Linear Embedding (LLE) 局部线性嵌入
- t-distributed Stochastic Neighbor Embedding (t-SNE) t-分布随机近邻嵌入
-
Association rule learning 关联规则学习
the goal is to dig into large amounts of data and discover interesting relations between attributes
- Apriori
- Eclat
Semisupervised learning
- deal with partially labeled training data, usually a lot of unlabeled data and a little bit of labeled data.
- Most semisupervised learning algorithms are combinations of unsupervised and supervised algorithms.
Reinforcement learning
The learning system, called an agent in this context, can observe the environment, select and perform actions, and get rewards in return (or penalties in the form of negative rewards). It must then learn by itself what is the best strategy, called a policy, to get the most reward over time. A policy defines what action the agent should choose when it is in a given situation.

1.3.2 Batch and Online Learning
这一小节目前不是很理解
-
Another criterion used to classify Machine Learning systems is whether or not the system can learn incrementally from a stream of incoming data.
看系统是否可以从传入的数据流中进行增量学习
Batch learning
-
In batch learning, the system is incapable of learning incrementally: it must be trained using all the available data.
-
This will generally take a lot of time and computing resources, so it is typically done offline. First the system is trained, and then it is launched into production and runs without learning anymore; it just applies what it has learned. This is called offline learning.
Online learning
-
In online learning, you train the system incrementally by feeding it data instances sequentially, either individually or by small groups called mini-batches. Each learning step is fast and cheap, so the system can learn about new data on the fly, as it arrives.(系统可以根据飞速写入的最新数据进行学习)
on the fly :(计算机)运行中
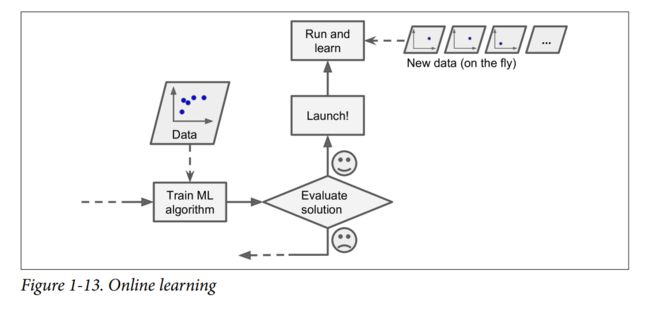
1.3.3 Instance-Based Versus Model-Based Learning
-
One more way to categorize Machine Learning systems is by how they generalize(如何泛化). Most Machine Learning tasks are about making predictions. This means that given a number of training examples, the system needs to be able to generalize to examples it has never seen before. Having a good performance measure on the training data is good, but insufficient; the true goal is to perform well on new instances.
在训练数据上实现良好的性能指标固然重要,但是还不够充分。真正的目的是要在新的对象实 例上表现出色
-
There are two main approaches to generalization: instance-based learning and model-based learning.
Instance-based learning
- the system learns the examples by heart, then generalizes to new cases by comparing them to the learned examples (or a subset of them), using a similarity measure
Model-based learning
-
build a model of these exam‐ ples, then use that model to make predictions
-
In summary:
- You studied the data.
- You selected a model.
- You trained it on the training data (i.e., the learning algorithm searched for the model parameter values that minimize a cost function).
- Finally, you applied the model to make predictions on new cases (this is called inference), hoping that this model will generalize well.
This is what a typical Machine Learning project looks like.
- There are many different types of ML systems: supervised or not, batch or online, instance-based or model-based, and so on.
- In a ML project you gather data in a training set, and you feed the training set to a learning algorithm. If the algorithm is model-based it tunes some parameters to fit the model to the training set (i.e., to make good predictions on the training set itself), and then hopefully it will be able to make good predictions on new cases as well. If the algorithm is instance-based, it just learns the examples by heart and uses a similarity measure to generalize to new instances.
1.4 Main Challenges of Machine Learning
In short, since your main task is to select a learning algorithm and train it on some data, the two things that can go wrong are “bad algorithm” and “bad data.” Let’s start with examples of bad data.
