人工智能原理自学(二)——激活函数、隐藏层神经元以及高维空间
人工智能原理自学(二)——笔记目录
-
- 激活函数——给机器注入灵魂
-
- 激活函数
- 代码实现:
- 隐藏层:神经网络为什么Working
-
- 问题的引出:
- 代码实现:
- 高维空间——面对越来越复杂的问题
-
- 类型分割线
- 隐藏层神经元——将类型分割线进一步扭曲
- 代码实现:
激活函数——给机器注入灵魂
人类思考问题的方式,往往都是离散的分类,而不是精确的拟合
基于分类的思想,传统的量值函数模型已经无法描述基于分类思想而得到的阶跃式函数值:
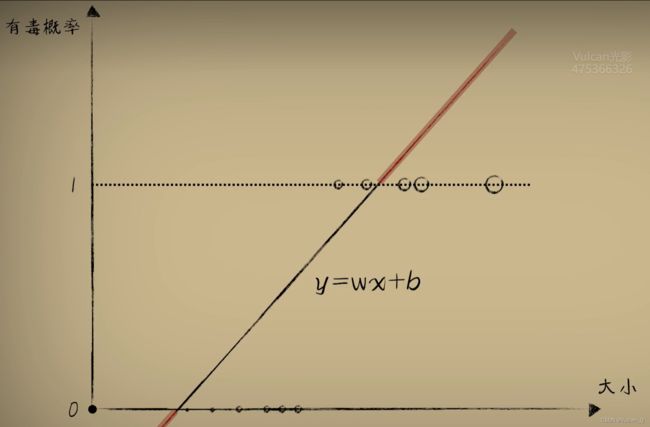
激活函数
面对两极分化的分类问题,在一元一次函数的输出大于某个阈值的时候输出1,小于某个阈值时输出0,可以用一个数学函数来描述这一分类,通常称这个函数为 激活函数。很容易想到的激活函数其实就是分段函数了,但是从梯度下降的视角来看,分段函数在分段点处存在一个**“冲击导数”**,不便于梯度下降时求导的进行。
因此采用一种“S型” 函数——Logistic函数
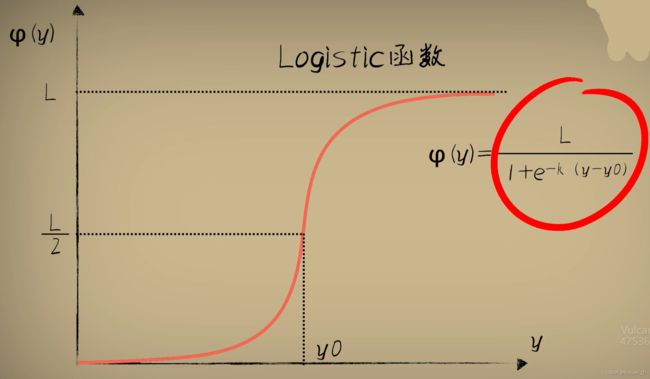
Logistics函数我们一般也是使用它的标准形式,也就是取L = 1,k = 1,y0 = 0.这属于Logistics函数的一种特例。此时要注意:
Sigmoid函数在数学意义上指的是一切具有S形状的函数,Logistics函数属于其中的一种,也是最为常用的一种。除此之外还有比如双正切函数Tanh,反正切函数arctan等。不过在人工智能领域鉴于大家默认使用的都是标准的Logistics函数,慢慢的人们也就不再区分这两种叫法。我们在机器学习中说Sigmoid函数,一般也就是指的标准Logistics函数
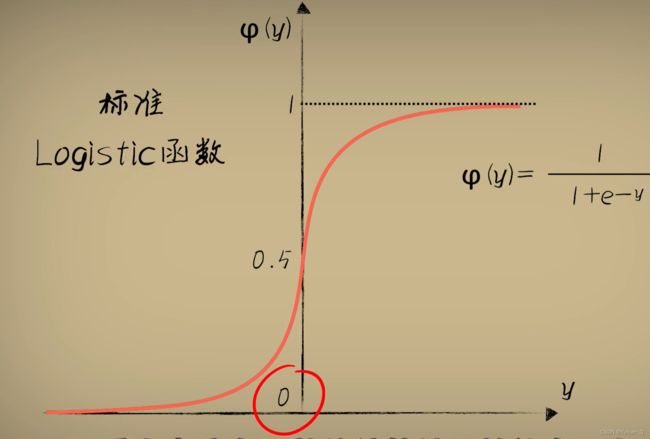
因此,将前文的函数模型y = wx +b变化为a = Sigmoid(wx + b)最终输出,就有了类似的分类拟合效果。则此时的代价函数为:
error = (y - Sigmoid(wx + b))^2
根据复合函数的链式求导法则,就可以求出关于w,b的导数表达式。
综上,非线性的激活函数Sigmoid的加入,使得原本线性的Rosenballt神经元模型变为了一个非线性模型,可以描述更多内容
代码实现:
import dataset
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
xs,ys = dataset.get_beans(100)
w = 0.100
b = 0.1
z = w * xs + b
a = 1/(1 + np.exp(-z))
# plot the figure
plt.title ("Size-Toxicity Function",fontsize = 12)
plt.xlabel("Bean size")
plt.ylabel("Toxicity")
plt.scatter(xs,ys)
plt.plot(xs ,a)
plt.show()
for _ in range(50000):
for i in range(100):
x = xs[i]
y = ys[i]
z = w * x + b
a = 1/(1+np.exp(-z))
e = (y - a)**2
deda = -2 * (y - a)
dadz = a * (1-a)
dzdw = x
dedw = deda* dadz * dzdw
dzdb = 1
dedb = deda * dadz * dzdb
alpha = 0.05
w = w - alpha * dedw
b = b - alpha * dedb
if _%100 == 0:
plt.clf()
plt.scatter(xs,ys)
z = w * xs + b
a = 1/(1 + np.exp(-z))
plt.xlim(0,1)
plt.ylim(0,1.2)
plt.plot(xs,a)
plt.pause(0.01)
print(b)
print(w)
隐藏层:神经网络为什么Working

问题的引出:
通过上文激活函数的概念,我已经可以通过Sigmoid函数的调节作用来对样本进行“一维”的简单描述,但是正如上图所示的样本分布特征,仅使用“一维”的神经网络来进行描述已经不足以表征样本信息,为我们需要再增加几个神经元用来进行更多信息的解读,这些中间层神经元就称为“隐藏层”,一般可以把隐藏层超过三层的神经网络称为**“深度神经网络”**
每添加一个神经元,就相当于添加了一个抽象的“维度”,把输入放入不同的维度中,每个维度通过不断的调整权重并进行激活,从而可以产生对输入的不同理解,最后再把这些抽象维度中的输出合并降维。
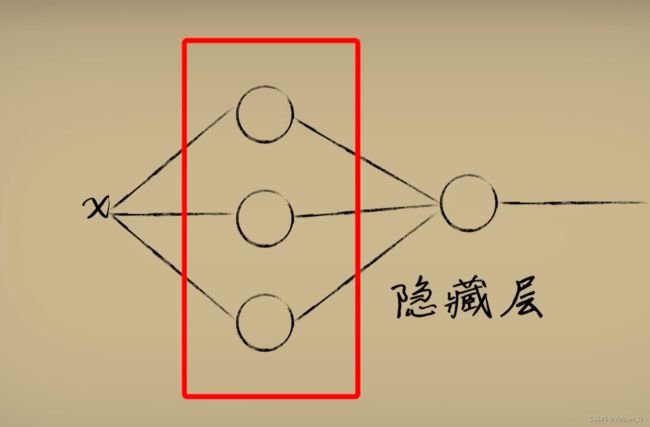
模型的“泛化”问题,就是神经网络追求的核心问题
代码实现:
基于梯度下降的求导思路:

from inspect import formatannotationrelativeto
import dataset
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
# Person function def
def Sigmoid(x):
return 1/(1 + np.exp(-x))
def forward_propgation(xs):
# 前向传播
#第一层
z1_1 = w11_1 * xs + b1_1
a1_1 = Sigmoid(z1_1)
z2_1 = w12_1 * xs + b2_1
a2_1 = Sigmoid(z2_1)
# 第二层
z1_2 = w11_2 * a1_1 + w21_2 * a2_1 + b1_2
a1_2 = Sigmoid(z1_2)
return a1_2 , z1_2 , a2_1,z2_1,a1_1,z1_1
#
# Get the beans and plot
xs,ys = dataset.get_beans(100)
plt.title ("Size-Toxicity Function",fontsize = 12)
plt.xlabel("Bean size")
plt.ylabel("Toxicity")
plt.scatter(xs,ys)
# 神经网络建立
# 第一层
# 第一个神经元
# 使用随机数生成权重与截距的初值,在后期网络更加复杂时,这样的随机数操作更加利于梯度下降的进行
w11_1 = np.random.rand() #第一层的第一个神经元在第一个输入上的权重,下划线之后的数字表示神经元所在的层数,第一个数字表示整个神经网络的第一个输入,第二个数字表示该层的第一个神经元
b1_1 = np.random.rand() # 第一层的第一个神经元的偏执项(截距),同样地,下划线之后的数字表示第一层神经元
# 第二个神经元
w12_1 = np.random.rand()
b2_1 = np.random.rand()
# 第二层
# 唯一神经元
w11_2 = np.random.rand() #第二层的第一个神经元在第一个输入上的权重
w21_2 = np.random.rand() #第二层的第一个神经元在第二个输入上的权重
b1_2 = np.random.rand()
a1_2 , z1_2 , a2_1,z2_1,a1_1,z1_1 = forward_propgation(xs)
plt.plot(xs ,a1_2)