Insuffcient Quantity of Training Data
作者这里写的很好玩哈哈哈
For a toddler (刚学会走路的孩子,牙牙学语的小孩)to learn what an apple is, all it takes is for you to point to an apple and say “apple” (possibly repeating this procedure a few times). Now the child is able to recognize apples in all sorts of colors and shapes. Genius. (天才)
Machine Learning is not quite there yet; it takes a lot of data for most Machine Learning algorithms to work properly. Even for very simple problems you typically need thousands of examples, and for complex problems such as image or speech recognition you may need millions of examples (unless you can reuse parts of an existing model).
Nonrepresentative Training Data
In order to generalize well, it is crucial that your training data be representative of the new cases you want to generalize to. This is true whether you use instance-based learning or model-based learning.
It is crucial to use a training set that is representative of the cases you want to generalize to. This is often harder than it sounds: if the sample is too small, you will have sampling noise (i.e., nonrepresentative data as a result of chance), but even very large samples can be nonrepresentative if the sampling method is flawed. This is called sampling bias.
针对你想要泛化的案例使用具有代表性的训练集,这一点至关重要。不过说起来容易,做起来难:如果样本集太小,将会出现采样噪声 (即非代表性数据被选中);而即便是非常大的样本数据,如果采样方式欠妥,也同样可能导致非代表性数据集,这就是所谓的采样偏差。
Poor-Quality Data
Obviously, if your training data is full of errors, outliers(异常值), and noise (e.g., due to poorquality measurements), it will make it harder for the system to detect the underlying patterns, so your system is less likely to perform well. It is often well worth the effort to spend time cleaning up your training data. The truth is, most data scientists spend a significant part of their time doing just that.
Irrelevant Features
As the saying goes: garbage in, garbage out. Your system will only be capable of learning if the training data contains enough relevant features and not too many irrelevant ones. A critical part of the success of a Machine Learning project is coming up with a good set of features to train on. This process, called feature engineering, involves:
- Feature selection: selecting the most useful features to train on among existing features.
- Feature extraction: combining existing features to produce a more useful one (as we saw earlier, dimensionality reduction algorithms can help).
- Creating new features by gathering new data.
前面几个challenge主要是bad data,下面几个主要是bad algorithm
Overfitting the Training Data
Say you are visiting a foreign country and the taxi driver rips you off. You might be tempted to say that all taxi drivers in that country are thieves. Overgeneralizing is something that we humans do all too often, and unfortunately machines can fall into the same trap if we are not careful.
这一段写的也好哈哈,仔细想想我们人确实常犯过拟合的错误。
-
In Machine Learning this is called overfitting: it means that the model performs well on the training data, but it does not generalize well.
-
Overfitting happens when the model is too complex relative to the amount and noisiness of the training data. The possible solutions are:
- To simplify the model by selecting one with fewer parameters (e.g., a linear model rather than a high-degree polynomial model), by reducing the number of attributes in the training data or by constraining the model
- To gather more training data
- To reduce the noise in the training data (e.g., fix data errors and remove outliers)
-
Constraining a model to make it simpler and reduce the risk of overfitting is called regularization.
-
The amount of regularization to apply during learning can be controlled by a hyper‐ parameter. A hyperparameter is a parameter of a learning algorithm (not of the model). As such, it is not affected by the learning algorithm itself; it must be set prior to training and remains constant during training. If you set the regularization hyper‐ parameter to a very large value, you will get an almost flat model (a slope close to zero); the learning algorithm will almost certainly not overfit the training data, but it will be less likely to find a good solution. Tuning hyperparameters is an important part of building a Machine Learning system。
Underfitting the Training Data
- Underfitting is the opposite of overfitting: it occurs when your model is too simple to learn the underlying structure of the data.
- The main options to fix this problem are:
- Selecting a more powerful model, with more parameters
- Feeding better features to the learning algorithm (feature engineering)
- Reducing the constraints on the model (e.g., reducing the regularization hyper‐ parameter)
The system will not perform well if your training set is too small, or if the data is not representative, noisy, or polluted with irrelevant features (garbage in, garbage out). Lastly, your model needs to be neither too simple (in which case it will underfit) nor too complex (in which case it will overfit).
once you have trained a model, you don’t want to just “hope” it generalizes to new cases. You want to evaluate it, and fine-tune(微调,精调) it if necessary. Let’s see how
1.5 Testing and Validating
这部分里面提到的训练集,测试集,验证集,交叉验证,之前学习周志华老师的课的时候感觉那里老师讲的很清楚,当时笔记记录在这:周志华 《机器学习初步》模型评估与选择
另外,这里也提到了 No Free Lunch(NFL) Theorem 哈哈哈!
- NFL定理 : 一个算法 L a \mathfrak{L}_{a} La若在某些问题上比另一个算法 L b \mathfrak{L}_{b} Lb 好,必存在 另一些问题 L b \mathfrak{L}_{b} Lb 比 L a \mathfrak{L}_{a} La 好
In a famous 1996 paper,(“The Lack of A Priori Distinctions Between Learning Algorithms,”) David Wolpert demonstrated that if you make absolutely no assumption about the data, then there is no reason to prefer one model over any other. This is called the No Free Lunch (NFL) theorem. For some datasets the best model is a linear model, while for other datasets it is a neural network. There is no model that is a priori guaranteed to work better (hence the name of the theorem). The only way to know for sure which model is best is to evaluate them all. Since this is not possible, in practice you make some reasonable assumptions about the data and you evaluate only a few reasonable models. For example, for simple tasks you may evaluate linear models with various levels of regularization, and for a complex problem you may evaluate various neural networks.
Exercises
-
1.How would you define Machine Learning?
Machine Learning is about building systems that can learn from data. Learning means getting better at some task, given some performance measure.
-
2.Can you name four types of problems where it shines?
Machine Learning is great for complex problems for which we have no algorithmic solution, to replace long lists of hand-tuned rules, to build systems that adapt to fluctuating environments, and finally to help humans learn (e.g., data mining).
-
3.What is a labeled training set?
A labeled training set is a training set that contains the desired solution (a.k.a. a label) for each instance.
“a.k.a.” stands for “also known as.” It is used to introduce an alternative name or nickname for someone or something. For example, you might say, “The artist a.k.a. Kanye West.” This means that Kanye West is also known as “the artist.”
-
4.What are the two most common supervised tasks?
Regression and classification.
-
5.Can you name four common unsupervised tasks?
Clustering, visualization, dimensionality reduction, and association rule learning.
-
6.What type of Machine Learning algorithm would you use to allow a robot to walk in various unknown terrains?
Reinforcement Learning is likely to perform best if we want a robot to learn to walk in various unknown terrains, since this is typically the type of problem that Reinforcement Learning tackles. It might be possible to express the problem as a supervised or semi-supervised learning problem, but it would be less natural.
-
7.What type of algorithm would you use to segment your customers into multiple groups?
If you don’t know how to define the groups, then you can use a clustering algorithm (unsupervised learning) to segment your customers into clusters of similar customers. However, if you know what groups you would like to have, then you can feed many examples of each group to a classification algorithm (supervised learning), and it will classify all your customers into these groups.
-
8.Would you frame the problem of spam detection as a supervised learning problem or an unsupervised learning problem?
Spam detection is a typical supervised learning problem: the algorithm is fed many emails along with their labels (spam or not spam).
-
9.What is an online learning system?
An online learning system can learn incrementally, as opposed to a batch learning system. This makes it capable of adapting rapidly to both changing data and autonomous systems, and of training on very large quantities of data.
-
10.What is out-of-core learning?
这个前面笔记里面偷懒没记
Out-of-core algorithms can handle vast quantities of data that cannot fit in a computer’s main memory. An out-of-core learning algorithm chops the data into mini-batches and uses online learning techniques to learn from these mini-batches.