plt.show()
for j in range(50000):
for i in range(100):
x = xs[i]
y = ys[i]
# 反向传播
a1_2 , z1_2 , a2_1,z2_1,a1_1,z1_1 = forward_propgation(x)
# 误差代价e
e = (y - a1_2)**2
deda1_2 = -2 * (y - a1_2)
da1_2dz1_2 = a1_2 * (1-a1_2)
dz1_2dw11_2 = a1_1
dz1_2dw21_2 = a2_1
dedw11_2 = deda1_2 * da1_2dz1_2 * dz1_2dw11_2
dedw21_2 = deda1_2 * da1_2dz1_2 * dz1_2dw21_2
dz1_2db1_2 = 1
dedb1_2 = deda1_2 * da1_2dz1_2*dz1_2db1_2
dz1_2da1_1 = w11_2
da1_1dz1_1 = a1_1 * (1-a1_1)
dz1_1dw11_1 = x
dedw11_1 = deda1_2 * da1_2dz1_2 * dz1_2da1_1*da1_1dz1_1* dz1_1dw11_1
dz1_1db1_1 = 1
dedb1_1 = deda1_2 * da1_2dz1_2 * dz1_2da1_1*da1_1dz1_1* dz1_1db1_1
dz1_2da2_1 = w21_2
da2_1dz2_1 = a2_1 * (1 - a2_1)
dz2_1dw12_1 = x
dedw12_1 = deda1_2 * da1_2dz1_2 * dz1_2da2_1 * da2_1dz2_1 * dz2_1dw12_1
dz2_1db2_1 = 1
dedb2_1 = deda1_2 * da1_2dz1_2 * dz1_2da2_1 * da2_1dz2_1 * dz2_1db2_1
alpha = 0.02
w11_1 = w11_1 - alpha * dedw11_1
w12_1 = w12_1 - alpha * dedw12_1
w11_2 = w11_2 - alpha * dedw11_2
w21_2 = w21_2 - alpha * dedw21_2
b1_1 = b1_1 - alpha * dedb1_1
b2_1 = b2_1 - alpha * dedb2_1
b1_2 = b1_2 - alpha * dedb1_2
if j % 100 == 0:
plt.clf()
plt.scatter(xs,ys)
a1_2 , z1_2 , a2_1,z2_1,a1_1,z1_1 = forward_propgation(xs)
plt.xlim(0,3)
plt.ylim(0,1.2)
plt.plot(xs,a1_2)
plt.pause(0.01)
高维空间——面对越来越复杂的问题
之前的学习过程一直建立在样本毒性仅取决于大小的基础上,然而在现实中毒性可能与很多其他因素有关,比如颜色。因此我们需要使用更多的维度来描述样本,即**“升维”**
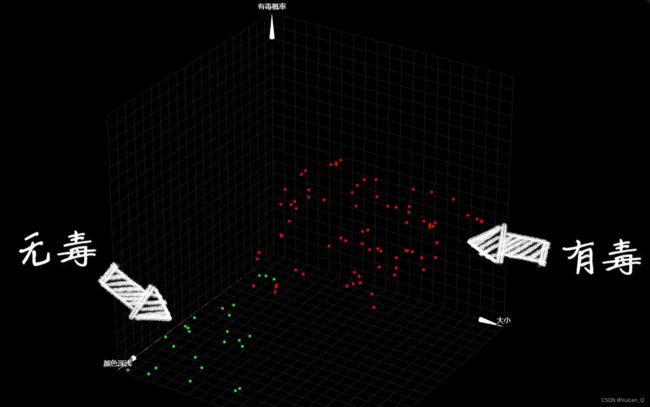
此时,我们的神经元就需要两个输入x1,x2,相应地,原有的y = wx + b也应当线性扩充为 y = w1x1 + w2x2 + b(下图省略了偏置项b)
类型分割线
加入了Sigmoid激活函数后,上文的式子在三维坐标系空间中被扭曲为一个曲面,如果将所有有毒概率为0.5的点连接起来,会发现是一条直线,通俗地讲便是“0.5等高线”,学术称为:类型分割线
隐藏层神经元——将类型分割线进一步扭曲
类型分割线如果只是直线,那么它对三维空间中分布的样本数据点的分割能力就颇具局限性,借助之前的思路,可以再次加入隐藏层神经元,将类型分割线扭曲,示意如下:
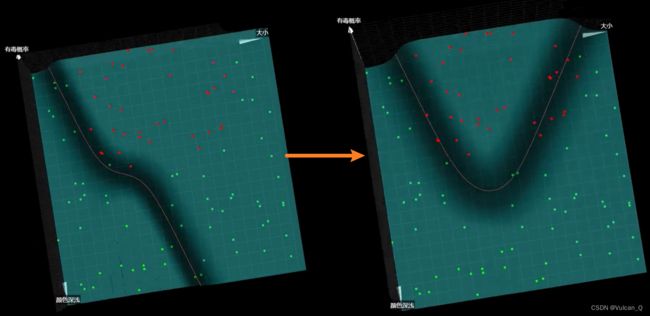
代码实现:
import numpy as np
import dataset
import plot_utils
m =100
xs,ys = dataset.get_beans(m)
print(xs)
print(ys)
plot_utils.show_scatter(xs,ys)
w1 = np.random.rand()
w2 = np.random.rand()
b = np.random.rand()
x1s = xs[:,0]
x2s = xs[:,1]
def forward_propagation(x1s,x2s):
z = w1 * x1s + w2 * x2s + b
a = 1 / (1 + np.exp(-z))
return a
plot_utils.show_scatter_surface(xs,ys,forward_propagation)
for _ in range (500):
for i in range(m):
x = xs[i]
y = ys[i]
x1 = x[0]
x2 = [1]
a = forward_propagation(x1,x2)
e = (y - a)**2
deda = -2 * (y - a)
dadz = a * (1-a)
dzdw1 = x1
dzdw2 = x2
dzdb = 1
dedw1 = deda * dadz * dzdw1
dedw2 = deda * dadz * dzdw2
dedb = deda * dadz * dzdb
alpha = 0.01
w1 = w1 - alpha * dedw1
w2 = w2 - alpha * dedw2
b = b - alpha * dedb
plot_utils.show_scatter_surface(xs,ys,forward_propagation)
plot_utils.py:
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
def show_scatter(xs,y):
x = xs[:,0]
z = xs[:,1]
fig = plt.figure()
ax = Axes3D(fig)
ax.scatter(x, z, y)
plt.show()
def show_surface(x,z,forward_propgation):
x = np.arange(np.min(x),np.max(x),0.1)
z = np.arange(np.min(z),np.max(z),0.1)
x,z = np.meshgrid(x,z)
y = forward_propgation(x,z)
fig = plt.figure()
ax = Axes3D(fig)
ax.plot_surface(x, z, y, cmap='rainbow')
plt.show()
def show_scatter_surface(xs,y,forward_propgation):
x = xs[:,0]
z = xs[:,1]
fig = plt.figure()
ax = Axes3D(fig)
ax.scatter(x, z, y)
x = np.arange(np.min(x),np.max(x),0.01)
z = np.arange(np.min(z),np.max(z),0.01)
x,z = np.meshgrid(x,z)
y = forward_propgation(x,z)
ax.plot_surface(x, z, y, cmap='rainbow')
plt.show()