-
11.What type of learning algorithm relies on a similarity measure to make predictions?
An instance-based learning system learns the training data by heart; then, when given a new instance, it uses a similarity measure to find the most similar learned instances and uses them to make predictions.
-
12.What is the difference between a model parameter and a learning algorithm’s hyperparameter?
A model has one or more model parameters that determine what it will predict given a new instance (e.g., the slope 斜率 of a linear model). A learning algorithm tries to find optimal values(最优解) for these parameters such that the model generalizes well to new instances. A hyperparameter is a parameter of the learning algorithm itself, not of the model (e.g., the amount of regularization to apply).
-
13.What do model-based learning algorithms search for? What is the most common strategy they use to succeed? How do they make predictions?
Model-based learning algorithms search for an optimal value for the model parameters such that the model will generalize well to new instances. We usually train such systems by minimizing a cost function that measures how bad the system is at making predictions on the training data, plus a penalty for model complexity if the model is regularized. To make predictions, we feed the new instance’s features into the model’s prediction function, using the parameter values found by the learning algorithm.
-
14.Can you name four of the main challenges in Machine Learning?
Some of the main challenges in Machine Learning are the lack of data, poor data quality, nonrepresentative data, uninformative features, excessively simple models that underfit the training data, and excessively complex models that overfit the data.
-
15.If your model performs great on the training data but generalizes poorly to new instances, what is happening? Can you name three possible solutions?
If a model performs great on the training data but generalizes poorly to new instances, the model is likely overfitting the training data (or we got extremely lucky on the training data). Possible solutions to overfitting are getting more data, simplifying the model (selecting a simpler algorithm, reducing the number of parameters or features used, or regularizing the model), or reducing the noise in the training data.
-
16.What is a test set and why would you want to use it?
A test set is used to estimate the generalization error that a model will make on new instances, before the model is launched in production.
-
17.What is the purpose of a validation set?
A validation set is used to compare models. It makes it possible to select the best model and tune the hyperparameters.
-
18.What is the train-dev set, when do you need it, and how do you use it?
The train-dev set is used when there is a risk of mismatch between the training data and the data used in the validation and test datasets (which should always be as close as possible to the data used once the model is in production). The train-dev set is a part of the training set that’s held out (the model is not trained on it). The model is trained on the rest of the training set, and evaluated on both the train-dev set and the validation set. If the model performs well on the training set but not on the train-dev set, then the model is likely overfitting the training set. If it performs well on both the training set and the train-dev set, but not on the validation set, then there is probably a significant data mismatch between the training data and the validation + test data, and you should try to improve the training data to make it look more like the validation + test data.
In the context of machine learning, a “train-dev set” is a set of data that is used to evaluate the performance of a model during the training process. The model is trained on a separate training set, and then its performance is evaluated on the development set to see how well it generalizes to unseen data. The train-dev set is used to tune the hyperparameters of the model and to help prevent overfitting. It is common practice to have a separate test set that is only used to evaluate the final performance of the model once training is complete.
In the context of machine learning, a development set (also known as a validation set) is a set of data that is used to evaluate the performance of a model during the training process. It is called a “development set” because it is used to develop the model, i.e., to tune the hyperparameters and ensure that the model is not overfitting the training data.
The development set is different from the training set, which is used to fit the model to the data, and the test set, which is used to evaluate the final performance of the model on unseen data.
Some people use the terms “development set” and “validation set” interchangeably, while others use them to refer to slightly different things. In general, the term “validation set” is used more commonly, and it usually refers to a set of data that is used to evaluate the model during training and fine-tune the hyperparameters.
-
19.What can go wrong if you tune hyperparameters using the test set?
If you tune hyperparameters using the test set, you risk overfitting the test set, and the generalization error you measure will be optimistic (you may launch a model that performs worse than you expect).
参考
-
https://github.com/ageron/handson-ml3
-
https://github.com/ageron/handson-ml2